






网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
在进行数据整理之前,我们需要对数据进行检查。
①缺失值检查
首先,我们需要检查缺失数据。输入以下代码:
pumpkins.isnull().sum() #检查每列数据中的缺失值的数量
图4 缺失值
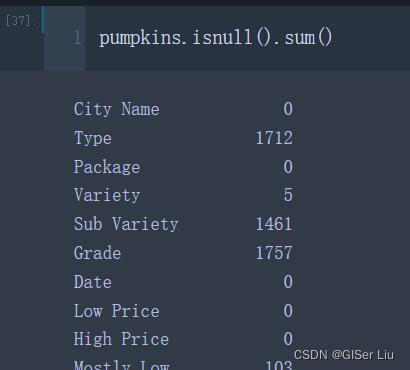
根据打印出来的结果可以看出,日期’date’数据的缺失值为0,并无缺失值,同理,其余需要的数据也没有缺失值。因此,缺失值检测通过。
②数据一致性检查
接着我们检查每列数据中的数据一致性。四列数据中,'Package’列中的数据是南瓜的称量单位,称量单位应保持一致,它决定着价格一致性。因此只对此列数据做一致性检验。输入以下代码:
pumpkins["Package"].is_unique
这行代码用于检验数据的值是否唯一,True代表唯一,False表示不唯一。输出结果为:
False
输出结果表明数据不唯一,稍后我们将对其进行处理。
③无效值检查
本数据因为是通过官方渠道获取,方便初学者入门,因此数据已经剔除无效值,之后的文章中我会详细讲解无效值检查,感兴趣的同学可提前去学习相关知识。
2.数据整理
现在,我们经过数据检查,整理了以下问题:
Package列数据未通过数据一致性检验
①数据过滤
我们通过输入以下代码统计"Package"列不同数据出现的频数以选择合适的数据:
pumpkins["Package"].value_counts() #统计"Package"列不同值出现的次数
打印结果如下,结果似乎很混乱,统计的称量方式多种多样。
图5 Package频数统计
经过深入研究原始数据后,我们发现,其中包含“每英寸”、“每箱”甚至“每个”的称重类型,这不是重量单位,它的价格是无意义的。南瓜似乎很难保持一致的重量,所以让我们通过只选择列中有字符串“'bushel”的南瓜来过滤它们,虽然缺失了很多数据,但它们对分析无用。
输入以下代码用于筛选只包含字符串“bushel”的数据:
pumpkins = pumpkins[pumpkins['Package'].str.contains('bushel', case=True, regex=True)]
②数据提取
经过数据过滤,现在我们的整理工作只剩下两个:
0 提取月份数据
0.0 将日期数据转换为月份格式(这些日期数据是美国日期,因此格式为MM/DD/YYYY)
0.1 将月份提取到新列
1 提取平均值数据
1.0 计算平均价格并提取至新列
(1)提取月份数据与价格数据
思考一下如何确定南瓜在给定月份的平均价格。在这里每月平均价格的计算公式为:
(Low Price+High Price)/2
price = (pumpkins['Low Price'] + pumpkins['High Price']) / 2 #price是平均价格
month = pd.DatetimeIndex(pumpkins['Date']).month #将日期列转换为日期并提取出月份数据
我们需要创建一个“month”列,从“date”列中提取出月份,并赋值给“month”列。
(2)提取数据至新列
将需要的数据提取出来放置新文件,并查看其结构。输入以下代码:
new_pumpkins=pd.DataFrame({'Month':month,'Package':pumpkins['Package'],'LowPrice':pumpkins['Low Price'],'High Price': pumpkins['High Price'], 'Price': price})
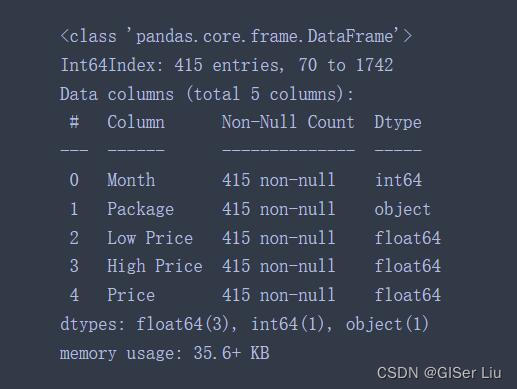
new_pumpkins.info()
输出结果为:
图6 新数据

