







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上C C++开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
按位或一个数,这个数对应的那个比特位为1,其余比特位为0
void set(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
_bits[i] |= (1 << j);
}
reset将x对应的比特位设置为0
将某一个比特位置为0,同时不影响其他比特位:
按位与一个数,这个数对应的那个比特位为0,其余比特位为1
void reset(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
_bits[i] &= ~(1 << j);
}
test检查x在不在
跟一个数进行按位与
按位与一个数,这个数对应的那个比特位为1,其余比特位为0
如果结果
为0:说明不存在,
不为0说明存在
bool test(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
return _bits[i] & (1<<j);
}
3.位图的实现
1.char类型的数组
实现了set reset test之后
位图其实就已经实现完毕了
namespace wzs
{
// N是需要多少比特位
template<size_t N>
class bitset
{
public:
bitset()
{
_bits.resize(N/8+1, 0);
}
void set(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
_bits[i] |= (1 << j);
}
void reset(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
_bits[i] &= ~(1 << j);
}
bool test(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
return _bits[i] & (1<<j);
}
private:
vector<char> _bits;
};
}
2.int类型的数组
也可以采用int类型的数组来搞
此时就不是除8模8了
而是除32模32了
因为一个int类型有32个比特位
namespace wzs
{
// N是需要多少比特位
template<size_t N>
class bitset
{
public:
bitset()
{
//\_bits.resize(N/32+1, 0);
_bits.resize((N>>5) + 1, 0);
}
void set(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
_bits[i] |= (1 << j);
}
