













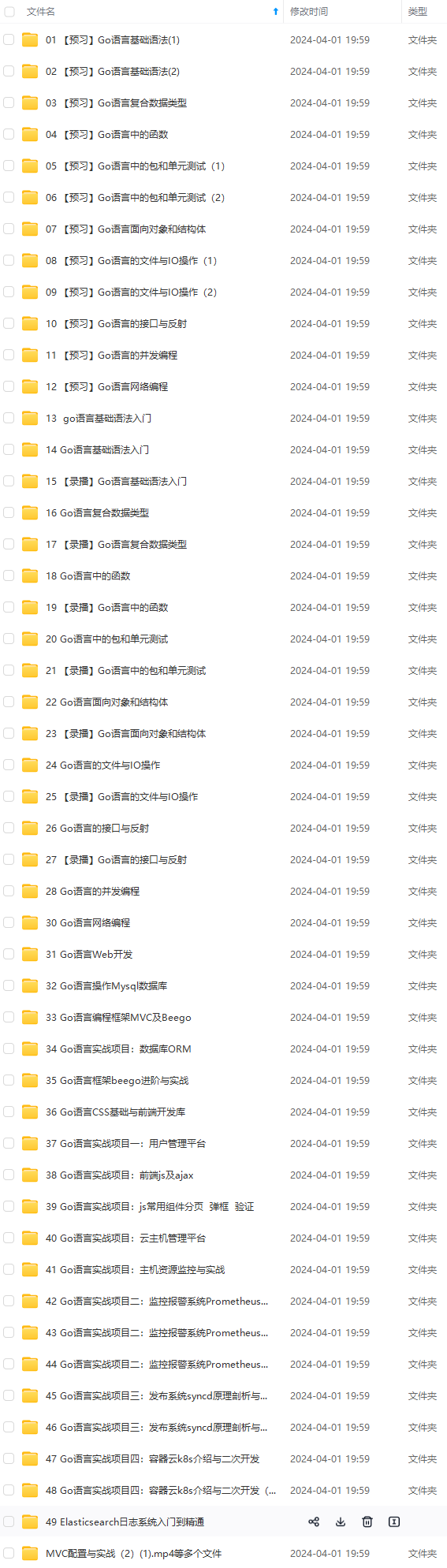
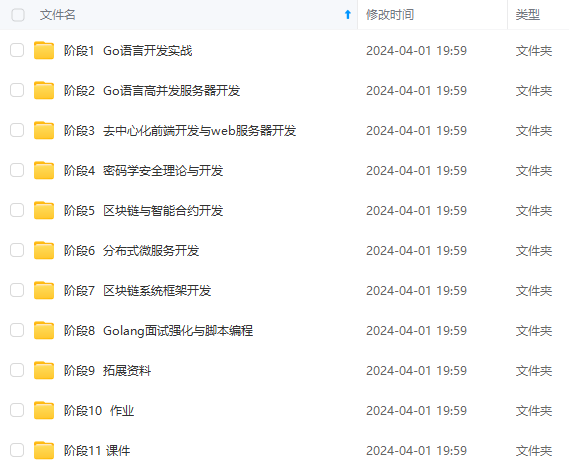
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
(2) 运行各类任务的Container:这是由ApplicationMaster向ResourceManager申请的,并由ApplicationMaster与NodeManager通信以启动之。
以上两类Container可能在任意节点上,它们的位置通常而言是随机的,即ApplicationMaster可能与它管理的任务运行在一个节点上。
整个MapReduce的过程大致分为 Map–>Shuffle(排序)–>Combine(组合)–>Reduce
下面通过一个单词计数案例来理解各个过程
1)将文件拆分成splits(片),并将每个split按行分割形成<key,value>对,如图所示。这一步由MapReduce框架自动完成,其中偏移量即key值

分割过程
将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对,如下图所示。

执行map方法
得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行Shuffle(排序),并执行Combine过程,将key至相同value值累加,得到Mapper的最终输出结果。如下图所示。

Map端排序及Combine过程
Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为WordCount的输出结果,如下图所示。

