







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
- 日志聚合与监控
- 分布式系统数据一致性、可用性、安全等问题。
微服务原则
- 高内聚: 对高内聚比较有表现力的描述是:“一起改变的代码,放置在一起”。将功能相关的代码聚合到一起,能够帮助我们在尽可能少的地方做修改。例如,把和用户权益相关的功能整合在一起,当我们需要频繁变更部署用户权益系统时,就不用改动也不用重新部署其他服务了。
- 低耦合: 高内聚强调的是微服务内部的关系,而低耦合强调的是服务与服务之间的关系。在微服务架构中,服务与服务之间的关系应该是松散、低耦合的。什么样的情况可能出现服务紧密耦合呢?举个例子,如果我们要对权益系统进行修改,就必须同时修改上游和下游服务。
高内聚与低耦合是一体两面的,更好地实现内聚也将降低服务间的耦合度,而低耦合同样也取决于服务与服务之间的沟通模式。对外提供的 API 应该更可能少,隐藏内部的实现细节,同时 API 提供向后兼容的能力。其他服务不需要知道当前服务内部实现的细节,将当前服务当做一个黑盒。这种服务关注点的分离,能够让我们驾驭更大规模的程序。
微服务通信
- 同步
- 异步
- 数据共享
- 协议
- 消息中间件
微服务技术点
- 服务划分
- 服务复用
- 通信与序列化协议:HTTP、HTTPS、GRPC、Protobuf、json等
- 服务发现和服务注册
- 网关
- 负载均衡
- 链路追踪
- 日志采集