void reset(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
_bits[i] &= ~(1 << j);
}
bool test(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
return _bits[i] & (1<<j);
}
private:
vector<int> _bits;
};
}
3.解决一开始的问题
因此对于一开始的那个问题:

位图开多大呢?
注意: 使用位图,且没有指定范围时,我们要按照该数据的范围大小来开位图
无符号整数的范围是0~4,294,967,295
因此我们需要开0~4,294,967,295大的范围
0~2的32次方-1的范围
一共有2的32次方个整数,
2的10次方是1024
2的30次方就是1024*1024*1024=1024*1024K=1024M=1G
因此2的32次方就是4G个整数
而我们使用一个比特位表示一个整数的,一个字节有8个比特位
因此我们只需要4G/8=0.5G个字节即可
因此我们的位图大小就是0.5G,正常情况下内存当中完全能存的下
无需担心
小小补充
而这个数字也不好记,其实它还有下面3种写法
- (size_t)-1 将-1强转为无符号整形
- UINT_MAX (unsigned_intMAX)
- 0xffffffff(16进制:8个f)
- pow(2,32)-1
一定注意:^在C++/C当中是异或,不是幂
因此(2^32)-1不等于那个数字
pow的返回值类型是double类型
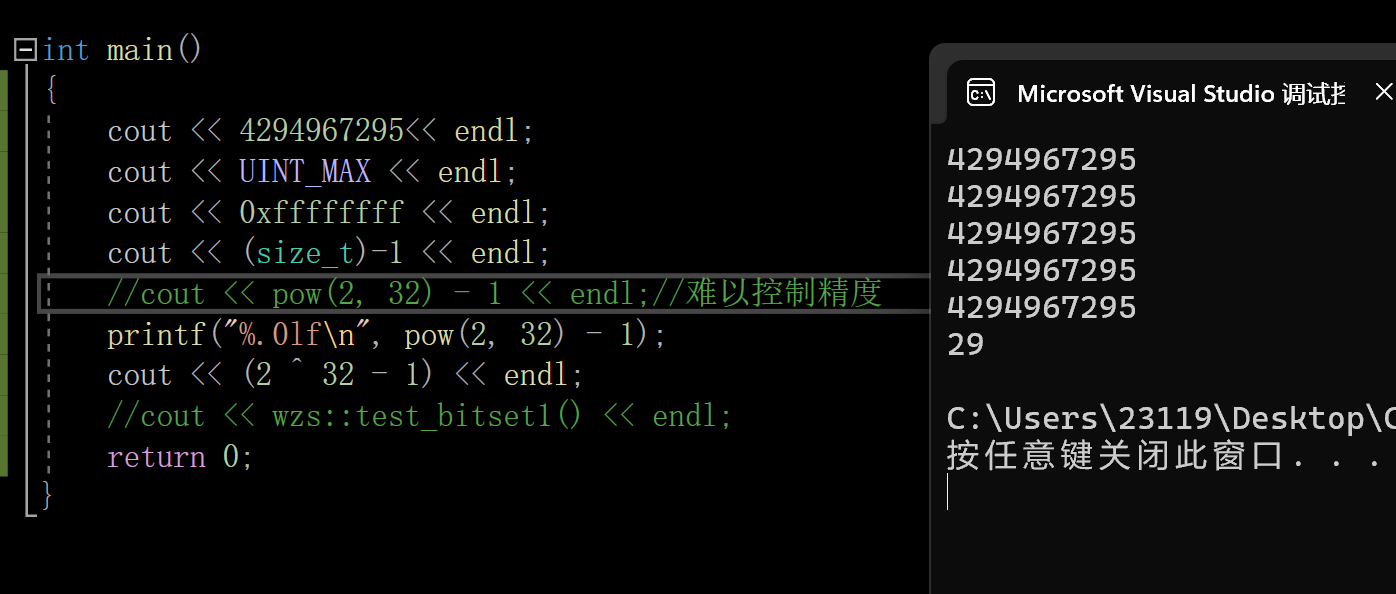
验证
下面我们来验证一下位图能否完成这一任务

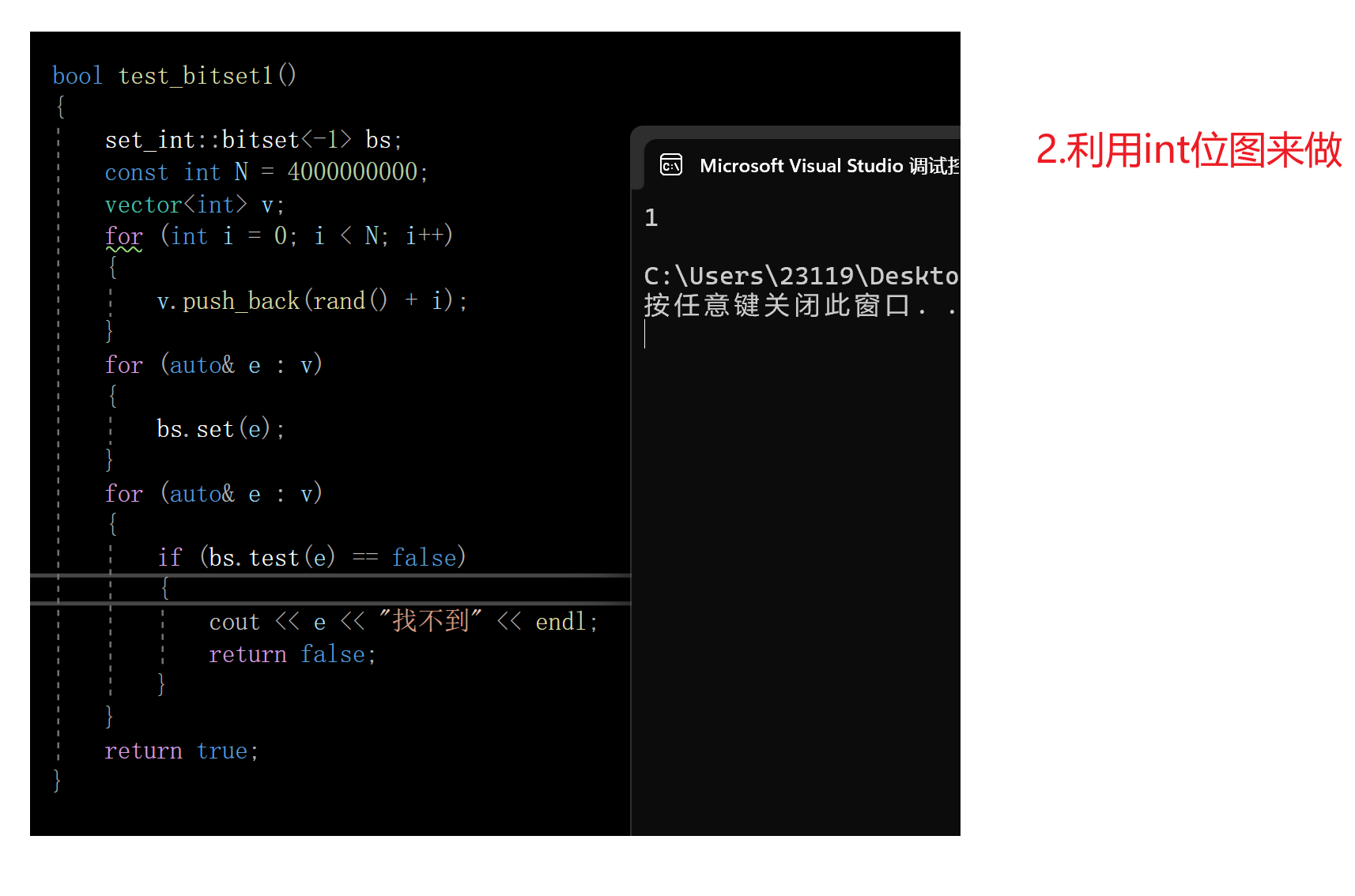
成功完成这一任务
4.位图的应用
1.给定100亿个整数,设计算法找到只出现一次的整数?
1.位图开多大?
我们先算一下100亿个整数要占多少G的内存?
一个比特位映射一个整数,一个字节有8个比特位
100亿个整数=100亿个比特位=100亿/8个字节=12.5亿字节=1.25G
我们真的要用1.25G的空间吗?
并不是!!!
而是刚才我们算的0.5G就足以
因为我们只存范围
如果要求必须使用位图来做,就算只有2个整数,不给我们范围,还是要用0.5G大小的位图
2.思路
找到只出现一次的整数,因为一个比特位只有0和1这两种状态,因此无法表示出现了1次以上的数字的状态
那么怎么办?
如果用2个比特位来表示一个整数的状态呢?
00就是出现0次
01就是出现1次
10就是出现2次
出现2次以后这个数我们就不再统计次数了
因此我们可以:
1.修改上面的位图,用2个比特位来表示一个整数
此时位图的大小就要乘以2,成为1G
2.用2个位图来做,每个位图依然是0.5G
只不过set,test函数要修改一下即可
下面我们就按照第2种来做吧,这个清晰易懂
3.代码
因为我们没有统计2次以上的次数,因此我们不允许进行reset操作
