






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
# 加载数据
train = pd.read_csv("../input/train.csv")
test = pd.read_csv("../input/test.csv")
Y_train = train["label"]
X_train = train.drop(labels = ["label"], axis = 1)
# 加载更多的数据集,如果没这批数据,validation accuracy = 0.9964
# 有这批数据后,validation accuracy 可以到达 0.9985
(x_train1, y_train1), (x_test1, y_test1) = mnist.load_data()
train1 = np.concatenate([x_train1, x_test1], axis=0)
y_train1 = np.concatenate([y_train1, y_test1], axis=0)
Y_train1 = y_train1
X_train1 = train1.reshape(-1, 28\*28)
Downloading data from https://s3.amazonaws.com/img-datasets/mnist.npz
11493376/11490434 [==============================] - 1s 0us/step
# 打印数据的直方图
g = sns.countplot(Y_train)

# 归一化数据,让CNN更快
X_train = X_train / 255.0
test = test / 255.0
X_train1 = X_train1 / 255.0
# Reshape 图片为 3D array (height = 28px, width = 28px , canal = 1)
X_train = np.concatenate((X_train.values, X_train1))
Y_train = np.concatenate((Y_train, Y_train1))
X_train = X_train.reshape(-1,28,28,1)
test = test.values.reshape(-1,28,28,1)
# 把label转换为one hot vectors (ex : 2 -> [0,0,1,0,0,0,0,0,0,0])
Y_train = to_categorical(Y_train, num_classes = 10)
# 拆分数据集为训练集和验证集
X_train, X_val, Y_train, Y_val = train_test_split(X_train, Y_train, test_size = 0.1, random_state=2)
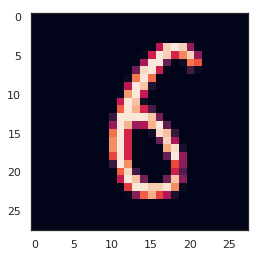
# 画一个数据集的例子来看看
g = plt.imshow(X_train[0][:,:,0])
# 创建CNN model
# 模型:
"""
[[Conv2D->relu]\*2 -> BatchNormalization -> MaxPool2D -> Dropout]\*2 ->
[Conv2D->relu]\*2 -> BatchNormalization -> Dropout ->
Flatten -> Dense -> BatchNormalization -> Dropout -> Out
"""
model = Sequential()
model.add(Conv2D(filters = 64, kernel_size = (5,5),padding = 'Same', activation ='relu', input_shape = (28,28,1)))
model.add(BatchNormalization())
model.add(Conv2D(filters = 64, kernel_size = (5,5),padding = 'Same', activation ='relu'))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters = 64, kernel_size = (3,3),padding = 'Same', activation ='relu'))
model.add(BatchNormalization())
model.add(Conv2D(filters = 64, kernel_size = (3,3),padding = 'Same', activation ='relu'))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2,2), strides=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters = 64, kernel_size = (3,3), padding = 'Same', activation ='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation = "relu"))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Dense(10, activation = "softmax"))
# 打印出model 看看
from keras.utils import plot_model
plot_model(model, to_file='model.png', show_shapes=True, show_layer_names=True)
from IPython.display import Image
Image("model.png")

# 定义Optimizer
optimizer = RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0)
# 编译model
model.compile(optimizer = optimizer , loss = "categorical\_crossentropy", metrics=["accuracy"])
# 设置学习率的动态调整
learning_rate_reduction = ReduceLROnPlateau(monitor='val\_acc',
patience=3,
verbose=1,
