









既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
a = Dog(‘小狗’)
Animal.animal_talk(a) # 多态调用
b = Cat(‘小猫’)
Animal.animal_talk(b)
c = Animal(‘111’)
Animal.animal_talk©
执行结果:小狗: 汪汪汪!
小猫: 喵喵喵!
111 叫
#### 4. 单元测试,单例模式
**单元测试(unit testing**),是指对软件中的最小可测试单元进行检查和验证。在python中指一个类。单元测试是在软件开发过程中要进行的最低级别的测试活动,软件的独立单元将在与程序的其他部分相隔离的情况下进行测试。
**单例模式**,是一种常用的软件设计模式。在它的核心结构中只包含一个被称为单例的特殊类。通过单例模式可以保证系统中,应用该模式的一个类只有一个对象实例。(详见面试总结一)
#### 5. python 如何实现单例模式?
**什么是单例模式(Singleton)?**
单例模式,也叫单子模式,是一种常用的软件设计模式。在应用这个模式时,单例对象的类必须保证只有一个实例存在。
单例模式优点:
1. 由于单例模式要求全局内只有一个实例,所以可以节省很多内存空间
2. 全局只有一个接入点,可以更好的进行数据同步,避免多重占用
3. 单例可以常驻内存,减少系统开销
单例模式应用:
1. 生成唯一序列号
2. 访问全局复用的唯一资源,如磁盘,总线等
3. 数据库连接池
4. 网站计数器
**实现单例的方式?**
* 全局变量:不直接调用 Config() ,而使用同一个全局变量
* 重写 \_\_new\_\_ 方法:重写 \_\_new\_\_来保证每次调用 Config() 都会返回同一个对象, \_\_new\_\_ 为对象分配空间,返回对象的引用
* 使用metaclass:metaclass重写\_\_call\_\_ 方法来保证每次调用 Config() 都会返回同一个对象
* 使用装饰器:使用装饰器来保证每次调用 Config() 都会返回同一个对象
原理:在真正调用 Config() 之前进行一些拦截操作,来保证返回的对象都是同一个:
**具体实现:**
1. 全局变量
config.py
from dataclasses import dataclass
@dataclass
class Config:
SQLALCHEMY_DB_URI = SQLALCHEMY_DB_URI
config = Config(SQLALCHEMY_DB_URI = “mysql://”)
通过使用全局变量,我们在所有需要引用配置的地方,都使用 from config import config 来导入,这样就达到了全局唯一的目的。
2. 重写\_\_new\_\_方法
class Singleton(object):
_instance = None # _instance 作为类属性,保证了所有对象的实例都是同一个
def \_\_new\_\_(cls, \*args, \*\*kwargs):
if cls._instance is None:
cls._instance = super().__new__(cls) # 为对象分配空间
return cls._instance # 返回对象的引用
a = Singleton() # 创建对象时,new方法会被自动调用
b = Singleton()
print(a)
print(b)
执行结果:<main.Singleton object at 0x0000023A88E0F2B0>
<main.Singleton object at 0x0000023A88E0F2B0>
每次实例化一个对象时,都会先调用 `__new__()` 创建一个对象,再调用 `__init__()` 函数初始化数据。因而,在 new 函数中判断 Singleton类 是否已经实例化过,如果不是,调用父类的 new 函数创建实例;否则返回之前创建的实例。
3. 使用metaclass元类
class SigletonMetaClass(type):
_instance = None
def \_\_new\_\_(cls, \*args, \*\*kwargs):
return super().__new__(cls, \*args, \*\*kwargs)
def \_\_call\_\_(self, \*args, \*\*kwargs):
if self._instance is None:
self._instance = super().__call__(\*args, \*\*kwargs)
return self._instance
class Singleton(metaclass=SigletonMetaClass):
def __new__(cls, *args, **kwargs):
return super().new(cls)
a = Singleton()
b = Singleton()
print(a)
print(b)
执行结果:<main.Singleton object at 0x000001A11E4AC908>
<main.Singleton object at 0x000001A11E4AC908>
因此,用元类实现单例时仍需按照三步骤:1. 拦截 2. 判断是否已经创建过对象 3. 返回对象。与上个方法相比,区别在于拦截的地点不同。
4. 装饰器
4.1 函数装饰器
def SingletonDecorator(cls):
_instance = None
def get\_instance(\*args, \*\*kwargs):
nonlocal _instance
if _instance is None:
_instance = cls(\*args, \*\*kwargs)
return _instance
return get_instance
@SingletonDecorator
class Singleton(object):
pass
a = Singleton()
b = Singleton()
print(a)
print(b)
执行结果:<main.Singleton object at 0x0000022194E6C438>
<main.Singleton object at 0x0000022194E6C438>
4.2 类装饰器
class SingletonDecorator(object):
_instance = None
def \_\_init\_\_(self, cls):
self._cls = cls
def \_\_call\_\_(self, \*args, \*\*kwargs):
if self._instance is None:
self._instance = self._cls(\*args, \*\*kwargs)
return self._instance
@SingletonDecorator
class Singleton(object):
pass
a = Singleton()
b = Singleton()
print(a)
print(b)
执行结果:<main.Singleton object at 0x0000028F42CFC8D0>
<main.Singleton object at 0x0000028F42CFC8D0>
#### 6. 装饰器有什么作用
`装饰器`本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下`增加额外功能`,装饰器的返回值也是一个函数对象。它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。有了装饰器,就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。
#### 7. 打印时间的装饰器
import time
装饰函数
def timer(func):
def wrapper(*args, **kw):
start =time.time()
# 这是函数真正执行的地方
func(*args, **kw)
end =time.time()
cost_time = end - start
print(“花费时间:{}秒”.format(cost_time))
return wrapper
@timer
def want_sleep(sleep_time):
time.sleep(sleep_time)
want_sleep(5)