- 系统监控
- 服务降级
- 测试
服务发现
- 服务发现: 服务端发现模式的优点是服务调用方不用关注发现的细节,服务和监控等策略可以统一在代理网关进行。但是服务端发现模式的缺点是网络中多了一层,部署相对复杂,并且本身容易变成新的单点故障和性能瓶颈。
- K8s Service资源: K8s 的 Service 资源实现服务发现本质上就是一种服务端的服务发现模式,但是它实现的方式却有很大不同。Service 会生成一个虚拟的 IP,通过修改 iptables 规则的方式,将虚拟的 IP 转发到指定 Pod 的地址中,实现服务发现与负载均衡的功能。
- 客户端发现: 和服务端发现模式不同的是,客户端发现模式能够直接从服务注册中心获取可用的节点列表,并可以监听服务节点注册的变化。调用方集成的 SDK 能够根据一定的负载均衡策略选定一个最终的服务节点。
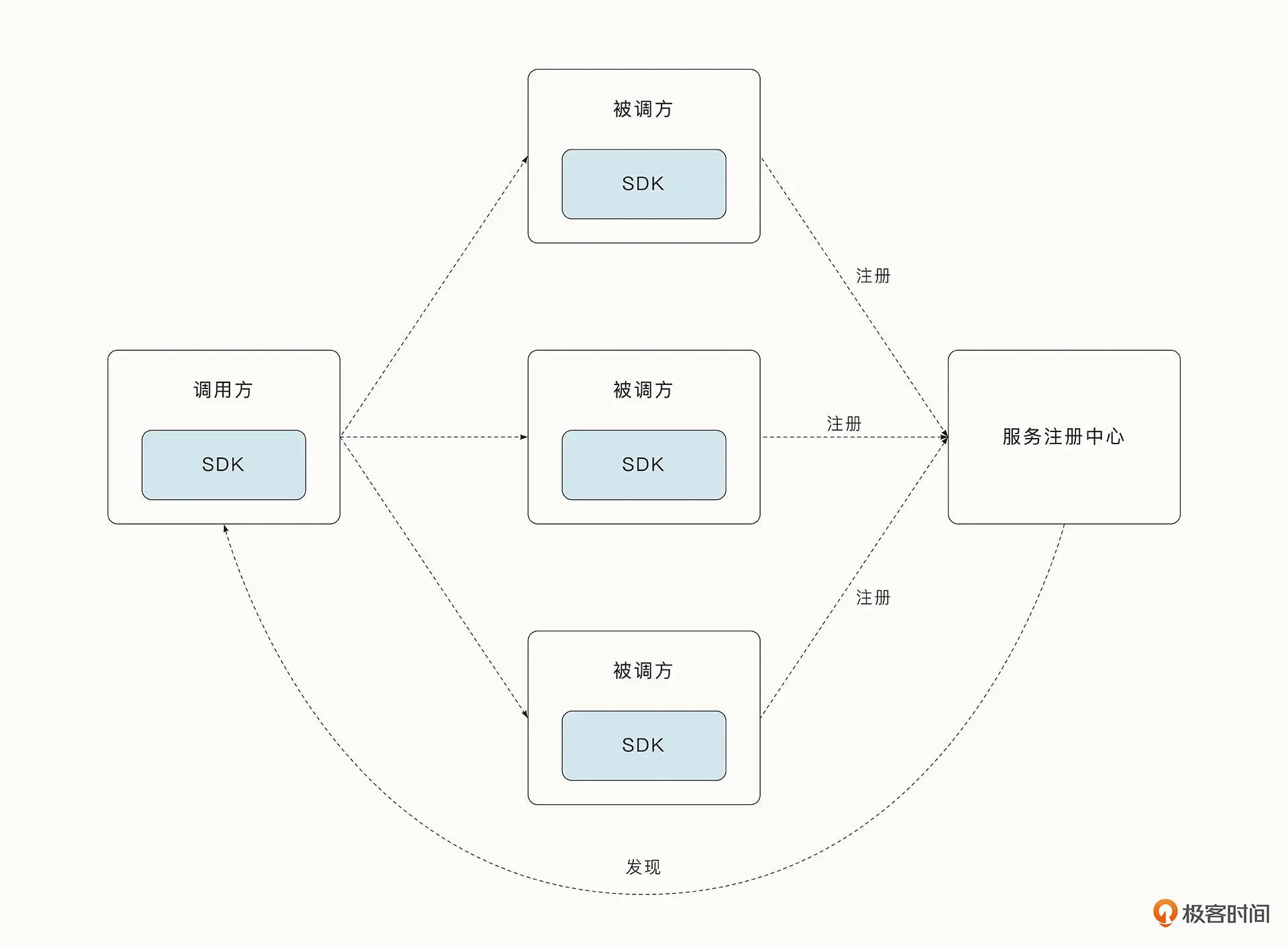
那这两种服务发现模式,选哪种更好呢?
其实,根据实际的场景,我们可以选择不同的服务发现模式和对应的负载均衡策略。有些大型互联网公司可能会同时使用两种模式,并把它们混合起来。例如,服务调用方利用 SDK 从服务注册中心获得的是虚拟 IP(virtual IP address ,VIP),然后借助 LVS、Nginx 等技术完成负载均衡。
分布式日志与监控
日志