Reduce端排序及输出结果
下面看怎么用Java来实现WordCount单词计数的功能
首先看Map过程
Map过程需要继承org.apache.hadoop.mapreduce.Mapper包中 Mapper 类,并重写其map方法。
/**
* Mapper<LongWritable, Text, Text, IntWritable>中 LongWritable,IntWritable是Hadoop数据类型表示长整型和整形
*
* LongWritable, Text表示输入类型 (比如本应用单词计数输入是 偏移量(字符串中的第一个单词的其实位置),对应的单词(值))
* Text, IntWritable表示输出类型 输出是单词 和他的个数
* 注意:map函数中前两个参数LongWritable key, Text value和输出类型不一致
* 所以后面要设置输出类型 要使他们一致
*/
//Map过程
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/***
*
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
//默认的map的value是每一行,我这里自定义的是以空格分割
String[] vs = value.toString().split("\\s");
for (String v : vs) {
//写出去
context.write(new Text(v), ONE);
}
}
}
Reduce过程
Reduce过程需要继承org.apache.hadoop.mapreduce包中 Reducer 类,并 重写 其reduce方法。Map过程输出<key,values>中key为单个单词,而values是对应单词的计数值所组成的列表,Map的输出就是Reduce的输入,所以reduce方法只要遍历values并求和,即可得到某个单词的总次数。
//Reduce过程
/***
* Text, IntWritable输入类型,从map过程获得 既map的输出作为Reduce的输入
* Text, IntWritable输出类型
*/
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count=0;
for(IntWritable v:values){
count+=v.get();//单词个数加一
}
context.write(key, new IntWritable(count));
}
}
最后执行MapReduce任务
public static void main(String[] args) {
Configuration conf=new Configuration();
try {
//args从控制台获取路径 解析得到域名
String[] paths=new GenericOptionsParser(conf,args).getRemainingArgs();
if(paths.length<2){
throw new RuntimeException("必須輸出 輸入 和输出路径");
}
//得到一个Job 并设置名字
Job job=Job.getInstance(conf,"wordcount");
//设置Jar 使本程序在Hadoop中运行
job.setJarByClass(WordCount.class);
//设置Map处理类
job.setMapperClass(WordCountMapper.class);
//设置map的输出类型,因为不一致,所以要设置
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置Reduce处理类
job.setReducerClass(WordCountReducer.class);
//设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(paths[0]));
FileOutputFormat.setOutputPath(job, new Path(paths[1]));
//启动运行
System.exit(job.waitForCompletion(true) ? 0:1);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
即可求得每个单词的个数
下面把整个过程的源码附上,有需要的朋友可以拿去测试
package hadoopday02;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
//计数变量
private static final IntWritable ONE = new IntWritable(1);
/**
*
* @author 汤高
* Mapper<LongWritable, Text, Text, IntWritable>中 LongWritable,IntWritable是Hadoop数据类型表示长整型和整形
*
* LongWritable, Text表示输入类型 (比如本应用单词计数输入是 偏移量(字符串中的第一个单词的其实位置),对应的单词(值))
* Text, IntWritable表示输出类型 输出是单词 和他的个数
* 注意:map函数中前两个参数LongWritable key, Text value和输出类型不一致
* 所以后面要设置输出类型 要使他们一致
*/
//Map过程
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/***
*
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
//默认的map的value是每一行,我这里自定义的是以空格分割
String[] vs = value.toString().split("\\s");
for (String v : vs) {
//写出去
context.write(new Text(v), ONE);
}
}
}
//Reduce过程
/***
* Text, IntWritable输入类型,从map过程获得 既map的输出作为Reduce的输入
* Text, IntWritable输出类型
*/
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count=0;
for(IntWritable v:values){
count+=v.get();//单词个数加一
}
context.write(key, new IntWritable(count));
}
}
public static void main(String[] args) {
Configuration conf=new Configuration();
try {
//args从控制台获取路径 解析得到域名
