






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
P
T
P
F
N
召回率=\cfrac{TP}{TP + FN}
召回率=TP+FNTP
TP是真正类的数量,FN是假负类的数量。
在 Scikit-Learn 中可以使用 precision_score , recall_score 来计算精度和召回率。
from sklearn.metrics import precision_score, recall_score
print('精度:', precision_score(y_train_5, y_train_pred))
print('召回率:', recall_score(y_train_5, y_train_pred))
| 输出 |
|---|
| 精度: 0.8370879772350012 |
| 召回率: 0.6511713705958311 |
也可以使用混淆矩阵进行计算。结果一样。
cm = confusion_matrix(y_train_5, y_train_pred)
print('精度:', cm[1, 1] / (cm[0, 1] + cm[1, 1]))
print('召回率:', cm[1, 1] / (cm[1, 0] + cm[1, 1]))
| 输出 |
|---|
| 精度: 0.8370879772350012 |
| 召回率: 0.6511713705958311 |
根据精度和召回率的结果来看,它不再像准确率那么高了。当它预测一张图片为 5 时,他只有 83.7% 的概率是准确的,在整个测试集中也只有 65.1% 的 5 被正确检测出来。
3.4
F
1
F_1
F1分数
我们可以将精度和召回率组合成一个指标,称为
F
1
F_1
F1分数。
F
1
F_1
F1分数:精度和召回率的谐波平均值
F
1
=
2
1
精
度
1
召
回
率
=
T
P
T
P
F
N
F
P
2
F_1=\cfrac{2}{\cfrac{1}{精度} + \cfrac{1}{召回率}}=\cfrac{TP}{TP + \cfrac{FN + FP}{2}}
F1=精度1+召回率12=TP+2FN+FPTP
它会给予精度和召回率中的低值更高的权重。只有当精度和召回率都很高时,F
1
F_1
F1分数才高。
在 Scikit-Learn 中可以使用 f1_score 来计算
F
1
F_1
F1分数。
from sklearn.metrics import f1_score
f1_score(y_train_5, y_train_pred)
# cm[1, 1] / (cm[1, 1] + (cm[1, 0] + cm[0, 1]) / 2)
| 0.7325171197343846 |
|---|
F
1
F_1
F1分数对那些具有相近精度和召回率的分类器更有利。在实际情况下,我们有时更关注的是精度,如青少年视频筛选,我们要尽量保证筛选出来的都是符合要求的,而对于财务造假,我们就需要更关注召回率。鱼和熊掌不可兼得,精度和召回率同样也是。
3.5 精度/召回率权衡
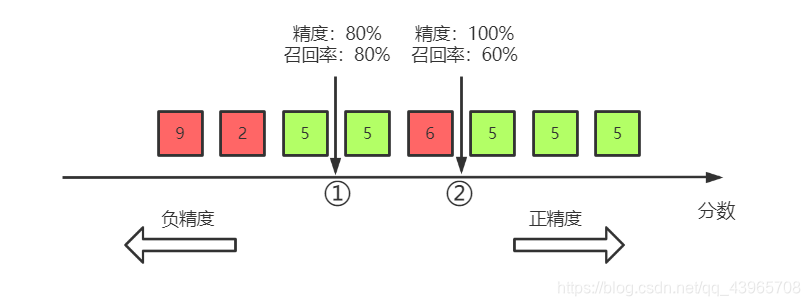
要理解这个权衡过程,首先要知道 SGDClassifier 如何进行分类的。对于数据集中的每一个实例,它会基于决策函数计算出一个分值,如果该值大于设定的阈值,则将该实例判为正类,否则便将其判为负类。
图中显示从左边最低分到右边最高分的几个数字,假设当前决策阈值位于①箭头的位置,在阈值的右边有四个 5(真正类)和一个 6 (假正类),因此精度为 80% 。在五个 5 中,只预测出了 4 个,召回率为 80% 。
现在提高阈值,以②箭头的位置作为决策阈值,此时,精度变为 100% ,召回率变为 60% 。
Scikit-Learn 不允许直接设置阈值,但可以使用 decision_function() 方法访问它用于预测的决策分数,该方法返回每个实例的分数,根据这些分数就可以使用任意阈值进行预测。下面先获取 3 个实例的决策分数。
y_scores = sgd_clf.decision_function(X[:3])
y_scores
| array([ 2164.22030239, -5897.37359354, -13489.14805779]) |
|---|
使用 SGDClassifier 默认的决策阈值 0 ,来得到分类结果。
threshold = 0
y_some_digit_pred = (y_scores > threshold)
y_some_digit_pred
| array([ True, False, False]) |
|---|
现在提升阈值看看是否会改变分类结果。
threshold = 3000
y_some_digit_pred = (y_scores > threshold)
y_some_digit_pred
| array([False, False, False]) |
|---|
结果发生了改变,这证明提高阈值确实可以降低召回率。
那我们如何在众多的实例中选择恰当的决策阈值?