目前业内通用的做法是借助一个 agent 服务(典型的工具有 Flume、Filebeat、Logstash、Scribe),监听并增量采集日志数据到消息中间件,下游计算引擎会实时处理数据,并把数据存储到对应的数据库做进一步处理。典型的日志采集与监控链路如下所示:
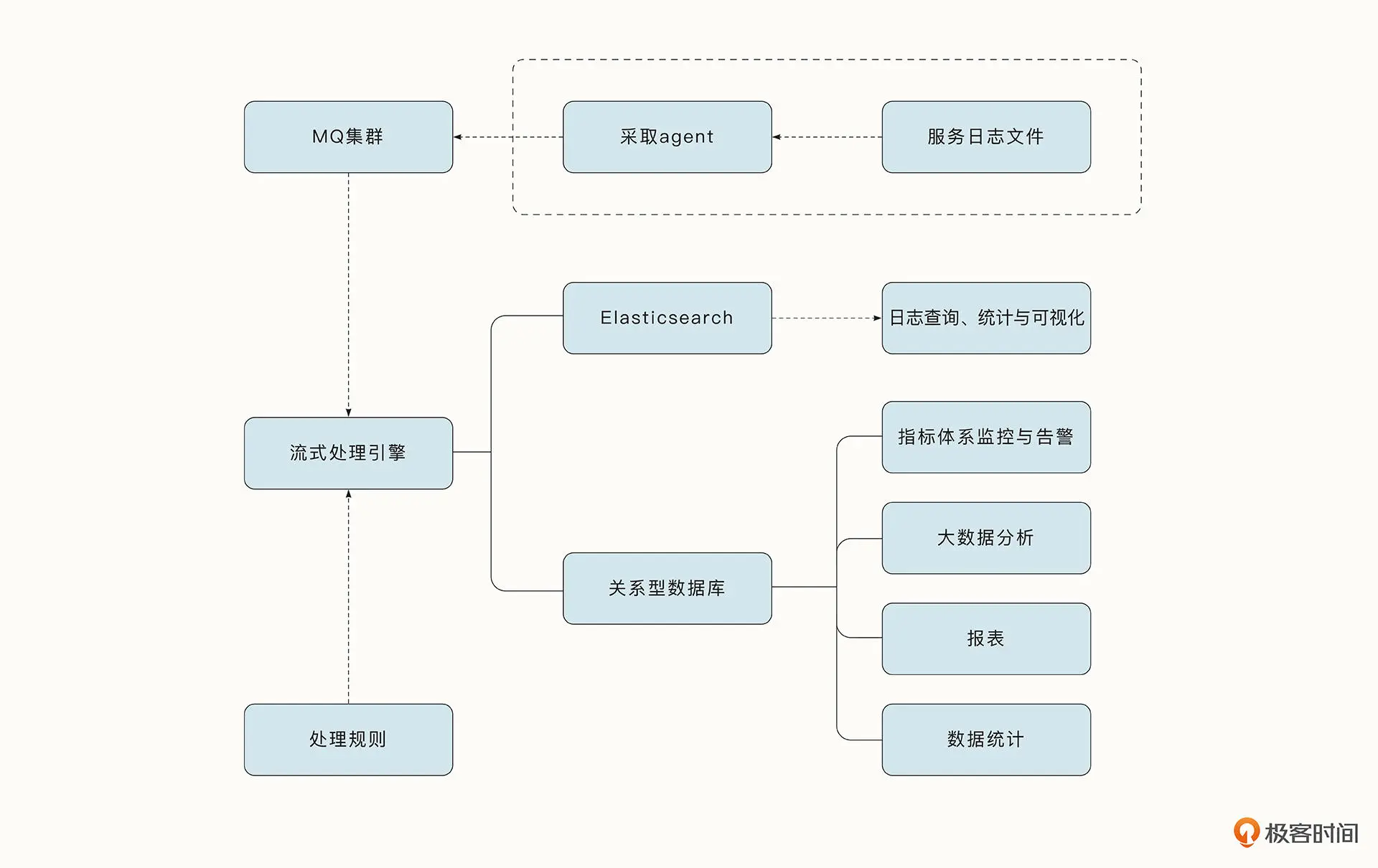
日志数据写入到 MQ 之后,下游流式处理引擎会按照预定的处理规则对数据进行清洗、统计,还可以对错误日志进行告警。经过最终处理的数据会存储到相应的数据库中。
一般业内比较常见的做法是将清洗后的日志数据存储到 Elaticsearch 中,Elaticsearch 的优势是开源、可扩展、支持倒排索引、全文本搜索,检索效率高,结合 Kibana 还可以对数据进行可视化处理。但是由于线上日志通常是海量的,数据在 Elaticsearch 中通常无法保存太久,所以我们也会有一些低成本、更持久的日志落盘方案,例如使用 Hbase、ClickHouse 等数据库。
而对于一些分析汇总类的数据,如果结构良好并且总量比较确定,可以选择关系型数据库 MySQL、PostgreSQL 来存储。
监控
针对这些数据,我们能够更进一步地进行离线的数据分析和统计,也可以基于它建立业务指标体系的监控。如,对于打车业务,如果遇到天价账单这种异常的监控数据,我们可以同比与环比当前打车数量、特殊费用,确认是不是真的存在问题。
指标体系如果利用得好,可以有效识别系统的异常,像上线导致的系统 Bug 就能够很快在指标体系中反映出来。再配合异常事件的告警,可以将大事故降为小事故,把小事故扼杀在摇篮中。
