







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
图3
对于线性边界的情况,边界形式如下:
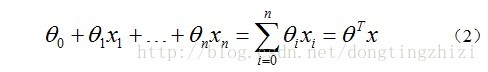
构造预测函数为:
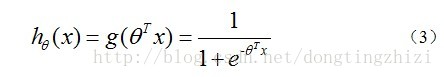
***hθ(x)***函数的值有特殊的含义,它表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
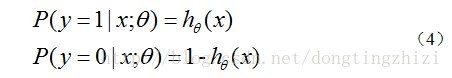
3.2 构造Cost函数
Andrew Ng在课程中直接给出了Cost函数及J(θ)函数如式(5)和(6),但是并没有给出具体的解释,只是说明了这个函数来衡量h函数预测的好坏是合理的。
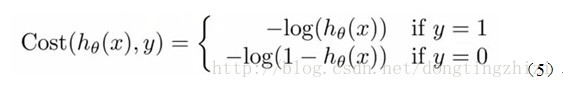
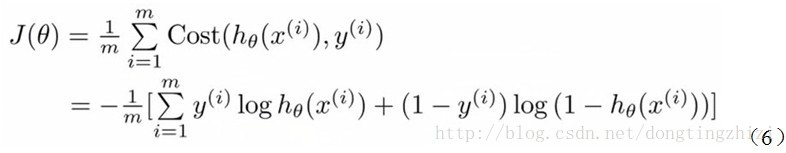
实际上这里的Cost函数和***J(θ)***函数是基于最大似然估计推导得到的。下面详细说明推导的过程。(4)式综合起来可以写成:
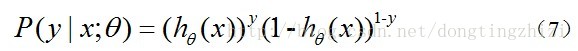
取似然函数为:
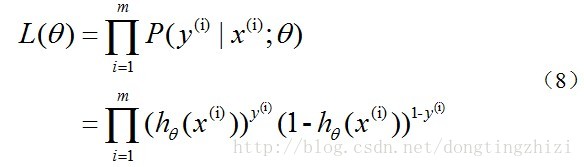
对数似然函数为:
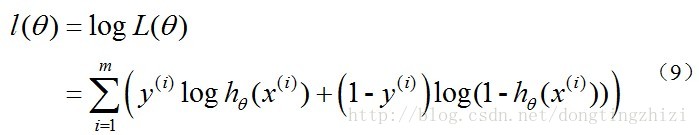
最大似然估计就是要求得使l(θ)取最大值时的θ,其实这里可以使用梯度上升法求解,求得的θ就是要求的最佳参数。但是,在Andrew Ng的课程中将***J(θ)***取为(6)式,即:

因为乘了一个负的系数***-1/m***,所以J(θ)取最小值时的θ为要求的最佳参数。
3.3 梯度下降法求*J(θ)*的最小值
求J(θ)的最小值可以使用梯度下降法,根据梯度下降法可得θ的更新过程:
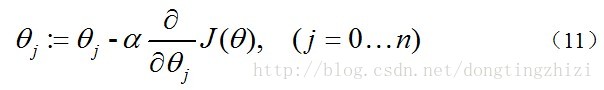
式中为α学习步长,下面来求偏导:
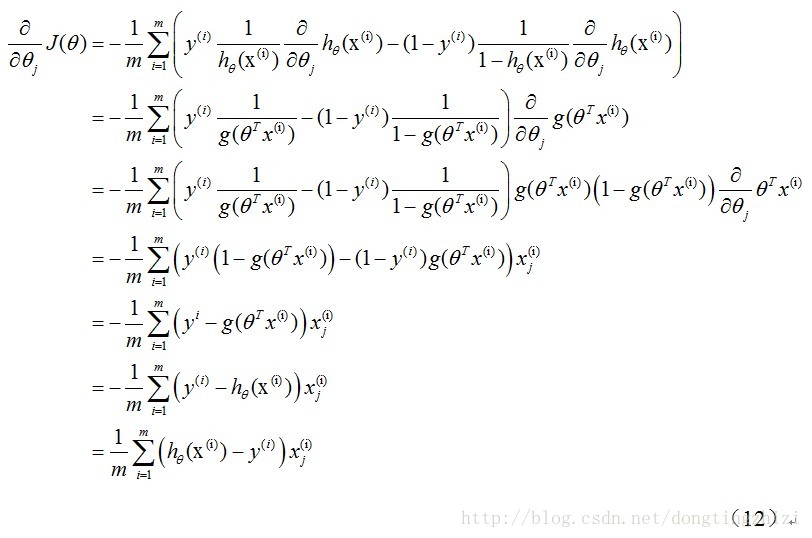
上式求解过程中用到如下的公式:
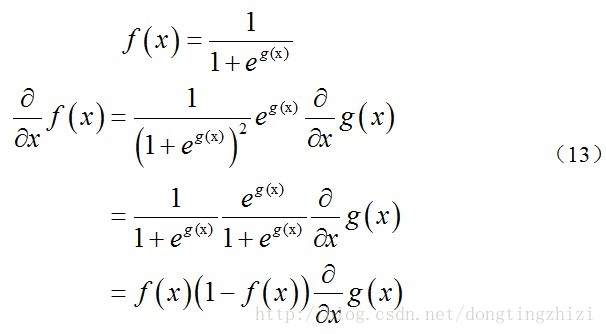
因此,(11)式的更新过程可以写成:
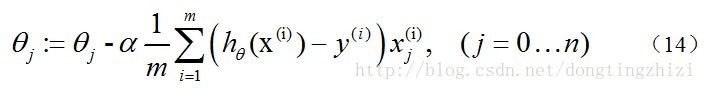
因为式中α本来为一常量,所以1/m一般将省略,所以最终的θ更新过程为:
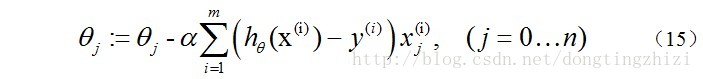
另外,补充一下,3.2节中提到求得l(θ)取最大值时的θ**也是一样的,用梯度上升法求(9)式的最大值,可得:
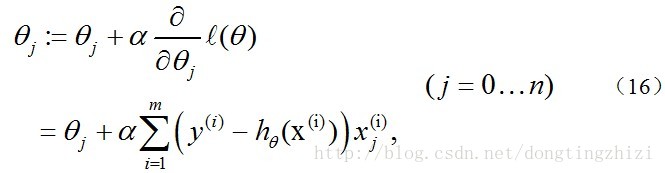
观察上式发现跟(14)是一样的,所以,采用梯度上升发和梯度下降法是完全一样的,这也是《机器学习实战》中采用梯度上升法的原因。
3.4 梯度下降过程向量化
关于θ更新过程的vectorization,Andrew Ng的课程中只是一带而过,没有具体的讲解。
《机器学习实战》连Cost函数及求梯度等都没有说明,所以更不可能说明vectorization了。但是,其中给出的实现代码确是实现了vectorization的,图4所示代码的32行中weights(也就是θ)的更新只用了一行代码,直接通过矩阵或者向量计算更新,没有用for循环,说明确实实现了vectorization,具体代码下一章分析。
文献[3]中也提到了vectorization,但是也是比较粗略,很简单的给出vectorization的结果为:
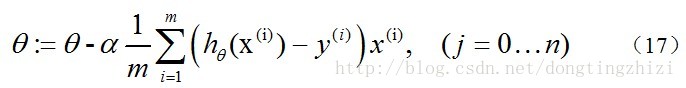
且不论该更新公式正确与否,这里的Σ(…)是一个求和的过程,显然需要一个for语句循环m次,所以根本没有完全的实现vectorization,不像《机器学习实战》的代码中一条语句就可以完成θ**的更新。