//利用组合来进行封装
template<size_t N>
class two\_bitset
{
public:
void set(int x)
{
//00 -> 01
if (_bits1.test(x) == false && _bits2.test(x) == false)
{
_bits2.set(x);
}
//01 -> 10
else if (_bits1.test(x) == false && _bits2.test(x) == true)
{
_bits1.set(x);
_bits2.reset(x);
}
//10,不记录了
}
//返回x出现了多少次
//返回2表示2次及以上
int test(int x)
{
if (_bits1.test(x) == false && _bits2.test(x) == false)
{
return 0;
}
else if (_bits1.test(x) == false && _bits2.test(x) == true)
{
return 1;
}
return 2;
}
private:
bitset<N> _bits1;
bitset<N> _bits2;
};
4.验证
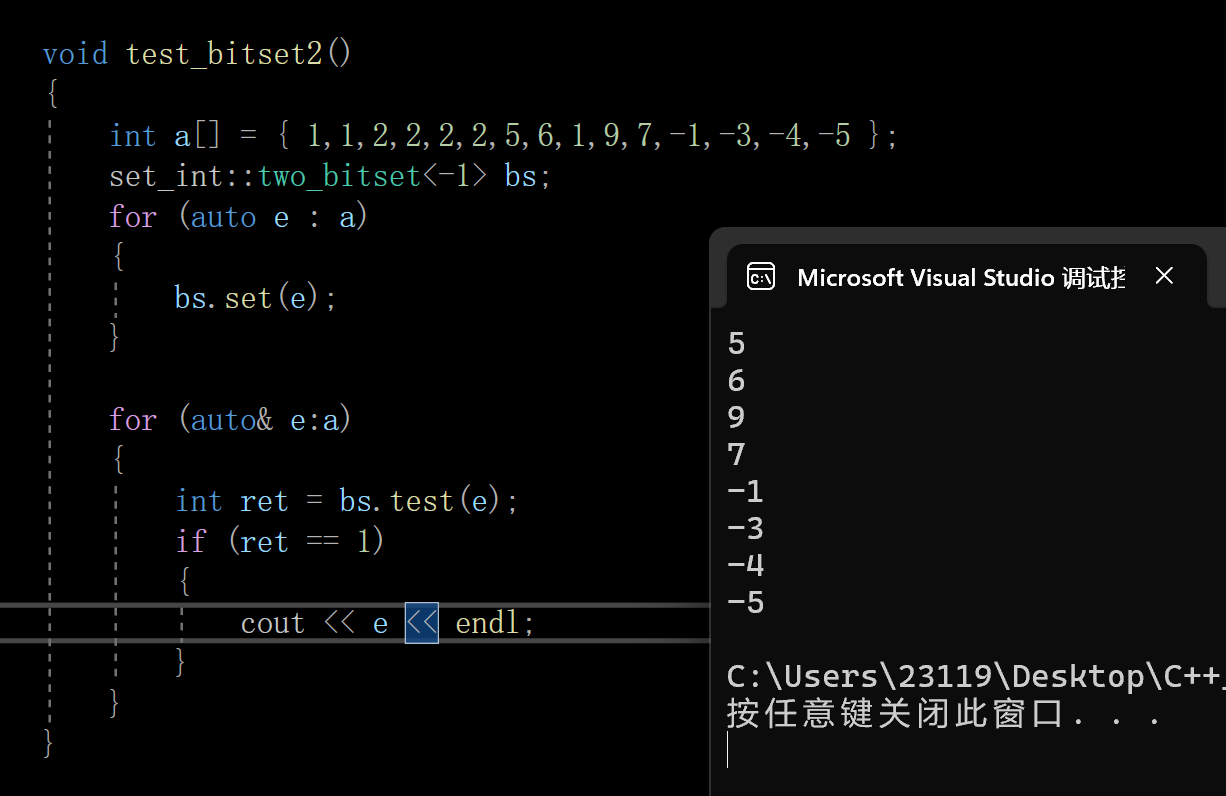
成功
2.给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
经过刚才的那道题
我们已经能够很轻松的解决了
管你100亿还是200亿,统统开0.5G的位图
因为有2个文件,因此开2个位图,正好1个G
每个文件当中的每个整数还是按照一个比特位来映射
只不过取交集的时候要求两个位图当中的test都为true才是交集
因此我们直接用一开始的位图即可,不用再去写位图了

集合是具有互异性的,而我们的位图是天然去重的,因此无需担心交集当中出现重复值
下面我们来玩一下
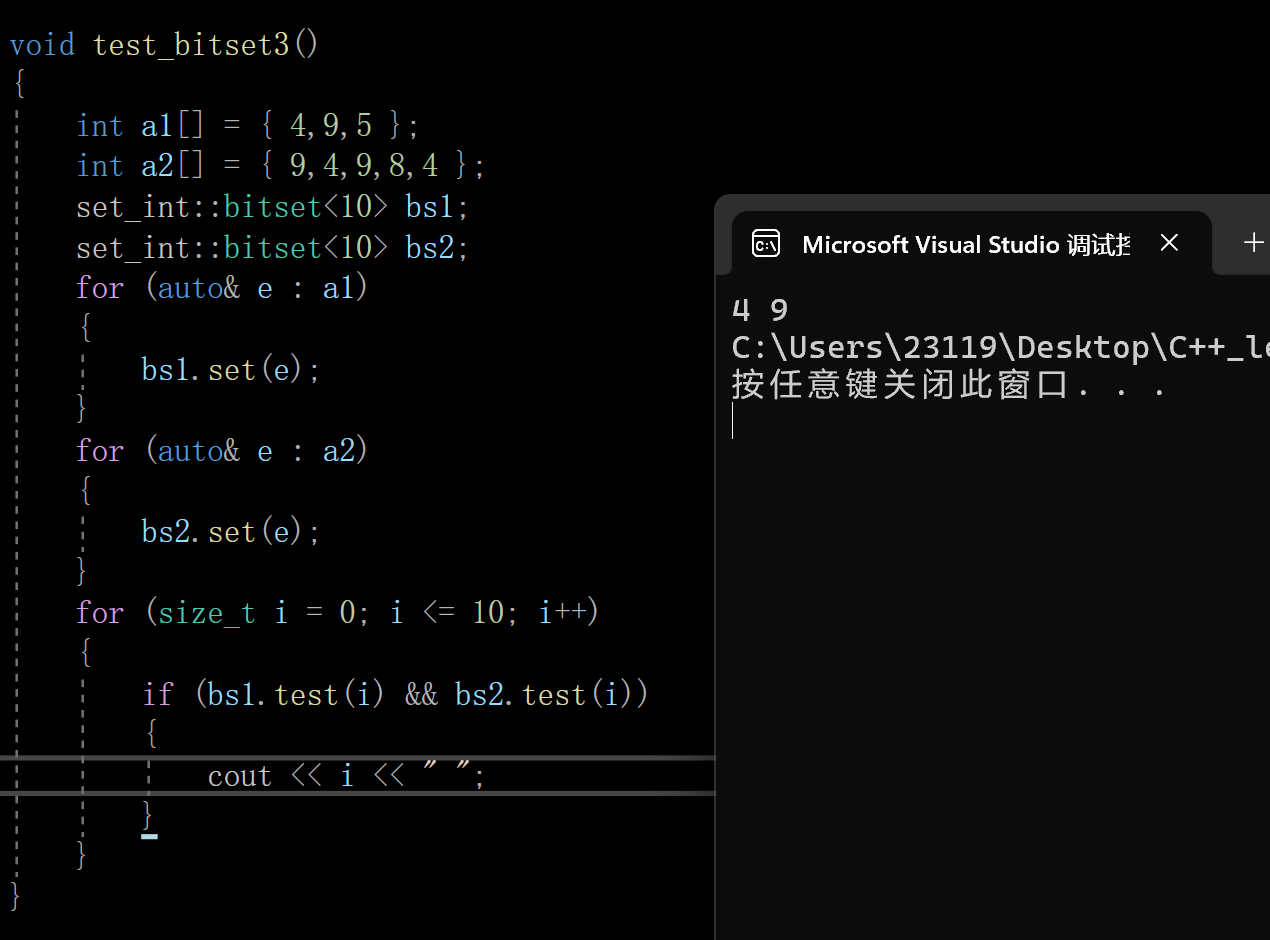
3.一个文件有100亿个整数,1G内存,设计算法找到出现次数不超过2次的所有整数
跟第一个问题的思路一样,只不过找的条件不一样
此时就需要记录超过2次的次数了
可以用11表示出现3次即以上的次数
然后稍稍改一下即可,这里就不赘述了
4.给定100亿个整数,0.5G内存,设计算法找到只出现一次的整数?
1.思路
这不还是第1题吗?
不是的,因为这里只有0.5G,而我们的一个位图是0.5G,需要使用2个位图才可以
因此按照第1题的思路来做的话,内存当中是存不下的
怎么办?
首先我们要知道:我们一定还是需要2个位图的,一个位图搞不定
而一共就只有0.5G内存,分配给2个位图的话
一个位图才只有0.25G啊,存不下0~2的32次方-1这么大的范围,只能存一半
此时我们发现,只能存一半,那么我一次存一半,一共存2次不就行了吗?
第一次位图当中只查找0到2的31次方-1的范围当中只出现1次的整数
第二次位图当中只查找2的31次方到2的32次方-1的范围当中只出现1次的整数不就行了吗?