#### 8. fun(\*args,\*\**kwargs)中的 \*args,*\*\*kwargs什么意思?
`*args`: 用来发送一个非键值对的可变数量的参数列表给一个函数。
`**kwargs`: 用来发送一个可变的键值对的参数给一个函数。
#### 9. python 中的闭包?
**闭包函数** 指定义在一个函数内部的函数,被外层函数包裹着,其特点是可以访问外层函数的变量。
def outer():
num = 1
def inner():
print num # 内层函数可以访问外层函数中的 num
return inner # 外层函数的返回值必须是内层函数
fun = outer()
num = 1
fun() # 1
#### 10. 简述 Python 的作用域以及 Python 搜索变量的顺序
Python作用域简单说就是一个变量的命名空间。代码中变量被赋值的位置,就决定了哪些范围的对象可以访问这个变量,这个范围就是变量的作用域。
在Python中,只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域。
Python的变量名解析机制也称为 LEGB 法则:本地作用域`Local`→当前作用域被嵌入的本地作用域`Enclosing locals`→全局/模块作用域`Global`→内置作用域`Built-in`
#### 11. 简述`__new__`和`__init__`的区别
创建一个新实例时调用 `__new__`,初始化一个实例时用`__init__`,这是它们最本质的区别。
`__new__`方法会返回所构造的对象,`__init__`则不会.
`__new__`函数必须以 **cls** 作为第一个参数,而`__init__`则以 **self** 作为其第一个参数.
例如,构造单例模式:
cls sington():
_instance = None
def __new__(cls):
if cls._instance is None:
cls._instance = super().new(cls)
return cls._instance
#### 12. 双下划线和单下划线的区别?
“**单下划线**”开始的成员变量叫做保护变量,类对象和子类对象都能访问。
“**双下划线**”开始的成员变量叫做私有成员,只有类对象自己能访问,子类对象不能访问。
#### 13. 列出几种魔法方法并简要介绍用途
`__init__`: 对象初始化方法
`__new__`:创建对象时候执行的方法,单列模式会用到
`__str__` : 当使用print输出对象的时候,只要自己定义了\_\_str\_\_(self)方法,那么就会打印从在这个方法中return的数据
`__del__`: 删除对象执行的方法
#### 14. 什么是 python 元类?
在 Python 当中万物皆对象,我们用 class 关键字定义的类本身也是一个对象,负责产生该对象的类称之为元类,元类可以简称为类的类,
元类的主要目的是为了控制类的创建行为.
`type`是 Python 的一个内建元类,用来直接控制生成类,在 python 当中任何 class 定义的类其实都是type 类实例化的结果。
只有继承了 type 类才能称之为一个元类,否则就是一个普通的自定义类,自定义元类可以控制类的产生过程,类的产生过程其实就是元类的调用过程.
