







HarmonyOS应用的UI操作必须在主线程执行(如修改UI控件,更新视图这些操作必须在UI线程中进行),如果主线程出现阻塞,那么UI界面就会出现明显的卡顿。因此为了解决此类问题,我们需要将一些耗时的操作例如加载网络数据、查询本地文件、数据等放到子线程中,以提升应用的响应速度和性能。
多线程能力介绍
进程与线程
在单线程中执行的代码都是串行的,即按顺序执行,直到执行完成后,程序才会退出。当程序需要执行多个任务时,每个任务必须等待前一个任务执行完成后才能继续执行,这使得程序的性能非常低下。多线程技术通过使用多个线程来充分利用CPU资源,同时执行多个任务,从而提高程序执行的效率。每个线程都是相互独立的,并能够单独执行、暂停、继续和停止。进程(Process):是操作系统进行资源分配的最小单元。线程(Thread):是操作系统进行运算调度的最小单元,它被包含在进程之中,是进程中的实际运作单位。
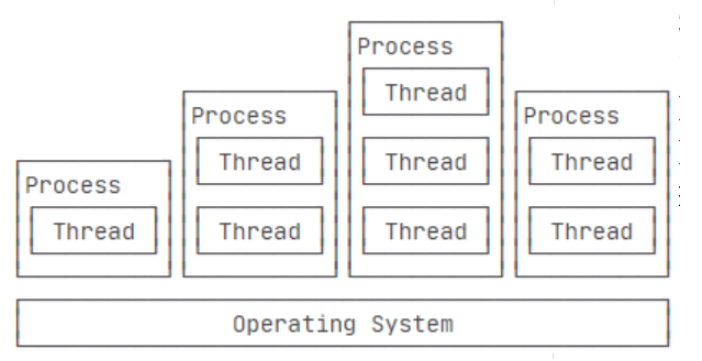
多线程的使用场景
多线程的应用场景包括但不限于以下场景:
-
CPU密集型:数据处理、图像处理。当需要大量的数据处理时,可以使用多线程,以提高处理效率
-
I/O密集型:文件读写、网络请求。当需要发起大量的I/O请求时,可以使用多线程,以避免卡主线
-
后台任务:自动化作业处理,比如需要定期完成特定任务。
ArkTS的多线程解决方案
在HarmonyOS的ArkTS侧为多线程提供了两种方式:TaskPool和Worker,应用可以结合自身业务诉求,选择对应的实现方案。
TaskPool简介
任务池(TaskPool)作用是为应用程序提供一个多线程的运行环境,降低整体资源的消耗、提高系统的整体性能,且开发者无需关心线程实例的生命周期。TaskPool提供了多种不同的任务能力:
| 能力 |
任务构建 |
任务执行 |
场景描述 |
| 普通任务 |
new taskpool.Task() |
taskpool.execute() |
立即执行的短时任务,耗时不能超过3分钟。 |
| 延时任务 |
new taskpool.Task() |
taskpool.executeDelayed() |
为了不影响应用启动的性能,一些不影响启动的初始化类任务往往期望放在延时任务中执行,如拉取线上的配置信息等。 |
| 长时任务 |
new taskpool.LongTask() |
taskpool.execute() |
希望长时运行的任务一直保持执行,已为其他模块提供特定的服务,比如日志埋点,后台长链接保活等。 |
| 串行任务 |
new taskpool.SequenceRunner(),new taskpool.Task() |
SequenceRunner. execute() |
用于执行一组需要串行执行的任务 |
| 依赖任务 |
task1.addDependency(task2), task1.removeDependency(task2) |
taskpool.execute() |
任务之间存在先后依赖关系 |
| 任务的优先级设置 |
待支持 |
待支持 |
在应用运行时,期望可以给设置空闲时任务,当应用处于闲时(比如冷启动完成后停留在首页)做一些相应的预加载动作(如预加载其他页面),从而提升应用整体性能。 |
TaskPool注意事项
-
实现任务的函数需要使用装饰器@Concurre
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