只不过第二次存的时候,只存大于等于2的31次方的值,而且所有的值要先减去2的31次方再存入,然后取的时候取出来再加上2的31次方
因此我们就可以这样玩
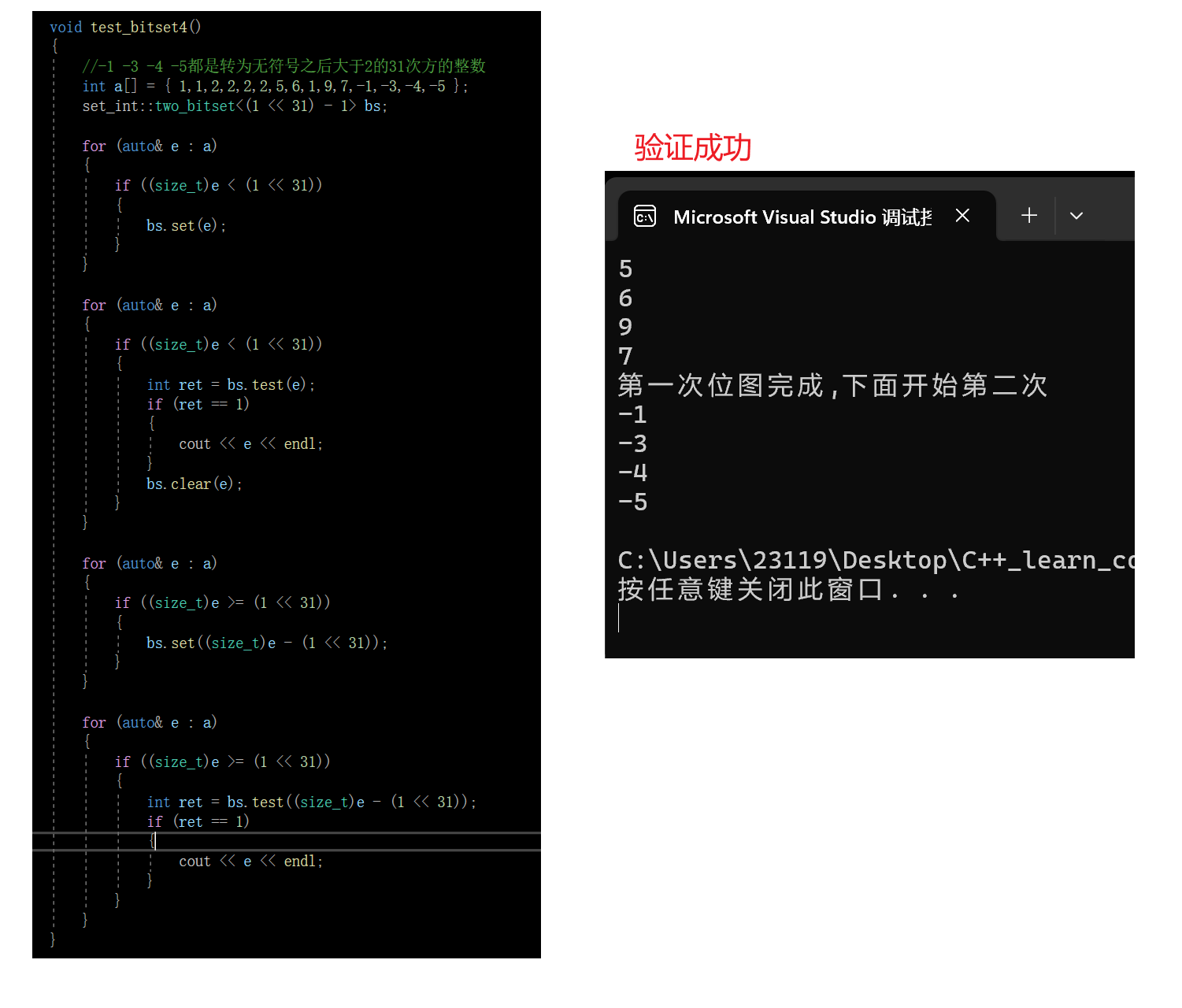
2.验证代码实现
因为第一次存完之后,存第二次之前要先把位图当中的原有数据清空
因此我们要提供一个clear操作,将位图当中的x对应的比特位置为0
void clear(int x)
{
_bits1.reset(x);
_bits2.reset(x);
}
void test\_bitset4()
{
//-1 -3 -4 -5都是转为无符号之后大于2的31次方的整数
int a[] = { 1,1,2,2,2,2,5,6,1,9,7,-1,-3,-4,-5 };
set_int::two_bitset<(1 << 31) - 1> bs;
for (auto& e : a)
{
if ((size_t)e < (1 << 31))
{
bs.set(e);
}
}
for (auto& e : a)
{
if ((size_t)e < (1 << 31))
{
int ret = bs.test(e);
if (ret == 1)
{
cout << e << endl;
}
bs.clear(e);
}
}
cout<<"第一次位图完成,下面开始第二次"<<endl;
for (auto& e : a)
{
if ((size_t)e >= (1 << 31))
{
bs.set((size_t)e - (1 << 31));
}
}
for (auto& e : a)
{
if ((size_t)e >= (1 << 31))
{
int ret = bs.test((size_t)e - (1 << 31));
if (ret == 1)
{
cout << e << endl;
}
}
}
}
二.布隆过滤器
这是知乎的一位大佬写的关于布隆过滤器的文章的开头的内容
我也觉得这句话写的特别好,分享给大家

我觉得不仅仅布隆过滤器是这句话的代表,我们后面要讲的哈希切分更是这句话典型的代表
完美的体现了对于数据结构选择的灵活性
1.布隆过滤器的提出
下面我们来分析一下,这种方法的准确性到底如何?