### 三. 函数
#### 1. 高阶函数:map() , reduce() , filter() ,lambda()
1.`map()`:遍历序列,根据提供的函数对指定序列做映射,对序列中每个元素进行操作,最终获取新的序列
例1:
print(list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9])))
输出结果:[‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’]
例2:
def square(x):
return x**2
result = list(map(square,[1,2,3,4,5]))
print(result)
输出结果:[1, 4, 9, 16, 25]
备注:map() : Python 2.x 返回列表;Python 3.x 返回迭代器
2.`reduce()`:对于序列内所有元素进行累计操作,即是序列中后面的元素与前面的元素做累积计算
(结果是所有元素共同作用的结果)
from functools import reduce
def addl(x,y):
return x + y
print(reduce(addl,range(1,5)))
输出结果:10
reduce()的作用是接收一个列表,[1,2,3,4]
首先,将1,2传给addl(),计算结果为3
接着,将3,3传给addl(),计算结果为6
接着,将6,4传给addl(),计算结果为10
…
3.`filter()`:过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换
def func(x):
return x%2==0
print(list(filter(func,range(1,6))))
输出结果:[2, 4]
**4.lambda(),匿名函数**,不需要命名的函数def f ( x ,y):
def add(x,y):
return x + y
print(add(1,2))
等效于:
g = lambda x, y : x + y
print(g(1,2))
lambda 表达式的作用:
1. python 写一些执行脚本时,使用 lambda 就可以省下定义函数过程,比如说我们只是需要写个简单的脚本来管理服务器时间,我们就不需要专门定义一个函数然后再写调用,使用 lambda 就可以使得代码更加精简。
2. 对于一些比较抽象并且整个程序执行下来只需要调用一两次的函数,有时候给函数起个名字也是比较头疼的问题,使用 lambda 就不需要考虑命名的问题了。
3. 简化代码的可读性,由于普通的函数阅读经常要跳到开头 def 定义部分,使用 lambda 函数可以省去这样的步骤。
### 四. 底层问题
#### 1. 垃圾回收机制
python 垃圾回收主要以引用计数为主,标记-清除和分代清除为辅的机制,其中标记-清除和分代回收主要是为了处理循环引用的难题。
##### 引用计数
**引用计数算法**
当有1个变量保存了对象的引用时,此对象的引用计数就会加1。
当使用del删除变量指向的对象时,如果对象的引用计数不为1,比如3,那么此时只会让这个引用计数减1,即变为2,当再次调用del时,变为1,如果再调用1次del,此时会真的把对象进行删除。
**引用计数+1的四种情况:**
1. 对象被创建 a=14
2. 对象被引用 b=a
3. 对象被作为参数,传到函数中 func(a)
4. 对象作为一个元素,存储在容器中 List={a,”a”,”b”,2}
**对应的引用计数-1的四种情况:**
1. 当该对象的别名被显式销毁时 del a
2. 当该对象的引别名被赋予新的对象, a=26
3. 一个对象离开它的作用域,例如 func函数执行完毕时,函数里面的局部变量的引用计数器就会减一(但是全局变量不会)
4. 将该元素从容器中删除时,或者容器被销毁时。
**优点:** 简单实时,一旦没有引用,内存就直接释放了。处理回收内存的时间分摊到了平时。
**缺点:** 维护引用计数消耗资源,会造成循环引用导致无法回收,造成`内存泄露`,比如:
list1 = []
list2 = []
list1.append(list2)
list2.append(list1)
‘’’
list1与list2相互引用,即使不存在其他对象对它们的引用,list1与list2的引用计数也
仍然为1,所占用的内存永远无法被回收,这将是致命的。
‘’’
##### 标记清除(Mark—Sweep)
算法是一种基于`追踪回收(tracing GC)`技术实现的垃圾回收算法。
它分为两个阶段:
* 第一阶段是标记阶段,GC会把所有的『活动对象』打上标记,
* 第二阶段是把那些没有标记的对象『非活动对象』进行回收。
**那么GC又是如何判断哪些是活动对象哪些是非活动对象的呢?**
1. 对象之间通过引用(指针)连在一起,构成一个`有向图`,对象构成这个有向图的节点,而引用关系构成这个有向图的边。
2. 从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。
根对象就是全局变量、调用栈、寄存器。
标记清除算法作为Python的辅助垃圾收集技术`主要处理`的是一些容器对象,比如list、dict、tuple,instance等,
因为对于字符串、数值对象是不可能造成循环引用问题。
**缺点:** 清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
##### 分代回收
分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代。
* Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),
* 他们对应的是3个`链表`,它们的垃圾收集频率与对象的存活时间的增大而减小。
* 新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被`触发`,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,
* 依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。
* 同时,分代回收是建立在标记清除技术基础之上。
* 说明**对象存在时间越长,越可能不是垃圾,应该越少去收集**。
* 分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象
#### 2. 赋值,深拷贝,浅拷贝
**浅拷贝**: 拷贝对象的第一层。
**深拷贝**: 拷贝对象的所有层。
说大白话:
B 拷贝于 A
浅拷贝虽然说是拷贝,但也是 “ 身不由己 ” ,当修改除了第一层之外的值时,都会改动(内嵌列表表面上也拷贝过来了,但实际还是不是自己说了算的,只要改了内嵌列表的值,拷贝的也要改,这就是只拷贝一层,内嵌的就无能为力了),当A的第二层改变时,B的第二层也会随之改变。
深拷贝就是彻底的拷贝,两者就再毫无关系,虽然拷贝完不改的话长的一样,但是不管对谁改动,另一个也是毫不受影响。当A的第二层改变时,B的第二层不受影响。
#### 3. 可变对象和不可变对象
什么是可变/不可变对象?