首先使用 cross_val_predict() 函数获取训练集中所有所有实例的决策分数(修改 method 参数)。
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,
method="decision\_function")
y_scores.shape
| (60000,) |
|---|
使用 precision_recall_curve() 函数来计算所有可能的阈值的精度和召回率。
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
最后使用 Matplotlib 绘制精度和召回率相对于阈值的函数图。
# 显示中文
plt.rcParams['font.family'] = 'SimHei'
# 显示中文负号
plt.rcParams['axes.unicode\_minus'] = False
def plot\_precision\_recall\_vs\_threshold(precisions, recalls, thresholds):
# 绘制精度曲线
plt.plot(thresholds, precisions[:-1], "b--", label="精度", linewidth=2)
# 绘制召回率曲线
plt.plot(thresholds, recalls[:-1], "g-", label="召回率", linewidth=2)
# 设置图例的位置与大小
plt.legend(loc="center right", fontsize=16)
# 设置x轴的信息
plt.xlabel("Threshold", fontsize=16)
# 显示网格
plt.grid(True)
# 指定坐标轴的范围
plt.axis([-50000, 50000, 0, 1])
# 设置图像的大小
plt.figure(figsize=(8, 4))
plot_precision_recall_vs_threshold(precisions, recalls, thresholds)
# 保存图片
plt.savefig(Path(current_path, "./images/precision\_recall\_vs\_threshold\_plot.png"), dpi=600)
plt.show()
| 在这里插入图片描述 |
|---|
注意: 在精度曲线上,上端有部分是崎岖的,这是由于当你提高阈值时,精度有时也可能会下降。
另一种找到好的精度/召回率权衡的方法是直接绘制精度和召回率的函数图。
def plot\_precision\_vs\_recall(precisions, recalls):
plt.plot(recalls, precisions, "b-", linewidth=2)
plt.xlabel("召回率", fontsize=16)
plt.ylabel("精度", fontsize=16)
plt.axis([0, 1, 0, 1])
plt.grid(True)
# 设置绘制图像大小
plt.figure(figsize=(8, 6))
# 图像绘制
plot_precision_vs_recall(precisions, recalls)
# 保存图片
plt.savefig(Path(current_path, "./images/precision\_vs\_recall\_plot.png"), dpi=600)
plt.show()
| 在这里插入图片描述 |
|---|
从图中可以看到,从80%召回率往右,精度开始极度下降。你可能会尽量在这个陡降之前选择一个精度/召回率权衡,这要根据项目的实际情况来定。
假如你需要将精度设为 90% ,那么需要知道能提供 90% 精度的最低阈值。可以用 np.argmax() 函数来获取。
threshold_90_precision = thresholds[np.argmax(precisions >= 0.90)]
threshold_90_precision
| 3370.0194991439557 |
|---|
获得预测结果。
y_train_pred_90 = (y_scores >= threshold_90_precision)
print('精度:', precision_score(y_train_5, y_train_pred_90))
print('召回率:', recall_score(y_train_5, y_train_pred_90))
| 输出 |
|---|
| 精度: 0.9000345901072293 |
| 召回率: 0.4799852425751706 |
这样就得到了一个接近 90% 精度的分类器了!
