







深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
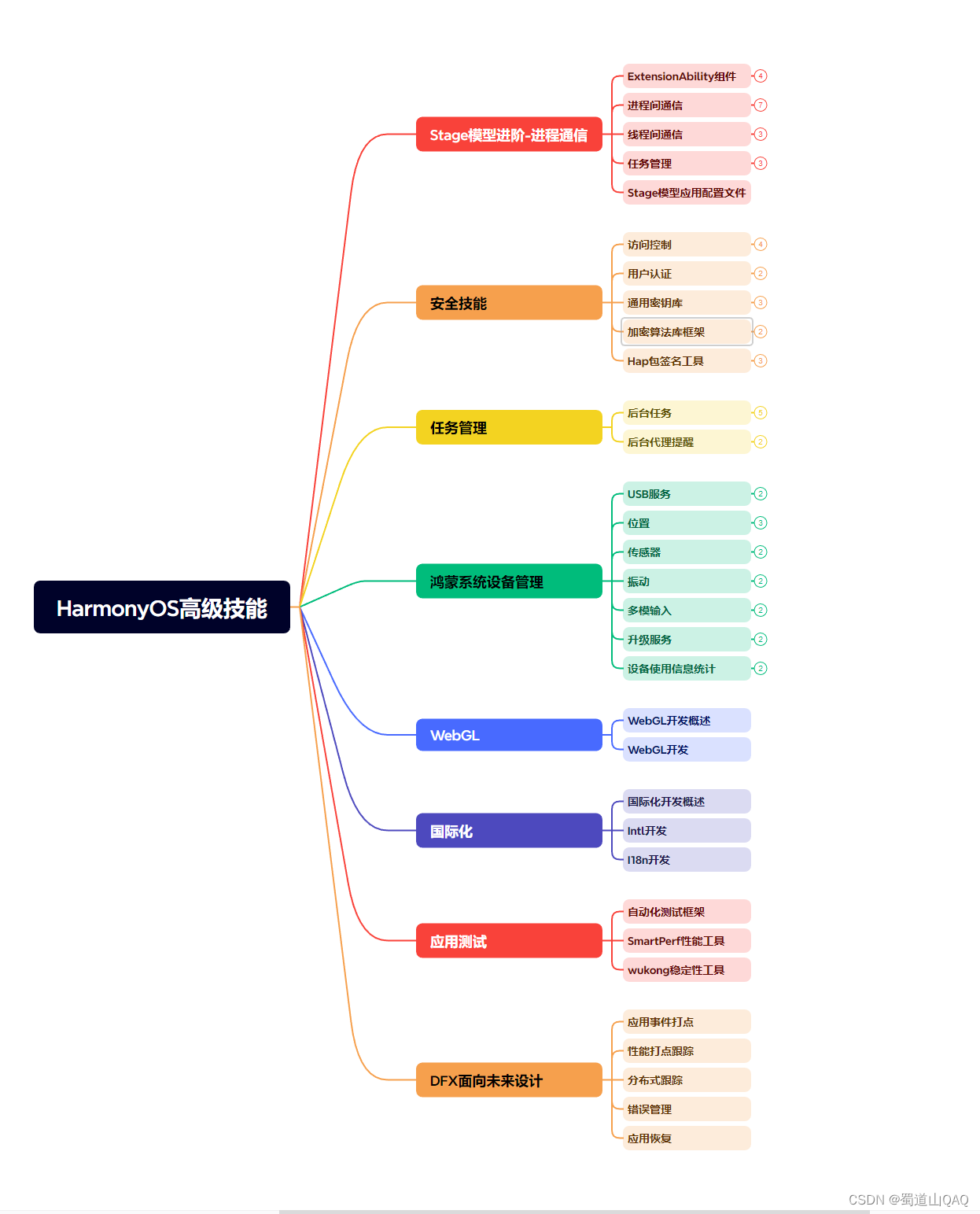


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
其它相关推荐:
系统架构之微服务架构
系统架构设计之微内核架构
鸿蒙操作系统架构
所属专栏:系统架构设计师
一. 大数据技术生态
- 存储:主要包括HDFS、Kafka
HDFS是Hadoop提供的分布式存储框架,它可以用来存储海量数据 - 计算:主要包括MapReduce、Spark、Flink
MapReduce是Hadoop提供的分布式计算框架,它可以用来统计和分析HDFS上的海量数据 - 联机查询OLAP:包括kylin、impala等
- 随机查询NoSQL:包括Hbase、Cassandra等
- 挖掘、机器学习和深度学习等技术:包括TensorFlow、caffe、mahout
二. 大数据分层架构
大数据分层架构图: 
大数据架构图:

HDFS:(Hadoop分布式文件系统),它可以用来存储海量数据,适合运行在通用硬件上的分布式文件系统(Distributed File System)。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。 HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用,【通常用于处理离线数据的存储】。
Hbase: 分布式、面向列的开源数据库,适合于非结构化数据存储。【实时数据和离线数据均支持】。
Flume: 高可用/可靠,分布式海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Kafka:一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。
ZooKeeper:开放源码的分布式应用程序协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
三. Lambda架构
3.1 Lambda架构分解为三层

- 批处理层(Batch Layer):两个核心功能,存储数据集和生成Batch View。
- 加速层(Speed Layer):存储实时视图并处理传入的数据流,以便更新这些视图。
- 服务层(Serving Layer):用于响应用户的查询请求,合并 Batch View 和 Real-time View 中的结果数据集到最终的数据集。
3.2 优缺点
其优点:
容错性好、查询灵活度高 、易伸缩、易扩展
其缺点:
全场景覆盖带来的编码开销。 针对具体场景重新离线训练一遍,益处不大。重新部署和迁移成本很高。
3.3 实际案例

四. Kappa架构
4.1 结构图

- 输入数据直接由实时层的实时数据处理引擎对源源不断的源数据进行处理;
- 再由服务层的服务后端进一步处理以提供上层的业务查询。
- 而中间结果的数据都是需要存储的,这些数据包括历史数据与结果数据,统一存储在存储介质中。
4.2 优缺点
其优点:
将实时和离线代码统一起来了;方便维护而且统一了数据口径;避免了Lambda架构中与离线数据合并的问题。
其缺点:
(1)消息中间件缓存的数据量和回溯数据有性能瓶颈。
(2)在实时数据处理时,遇到大量不同的实时流进行关联时,非常依赖实时计算系统的能力,很可能因为数据流先后顺序问题,导致数据丢失。
(3)Kappa在抛弃了离线数据处理模块的时候,同时抛弃了离线计算更加稳定可靠的特点。
4.3 实际案例


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
ps://bbs.csdn.net/topics/618636735)**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1308
1308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