除了分布式的日志聚合,通常我们还需要聚合起服务的其他信息,包括:
- 容器与宿主机系统资源利用率(包括 CPU 利用率、CPU 用户态使用率、CPU 内核态使用率、内存利用率、内存占用量、磁盘利用率、磁盘读写吞吐、磁盘读写次数、进程端口监控、线程数量、进程数量、网卡出入带宽等 );
- 服务自身错误率(包括自身核心接口错误率、下游接口错误率、基础服务错误率);
- 服务延迟(接口平均与 P99 延迟、下游平均与 P99 耗时);
- 服务请求量(当前接口请求量、下游接口请求量);
- 服务运行时指标(例如对 Go 语言,可以上报服务的协程数量、线程数量、垃圾回收时间等重要指标);
- 业务指标(服务内特定事件监控,例如配置参数异常等)。
采集到的信息会通过恰当的频率,或在遇到特定事件时上报到监控服务。这些数据最终会存储到时序数据库中,并由监控平台提供可视化能力。好的可视化会提供按照不同维度查看数据的能力,例如选择不同的机器,使用求和、均值、最大值、最小值等聚合方式。环比、同比可以选择不同的时间维度(例如分钟级别、小时级别、天级别、月度级别)。指标数据还可以通过标识不同的 tag 快速筛选不同种类的数据。
有一些指标的出现说明存在异常事件,例如当 Go 程序 panic 时我们会收到相关信息。对于其他一些信息,例如接口调用量、CPU 利用率等,我们不仅希望能够监控当前时刻的指标,还希望能够查看这些指标的变化趋势。这些监控信息不仅能够反映当前系统和服务的运行状态,及时判断是否需要扩容等操作,还能够有效地检测出系统运行的变化和错误,快速发现线上问题,保障业务稳定运行。