3.6 ROC曲线
还有一种经常与二元分类器一起使用的工具,叫做受试者工作特征曲线( ROC )。它绘制的是真正类率( TPR 召回率)与假正类率( FPR )的关系。
- 真正类率(
TPR):预测为正例,且实际为正例的样本占所有正例样本(真实结果为正样本)的比例。 - 假正类率(
FPR):预测为正例,但实际为负例的样本占所有负例样本(真实结果为负样本)的比例。
T
P
R
=
T
P
T
P
F
N
TPR=\cfrac{TP}{TP + FN}
TPR=TP+FNTP
TP是真正类的数量,FN是假负类的数量。
F
P
R
=
F
P
F
P
T
N
FPR =\cfrac{FP}{FP + TN}
FPR=FP+TNFP
TP是假正类的数量,FN是真负类的数量。
要绘制 ROC 曲线,首先需要使用 roc_curve() 函数计算多种阈值的 TPR 和 FPR :
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)
使用 Matplotlib 绘制 FPR 对 TPR 的曲线。
def plot\_roc\_curve(fpr, tpr, label=None):
plt.plot(fpr, tpr, linewidth=2, label=label)
plt.plot([0, 1], [0, 1], 'k--') # 绘制虚线对角线
plt.axis([0, 1, 0, 1])
plt.xlabel('假正类率(FPR)', fontsize=16)
plt.ylabel('真正类率(TPR)', fontsize=16)
plt.grid(True)
# 设置绘制图像大小
plt.figure(figsize=(8, 6))
# 绘制FPR对TPR的曲线
plot_roc_curve(fpr, tpr)
# 保存图片
plt.savefig(Path(current_path, "./images/roc\_curve\_plot.png"), dpi=600)
plt.show()
| 在这里插入图片描述 |
|---|
召回率( TPR )越高,分类器产生的假正类( FP )就越多。虚线表示纯随机分类器的 ROC 曲线,一个好的分类器应该离这条线越远越好(接近左上角)。
一种常用的比较分类器 ROC 曲线的方法就是测量曲线下的面积( AUC )。完美的分类器 ROC AUC 等于 1 ,而纯随机分类器 ROC AUC 等于 0.5 。可以使用 Scikit-Learn 中的 roc_auc_score 来计算 ROC AUC 的值。
from sklearn.metrics import roc_auc_score
roc_auc_score(y_train_5, y_scores)
| 0.9604938554008616 |
|---|
ROC曲线与PR(精度 / 召回率)曲线的选择
当正类非常少时或你更关注假正类而不是假负类时,应该选择 PR 曲线,反之则选择 ROC 曲线。
现在我们来训练一个 RandomForestClassifier 分类器,并比较它和 SGDClassifier 分类器的 ROC 曲线和 ROC AUC 分数。 RandomForestClassifier 类没有 decision_function() 方法,它由 dict_proba() 方法。该方法会返回一个数组,其中每行代表一个实例,每列代表一个类别,意思是某个给定实例属于某个给定类别的概率。
from sklearn.ensemble import RandomForestClassifier
# 创建一个随机森林分类器
forest_clf = RandomForestClassifier(n_estimators=100, random_state=42)
# 使用交叉验证获得类别概率的平均值
y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3,
method="predict\_proba")
y_probas_forest
| 输出 |
|---|
| 在这里插入图片描述 |
根据结果可以看到,数组中包含该实例属于 非5 或 5 的概率值, shape 为 (60000, 2) 。
roc_curve() 函数需要标签和分数,我们直接使用正类的概率最为分数值。
y_scores_forest = y_probas_forest[:, 1] # score取属于正类的概率
fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5,y_scores_forest)
绘制 ROC 曲线。
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, "b:", linewidth=2, label="SGD")
plot_roc_curve(fpr_forest, tpr_forest, "Random Forest")
plt.grid(True)
plt.legend(loc="lower right", fontsize=16)
plt.savefig(Path(current_path, "./images/roc\_curve\_comparison\_plot.png"), dpi=600)
plt.show()
| 在这里插入图片描述 |
|---|