* **不可变对象,该对象所指向的内存中的值不能被改变**,当改变某个变量时候,由于其所指的值不能被改变,相当于把原来的值复制一份后再改变,这会开辟一个新的地址,变量再指向这个新的地址。
* **可变对象,该对象所指向的内存中的值可以被改变**,变量(准确的说是引用)改变后,实际上是其所指的值直接发生改变,并没有发生复制行为,也没有开辟新的出地址,通俗点说就是原地改变。
Python中
**可变对象**:dict、list、set
**不可变对象**:str、int、tuple、float
**附: python函数调用时,参数传递方式是值传递还是引用传递?**
不可变参数: 值传递
可变参数: 引用传递
#### 4. python 传参数是传值还是传址?
Python中函数参数是引用传递(注意不是值传递)。
* 对于不可变类型(数值型、字符串、元组),因变量不能修改,所以运算不会影响到变量自身;
* 对于可变类型(列表、字典)来说,函数体运算可能会更改传入的参数变量。
#### 5. def fun(a, b=[]): 这种写法有什么坑?
def func(a,b=[]):
b.append(a)
print(b)
func(1) # [1]
func(1) # [1, 1]
func(1) # [1, 1, 1]
func(1) # [1, 1, 1, 1]
函数的第二个默认参数是一个list,当第一次执行的时候实例化了一个list,第二次执行还是用第一次执行的时候实例化的地址存储,所以三次执行的结果就是 [1, 1, 1] 。
想每次执行只输出[1] ,b = [] 应该放在函数里面。
#### 6. is 和 == 的区别?
* is 就是判断两个对象的id是否相同
* == 判断的则是内容是否相同
#### 7. 连接字符串用 join 还是 +
字符串是不可变对象。
* 当用操作符`+`连接字符串的时候,每执行一次`+`都会申请一块新的内存,然后复制上一个`+`操作的结果和本次操作的右操作符到这块内存空间,因此用`+`连接字符串的时候会涉及好几次内存申请和复制。
* 而`join`在连接字符串的时候,会先计算需要多大的内存存放结果,然后一次性申请所需内存并将字符串复制过去,这是为什么`join`的性能优于`+`的原因。
* 所以在连接字符串数组的时候,我们应考虑优先使用join。
#### 8. Python 中的复制(赋值),底层是怎么实现的?
Python中,对象的赋值实际上是简单的对象引用。也就是说,当你创建一个对象,然后把它复制给另一个变量的时候,Python并没有拷贝这个对象,而是拷贝了这个对象的引用(指针)。
#### 9. python with 用法+原理剖析
**用法**:with语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会释放资源,比如**文件使用后自动关闭**、**线程中锁的自动获取和释放**等。
with open(“xxx”) as f:
f.write() #文件操作
**原理**: 基本思想是with所求值的对象必须有一个`__enter__()`方法,一个`__exit__()`方法。
紧跟with后面的语句被求值后,`__enter__()`方法的返回值将被赋值给as后面的变量。当with下面的代码块全部被执行完之后,将调用前面返回对象的`__exit__()`方法,对象的`__exit__`要接受三个参数:异常类型、异常对象和异常跟踪。
#### 10. 如何捕获异常,常用的异常机制有哪些?
捕获异常需调用python默认的异常处理器,并在终端输出异常信息。
1. `try...except...finally`语句:当try语句执行时发生异常,回到try语句层,寻找后面是否有except语句。找到except语句后,会调用这个自定义的异常处理器。except将异常处理完毕后,程序继续往下执行。finally语句表示,无论异常发生与否,finally中的语句都要执行。
2. `assert语句`:判断assert后面紧跟的语句是True还是False,如果是True则继续执行print,如果是False则中断程序,调用默认的异常处理器,同时输出assert语句逗号后面的提示信息。
3. `with语句`:如果with语句或语句块中发生异常,会调用默认的异常处理器处理,但文件还是会正常关闭。
#### 11. python 中断言方法举例
assert()方法,断言成功,则程序继续执行,断言失败,则程序报错
a = 3
assert (a > 1)
print(“断言成功,程序继续往下执行”)
b = 4
assert (b > 7)
print(“断言失败,程序报错”)
