







ARCH和GARCH模型
自回归条件异方差,由美国经济学家罗伯特・恩格尔(Robert F. Engle)于 1982 年提出,该模型在金融时间序列分析等领域具有重要的应用,能够有效捕捉数据的异方差性。
在传统的时间序列分析中,通常假定随机误差项具有恒定的方差,即同方差性。然而,在许多实际的经济与金融时间序列数据中,如股票收益率、汇率波动等,在现代高频金融时间序列中,数据经常出现波动性聚集的特点,但从长期来看数据是平稳的,即长期方差(无条件方差)是定值,但从短期来看方差是不稳定的,我们称这种异方差为条件异方差。ARCH 模型正是为了解决这类异方差问题而构建的,它能够动态地刻画时间序列的方差随时间的变化特征。
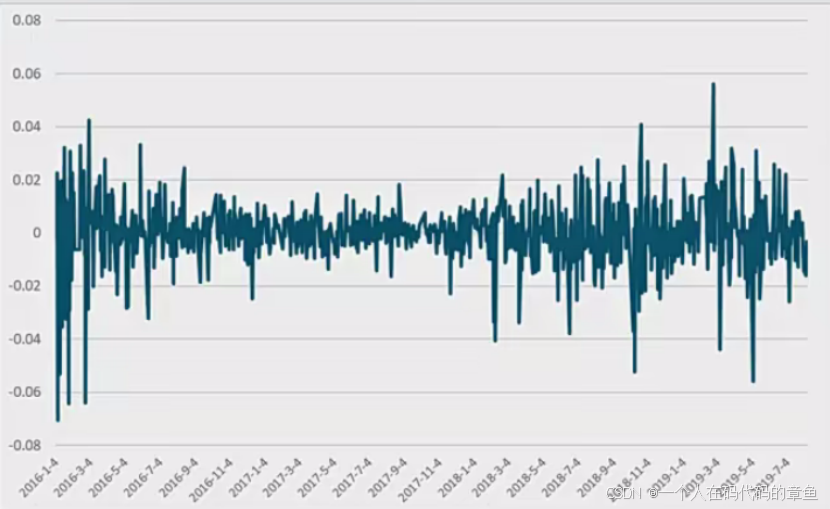
ARCH(p)模型
加法条件异方差
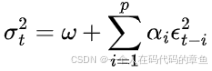
乘法条件异方差:
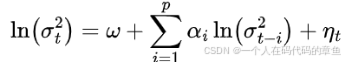
将扰动项变化为了
ARCH 模型认为,当前时刻的随机误差项的方差依赖于过去若干期误差项的平方值。如果过去某一时期的误差较大(即较大),那么当前时期的方差也会相应增大,这意味着未来的波动可能会加剧;反之,若过去误差较小,则当前方差也较小,未来波动相对平稳。这种机制能够很好地捕捉到金融时间序列中常见的波动聚集现象,即大的波动往往会伴随着大的波动,小的波动往往会伴随着小的波动。
GRACH(p,q)模型
广义自回归条件异方差模型
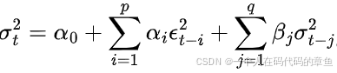
检验GRACH效应:预测完ARMA模型后,如果扰动项和他的平方不是白噪声,就存在GRACH现象
应用:
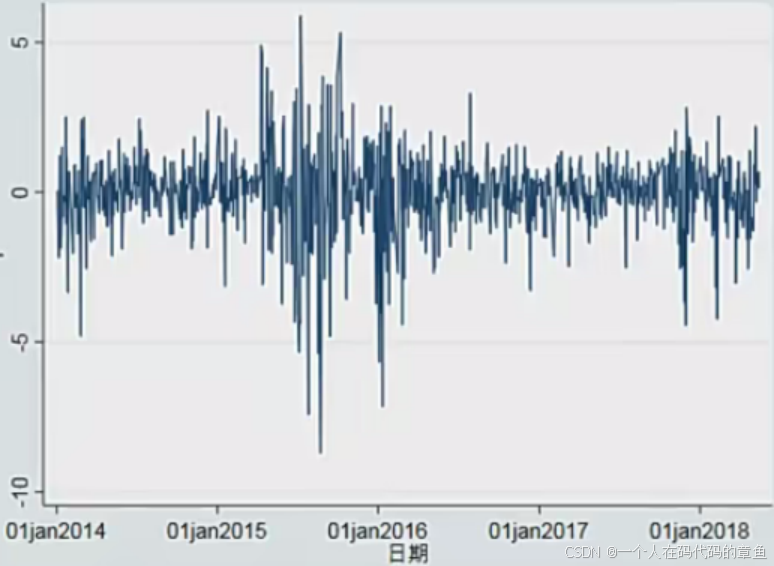
下面是对深证B进行时间序列的预测建模
下面对收益率进行预测
大概的步骤’
1,单位根检验:原假设:单位根序列,备择假设:平稳序列
平稳数据用ARMA模型,单位根用ARIMA模型
2,根据ACF和PACF图选择一些阶数
3,计算模型的AIC和BIC,选择平均值最小的模型
4,检验残差是否为白噪声(检验ARMA/ARIMA有效性)
5,LM检验残差平方和(是否存在GRACH)
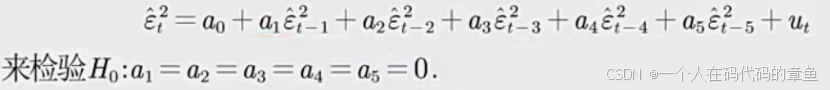
6,在正态分布和t分布的GRACH(1,1)和GRACH(2,2)的模型进行选择
代码:
clear // 清空变量
* (1) 导入数据并生成时间序列 (*和//都可以用来注释一行)
insheet using "Bindex.csv" //导入位于和代码同一文件夹下的csv数据文件
gen datevar = date(date,"YMD") // 将csv中的变量date转换为stata能识别的时间数据datevar
format datevar %td // 对datevar的展示格式进行转换,转换后以:日月年 显示
label variable datevar "日期" // 设置datevar的标签为日期,主要用于画图时的展示
tsset datevar // 定义datevar是一个时间序列数据
gen time=_n // 定义一个从1到n的time序列,n是观测值的个数,系统自动在后台记录的
tsset time
// 画深成B指的时间序列图
line index datevar
graph export "深成B指的时间序列图.png", as(png) replace // 导出图片到本地文件夹
// 计算日收益率数据
gen r=100*(index-L.index)/L.index //(今天的收盘价-昨天的收盘价)/昨天的收盘价 L是lag的缩写
// 对日收益率r进行描述性统计
summarize r
// 做出日收益率的时间序列图
line r datevar
graph export "深成B指日收益率的时间序列图.png", as(png) replace // 导出图片到本地文件夹
// 检验收益率序列r是否为单位根,检验方法是ADF检验(原假设:是单位根序列,备择假设:是平稳序列)
dfuller r