下面说明一下我理解《机器学习实战》中代码实现的vectorization过程。
约定训练数据的矩阵形式如下,x的每一行为一条训练样本,而每一列为不同的特称取值:
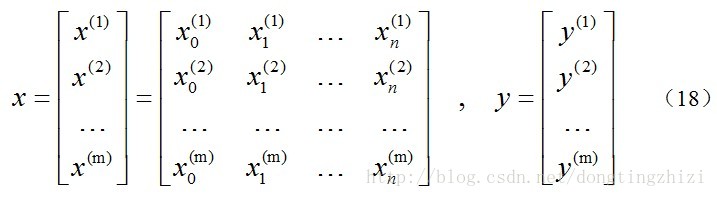
约定待求的参数θ的矩阵形式为:
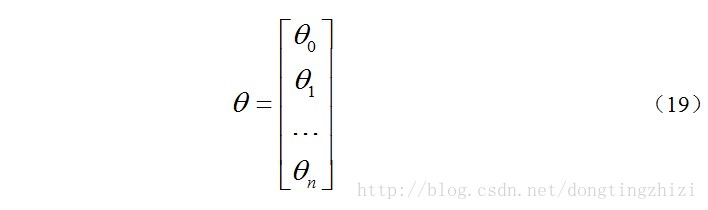
先求x.θ并记为A:

求hθ(x)-y并记为E:
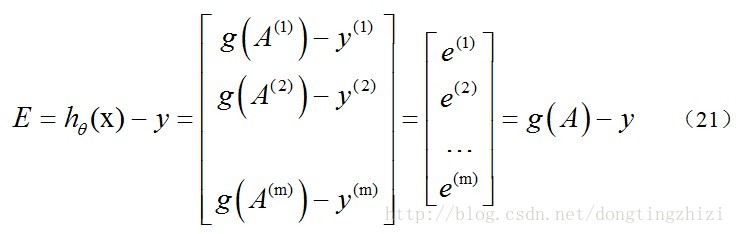
g(A)的参数A为一列向量,所以实现g函数时要支持列向量作为参数,并返回列向量。由上式可知hθ(x)-y可以由g(A)-y一次计算求得。
再来看一下(15)式的θ更新过程,当j=0时:
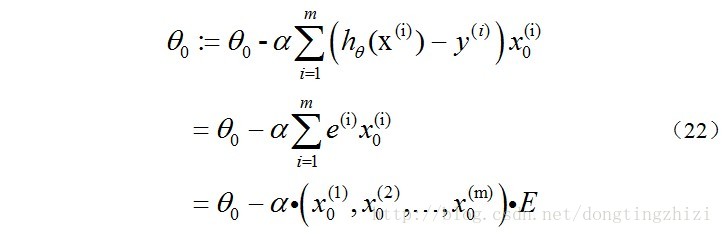
同样的可以写出θj,
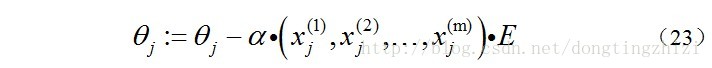
综合起来就是:
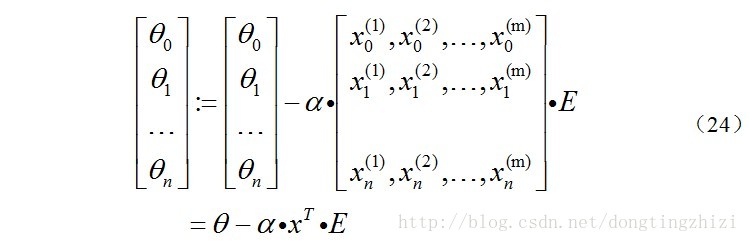
综上所述,vectorization后θ更新的步骤如下:
(1)求A=x.θ;
(2)求E=g(A)-y;
(3)求**θ:=θ-α.x’.E,**x’表示矩阵x的转置。
也可以综合起来写成:
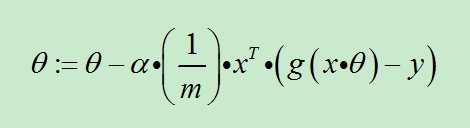
前面已经提到过:1/m是可以省略的。
4. 代码分析
图4中是《机器学习实战》中给出的部分实现代码。
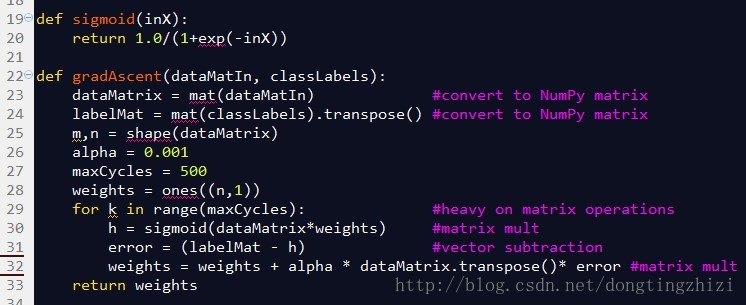
图4


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
1715882449034)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