#### 12. 如何提高 python 的运行效率?
1. 关键代码使用外部功能包(Cython,pylnlne,pypy,pyrex)
2. 针对循环的优化–尽量避免在循环中访问变量的属性
3. 使用较新版本的python
4. 尝试多种编码方法
5. 交叉编译应用程序
### 五. 列表
#### 1. 迭代器和生成器
###### 列表生成式:(还没有放到内存中)
a1 = [x for x in range(1,10)]
a2 = [x**2 for x in range(1,10)]
也可以放一个函数:
def f(n):
return n**3
a3 = [f(x) for x in range(1,10)]
###### 生成器:
**背景**:通过列表生成式,我们可以直接创建一个列表,但是,受到内存限制,列表容量肯定是有限的,而且创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间,在Python中,这种一边循环一边计算的机制,称为生成器:generator
**定义**: 在Python中,这种一边循环一边计算的机制,称为生成器:generator 。
**说明**:生成器是一个特殊的程序,可以被用作控制循环的迭代行为,python中生成器是迭代器的一种,使用yield返回值函数,每次调用yield会暂停,而可以使用next()函数和send()函数恢复生成器。
**两种创建方式**:
1. (x\*2 for x in range(5,100)) # 此处注意区分列表生成式
2. yield
其中:
* 生成器表达式:返回一个对象,这个对象只有在需要的时候才产生结果
* 生成器函数:也是用def定义的,利用关键字yield(相当于return)一次性返回一个结果,阻塞,重新开始
为了节省空间,生成器生成的数据并没有放到内存中,只有在调取的时候才往内存中放。
只能从前往后逐一调取。
next() 返回迭代器的下一个项目
a = (x2 for x in range(5,100)) #元组
print(next(a)) #将5返回给x2 10
用生成器来实现斐波那契数列的例子是:
def fib(max):
a, b = 0, 1
while max > 0:
a, b = b, a + b
yield a
max -= 1
print([i for i in fib(10)])
f.send() 和 next() 的区别:
* f.send(),将参数传给yield前一个变量,也就是说send()可以强行修改上一个yield的值;
* next()参数是迭代器函数名字;
* 第一个send()不可传值,写作f.send(None),相当于next(b)。
###### 迭代器
**定义**:任何实现了\_\_iter\_\_和\_\_next\_\_()方法的对象都是迭代器(这是迭代器协议),\_\_iter\_\_返回迭代器自身,\_\_next\_\_返回容器中的下一个值,直到容器中没有更多元素时抛出StopIteration异常并停止迭代。
迭代就是循环,它是一个带状态的对象,能在你调用next()方法的时候返回容器中的下一个值。
迭代器就像一个懒加载的工厂,等到有人需要的时候,它才会生成值并返回,没调用的时候就处于休眠状态等待下一次调用。
###### 生成器与迭代器的区别
* 迭代器(iterator)是一个实现了迭代器协议(**iter\_\_和\_\_next**()方法)的对象。
* 生成器(generator)是通过**yield**语句或**生成器函数**快速生成迭代器,可以不用iter和next方法 。
* 生成器本质上也是一个迭代器,自己实现了可迭代协议,与迭代器不同的是生成器的实现方式不同,可以通过生成器表达式和生成器函数两种方式实现,代码更简洁。
* 生成器和迭代器都是惰性可迭代对象,只能遍历一次,数据取完抛出Stopiteration异常
###### 什么是可迭代对象?
我们已经知道,可以直接作用于for循环的数据类型有以下几种:
* 一类是集合数据类型,如list,tuple,dict,set,str等
* 一类是generator,包括生成器表达式和生成器函数
**定义**:实现了\_\_iter\_\_方法的对象就叫做可迭代对象。说白了就是可以直接作用于for 循环的对象统称为可迭代对象:Iterable
**区别**:一个可迭代的对象必须是定义了\_\_iter\_\_()方法的对象;而一个迭代器必须是同时定义了\_\_iter\_\_()方法和next()方法的对象。
**for函数的本质**:在python3中,就是不断调用next() 方法实现for循环。
x = [1,2,3]
for i in x:
print(i)
实际执行情况:
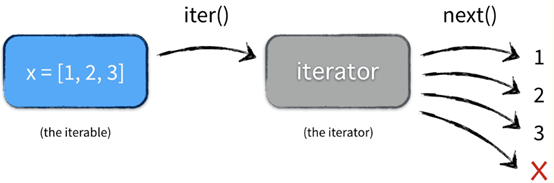
等价于:
首先获得Iterator对象:
iterator = iter([1, 2, 3])
循环:
while True:
try:
# 获得下一个值:
x = next(iterator)
print(x)
except StopIteration:
# 遇到StopIteration就退出循环
break
总结:
* 凡是可作用于for循环的对象都是可迭代对象;
* 凡是可作用于next()函数的对象都是迭代器,它们表示一个惰性计算的序列;
* 集合数据类型如list、dict、str等是可迭代对象,但不是迭代器,不过可以通过iter()方法获得一个Iterator对象;
* 文件是可迭代对象,也是迭代器。
**你可能会问,为什么list、dict、str等数据类型不是迭代器?**
这是因为Python的迭代器对象表示的是一个数据流,可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
迭代器甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
list,str,dict…这些可迭代的对象你可以随意的读取所以非常方便易用,但是**你必须把它们的值放到内存里,当它们有很多值时就会消耗太多的内存。**
**如何判断是可迭代对象还是迭代器?如何把可迭代对象转换为迭代器?**
from collections import Iterator # 迭代器
from collections import Iterable # 可迭代对象
s = ‘hello’
print(isinstance(s, Iterator)) # 判断是不是迭代器
print(isinstance(s, Iterable)) # 判断是不是可迭代对象
print(isinstance(iter(s), Iterator)) # 把可迭代对象转换为迭代器 iter(s)
#### 2. sorted() 函数
‘’’
sorted(iterable, cmp=None, key=None, reverse=False)
iterable – 可迭代对象。
cmp – 比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
key – 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse – 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
‘’’
#### 3. 现有字典 dict = {‘a’ : 24, ‘d’ : 55, ‘kj’ : 86},请按照字段中的的value值进行排序
dict = {‘a’: 24, ‘d’: 55, ‘kj’: 30}
按照 value 进行排序
new_dict1 = sorted(dict.items(), key=lambda c: c[1])
print new_dict1
按照 key 进行排序
new_dict2 = sorted(dict.items(), key=lambda c: c[0])
print new_dict2
#### 4. 现有列表 list=[{‘name’: ‘a’, ‘age’: 24}, {‘name’: ‘d’, ‘age’: 55}, {‘name’: ‘c’, ‘age’: 67}],请按照 age 进行从大到小排序
list = [{‘name’: ‘a’, ‘age’: 24}, {‘name’: ‘d’, ‘age’: 55}, {‘name’: ‘c’, ‘age’: 32}]
new_list1 = sorted(list, key=lambda c: c[‘age’], reverse=True)