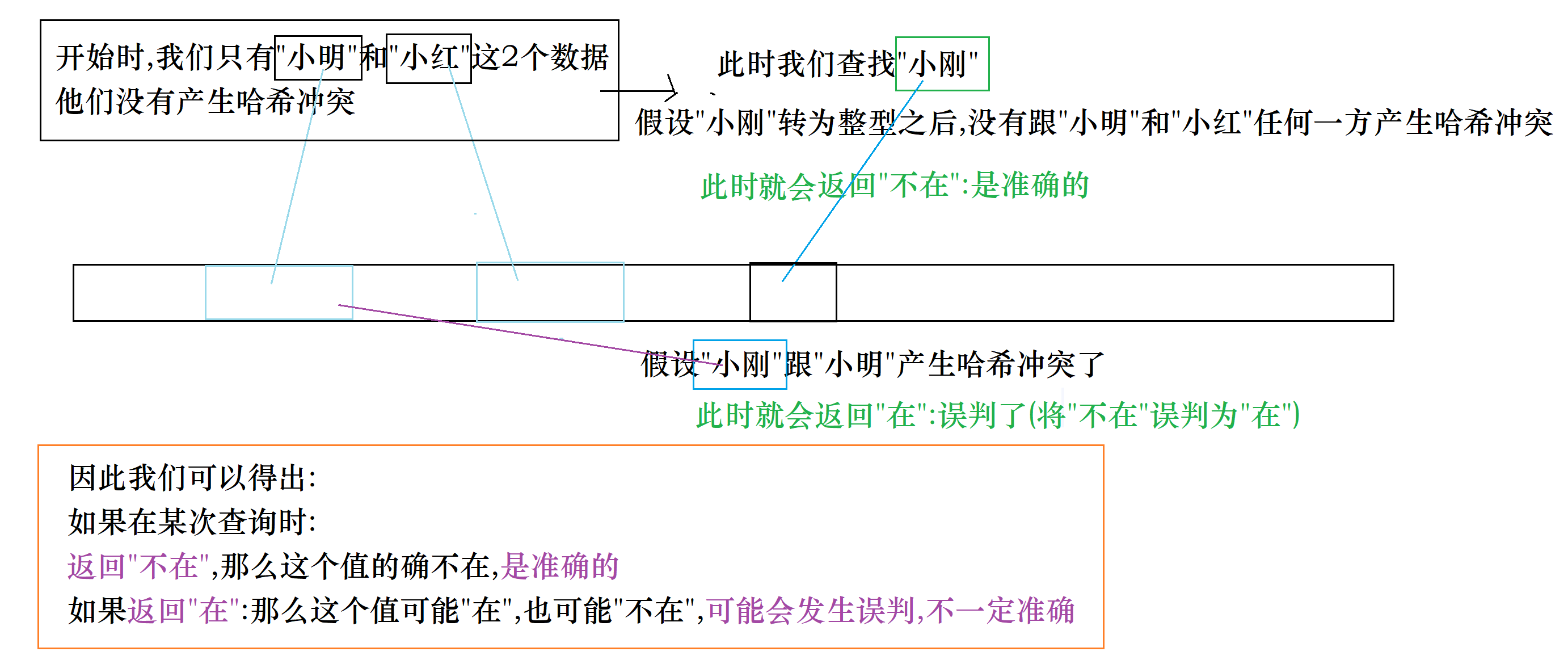
也就是说这个方法是走不通的,因为存在误判的可能
2.布隆过滤器的概念
但是布隆这个大佬是这么考虑的:
这个方法的确是行不通,但是这个方法对于不在的判定结果是准确的
那么我能否利用这个方法来进行一层过滤,把不在的完全过滤出去呢
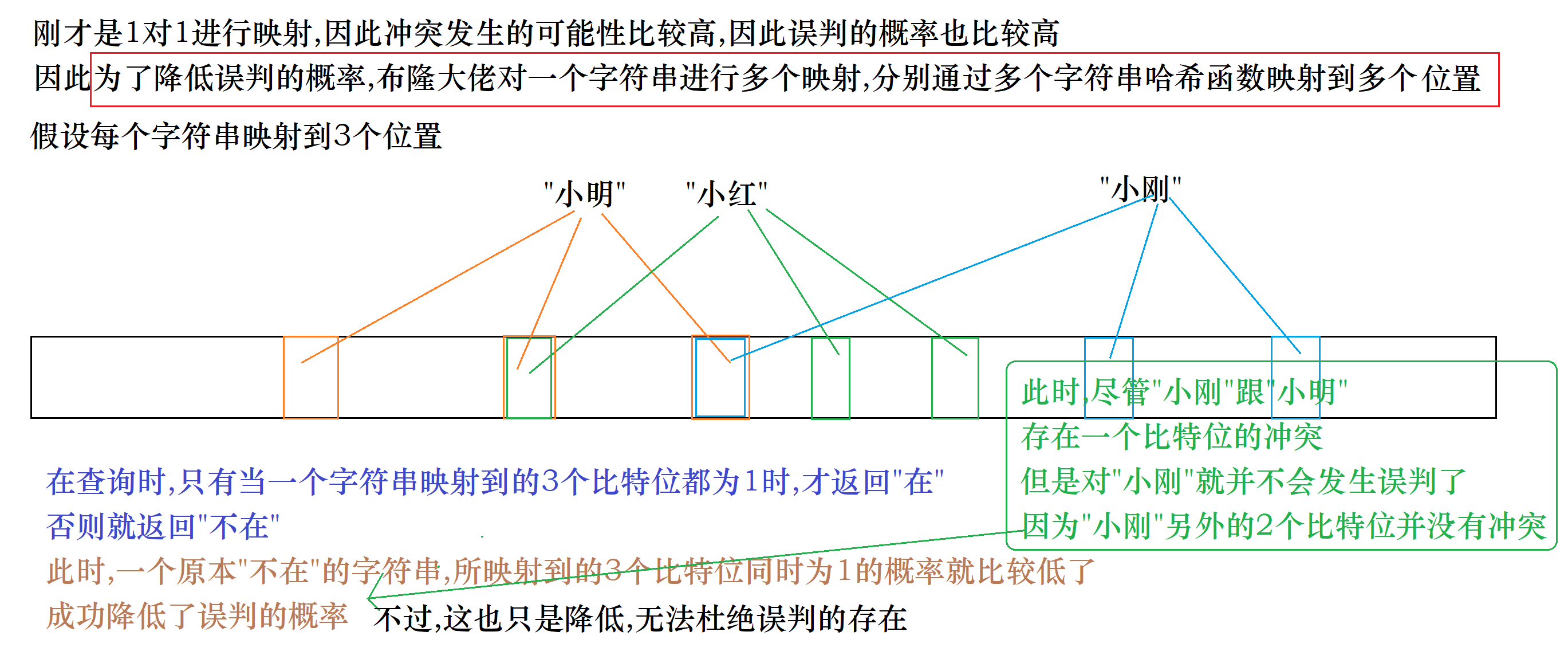
而这就是我们今天要介绍的布隆过滤器

3.布隆过滤器的应用场景
1.能够容忍误判的场景
对于一些能够容忍误判的场景(也就是能够接受把不在误判为在),这个方法完全可以
比如说:


2.无法容忍误判的场景
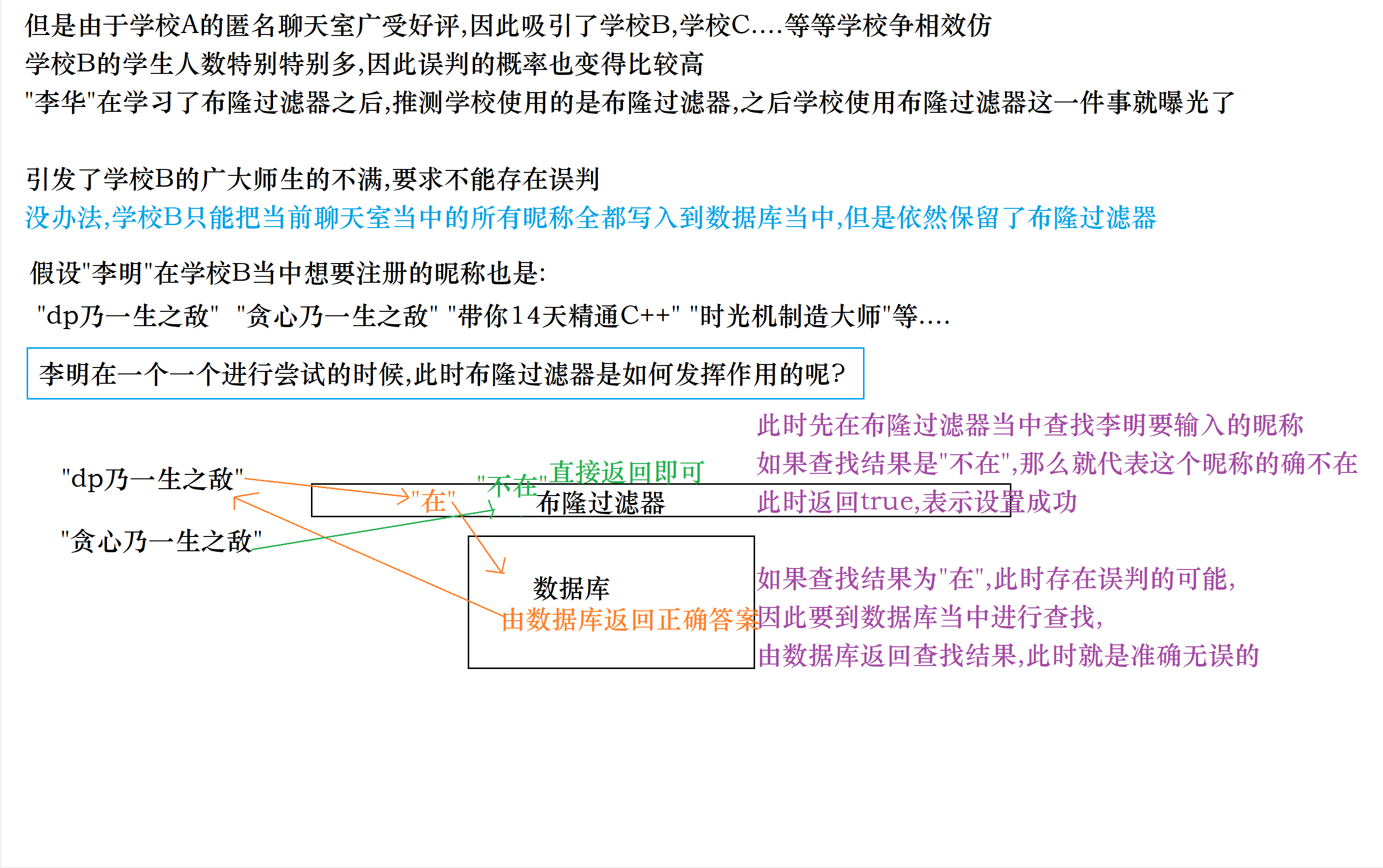
对于一些无法容忍误判的场景,这个方法可以提高我查询的效率
也就是如果判定为不在,那么这个字符串一定不在,直接返回即可
如果判断为在,那么我再去相应的数据库当中进行查找,看看这个字符串到底是不是真的存在
因此布隆过滤器才叫做"过滤器"嘛
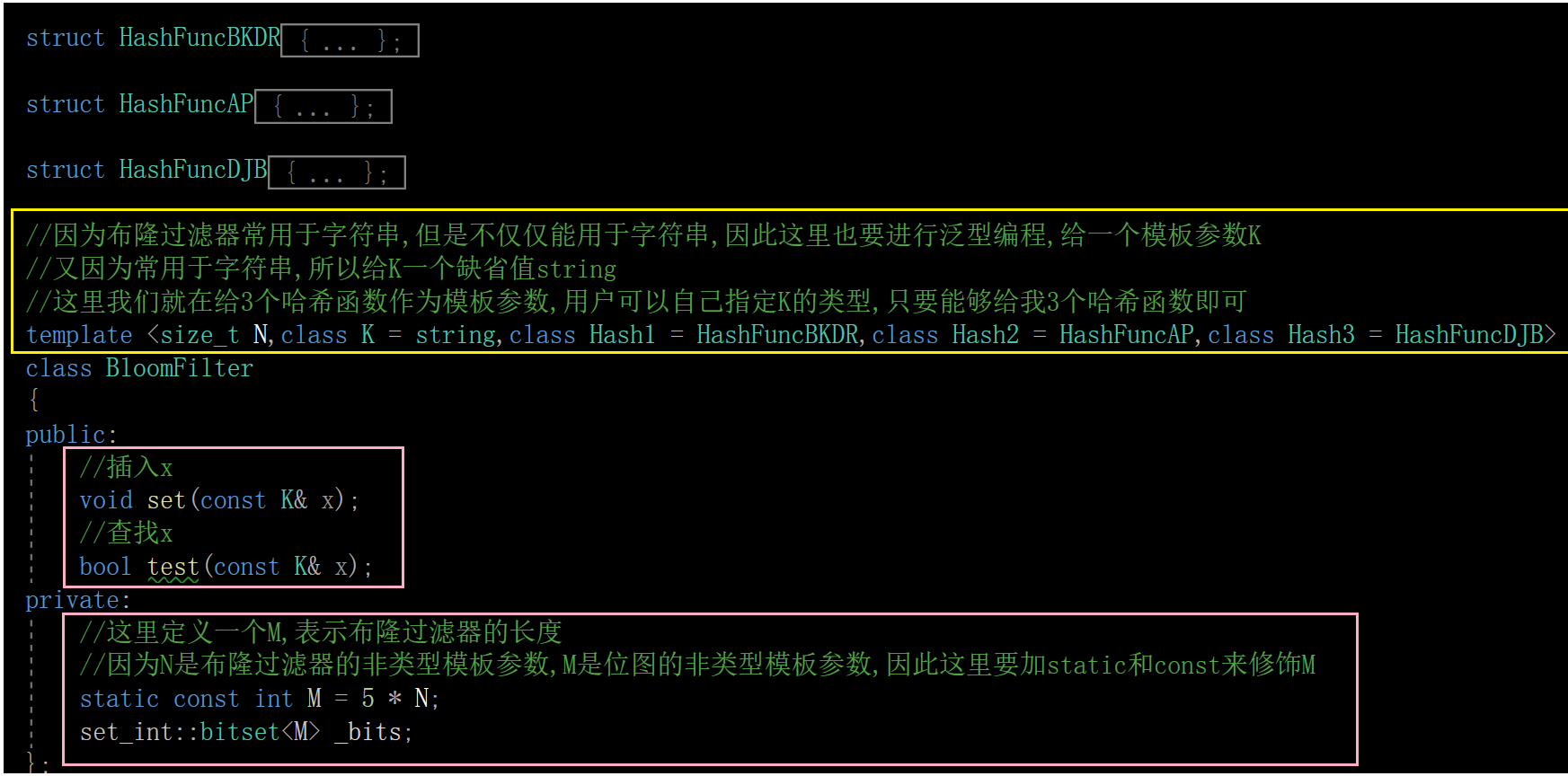
4.代码实现
下面我们来一起实现一下布隆过滤器吧
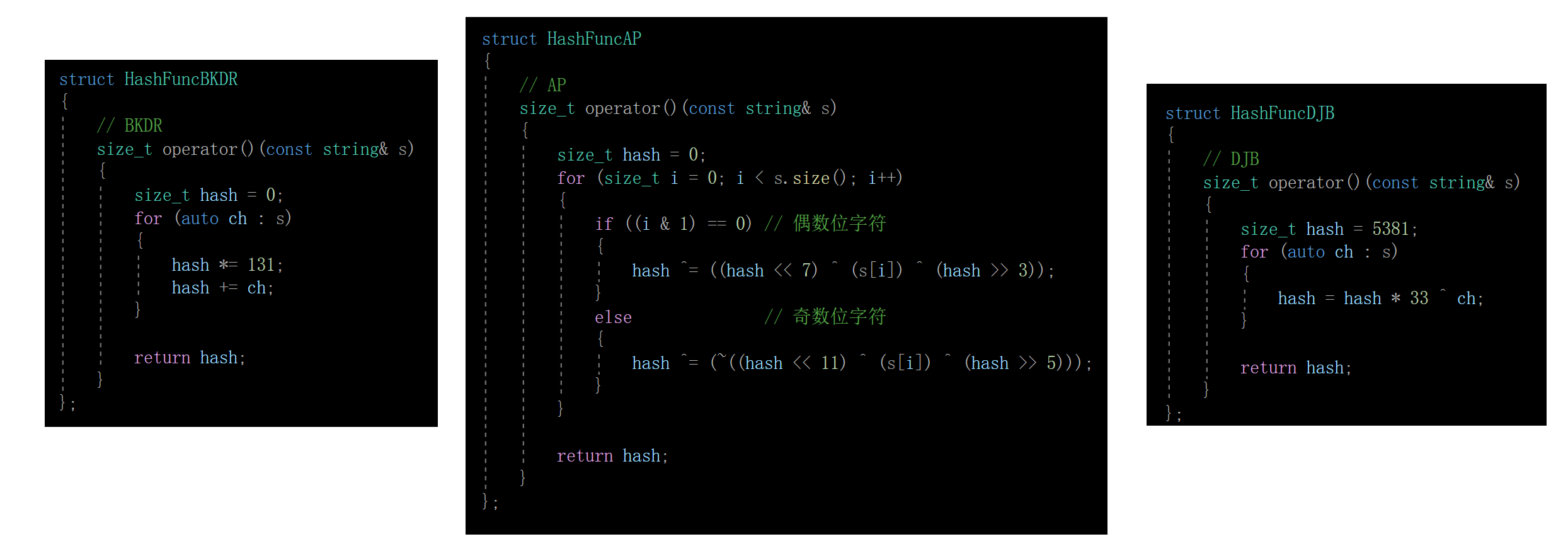
1.选择字符串哈希函数
很多大佬设计的很多字符串哈希算法:字符串哈希函数
我们就选上3个哈希函数吧
2.推导出布隆过滤器长度
这是知乎上的一位大佬写的关于布隆过滤器的一篇文章,感兴趣的话大家可以看一看
详解布隆过滤器的原理,使用场景和注意事项

3.大致结构
下面请大家思考一个问题:布隆过滤器支持删除吗?
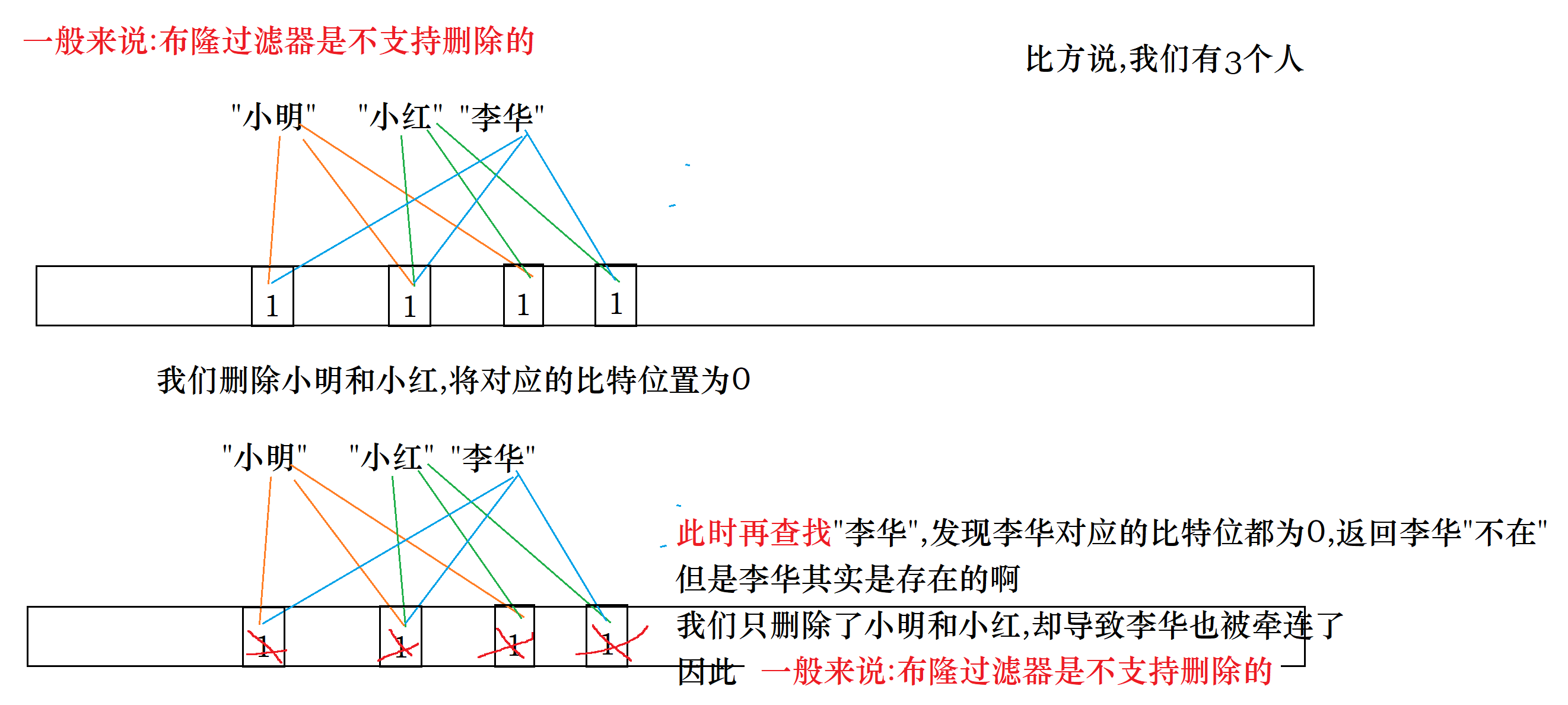
答案是:一般是不支持的
当然也可以支持,此时就不能用一个比特位来进行映射了,而要用一个char/int来进行映射,采用类似于引用计数的方式进行映射
不过那样做的缺陷是,本来一个比特位就能解决问题,现在要用8个甚至32个比特位才能解决问题,对于空间的消耗一下子扩大为8被甚至32倍