factor=0.5,
min_lr=0.00001)
epochs = 50
batch_size = 128
# 通过数据增强来防止过度拟合
datagen = ImageDataGenerator(
featurewise_center=False, # set input mean to 0 over the dataset
samplewise_center=False, # set each sample mean to 0
featurewise_std_normalization=False, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range=10, # randomly rotate images in the range (degrees, 0 to 180)
zoom_range = 0.1, # Randomly zoom image
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=False, # randomly flip images
vertical_flip=False) # randomly flip images
datagen.fit(X_train)
# 训练模型
history = model.fit_generator(datagen.flow(X_train,Y_train, batch_size=batch_size),
epochs = epochs, validation_data = (X_val,Y_val),
verbose = 2, steps_per_epoch=X_train.shape[0] // batch_size
, callbacks=[learning_rate_reduction])
Epoch 1/50
- 47s - loss: 0.1388 - acc: 0.9564 - val_loss: 0.0434 - val_acc: 0.9852
Epoch 2/50
- 43s - loss: 0.0496 - acc: 0.9845 - val_loss: 0.0880 - val_acc: 0.9767
Epoch 3/50
- 43s - loss: 0.0384 - acc: 0.9884 - val_loss: 0.0230 - val_acc: 0.9933
Epoch 4/50
- 44s - loss: 0.0331 - acc: 0.9898 - val_loss: 0.0224 - val_acc: 0.9942
Epoch 5/50
- 42s - loss: 0.0300 - acc: 0.9910 - val_loss: 0.0209 - val_acc: 0.9933
Epoch 6/50
- 42s - loss: 0.0257 - acc: 0.9924 - val_loss: 0.0167 - val_acc: 0.9953
Epoch 7/50
- 42s - loss: 0.0250 - acc: 0.9924 - val_loss: 0.0159 - val_acc: 0.9952
Epoch 8/50
- 43s - loss: 0.0248 - acc: 0.9928 - val_loss: 0.0149 - val_acc: 0.9951
Epoch 9/50
- 42s - loss: 0.0218 - acc: 0.9934 - val_loss: 0.0170 - val_acc: 0.9954
Epoch 00009: ReduceLROnPlateau reducing learning rate to 0.0005000000237487257.
Epoch 10/50
- 42s - loss: 0.0176 - acc: 0.9947 - val_loss: 0.0106 - val_acc: 0.9965
Epoch 11/50
- 43s - loss: 0.0149 - acc: 0.9956 - val_loss: 0.0101 - val_acc: 0.9969
Epoch 12/50
- 42s - loss: 0.0152 - acc: 0.9953 - val_loss: 0.0084 - val_acc: 0.9973
Epoch 13/50
- 42s - loss: 0.0146 - acc: 0.9958 - val_loss: 0.0079 - val_acc: 0.9980
Epoch 14/50
- 43s - loss: 0.0134 - acc: 0.9959 - val_loss: 0.0129 - val_acc: 0.9962
Epoch 15/50
- 42s - loss: 0.0135 - acc: 0.9959 - val_loss: 0.0093 - val_acc: 0.9971
Epoch 16/50
- 43s - loss: 0.0129 - acc: 0.9960 - val_loss: 0.0085 - val_acc: 0.9974
Epoch 00016: ReduceLROnPlateau reducing learning rate to 0.0002500000118743628.
Epoch 17/50
- 43s - loss: 0.0109 - acc: 0.9968 - val_loss: 0.0064 - val_acc: 0.9980
Epoch 18/50
- 44s - loss: 0.0107 - acc: 0.9966 - val_loss: 0.0068 - val_acc: 0.9984
Epoch 19/50
- 43s - loss: 0.0104 - acc: 0.9969 - val_loss: 0.0065 - val_acc: 0.9986
Epoch 20/50
- 43s - loss: 0.0097 - acc: 0.9969 - val_loss: 0.0057 - val_acc: 0.9985
Epoch 21/50
- 43s - loss: 0.0092 - acc: 0.9971 - val_loss: 0.0073 - val_acc: 0.9981
Epoch 22/50
- 43s - loss: 0.0097 - acc: 0.9970 - val_loss: 0.0068 - val_acc: 0.9982
Epoch 00022: ReduceLROnPlateau reducing learning rate to 0.0001250000059371814.