我们可以看到,我们分析需要的数据已经基本整理完成。那你是否注意到南瓜单位的量因每行而异呢,你需要规范定价,以便显示每pushel的定价,因此请进行一些数学运算以对其进行标准化。
在创建new_pumpkins数据之后添加以下代码:
new_pumpkins.loc[new_pumpkins['Package'].str.contains('1 1/9'), 'Price'] = price/(1 + 1/9) # loc()函数通过索引行标签索引行数据,即包含1 1/9的行,price = price/(1 + 1/9)
new_pumpkins.loc[new_pumpkins['Package'].str.contains('1/2'), 'Price'] = price/(1/2) #同上
根据The Spruce Eats的说法,bushel的重量取决于农产品的类型,因为它是体积测量。“例如,1 bushel西红柿应该重达56磅…叶子和绿色蔬菜以更轻的重量占用更多的空间,所以1 bushel菠菜只有20磅。
这一切都非常复杂!让我们不要费心进行bushel(单位)到磅的转换,而是按bushel(单位)定价。这一切都表明了解数据的性质是多么重要!
现在,我们可以根据测量值分析每单位的定价。
Tip:你有没有注意到半bushel出售的南瓜非常昂贵?你能弄清楚为什么吗?因为小南瓜比大南瓜贵得多,可能是因为每bushel的南瓜数量更多,因为一个大空心馅饼南瓜占用了未使用的空间。
三、数据可视化
数据科学工作者为了体现数据的质量和性质,通常会创建有趣的可视化效果,以显示数据的不同特点。通过这种方式,他们能够直观地显示难以发现的联系和误差。
可视化还可以帮助确定最适合数据的机器学习技术。例如,散点图中的一条直线表示数据是线性回归练习的典型案例。
在 Jupyter notebook中入门常用的数据可视化库是matplotlib,虽然有更好的可视化库,但是大多都是基于Matplotlib封装的,学好Matplotlib,走遍天下可视化😁。
尝试创建一些基本图表来可视化刚刚构建的新数据。
1.散点图
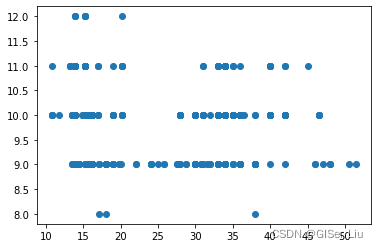
将平均价格与月份数据并以散点图的形式可视化
import matplotlib.pyplot as plt
price = new_pumpkins.Price
month = new_pumpkins.Month
plt.scatter(price, month)
plt.show()
图4 散点图
2.柱状图
要使图表显示有用的数据,通常需要以某种方式对数据进行分组。让我们尝试创建一个柱状图,其中 y 轴显示月份。这一步我们常称之为“分组聚合”
以分组聚合的方式创建分组直方图:
new_pumpkins.groupby(['Month'])['Price'].mean().plot(kind='bar')#按月份分组并统计出每个月的平均价格,绘制柱状图
plt.ylabel("Pumpkin Price") #横轴为月份,纵轴为平均价格
图5 直方图
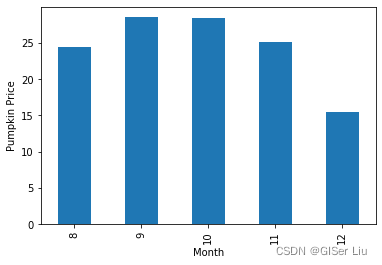
直方图可视化效果很直观!这似乎表明南瓜的最高价格出现在9月和10月。这符合您的期望吗?为什么呢?
四、总结
在本文中,我们以美国南瓜数据为例,观察并整理了需要的数据,挑选及提取了特征变量:如月份,平均价格。并对其进行了数据可视化,我们发现,9月和10月份是南瓜的平均价格最高。下一篇文章中,我将基于本文成果数据构建线性和多项式回归模型。
**课后题:**请读者探索Matplotlib绘图类型 — Matplotlib 3.5.1 文档库提供的不同类型的可视化案例。哪些适合回归?哪些又适合分类?

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
aa6ee7a946f44.png)
[外链图片转存中…(img-SMCnPXAL-1715882868174)]
[外链图片转存中…(img-E111ilIj-1715882868174)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 9112
9112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