4.具体实现
1.set
//插入x
void set(const K& x)
{
//Hash1()是匿名对象,是仿函数对象,调用operator(),传入x作为参数
size_t hashi1 = Hash1()(x) % M, hashi2 = Hash2()(x) % M, hashi3 = Hash3()(x) % M;
//将3个比特位全部置为1即可
_bits.set(hashi1);
_bits.set(hashi2);
_bits.set(hashi3);
}
2.test
//查找x
bool test(const K& x)
{
//只要有一个比特位为0,就是false
//3个比特位都为1,返回true(但是存在误判)
size_t hashi1 = Hash1()(x) % M, hashi2 = Hash2()(x) % M, hashi3 = Hash3()(x) % M;
if (_bits.test(hashi1) == false) return false;
if (_bits.test(hashi2) == false) return false;
if (_bits.test(hashi3) == false) return false;
return true;
}
5.测试
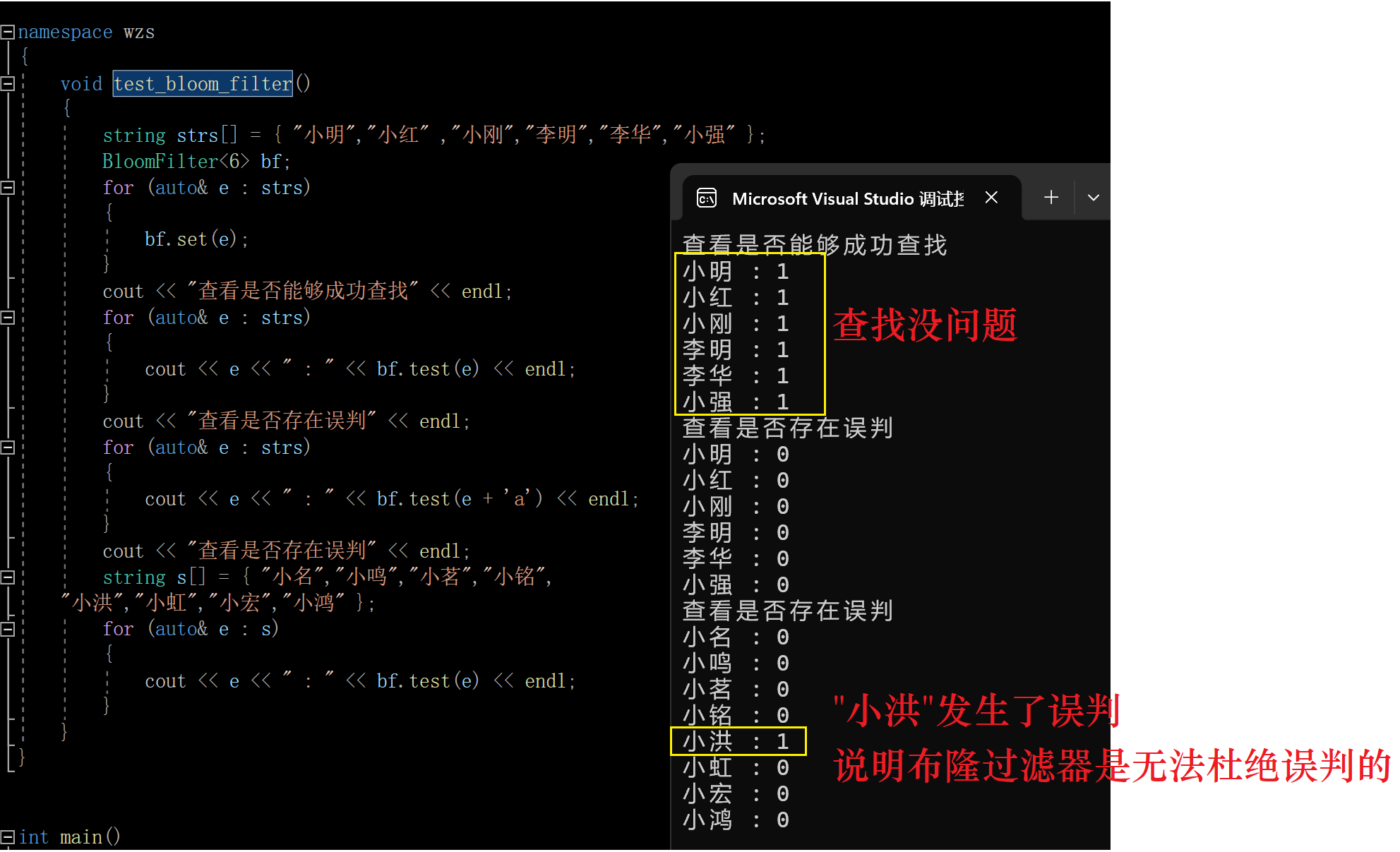
1.小型测试
void test\_bloom\_filter()
{
string strs[] = { "小明","小红" ,"小刚","李明","李华","小强" };
BloomFilter<6> bf;
for (auto& e : strs)
{
bf.set(e);
}
cout << "查看是否能够成功查找" << endl;
for (auto& e : strs)
{
cout << e << " : " << bf.test(e) << endl;