print new_list1
#### 5. 下面代码输出结果是?
list = [1, 2, 3, 4, 5]
print list[10:]
‘’’
代码输出空列表[], 并不会出现 IndexError
‘’’
print list[10]
‘’’
IndexError: list index out of range
‘’’
#### 6. 修改列表时,如何保证地址不变?
**若要维持地址不变,需要加上[:]**
l = [1, 2, 3]
print id(l) # 52733960
l = [2, 3]
print id(l) # 52661384
l[:] = [3]
print id(l) # 52661384
#### 7.列表和元组的区别
**区别:**
* **语法差异**:使用方括号 [ ] 创建列表,而使用括号 ( ) 创建元组
* **是否可变**:列表是可变的,而元组是不可变的。可以修改列表的值,但是不修改元组的值。
* **重用与拷贝**:元组无法复制。 原因是元组是不可变的。 如果运行tuple(tuple\_name)将返回自己。
**相同点:**
* 都是序列
* 都可以存储任何数据类型
* 可以通过索引访问
**什么时候用元组什么时候用列表?**
* 不确定元素可以用列表
* 确定元素的用元组。
### 六. 常用模块
#### **time 模块**:从1970年开始
time.time() #记录当前时间戳 1556723770.0009158
time.sleep(3) #延迟3秒钟
time.localtime() #结构化时间(本地)
time.strftime(‘%Y-%m-%d %H:%M:%S’) #自定义时间格式2019-05-01 23:05:45
time.mktime(time.localtime()) #将本地时间转化为时间戳
datetime 模块
datetime.datetime.now() #2019-05-01 23:18:38.512192
#### **random 模块**
import random
random.random() # 生成一个0到1的随机数 0.758108354250769
random.randint(1, 8) # 生成一个0到8的随机整数 4
random.choice({}/[]/()/‘’) # 从一个对象中随机选择一个元素
random.randrang(1, 3) # 从1到3中随机取一个整数(不包括3)
#### **os 模块**:与操作系统进行交互
import os
os.getcwd() # 获取当前工作目录
os.chdir() # 更改当前工作目录 change
os.makedirs(‘dirname1/dirname2’) # 可生成多层递归目录
os.removedirs() #(递归)删除空文件夹
os.mkdir(‘dirname’) # 生成一个文件夹
os.rmdir(‘dirname’) # 删除一个空文件夹,若文件不为空,报错
os.remove() #只能删除文件,不能删除文件夹
os.listdir(“G:\python”) # 显示出目录下的所有文件
os.rename(‘oldname’,‘newname’) # 改变文件夹名称
os.path.dirname(‘./abc’) # 返回abc所在的文件的路径
os.path.exists(path) # 如果path存在,返回Ture
os.path.join(path1,path2,) # 将多个路径合并并返回
#### **sys 模块**:与 python 解释器进行交互
sys.argv
sys.argv[]说白了就是一个从程序外部获取参数的桥梁。因为我们从外部取得的参数可以是多个,所以获得的是一个列表(list),也就是说sys.argv其实可以看作是一个列表,所以才能用[]提取其中的元素。其第一个元素是程序本身,随后才依次是外部给予的参数。
Sys.argv[ ]其实就是一个列表,里边的项为用户输入的参数,关键就是要明白这参数是从程序外部输入的,而非代码本身的什么地方,要想看到它的效果就应该将程序保存了,从外部来运行程序并给出参数。
#### hashlib 模块:提供了很多加密的算法
这里介绍一下hashlib的简单使用事例,用hashlib的md5算法加密数据
加密算法的转化结果是唯一的,不会改变。(唯一性)
import hashlib
def md5(arg): # 这是加密函数,将传进来的函数加密
md5_pwd = hashlib.md5(bytes(‘abd’, encoding=‘utf-8’))
md5_pwd.update(bytes(arg, encoding=‘utf-8’))
return md5_pwd.hexdigest() # 返回加密后的数据(十六进制)
def log(user, pwd): # 登陆时候的函数,由于md5不能反解,因此登陆的时候用正解
with open(‘db’, ‘r’, encoding=‘utf-8’) as f:
for line in f:
u, p = line.strip().split(‘|’)
if u == user and p == md5(pwd): # 登陆的时候验证用户名以及加密的密码跟之前保存的是否一样
return True
def register(user, pwd): # 注册的时候把用户名和加密的密码写进文件,保存起来
with open(‘db’, ‘a’, encoding=‘utf-8’) as f:
temp = user + ‘|’ + md5(pwd)
f.write(temp)
i = input(‘1表示登陆,2表示注册:’)
if i == ‘2’:
user = input(‘用户名:’)
pwd = input(‘密码:’)