// MacKinnon approximate p-value for Z(t) = 0.0000 p值为0意味着拒绝原假设,所以我们认为r序列平稳
// 观察acf图与pacf图 ,判断AMRA模型的阶数
ac r,lags(20) // 自相关系数图,滞后20期
graph export "自相关系数图.png", as(png) replace // 导出图片到本地文件夹
pac r,lags(20) // 偏自相关系数图,滞后20期
graph export "偏自相关系数图.png", as(png) replace // 导出图片到本地文件夹
// 根据acf和pacf图,初步判断使用四个备选的ARMA模型来拟合
set matsize 1500 // 把计算时支持的最大矩阵大小设置的大一点,否则计算机性能较差的电脑可能在计算中会报错
arima r,arima(3,0,3) // 用ARIMA(3,0,3)模型对r进行估计
estat ic // 得到AIC和BIC,用于选择合适的模型(选小原则,详见第十一讲)
arima r,arima(8,0,8)
estat ic
arima r,arima(3,0,8)
estat ic
arima r,arima(8,0,3)
estat ic
// ARIMA(3,0,3)模型的AIC值和BIC值的平均值最小,所以下面我们使用这个模型进行估计
arima r,arima(3,0,3)
// 得到残差的预测值并生成残差分布直方图图
predict residess, residuals // 保存残差
hist residess,norm freq // norm freq表示加上标准正态分布的概率密度函数
graph export "残差分布直方图.png", as(png) replace // 导出图片到本地文件夹
// 检验残差是否为白噪声序列,检验方法为Q检验:原假设是白噪声,备择假设不是白噪声
wntestq residess, lag(12) // 对残差序列进行白噪声检验
// 生成残差的平方,并进行Q检验
gen ressq = residess^2 // 生成残差平方序列ressq
wntestq ressq, lag(12) // 对残差平方序列ressq进行白噪声检验
// LM检验:是否存在ARCH误差
reg ressq l.ressq l2.ressq l3.ressq l4.ressq l5.ressq // 将残差平方项对其滞后项回归
gen LM_STAT=e(N)*e(r2) // 计算LM统计量
display LM_STAT // 输出LM统计量
display chiprob(e(df_m),LM_STAT) // 计算p值
// 利用AIC BIC选择合适的模型进行估计
// 注意:扰动项的分布在金融数据中常服从t分布
// 正态分布下GARCH(1,1)估计
arch r,arima(3 0 3) arch(1) garch(1)
estat ic
// t分布下GARCH(1,1)估计
arch r,arima(3 0 3) arch(1) garch(1) distribution(t 3) // 自由度为3的t分布
estat ic
// 正态分布下GARCH(2,2)估计
arch r,arima(3 0 3) arch(2) garch(2)
estat ic
// t分布下GARCH(2,2)估计
arch r,arima(3 0 3) arch(2) garch(2) distribution(t 3)
estat ic
// 得到拟合结果,并进行预测
arch r,arima(3 0 3) arch(1) garch(1) distribution(t 3)
tsappend ,add(10) // 将时间延长10期
predict result // 对数据进行预测
tsline result r, legend(label(1 "预测值") label(2 "真实值")) // 绘制拟合图
graph export "预测结果图.png", as(png) replace // 导出图片到本地文件夹



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