}
cout << "查看是否存在误判" << endl;
for (auto& e : strs)
{
cout << e << " : " << bf.test(e + 'a') << endl;
}
cout << "查看是否存在误判" << endl;
string s[] = { "小名","小鸣","小茗","小铭",
"小洪","小虹","小宏","小鸿" };
for (auto& e : s)
{
cout << e << " : " << bf.test(e) << endl;
}
}
2.大型测试
void test\_bloom\_filter2()
{
srand(time(0));
const size_t N = 1000000;//N是100万
BloomFilter<N> bf;
std::vector<std::string> v1;
std::string url = "https://zhuanlan.zhihu.com/p/43263751/";
for (size_t i = 0; i < N; ++i)
{
v1.push\_back(url + std::to\_string(i));
}
for (auto& str : v1)
{
bf.set(str);
}
// v2跟v1是相似字符串集(前缀一样),但是后缀不一样
std::vector<std::string> v2;
for (size_t i = 0; i < N; ++i)
{
std::string urlstr = url;
urlstr += std::to\_string(9999999 + i);
v2.push\_back(urlstr);
}
size_t n2 = 0;
for (auto& str : v2)
{
if (bf.test(str)) // 误判
{
++n2;
}
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;
// 不相似字符串集 前缀后缀都不一样
std::vector<std::string> v3;
for (size_t i = 0; i < N; ++i)
{
string url = "布隆过滤器";
url += std::to\_string(i + rand());
v3.push\_back(url);
}
size_t n3 = 0;
for (auto& str : v3)
{
if (bf.test(str))


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618668825)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
for (auto& str : v2)
{
if (bf.test(str)) // 误判
{
++n2;
}
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;
// 不相似字符串集 前缀后缀都不一样
std::vector<std::string> v3;
for (size_t i = 0; i < N; ++i)
{
string url = "布隆过滤器";
url += std::to\_string(i + rand());
v3.push\_back(url);
}
size_t n3 = 0;
for (auto& str : v3)
{
if (bf.test(str))
[外链图片转存中...(img-nDLwnlg9-1715545759817)]
[外链图片转存中...(img-sdcS0qHN-1715545759818)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618668825)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









