






深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
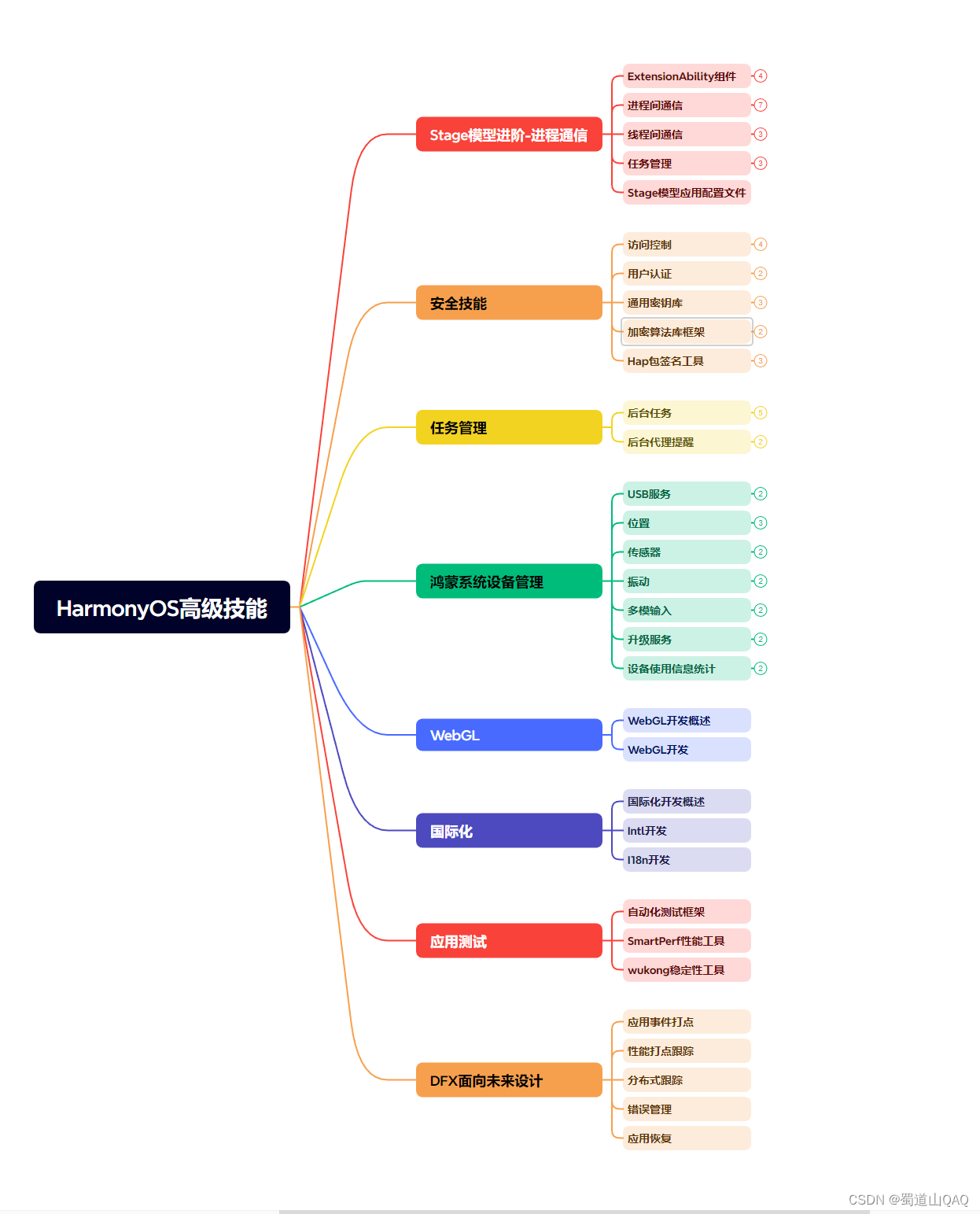

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
+ - [2.1 图表](#21__29)
- [2.2、排版](#22_33)
+ [3.调位置](#3_43)
+ - [3.1、距离之美](#31_44)
- [3.2、对齐之美](#32_46)
- [3.3、对称之美](#33_48)
- [3.4、留白之美](#34_50)
+ [4.精美模板](#4_52)
+ - [4.1 封面纯文字](#41__53)
- [4.2 封面图文混合式](#42__55)
- [4.3 过渡页\标题纲要式](#43___58)
- [4.4 过渡页\纯标题式](#44__60)
- [4.5 过渡页\颜色突显式](#45__62)
- [4.6 目录\传统型目录](#46__64)
- [4.7 目录\创意性目录](#47__66)
- [4.8 目录\图文型目录](#48__68)
- [4.9 排版\单图排版](#49__70)
- [4.10 排版\多图排版](#410__72)
- [4.11 排版\双图排版](#411__74)
- [4.12 文字排版—字多](#412__76)
- [4.13 文字排版—字少](#413__78)
- [4.14 封底\图文混合式](#414__81)
前言
从设计方法和审美原理入手,帮你从字体设计、配色攻略、数据表格处理, 以及专业的版式设计,由浅入深,层层递进……帮你应对演讲、 自我介绍、学术报告、论文答辩、商业提案、 企业培训等不同场景的需求,提升设计逻辑和审美体验,用高水平的 PPT 快速提高职场竞争力
1.定模板
1.1 字体
中文字体:微软雅黑+华康俪金黑W8
英文字体:Tahoma+ Arial
字体大小:正文≥16号,大小间距不超过4
1.2 色彩

1.3 动画

1.4 母版
在做PPT开始,先设计PPT的母版的5个关键页。

2.修文图
2.1 图表
http://www.easyicon.net
http:// pixabay.com

2.2、排版








3.调位置
3.1、距离之美

3.2、对齐之美

3.3、对称之美

3.4、留白之美

4.精美模板
4.1 封面纯文字

4.2 封面图文混合式

4.3 过渡页\标题纲要式

4.4 过渡页\纯标题式
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
盖了95%以上鸿蒙开发知识点,真正体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 1206
1206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