RandomForestClassifier 的 ROC 曲线看起来比 SGDClassifier 好的多,它离左上角更近,因此它的 ROC AUC 分数也高得多。下面也看看精度和召回率的分数。
# ROC AUC分数
print('ROC AUC分数: ', roc_auc_score(y_train_5, y_scores_forest))
# 交叉验证获取平均预测结果
y_train_pred_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3)
# 精度
precision_score('精度: ', y_train_5, y_train_pred_forest)
# 召回率
recall_score('召回率: ', y_train_5, y_train_pred_forest)
| 输出 |
|---|
| ROC AUC分数: 0.9983436731328145 |
| 精度: 0.9905083315756169 |
| 召回率: 0.8662608374838591 |
看起来结果也不错,现在对二元分类器已经有了一个基本的了解,知道了如何使用合适的指标利用交叉验证来对分类器进行评估,如何选择满足需求的 精度/召回 权衡,以及如何使用 ROC 曲线和 ROC AUC 分数比较多个模型,接下来尝试一下多类分类器。
4. 多类分类器
多类分类器可以区分两个以上的类。有一些算法(如 随机森林分类器 或 朴素贝叶斯分类器 )可以直接处理多个类。也有一些严格的二元分类器(如 支持向量机分类器 或 线性分类器 )。但是,有多种方法可以让你用几个二元分类器实现多类分类的目的。
如现在要创建一个系统将数字图片分为 10 类( 0-9 )
- 一种方法是训练
10个二元分类器,每个数字一个,当某张图片进行分类时,获取每个分类器的决策分数,将得分最高的分类器分类的结果作为它的类别。这叫做一对剩余策略(OvR)。 - 另一种方法是对每一个数字训练一个二元分类:一个用来区别
0与1,一个用来区别0与2,一个用来区别1与2,依次类推,这叫做一对一策略(OvO)。如果存在N个类别,那么训练器的个数就是:
N
×
(
N
−
1
)
2
\cfrac{N×(N - 1)}{2}
2N×(N−1)
当某张图片进行分类时,要运行所有的分类器来对图片进行分类,看分到哪个类的次数最多就将其分到那个类。 OvO 的主要优点就是:每个分类器只需要用到部分训练集对其所区分的两个类进行训练。
有些算法(如 支持向量机分类器 )在数据规模扩大时表现非常糟糕,对于这类算法, OvO 是一个较好的选择,因为在较小训练集上分别训练多个分类器比在大型数据集上训练少量分类器要快得多。但对于大多数二元分类器来说, OvR 策略还是更好的选择。
Scikit-Learn 可以检测到你尝试使用二元分类器进行多分类任务,它会根据情况自动运行 OvR 或 OvO 。我们先试试 SVM 分类器:
from sklearn.svm import SVC
# 创建分类器
svm_clf = SVC(gamma="auto", random_state=42)
# 训练分类器
svm_clf.fit(X_train[:1000], y_train[:1000])
# 对X\_train前三个实例进行分类
svm_clf.predict(X_train[:3])
| array([5, 0, 4], dtype=uint8) |
|---|
上面代码使用包含类别 0-9 的数据集对 SVC 进行训练,然后对测试集进行预测,在内部, Scikit-Learn 实际上训练了 45 个分类器,获得它们对图片的决策分数,选择分数最高的类。我们可以用 decision_function() 方法验证一下,该方法会获得 10 个分数,每个类 1 个。
some_digit_scores = svm_clf.decision_function(X_train[:3])
some_digit_scores
| 输出 |
|---|
| 在这里插入图片描述 |
最高的分数分别是分类5 ,分类0 ,分类4 。
在训练分类器时,目标类的列表会存储在 classes_ 属性中,按值的大小进行排序。
svm_clf.classes_
| array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8) |
|---|
如果要强制 Scikit-Learn 使用一对一或一对多策略,可以使用 OneVsOneClassifier 或 OneVsRestClassifier 类。只需要创建一个实例,然后将分类器传给其构造函数即可。例如下面使用 OvR 策略,基于 SVC 创建一个多类分类器。
from sklearn.multiclass import OneVsRestClassifier
# 将SVC分类器传给构造函数
ovr_clf = OneVsRestClassifier(SVC(gamma="auto", random_state=42))
# 训练分类器
ovr_clf.fit(X_train[:1000], y_train[:1000])
# 分类
ovr_clf.predict(X_train[:3])
| array([5, 0, 4], dtype=uint8) |
|---|
查看此时分类器的数量
len(ovr_clf.estimators_)
| 10 |
|---|
5. 误差分析
