






网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
而 SQL 对 JOIN 的定义中没有主键的约定,就不能认定与事实表中外键关联的维表记录有唯一性,有可能发生与多条记录关联的情况。对于订单表的记录来讲,eid 值没有办法唯一对应一条雇员记录,就无法做到外键地址化了。而且 SQL 也没有记录地址这种数据类型,结果会导致每次关联时还是要计算 HASH 值并比对。
只是两个表 JOIN 时,外键地址化和 HASH 关联的差别还不是非常明显。这是因为 JOIN 并不是最终目的,JOIN 之后还会有其它很多运算,JOIN 本身运算消耗时间的占比相对不大。但事实表常常会有多个维表,甚至维表还会有很多层。比如订单关联产品,产品关联供应商,供应商关联城市,城市关联国家等等。在关联表很多时,外键地址化的性能优势会更明显。
下面的测试,在关联表个数不同的情况下对比 SPL 与 Oracle 的性能差异,可以看出在表很多时,外键地址化的优势相当明显:
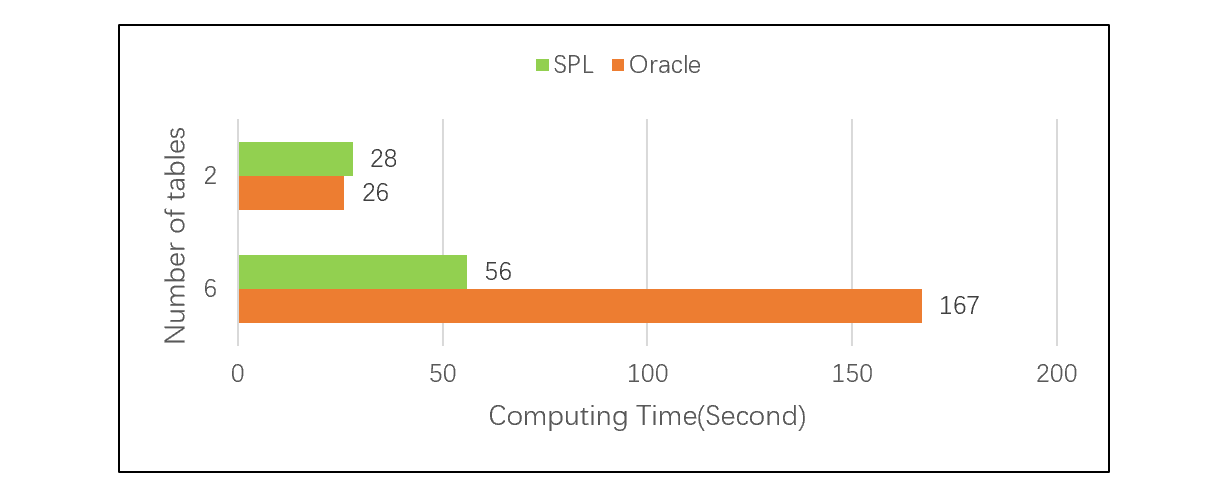
测试的详细情况请参考:性能优化技巧:预关联。
对于只有维表能装入内存,而事实表很大需要外存的情况,SPL 提供了外键序号化方法:预先将事实表中的外键字段值转换为维表对应记录的序号。关联计算时,分批读入新事实表记录,再用序号取出对应维表记录。
以上述订单表、产品表为例,假定产品表已经装入内存,订单表存储在外存中。外键序号化的过程是这样:先读入一批订单数据,设其中某记录 r 中的 pid 对应的是内存中产品表的第 i 条记录。我们要将 r 中的 pid 字段值转换为 i。对这批订单记录都完成这样的转换后,再做关联计算时,从外存中分批读入订单数据。对于其中的记录 r,就可以直接根据 pid 值,去内存中的产品表里用位置取出相应的记录,也避免了查找动作。
外键序号化原理更详细的介绍参考:【性能优化】6.3 [外键关联] 外键序号化。
数据库通常会把小表读入内存,再分批读入大表数据,用哈希算法做内存连接,需要计算哈希值和比对。而 SPL 使用序号定位是直接读取,不需要进行任何比对,性能优势比较明显。虽然预先把事实表的外键字段转换成序号需要一定成本,但这个预计算只需要做一次,而且可以在多次外键关联中得到复用。
SPL 外键序号化同样利用了维表关联字段是主键的特征。如前所述,SQL 对 JOIN 的定义没有主键的约定,无法利用这一特征做到外键序号化。另外,SQL 使用无序集合的概念,即使我们事先把外键序号化了,数据库也无法利用这个特点,不能在无序集合上使用序号快速定位的机制,最快也就是用索引查找。而且,数据库并不知道外键被序号化了,仍然会去计算 HASH 值和比对。
下面这个测试,在不同并行数情况下,对比 SPL 和 Oracle 完成大事实表、小维表关联计算的速度,SPL 跑的比 Oracle 快 3 到 8 倍。测试结果见下图:
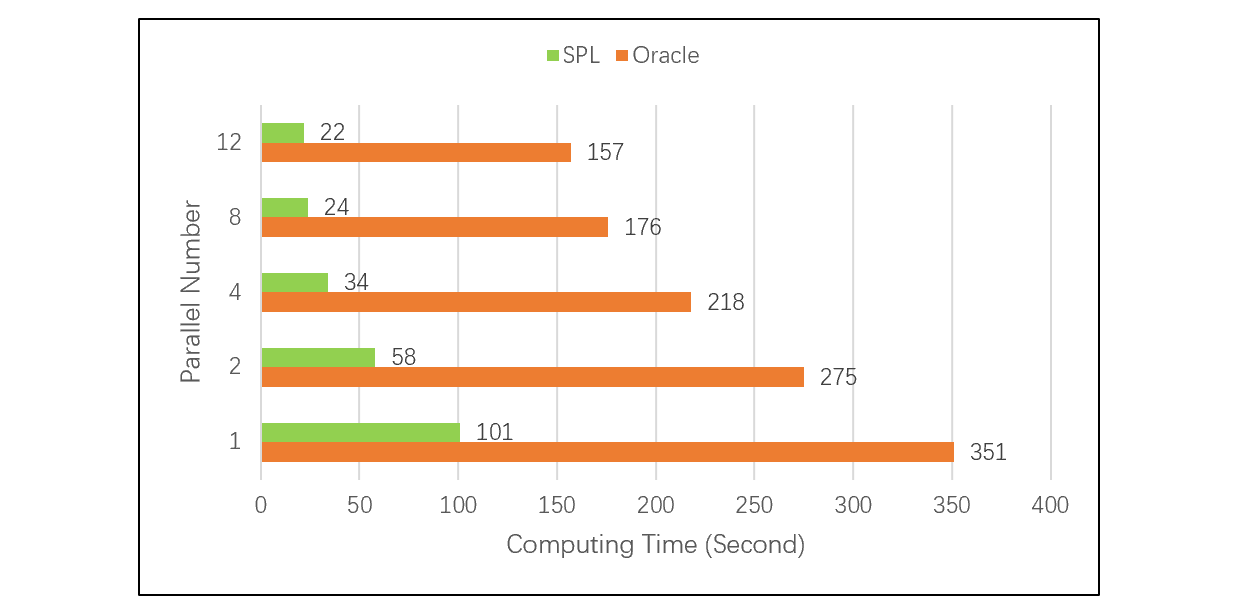
这个测试更详细的信息请参考:性能优化技巧:外键序号化。