register(user, pwd)
elif i == ‘1’:
user = user = input(‘用户名:’)
pwd = input(‘密码:’)
r = log(user, pwd) # 验证用户名和密码
if r == True:
print(‘登陆成功’)
else:
print(‘登陆失败’)
else:
print(‘账号不存在’)
#### logging 模块:输出日志

import logging
1.创建一个logger
logger = logging.getLogger() # get一个Logger对象,日志对象
logger.setLevel(logging.INFO) # Log等级总开关
2.创建一个handler,用于写入日志文件
fh = logging.FileHandler(‘txt’) # 用于写入文件,文件对象
fh.setLevel(logging.DEBUG) # 输出到file的log等级的开关
3.创建一个handler,用于输出控制台
ch = logging.StreamHandler() # 输出控制台,屏幕对象
ch.setLevel(logging.WARNING) # 输出到console的log等级的开关
4.定义handler的输出格式
formatter = logging.Formatter(“%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s”)
fh.setFormatter(formatter) # fh创建格式,和formatter一样
ch.setFormatter(formatter) # ch创建格式,和formatter一样
5.控制输出
logger.addHandler(fh) # 输出文件
logger.addHandler(ch) # 输出控制台
6.日志
logger.debug(‘this is a logger debug message’)
logger.info(‘this is a logger info message’)
logger.warning(‘this is a logger warning message’)
logger.error(‘this is a logger error message’)
logger.critical(‘this is a logger critical message’)
#### json 模块
json.dumps() # 字典转json字符串
json.loads() # json字符串转字典
#### re 模块:正则表达式
##### 1. 限定符
| 字符 | 描述 |
| --- | --- |
| \* | 匹配前面的子表达式零次或多次。\* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。? 等价于 {0,1}。 例如,`do(es)?` 可以匹配 `do` 、 `does` 中的 `does` 、 `doxy` 中的 `do` 。 |
| ^ | 1.匹配输入字符串的开始位置 2.在[ ]中使用时,表示不匹配[ ]中的字符集合。 |
| $ | 匹配输入字符串的结尾位置。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。 例如,`o{2}` 不能匹配 `Bob` 中的 `o`,但是能匹配 `food`中的`oo`。 |
| {n,} | n 是一个非负整数。至少匹配n 次。 例如,`o{2,}` 不能匹配 `Bob` 中的 `o`,但能匹配 `foooood` 中的所有 `oooooo`。‘o{1,}’ 等价于 ‘o+’。‘o{0,}’ 则等价于 ‘o\*’。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 例如,`o{1,3}`将匹配 `fooooood` 中的前三个 `ooo`。‘o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
| ( ) | 标记一个子表达式的开始和结束位置。即分组匹配。 |
| [ ] | 符合 [ ]中的任一字符就匹配。例如,`a[bcd]f`可以匹配`acf`, 但不能匹配`agf` |
| | | 指明两项之间的一个选择。例如,`s |
##### 2. 预定义字符
| 字符 | 描述 | 规则 | 结果 |
| --- | --- | --- | --- |
| \d | \d匹配任何十进制数,它相当于类[0-9] \d+如果需要匹配一位或者多位数的数字时用 | a\dc | a1c |
| \D | \D匹配任何非数字字符,它相当于类[ ^0-9 ] | a\Dc | abc |
| \s | \s匹配任何空白字符,它相当于类[\t\n\r\f\v] | a\sc | a c |
| \S | \S匹配任何非空白字符,它相当于类[ ^\t\n\r\f\v ] | a\Sc | abc |
| \w | \w匹配包括下划线在内任何字母数字字符,它相当于类[a-zA-Z0-9\_] | a\wc | abc |
| \W | \W匹配非任何字母数字字符包括下划线在内,它相当于类[ ^a-zA-Z0-9\_ ] | a\Wc | a c |
##### 3. 常用函数
>
> re.findall() 匹配所有符合规则的字符串
>
>
>
语法:
findall(pattern, string, flags=0)
pattern: 正则模型
string : 要匹配的字符串
falgs : 匹配模式
>
> re.match() 从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