String[] paths=new GenericOptionsParser(conf,args).getRemainingArgs();
if(paths.length<2){
throw new RuntimeException("必須輸出 輸入 和输出路径");
}
//得到一个Job 并设置名字
Job job=Job.getInstance(conf,"wordcount");
//设置Jar 使本程序在Hadoop中运行
job.setJarByClass(WordCount.class);
//设置Map处理类
job.setMapperClass(WordCountMapper.class);
//设置map的输出类型,因为不一致,所以要设置
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置Reduce处理类
job.setReducerClass(WordCountReducer.class);
//设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(paths[0]));
FileOutputFormat.setOutputPath(job, new Path(paths[1]));
//启动运行
System.exit(job.waitForCompletion(true) ? 0:1);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
二、通过 Hadoop 建立倒排索引
倒排索引就是根据单词内容来查找文档的方式,由于不是根据文档来确定文档所包含的内容,进行了相反的操作,所以被称为倒排索引, 它是搜索引擎最为核心的数据结构,以及文档检索的关键部分。
下面来看一个例子来理解什么是倒排索引
这里我准备了两个文件 分别为1.txt和2.txt
1.txt的内容如下
I Love Hadoop
I like ZhouSiYuan
I love me
2.txt的内容如下
I Love MapReduce
I like NBA
I love Hadoop
我这里使用的是默认的输入格式TextInputFormat,他是一行一行的读的,键是偏移量。
所以在map阶段之前的到结果如下
map阶段从1.txt的得到的输入
0 I Love Hadoop
15 I like ZhouSiYuan
34 I love me
map阶段从2.txt的得到的输入
0 I Love MapReduce
18 I like NBA
30 I love Hadoop
map阶段
把词频作为值
把单词和URI组成key值
比如
key : I+hdfs://192.168.52.140:9000/index/2.txt value:1
为什么要这样设置键和值?
因为这样设计可以使用MapReduce框架自带的map端排序,将同一单词的词频组成列表
经过map阶段1.txt得到的输出如下
I:hdfs://192.168.52.140:9000/index/1.txt 1
Love:hdfs://192.168.52.140:9000/index/1.txt 1
MapReduce:hdfs://192.168.52.140:9000/index/1.txt 1
I:hdfs://192.168.52.140:9000/index/1.txt 1
Like:hdfs://192.168.52.140:9000/index/1.txt 1
ZhouSiYuan:hdfs://192.168.52.140:9000/index/1.txt 1
I:hdfs://192.168.52.140:9000/index/1.txt 1
love:hdfs://192.168.52.140:9000/index/1.txt 1
me:hdfs://192.168.52.140:9000/index/1.txt 1
经过map阶段2.txt得到的输出如下
I:hdfs://192.168.52.140:9000/index/2.txt 1
Love:hdfs://192.168.52.140:9000/index/2.txt 1
MapReduce:hdfs://192.168.52.140:9000/index/2.txt 1
I:hdfs://192.168.52.140:9000/index/2.txt 1
Like:hdfs://192.168.52.140:9000/index/2.txt 1
NBA:hdfs://192.168.52.140:9000/index/2.txt 1
I:hdfs://192.168.52.140:9000/index/2.txt 1
love:hdfs://192.168.52.140:9000/index/2.txt 1
Hadoop:hdfs://192.168.52.140:9000/index/2.txt 1
1.txt经过MapReduce框架自带的map端排序得到的输出结果如下
I:hdfs://192.168.52.140:9000/index/1.txt list{1,1,1}
Love:hdfs://192.168.52.140:9000/index/1.txt list{1}
MapReduce:hdfs://192.168.52.140:9000/index/1.txt list{1}
Like:hdfs://192.168.52.140:9000/index/1.txt list{1}
ZhouSiYuan:hdfs://192.168.52.140:9000/index/1.txt list{1}
love:hdfs://192.168.52.140:9000/index/1.txt list{1}
me:hdfs://192.168.52.140:9000/index/1.txt list{1}
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618658159)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
:9000/index/1.txt list{1}
me:hdfs://192.168.52.140:9000/index/1.txt list{1}
[外链图片转存中...(img-HKGpi1jk-1715903036375)]
[外链图片转存中...(img-etSyhSl8-1715903036376)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618658159)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 564
564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