如果维表很大也需要外存,而事实表较小能装入内存,SPL 则提供了大维表查找机制。如果维表和事实表都很大,SPL 则使用单边分堆算法。对于维表过滤后再关联的情况,SPL 提供了索引复用方法及对位序列等方法。
数据量大到需要分布式计算时,如果维表较小,SPL 采用复写维表机制,将维表在集群节点上复制多份;如果维表很大,则采用集群维表方法以保证随机访问。这两种方法都可以有效的避免 Shuffle 动作。相比而言,SQL 体系下不能区分出维表,HASH 拆分方法要将两个表都做 Shuffle 动作,网络传输量要大得多。
主键关联
主键关联涉及的表一般都比较大,需要存储在外存中。SPL 为此提供了有序归并方法:预先将外存表按照主键有序存储,关联时顺序取出数据做归并计算。
以客户和 VIP 客户两个表做内连接为例,假设已经预先将两个表按照主键 cid 有序存储在外存中。关联时,从两个表的游标中读取记录,逐条比较 cid 值。如果 cid 相等,则将两表的记录合并成结果游标的一条记录返回。如果不相等,则 cid 小的那个游标再读取记录,继续判断。重复这些动作直到任何一个表的数据被取完,返回的游标就是 JOIN 的结果。
对于两个大表关联,数据库通常使用哈希分堆算法,复杂度是乘法级的。而有序归并算法复杂度是加法级,性能会好很多。而且,数据库做大数据的外存运算时,哈希分堆会产生缓存文件的读写动作。有序归并算法则只需要对两个表依次遍历,不必借助外存缓存,可以大幅降低 IO 量,有巨大的性能优势。
预先按照主键排序的成本虽高,但是一次性做好即可,以后就总能使用归并算法实现 JOIN,性能可以提高很多。同时,SPL 也提供了在有追加数据时仍然保持数据整体有序的方案。
这类 JOIN 的特征在于关联字段是主键或部分主键,有序归并算法正是根据这个特征来设计的。因为不管是同维表还是主子表,关联字段都不会是主键之外的其他字段,所以我们将关联表按照主键有序这一种方式排序存储就可以了,不会出现冗余。而外键关联就不具备这个特征,不能使用有序归并。具体来说,是因为事实表的关联字段不是主键,会存在多个要参与关联的外键字段,我们不可能让同一个事实表同时按多个字段都有序。
SQL 对 JOIN 的定义不区分 JOIN 类型,不假定某些 JOIN 总是针对主键的,就没办法从算法层面上利用主键关联的特征。而且,前面说过 SQL 基于无序集合概念,数据库不会刻意保证数据的物理有序性,很难实施有序归并算法。
有序归并算法的优势还在于易于分段并行。以订单和订单明细按 oid 关联为例,假如将两表都按照记录数大致平均分为 4 段,订单第 2 段的 oid 有可能会出现在明细第 3 段,类似的错位会导致错误的计算结果。SPL 再次利用主键 oid 的有序性,提供同步分段机制,解决了这个问题:先将有序的订单表分为 4 段,再找到每一段起止记录的 oid 值形成 4 个区间,将明细表也分成同步的 4 段。这样,在并行计算时两表对应分段就不会出现错位了。由于明细表也对 oid 有序,可以迅速地按照起止 oid 定位,不会降低有序归并的性能。
有序归并和同步分段并行的原理,详见:SPL 有序归并关联。
传统的 HASH 分堆技术实现并行就比较困难了,多线程做 HASH 分堆时需要同时向某个分堆写出数据,造成共享资源冲突;而下一步实现某组分堆关联时又会消费大量内存,无法实施较大的并行数量。