Epoch 23/50
- 43s - loss: 0.0083 - acc: 0.9975 - val_loss: 0.0064 - val_acc: 0.9984
Epoch 24/50
- 43s - loss: 0.0085 - acc: 0.9974 - val_loss: 0.0061 - val_acc: 0.9985
Epoch 25/50
- 43s - loss: 0.0081 - acc: 0.9976 - val_loss: 0.0058 - val_acc: 0.9988
Epoch 26/50
- 43s - loss: 0.0080 - acc: 0.9977 - val_loss: 0.0065 - val_acc: 0.9986
Epoch 27/50
- 43s - loss: 0.0078 - acc: 0.9977 - val_loss: 0.0066 - val_acc: 0.9984
Epoch 28/50
- 44s - loss: 0.0088 - acc: 0.9975 - val_loss: 0.0060 - val_acc: 0.9988
Epoch 00028: ReduceLROnPlateau reducing learning rate to 6.25000029685907e-05.
Epoch 29/50
- 44s - loss: 0.0077 - acc: 0.9975 - val_loss: 0.0056 - val_acc: 0.9988
Epoch 30/50
- 43s - loss: 0.0063 - acc: 0.9980 - val_loss: 0.0054 - val_acc: 0.9988
Epoch 31/50
- 44s - loss: 0.0069 - acc: 0.9980 - val_loss: 0.0056 - val_acc: 0.9988
Epoch 00031: ReduceLROnPlateau reducing learning rate to 3.125000148429535e-05.
Epoch 32/50
- 44s - loss: 0.0068 - acc: 0.9980 - val_loss: 0.0055 - val_acc: 0.9986
Epoch 33/50
- 43s - loss: 0.0066 - acc: 0.9981 - val_loss: 0.0055 - val_acc: 0.9987
Epoch 34/50
- 43s - loss: 0.0069 - acc: 0.9979 - val_loss: 0.0055 - val_acc: 0.9988
Epoch 00034: ReduceLROnPlateau reducing learning rate to 1.5625000742147677e-05.
Epoch 35/50
- 43s - loss: 0.0065 - acc: 0.9979 - val_loss: 0.0055 - val_acc: 0.9988
Epoch 36/50
- 42s - loss: 0.0069 - acc: 0.9980 - val_loss: 0.0054 - val_acc: 0.9988
Epoch 37/50
- 43s - loss: 0.0064 - acc: 0.9980 - val_loss: 0.0054 - val_acc: 0.9988
Epoch 00037: ReduceLROnPlateau reducing learning rate to 1e-05.
Epoch 38/50
- 42s - loss: 0.0067 - acc: 0.9979 - val_loss: 0.0054 - val_acc: 0.9989
Epoch 39/50
- 43s - loss: 0.0067 - acc: 0.9979 - val_loss: 0.0055 - val_acc: 0.9988
Epoch 40/50
- 43s - loss: 0.0060 - acc: 0.9983 - val_loss: 0.0055 - val_acc: 0.9988
Epoch 41/50
- 42s - loss: 0.0056 - acc: 0.9983 - val_loss: 0.0055 - val_acc: 0.9988
Epoch 42/50
- 43s - loss: 0.0064 - acc: 0.9981 - val_loss: 0.0055 - val_acc: 0.9988
Epoch 43/50
- 42s - loss: 0.0060 - acc: 0.9982 - val_loss: 0.0054 - val_acc: 0.9988
Epoch 44/50
- 42s - loss: 0.0062 - acc: 0.9981 - val_loss: 0.0054 - val_acc: 0.9989
Epoch 45/50
- 42s - loss: 0.0061 - acc: 0.9980 - val_loss: 0.0055 - val_acc: 0.9989
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618668825)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
989
[外链图片转存中...(img-gPHASrOB-1715765450725)]
[外链图片转存中...(img-Q6nPHGIl-1715765450725)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618668825)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 232
232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









