







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
+ - [1、空间预分配](#1_65)
- [2、惰性空间释放](#2_99)
- [3、二进制安全](#3_129)
- [4、兼容部分C字符串函数](#4C_139)
数据结构章节
- 数据库键总是一个字符串对象
- 数据库键的值可以是:
- 字符串对象
- 列表对象 list object
- 哈希对象 hash object
- 集合对象 set object
- 有序集合对象 sorted set object
SDS 数据结构
- redis 使用的一种名为简单动态字符串(simple dynamic string , SDS)的抽象类型,
用作redis的默认字符串标识。
struct sdshdr {
//记录buf 数组总已使用的字节的数量
//等于SDS所保存的字符串的长度
int len;
// 记录buf数组中未使用的字节的数量
int free;
// 字节数组,用于保存字符串(字节数组,字符数组,勿混淆)
char buf[]
}
*
如果执行sdscat(s, " Cluster");
目前s的空间不足以拼接,遂sdscat 会先扩展s的空间,然后再执行拼接操作。
拼接完成后的SDS如下图:

sdscat 不仅对这个SDS 进行了拼接的操作,还为SDS分配了13字节的未使用空间,并且拼接之后的字符串也正好是13字节长, 这不是BUG也不是巧合,她和SDS的空间分配策略有关
- 普通的C字符串的缺陷:
因为C字符串并不记录自身的长度,所以对于一个包含了N个字符的C字符串来说,底层实现总是一个N+1个字符长的数组。
因此,每次增长或缩短一个C字符串,程序都总要对保存这个C字符串的数组进行一次内存分重分配的操作:
+ 如果程序执行的是增长字符串的操作,比如拼接操作,那么程序需要在执行操作之前先通过内存重分配来 **扩展底层数组的空间大小**——如果忘记这一步, 就会产生 **缓冲区溢出**
+ 如果程序执行的是缩短字符串的操作,比如截断操作,那么程序需要再执行操作之前先通过内存重分配来 **释放字符串不再使用的那部分空间**——如果忘记这一步,就会产生 **内存泄漏**
*因为内存重分配涉及复杂的算法(具体是什么呢?待了解)***并且可能需要执行系统调用,所以它通常是一个比较耗时的操作。
所以,为了避免C字符串的这种缺陷,SDS通过未使用空间解除了字符串长度和低层数组长度之间的关联:在SDS中,buf数组的长度不一定就是字符数量加一,数组里面可以包含没使用的字节,由SDS的free属性记录
通过未使用空间,SDS实现了空间预分配和惰性空间释放的两种优化策略。
1、空间预分配
- 空间预分配用于优化SDS的字符串增长操作:当SDS的API 对一个SDS进行修改,并且需要对SDS进行空间扩展的时候,程序不仅会为SDS分配修改所必须要的空间,还会为SDS分配额外的未使用空间。
其中,额外分配的未使用空间数量由一下公式决定:
+ 如果对SDS进行修改后,SDS的长度(len属性的值)将小于1MB,那么程序分配和len属性同样大小的未使用空间,即free 和 len 值相同,eg:如果进行修改后SDS的len将变成13字节,那么free 也将是13 ,那SDS的buf数组的实际长度将变为:
13+13+1=27字节(**不要忘记最后一个字节的空字符**)
+ 如果对SDS进行修改之后,SDS的长度将大于等于1MB,那么程序将会分配1MB的未使用空间
+ **总结:free 的大小在SDS进行空间扩展时,将会变化成不超过1MB的数值**
- 案例:

执行sdscat(s, " Cluster");

执行sdscat(s, " Tutorial");
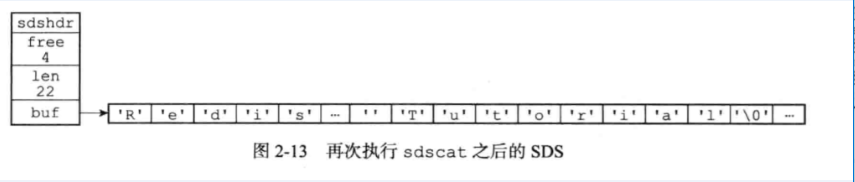
注意三张图中,free,len,buf的内容变化!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
.csdn.net/topics/618668825)**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