实际测试证明,在相同情况下,我们对两个大表做主键关联测试(详情参见性能优化技巧:有序归并),结果是 SPL 比 Oracle 快了近 3 倍:
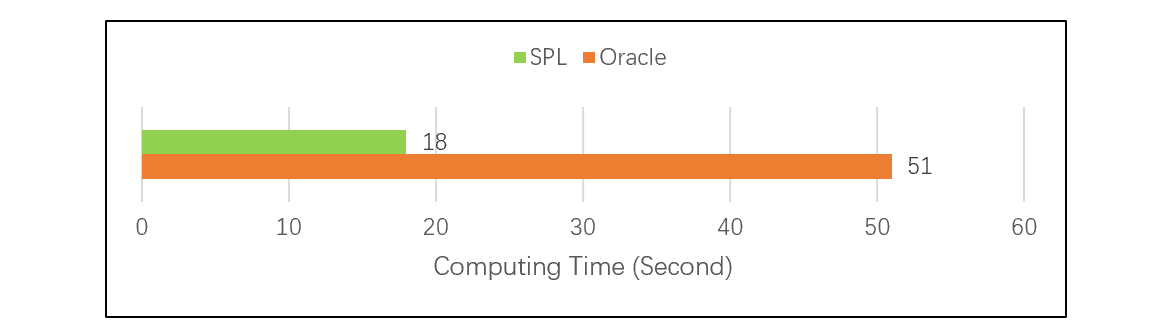
除了有序归并,SPL 还提供了很多高性能算法,全面提高主键关联 JOIN 的计算速度。包括:附表机制,可以将多表一体化存储,减少存储数据量的同时,还相当于预先完成了关联,不需要再比对了;关联定位算法,实现先过滤再关联,可以避免全表遍历,获得更好的性能等等。
当数据量继续增加,需要多台服务器集群时,SPL 提供复组表机制,将需要关联的大表按照主键分布到集群节点上。相同主键的数据在同一节点,避免分机之间的数据传输,也不会出现 Shuffle 动作。
回顾与总结
回顾上面两大类、各场景 JOIN,采用 SPL 分情况提供的高性能算法,可以利用不同类型 JOIN 的特征提速,让 JOIN 跑得更快。SQL 对上述这么多种 JOIN 场景笼统的处理,就没办法针对不同 JOIN 的特征来实施这些高性能算法。比如:事实表和维表都装入内存时,SQL 只能按照键值计算 HASH 和比对,无法利用地址直接对应;SQL 数据表无序,在大表按照主键关联时无法做到有序归并,只能使用 HASH 分堆,有可能会出现多次缓存的现象,性能有一定的不可控性。
并行计算方面,SQL 单表计算时还容易做到分段并行,多表关联运算时一般就只能事先做好固定分段,很难做到同步动态分段,这就难以根据机器的负载临时决定并行数量。
对于集群运算也是这样,SQL 在理论上不区分维表和事实表,要实现大表 JOIN 就会不可避免地产生占用大量网络资源的 HASH Shuffle 动作,在集群节点数太多时,网络传输造成的延迟会超过节点多带来的好处。
SPL 设计并应用了新的运算和存储模型,可以在原理和实现上解决 SQL 的这些问题。对于 JOIN 的不同分类和场景,程序员有针对性的采取上述高性能算法,就能获得更快的计算速度,让 JOIN 跑得更快。
SPL资料

欢迎对SPL有兴趣的加小助手(VX号:SPL-helper),进SPL技术交流群
文末送书
赠送书籍: 《数据结构和算法基础》 (也可以任选其他的书籍)
赠书数量:5
参与方式:点赞+收藏+评论本文之后
微信私聊石臻臻暗号:13 (因为是石臻臻日常撒书第13期) 博主通过好友之后,会将大家拉到一个小群里面,凭运气抽奖 为了让中奖率限制在25%,会限制参与人数。
也可以任选下面其他书籍
1,自然语言处理NLP从入门到项目实战(Python语言实现)
2,数据结构和算法基础(Java语言实现)
3,架构基础:从需求到架构
4,元宇宙
5,统计分析:以R语言为工具
6,Web渗透攻防实战
7,Python Web开发从入门到精通
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618668825)**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









