






目录
六、BeautifulSoup库
1、常见的提取分析网页内容的三种方式
(1)正则表达式
Python自带的re库中的正则表达式,对于网页内容的提取分析非常方便,而且速度极快,但是适应性较差,可能面对不同的页面,正则表达式就需要修改
(2)BeautifulSoup库
速度和正则表达式接近,但是还是没有正则表达式快
(3)pyppeteer库中的元素查找函数
速度较慢(约是正则表达式的百分之一)
2、HTML中的tag
当我们随机打开一个页面,右键页面空白处,然后点击检查,我们就可以看到一个网页的源码,而在源码中,我们会发现源码中包含很多的尖括号,即“<>”,这就是一个tag
大部分的tag都包含<x>和</x>,只有极少数的只有一个<x>(这里的x就是tag的名字)
当然,tag也可以嵌套,即一个tag里面包含另一个tag
不同的tag可能会包含不同的功能,而有的tag里面会包含一些属性,或者一些网站的路径(href,src等),我们可以根据某些特定的tag或者属性,来定位到,查找到我们想要的内容
3、BeautifulSoup库的安装和导入
我们使用pip命令来安装BeautifulSoup库
pip install beautifulsoup4在Python中,我们需要这样导入BeautifulSoup库:
import bs44、BeautifulSoup库分析过程
①先把HTML文档装入一个BeautifulSoup对象中
②针对对象,我们使用find或者find_all等函数找到我们想要的tag
③找到tag后,可以再次使用find或者find_all等函数去找内部嵌套的tag或者相关的内容
5、利用BeautifulSoup库分析HTML
我们先创建一个HTML文档
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<h1>这是一个网页</h1>
<a href="https://www.baidu.com">点我进入百度</a>
<a href="https://www.google.com">点我进入谷歌</a>
</body>
</html>再在其当前文件创建一个py文件:
import bs4
Soup = bs4.BeautifulSoup(open(r"D:\学习\Python\001.html" , "r" , encoding = "utf-8") , "html.parser")
#"html.parser" 是一个解析器的名称,用于解析 HTML 文档
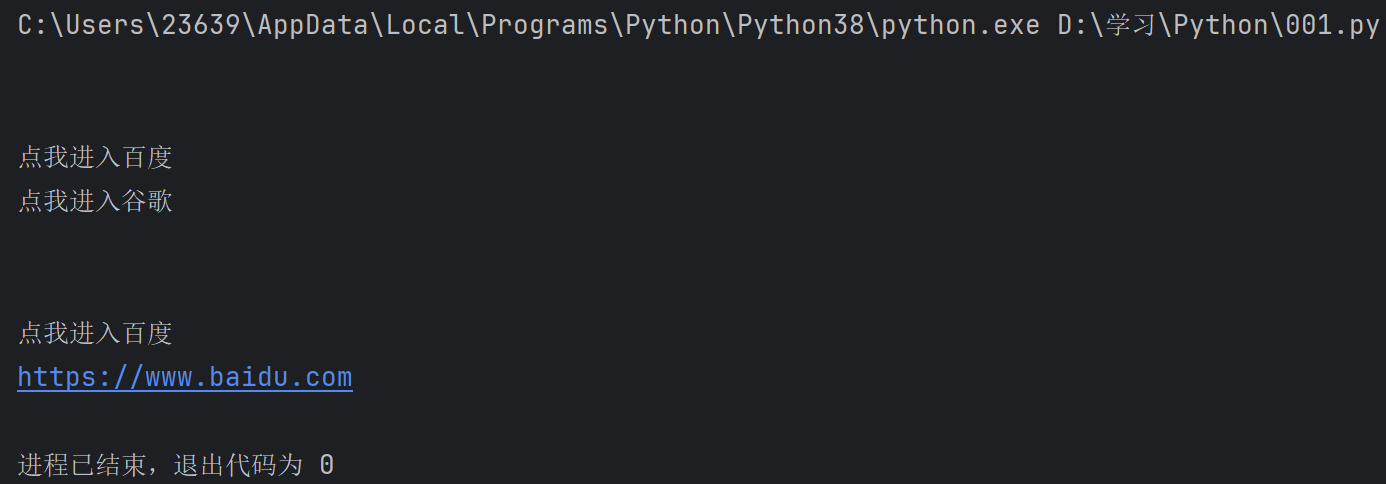
tags = Soup.find_all("a") #如果只想输出第一个,就是用find函数
for tag in tags :
print(tag.text)
输出:

当然,我们可以把第一行换成一个字符串,字符串里面包含一个HTML文档,也可以指定一个网址,用getHTML()
6、BeautifulSoup库进阶
上面的代码只是寻找一个tag的内容或者输出所有名字为x的一类tag,上面提到tag是可以嵌套的,而且tag拥有可以拥有很多属性(比如class,id等)那么我们怎么在众多的属性中和嵌套中找到我们想要的结果:
HTML代码:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>test</title>
</head>
<body>
<span id="css">
<p>这是一个p标签</p>
</span>
<span id="html">
<div class="p1">这是一个div标签1</div>
<div class="p2">这是一个div标签2</div>
<div class="p3">这是一个div标签3</div>
<div class="p4">
<scy class="scy" id="hello">
<a class="one" href="https://www.baidu.com">点我进入百度</a>
<a class="two" href="https://www.google.com">点我进入谷歌</a>
</scy>
</div>
</span>
</body>
</html>Python代码:
import bs4
soup = bs4.BeautifulSoup(open(r"D:\学习\Python\001.html" , encoding = "utf-8") , "html.parser")
#打开文件并读取内容
diva = soup.find("span" , attrs = {"id" : "html"})
#先寻找一个id是html的span标签
if diva != None : #如果有符合要求的
for x in diva.find_all("div" , attrs = {"class" : "p4"}) : #再在里面找有没有class是p4的div标签
print(x.text)
if x != None : #这里x就是class是p4的div标签,在此基础上如果x存在
for y in x.find_all("a" , attrs = {"class" : "one"}) : #就在x中找有没有class是one的a标签
print(y.text)
print(y["href"]) #输出符合条件的标签的href属性中的内容输出:
以上就是Python网络爬虫设计(二)的全部内容:)

















 1380
1380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