>
>
>
语法:
match(pattern, string, flags=0)
pattern: 正则模型
string : 要匹配的字符串
falgs : 匹配模式
>
> re.search() 浏览全部字符串,直到匹配出第一个符合规则的字符串
>
>
>
语法:
search(pattern, string, flags=0)
pattern: 正则模型
string : 要匹配的字符串
falgs : 匹配模式
**注意:search()和match()的区别**
**match() 从第一个字符开始匹配, 如果第一个字符不匹配就返回None, 不再继续匹配。**
**search() 在整个字符串查找,直到找到一个匹配的字符。**
>
> re.split() 根据正则匹配分割字符串,返回分割后的一个列表
>
>
>
语法:
split(pattern, string, maxsplit=0, flags=0)
pattern: 正则模型
string : 要匹配的字符串
maxsplit:指定分割个数
flags : 匹配模式
>
> re.sub() 替换匹配成功的指定位置字符串
>
>
>
语法:
sub(pattern, repl, string, count=0, flags=0)
pattern: 正则模型
repl : 要替换的字符串
string : 要匹配的字符串
count : 指定匹配个数
flags : 匹配模式
###### 问题:正则表达式匹配中,(.\*)和(.\*?)匹配区别?
(.\*)是贪婪匹配,会把满足正则的尽可能多的往后匹配
(.\*?)是非贪婪匹配,会把满足正则的尽可能少匹配
import re
s = “哈哈呵呵呵”
res1 = re.findall(“(.*)”,s)
print(“贪婪匹配”, res1)
res2 = re.findall(“(.*?)”,s)
print(“非贪婪匹配”, res2)
运行结果:贪婪匹配 [‘哈哈呵呵呵’]
非贪婪匹配 [‘哈哈’, ‘呵呵呵’]
### 七. 常见问题
#### 1. 时间复杂度
**如何推导出时间复杂度呢?有如下几个原则:**
1. 如果运行时间是常数量级,用常数1表示;
2. 只保留时间函数中的最高阶项;
3. 如果最高阶项存在,则省去最高阶项前面的系数。
**场景1:T(n) = 3n,执行次数是线性的,T(n) = O(n)**
void eat1(int n){
for(int i=0; i<n; i++){;
System.out.println(“等待一天”);
System.out.println(“等待一天”);
System.out.println(“吃一寸面包”);
}
}
**场景2:T(n) = 5logn,执行次数是对数的,T(n) = O(log n)**
void eat2(int n)
for(int i=1; i<n; i*=2){
System.out.println(“等待一天”);
System.out.println(“等待一天”);
System.out.println(“等待一天”);
System.out.println(“等待一天”);
System.out.println(“吃一半面包”);
}
}
**场景3:T(n) = 2,执行次数是常量的, T(n) = O(1)**

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
题:正则表达式匹配中,(.*)和(.*?)匹配区别?
(.*)是贪婪匹配,会把满足正则的尽可能多的往后匹配
(.*?)是非贪婪匹配,会把满足正则的尽可能少匹配
import re
s = "<a>哈哈</a><a>呵呵呵</a>"
res1 = re.findall("<a>(.\*)</a>",s)
print("贪婪匹配", res1)
res2 = re.findall("<a>(.\*?)</a>",s)
print("非贪婪匹配", res2)
运行结果:贪婪匹配 ['哈哈</a><a>呵呵呵']
非贪婪匹配 ['哈哈', '呵呵呵']
七. 常见问题
1. 时间复杂度
如何推导出时间复杂度呢?有如下几个原则:
- 如果运行时间是常数量级,用常数1表示;
- 只保留时间函数中的最高阶项;
- 如果最高阶项存在,则省去最高阶项前面的系数。
场景1:T(n) = 3n,执行次数是线性的,T(n) = O(n)
void eat1(int n){
for(int i=0; i<n; i++){;
System.out.println("等待一天");
System.out.println("等待一天");
System.out.println("吃一寸面包");
}
}
场景2:T(n) = 5logn,执行次数是对数的,T(n) = O(log n)
void eat2(int n)
for(int i=1; i<n; i\*=2){
System.out.println("等待一天");
System.out.println("等待一天");
System.out.println("等待一天");
System.out.println("等待一天");
System.out.println("吃一半面包");
}
}
场景3:T(n) = 2,执行次数是常量的, T(n) = O(1)
[外链图片转存中...(img-ldvIOaxl-1715637788933)]
[外链图片转存中...(img-b0h0sImt-1715637788934)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618658159)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