例如,当我们发现调用下游核心系统的错误率大于了 5% 时,就应该立即启动一级报警策略,通过群报警、短信和电话的方式通知责任人。一些做得好的告警信息还会推荐止损办法,例如服务降级的手段,或者是下游负责人的联系方式等。
分布式追踪
在复杂的微服务架构中,一个开发团队通常只需要维护自己的服务,对整体的系统不甚了解。但用户的一个请求常常会跨越多个服务。如果当前的请求出现了问题,怎么快速定位到相关的服务呢? 怎么快速了解当前环境下接口调用链路是否正常运行?怎么定位到当前的调用链路中耗时最多的位置,从而找到性能瓶颈?解决这些问题就是分布式链路追踪的目的。
相对于只提供一个特殊的用于标识指定请求的 traceID,分布式追踪的方案提供了更多的链路信息,更直观的调用关系,甚至链路的可视化。
分布式跟踪有一个重要的概念: span。span 表示调用链路中的单个操作,单个服务中可能有多个 span,追踪重要函数的调用时就是这样。span 中可以存储多个信息,在 OpenTracing API 中,每个 span 除了存储开始时间、结束时间,还可以存储额外的信息,例如客户 ID、订单 ID、主机名等。
每一个 span 中还保存了当前调用链唯一的 traceID,当前 span 的 ID、以及父 span 的 ID。当函数调用或跨服务传递时,服务会传递 span 的这些上下文信息,以便跟踪 span 之间的调用链关系。