







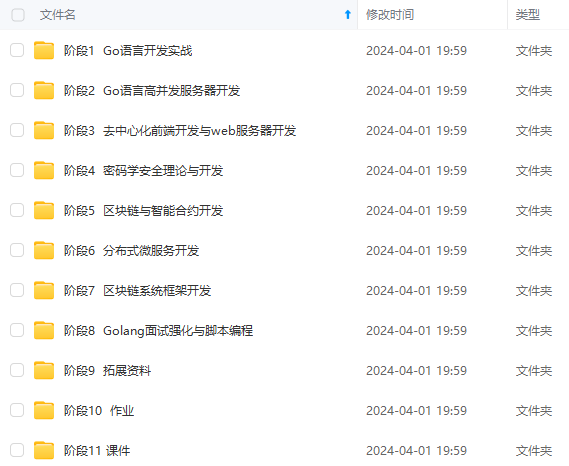
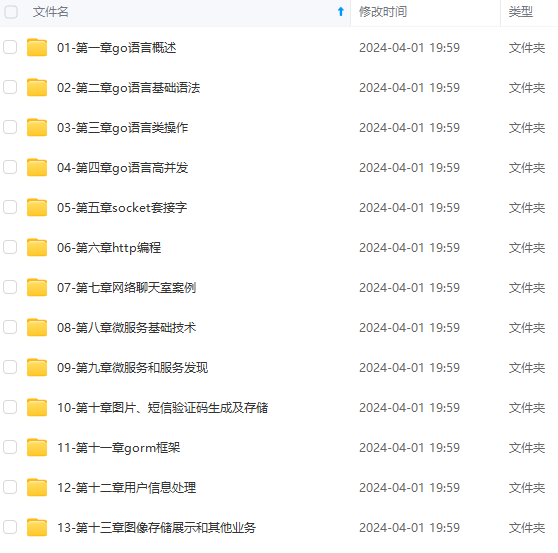
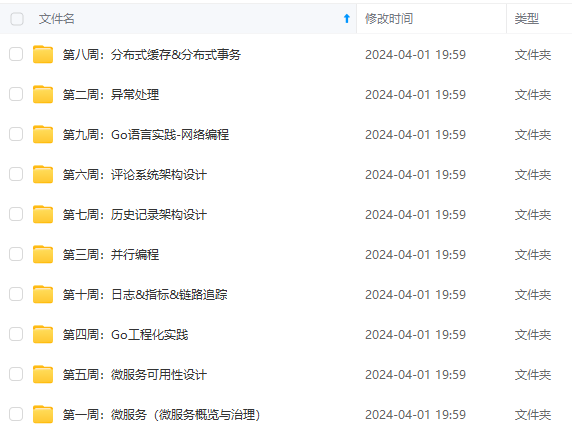
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
)
=
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
P
(
w
1
,
⋯
,
w
n
∣
c
2
)
⋅
P
(
c
2
)
P\left ( w_1,\cdots ,w_n \right )=P\left ( w_1,\cdots ,w_n\mid c_1 \right )\cdot P\left ( c_1 \right )+P\left ( w_1,\cdots ,w_n\mid c_2\right )\cdot P\left ( c_2\right )
3.1、贝叶斯模型的训练
贝叶斯模型的训练过程实质上是在统计每一个特征出现的频次,其核心代码如下:
def train(self, data):
# data 中既包含正样本,也包含负样本
for d in data: # data中是list
# d[0]:分词的结果,list
# d[1]:正/负样本的标记
c = d[1]
if c not in self.d:
self.d[c] = AddOneProb() # 类的初始化
for word in d[0]: # 分词结果中的每一个词
self.d[c].add(word, 1)
# 返回的是正类和负类之和
self.total = sum(map(lambda x: self.d[x].getsum(), self.d.keys())) # 取得所有的d中的sum之和
这使用到了AddOneProb类,AddOneProb类如下所示:
class AddOneProb(BaseProb):
def \_\_init\_\_(self):
self.d = {}
self.total = 0.0
self.none = 1 # 默认所有的none为1
# 这里如果value也等于1,则当key不存在时,累加的是2
def add(self, key, value):
self.total += value
# 不存在该key时,需新建key
if not self.exists(key):
self.d[key] = 1
self.total += 1
self.d[key] += value
注意:
- none的默认值为1
- 当key不存在时,total和对应的d[key]累加的是1+value,这在后面预测时需要用到
AddOneProb类中的total表示的是正类或者负类中的所有值;train函数中的total表示的是正负类的total之和。
当统计好了训练样本中的total和每一个特征key的d[key]后,训练过程就构建完成了。
3.2、贝叶斯模型的预测
预测的过程使用到了上述的公式,即:
P(c1∣w1,⋯,wn)=P(w1,⋯,wn∣c1)⋅P(c1)P(w1,⋯,wn∣c1)⋅P(c1)+P(w1,⋯,wn∣c2)⋅P(c2)
P
(
c
1
∣
w
1
,
⋯
,
w
n
)
=
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
P
(
w
1
,
⋯
,
w
n
∣
c
2
)
⋅
P
(
c
2
)
P\left ( c_1\mid w_1,\cdots ,w_n \right )=\frac{P\left ( w_1,\cdots , w_n\mid c_1 \right )\cdot P(c_1)}{P\left ( w_1,\cdots ,w_n\mid c_1 \right )\cdot P\left ( c_1 \right )+P\left ( w_1,\cdots ,w_n\mid c_2\right )\cdot P\left ( c_2\right )}
对上述的公式简化:
P(c1∣w1,⋯,wn)=P(w1,⋯,wn∣c1)⋅P(c1)P(w1,⋯,wn∣c1)⋅P(c1)+P(w1,⋯,wn∣c2)⋅P(c2)=11+P(w1,⋯,wn∣c2)⋅P(c2)P(w1,⋯,wn∣c1)⋅P(c1)=11+exp[log(P(w1,⋯,wn∣c2)⋅P(c2)P(w1,⋯,wn∣c1)⋅P(c1))]=11+exp[log(P(w1,⋯,wn∣c2)⋅P(c2))−log(P(w1,⋯,wn∣c1)⋅P(c1))]
P
(
c
1
∣
w
1
,
⋯
,
w
n
)
=
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
P
(
w
1
,
⋯
,
w
n
∣
c
2
)
⋅
P
(
c
2
)
=
1
1
P
(
w
1
,
⋯
,
w
n
∣
c
2
)
⋅
P
(
c
2
)
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
=
1
1
e
x
p
[
l
o
g
(
P
(
w
1
,
⋯
,
w
n
∣
c
2
)
⋅
P
(
c
2
)
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
)
]
=
1
1
e
x
p
[
l
o
g
(
P
(
w
1
,
⋯
,
w
n
∣
c
2
)
⋅
P
(
c
2
)
)
−
l
o
g
(
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
)
]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
)
]
=
1
1
e
x
p
[
l
o
g
(
P
(
w
1
,
⋯
,
w
n
∣
c
2
)
⋅
P
(
c
2
)
)
−
l
o
g
(
P
(
w
1
,
⋯
,
w
n
∣
c
1
)
⋅
P
(
c
1
)
)
]
[外链图片转存中…(img-on67nhRD-1715510594199)]
[外链图片转存中…(img-w0lw29R9-1715510594200)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