现在假设已经找到了一个有潜力的模型,希望能够找到一些方法对其进行改进,方法之一就是分析其错误类型。
首先看看混淆矩阵,使用 cross_val_predict() 函数进行预测,然后调用 confusion_matrix() 函数:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# 标准化
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
# 交叉验证
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
# 计算混淆矩阵
conf_mx = confusion_matrix(y_train, y_train_pred)
conf_mx
| 输出 |
|---|
| 在这里插入图片描述 |
由于是多分类,数组为 10 × 10 ,使用 Matplotlib 的 matshow() 函数来查看混淆矩阵的图像。
plt.matshow(conf_mx, cmap=plt.cm.gray)
plt.savefig(Path(current_path, "./images/confusion\_matrix\_plot.png"), dpi=600)
plt.show()
| 在这里插入图片描述 |
|---|
混淆矩阵中,每行表示每个实际类别,每列表示每个预测类别。混淆矩阵中大多数图片都在对角线上,这说明它们被正确的分类。但数字 5 的颜色比较暗,可能是因为测试集中的数字 5 的图片较少,也可能是因为该分类的分类效果不太好。
由于目前混淆矩阵的值是错误数量的绝对值,它会受到各分类图片数量的影响。我们需要将混淆矩阵中的每一个值除以相应类中的图片数量,这样比较的就是错误率了。为了凸显错误的种类,我们将对角线的值填充为0(因为它所占的比例很大,不将它填充0,其他的值颜色就难以区分开),重新绘制结果。
row_sums = conf_mx.sum(axis=1, keepdims=True)
# 混淆矩阵的每个值 / 单个实际类别总数量
norm_conf_mx = conf_mx / row_sums
# 用0填充主对角线
np.fill_diagonal(norm_conf_mx, 0)
plt.matshow(norm_conf_mx, cmap=plt.cm.gray)
plt.savefig(Path(current_path, "./images/confusion\_matrix\_errors\_plot.png"), dpi=600)
plt.show()
| 在这里插入图片描述 |
|---|
现在能够清晰的看到分类器产生的错误种类了,第 8 列非常亮,说明许多实际类别不是 8 的被错误的分类为数字 8 ,但根据第 8 行的颜色,准确分类为 8 的效果也还不错。对于这种分类错误,我们可以尝试和收集更多看起来像数字 8 的训练数据,以便分类器能够通过特征将它与其他数字区分开。或者对图片进行预处理(使用 Scikit-Image 、 Pillow 或 Opencv )让闭环( 8 有两个)更加突出等。同时上图中的数字 3 和数字 5 经常混淆(红框圈出)。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
个预测类别**。混淆矩阵中大多数图片都在对角线上,这说明它们被正确的分类。但数字 5 的颜色比较暗,可能是因为测试集中的数字 5 的图片较少,也可能是因为该分类的分类效果不太好。
由于目前混淆矩阵的值是错误数量的绝对值,它会受到各分类图片数量的影响。我们需要将混淆矩阵中的每一个值除以相应类中的图片数量,这样比较的就是错误率了。为了凸显错误的种类,我们将对角线的值填充为0(因为它所占的比例很大,不将它填充0,其他的值颜色就难以区分开),重新绘制结果。
row_sums = conf_mx.sum(axis=1, keepdims=True)
# 混淆矩阵的每个值 / 单个实际类别总数量
norm_conf_mx = conf_mx / row_sums
# 用0填充主对角线
np.fill_diagonal(norm_conf_mx, 0)
plt.matshow(norm_conf_mx, cmap=plt.cm.gray)
plt.savefig(Path(current_path, "./images/confusion\_matrix\_errors\_plot.png"), dpi=600)
plt.show()
| 在这里插入图片描述 |
|---|
现在能够清晰的看到分类器产生的错误种类了,第 8 列非常亮,说明许多实际类别不是 8 的被错误的分类为数字 8 ,但根据第 8 行的颜色,准确分类为 8 的效果也还不错。对于这种分类错误,我们可以尝试和收集更多看起来像数字 8 的训练数据,以便分类器能够通过特征将它与其他数字区分开。或者对图片进行预处理(使用 Scikit-Image 、 Pillow 或 Opencv )让闭环( 8 有两个)更加突出等。同时上图中的数字 3 和数字 5 经常混淆(红框圈出)。
[外链图片转存中…(img-55xlKbs1-1715882482354)]
[外链图片转存中…(img-iP58jJDk-1715882482355)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