如下图左侧是服务调用链构成的一个有向无环图,有些分布式追踪组件可以通过瀑布图的形式显示出在调用链中每个 span 的耗时,如下图右侧看到的,这种可视化的手段能直观地反应调用链的耗时情况。
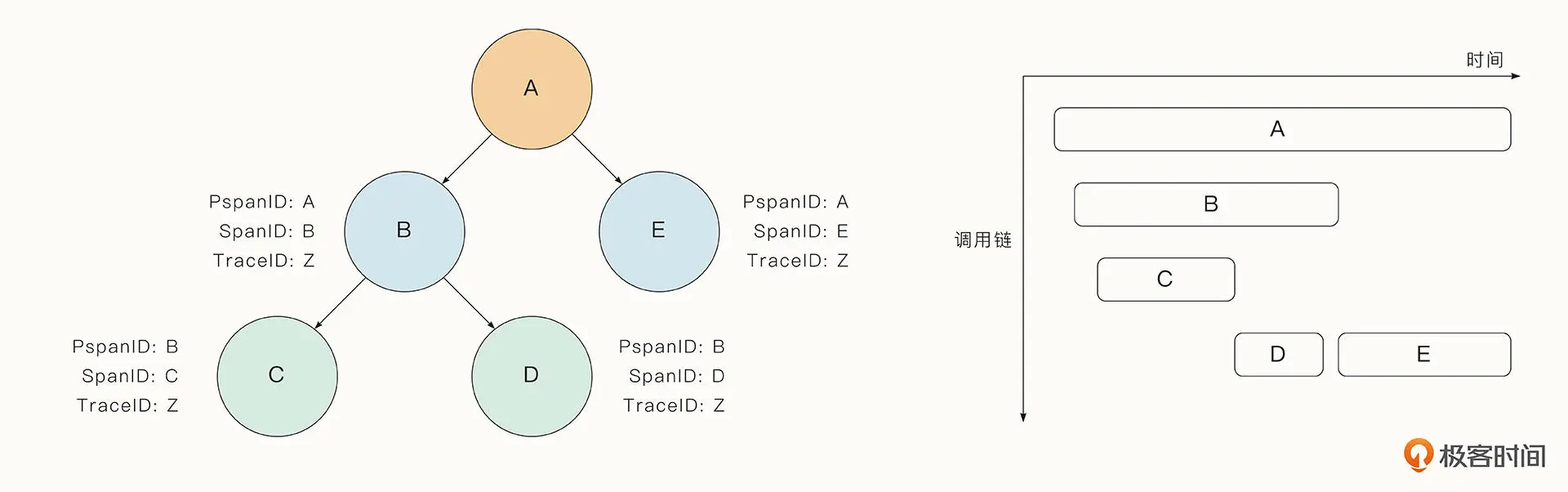
当前有一些优秀的分布式追踪组件,以开源的 Jaeger 为代表。
微服务测试
- 单元测试
- 服务测试
- 端到端测试
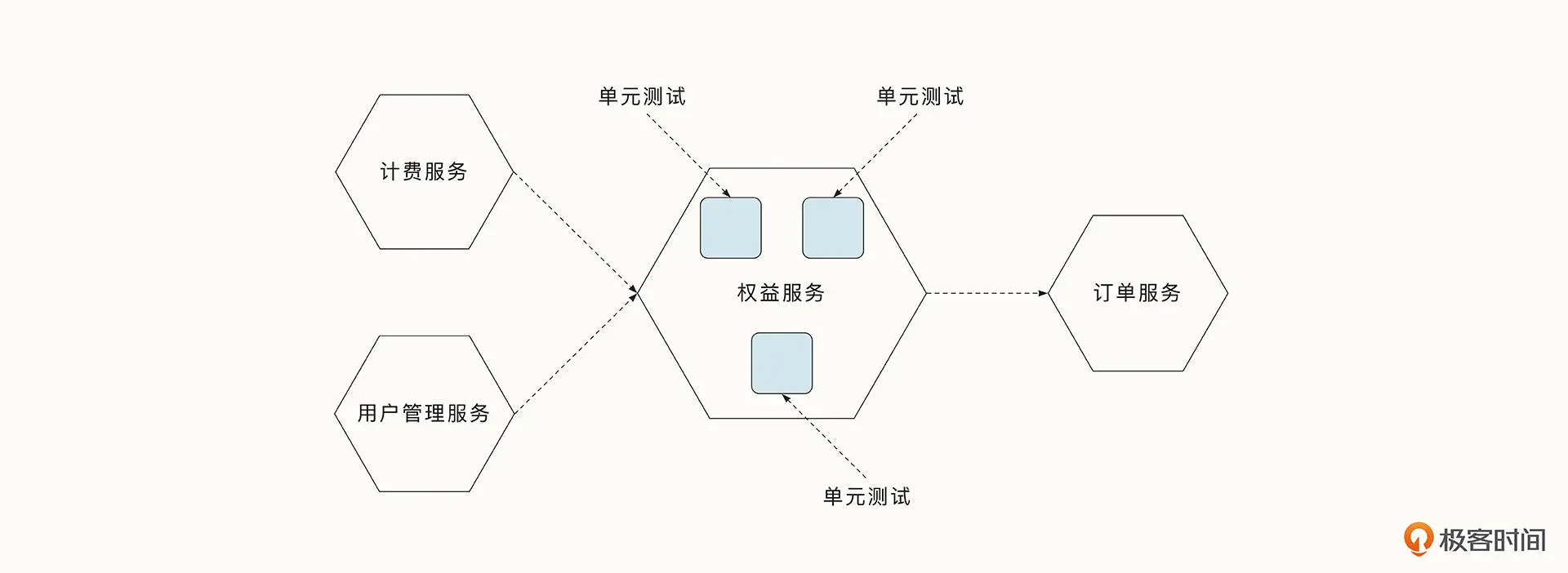
单元测试
单元测试是在内部对于单一功能模块的测试,其测试速度快,测试范围小。对于单元测试中依赖外部组件的模块,例如数据库和外部服务,我们需要使用 Mock 等手段完成依赖注入。
就拿 Go 语言来说,我们常常利用接口的特性来实现依赖的注入。这要求代码在设计时就实现了核心功能的接口抽象,否则对于所有的依赖和功能混杂在一起的函数,是非常难进行单元测试的。
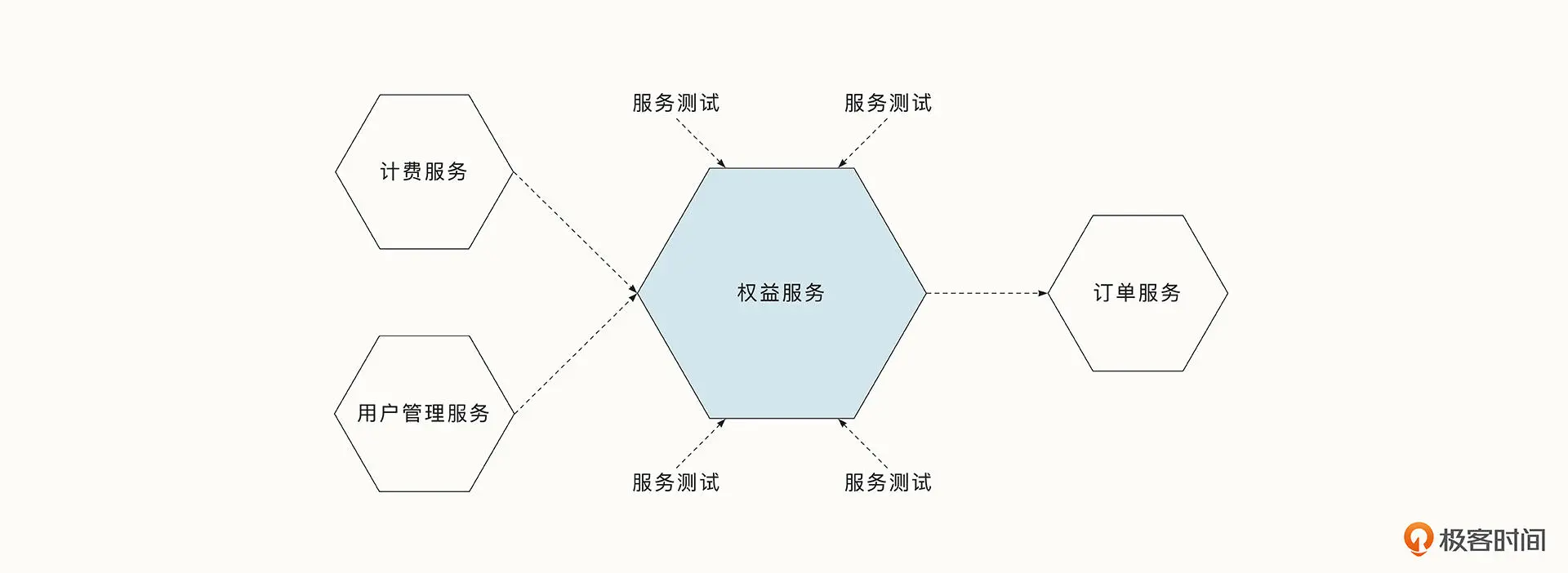
服务测试
服务级别的测试指的是将单个微服务作为一个黑盒,测试服务的功能。服务级别测试覆盖的代码与功能范围比单元测试更大,如果我们测试的场景足够充分,就能保证大多数场景是符合预期的。但是由于服务级别的测试调用的链路更复杂,出现问题时也更难定位。如果我们模拟线上环境,真实调用数据库和下游服务,会导致该阶段测试的耗时更长。
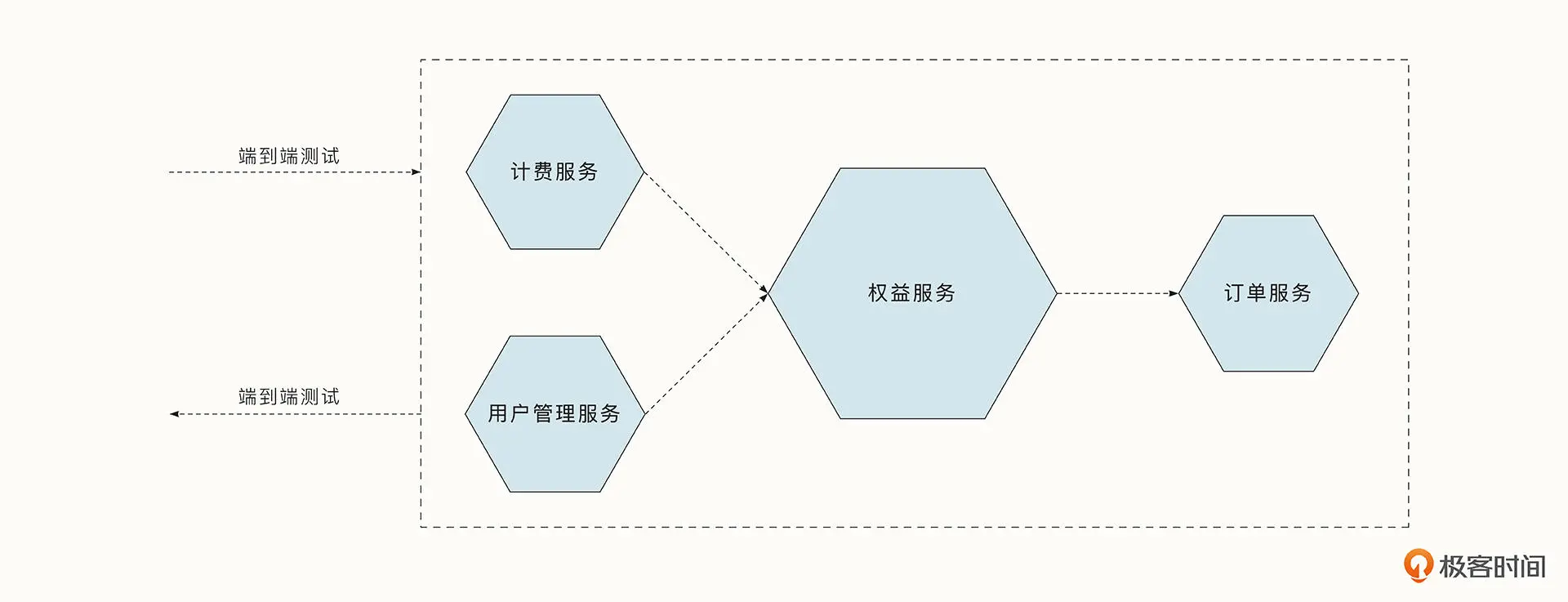
端到端测试
端到端的测试要求对整个服务进行测试。例如对于一个打车服务,通常我们要模拟乘客与司机的行为,完整走一遍从乘客预估、司机接单、开始计费、行程中、结束计费等多个流程,并验证每个环节中的交互和数据准确性。端到端测试会覆盖更多的服务和代码,并让我们对发布的产品更加有信心。但是可以想象,端到端测试比服务级别的测试耗时更久,测试出问题后,也更难定位。
服务降级
一个服务复现故障后,这种故障会传导到上游服务。我们需要有效地对系统进行自动或手动的控制,保证服务处于正常的状态、将损失降低到最小。为了实现这个目标,我们可以采用降级、限流、熔断、切流等手段。
降级
降级是服务的一种自我保护机制,它指的是对一些服务和页面有策略地不处理,或者只进行简单的处理,以此释放服务器资源,保证核心业务正常高效运行。
- 在电商的秒杀场景中,为了应对海量请求,我们可以暂时禁用用户显示页面上一些不关键的模块(例如广告),或者用预置的内容代替它,减轻服务器的压力。
- 在打车服务中,为了应对海量的流量,保证服务可用,我们可以短期内不调用用户的权益系统。虽然这样可能无法正确计算用户的优惠券和权益,但是能够保证用户正常的出行。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
尝辄止,不再深入研究,那么很难做到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









