







通过多组 L1 读取性能提升,能够抗住峰值、突发流量,而且成本会大大降低。
对读写策略,采取多写,读的话采用逐层穿透,如果 Miss 的话就进行回写。对存在里面的数据,我们最初采用 Json/xml,2012 年之后就直接采用 Protocol Buffer 格式,对一些比较大的用 QuickL 进行压缩。
集合类数据
======

刚才讲到简单的 QA 数据,那对于复杂的集合类数据怎么来处理?
比如我关注了 2000 人,新增 1 个人,就涉及到部分修改。有一种方式是把 2000 个 ID 全部拿下来进行修改,但这种对带宽、机器压力会很大。
还有一些分页获取,我存了 2000 个,只需要取其中的第几页,比如第二页,也就是第十到第二十个,能不能不要全量把所有数据取回去。
还有一些资源的联动计算,会计算到我关注的某些人里面 ABC 也关注了用户 D。这种涉及到部分数据的修改、获取,包括计算,对 MC 来说实际上是不太擅长的。
各种关注关系都存在 Redis 里面取,通过 Hash 分布、储存,一主多从的方式来进行读写分离。现在 Redis 的内存大概有 30 个 T,每天都有 2-3 万亿的请求。
在使用 Redis 的过程中,实际上还是遇到其他一些问题。比如从关注关系,我关注了 2000 个 UID,有一种方式是全量存储。
但微博有大量的用户,有些用户登录得比较少,有些用户特别活跃,这样全部放在内存里成本开销是比较大的。
所以我们就把 Redis 使用改成 Cache,比如只存活跃的用户,如果你最近一段时间没有活跃,会把你从 Redis 里踢掉,再次有访问的时候再把你加进来。
这时存在一个问题,因为 Redis 工作机制是单线程模式,如果它加某一个 UV,关注 2000 个用户,可能扩展到两万个 UID,两万个 UID 塞回去基本上 Redis 就卡住了,没办法提供其他服务。
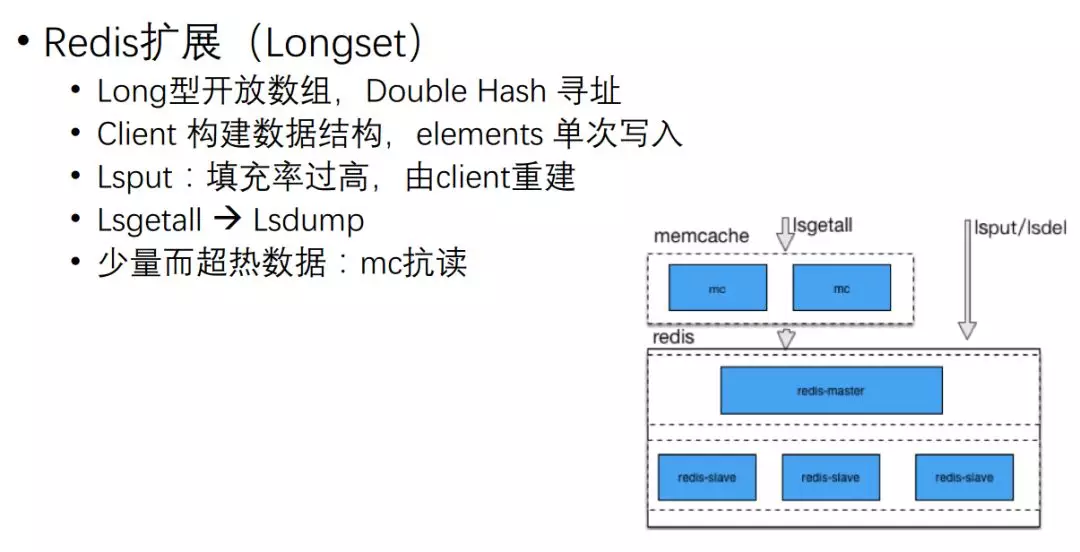
所以我们扩展一种新的数据结构,两万个 UID 直接开了端,写的时候直接依次把它写到 Redis 里面去,读写的整个效率就会非常高。
它的实现是一个 long 型的开放数组,通过 Double Hash 进行寻址。

我们对 Redis 进行了一些其他的扩展,大家可能也在网上看到过我们之前的一些分享,把数据放到公共变量里面。
整个升级过程,我们测试 1G 的话加载要 10 分钟,10G 大概要 10 分钟以上,现在是毫秒级升级。
对于 AOF,我们采用滚动的 AOF,每个 AOF 是带一个 ID 的,达到一定的量再滚动到下一个 AOF 里去。
对 RDB 落地的时候,我们会记录构建这个 RDB 时,AOF 文件以及它所在的位置,通过新的 RDB、AOF 扩展模式,实现全增量复制。
其他数据类型:计数
==========
接下来还有一些其他的数据类型,比如一个计数,实际上计数在每个互联网公司都可能会遇到,对一些中小型的业务来说,实际上 MC 和 Redis 足够用的。
**但在微博里计数出现了一些特点:**单条 Key 有多条计数,比如一条微博,有转发数、评论数,还有点赞;一个用户有粉丝数、关注数等各种各样的数字。
因为是计数,它的 Value size 是比较小的,根据它的各种业务场景,大概就是 2-8 个字节,一般 4 个字节为多。
然后每日新增的微博大概十亿条记录,总记录就更可观了,然后一次请求,可能几百条计数要返回去。

计数器 Counter Service
====================
最初是可以采取 Memcached,但它有个问题,如果计数超过它内容容量时,会导致一些计数的剔除,宕机或重启后计数就没有了。
另外可能有很多计数它为零,那这个时候怎么存,要不要存,存的话就占很多内存。
微博每天上十亿的计数,光存 0 都要占大量的内存,如果不存又会导致穿透到 DB 里去,对服务的可溶性会存在影响。
2010 年之后我们又采用 Redis 访问,随着数据量越来越大之后,发现 Redis 内存有效负荷还是比较低的,它一条 KV 大概需要至少 65 个字节。
但实际上我们一个计数需要 8 个字节,然后 Value 大概 4 个字节,所以有效只有 12 个字节,还有四十多个字节都是被浪费掉的。
这还只是单个 KV,如果在一条 Key 有多个计数的情况下,它就浪费得更多了。
比如说四个计数,一个 Key 8 个字节,四个计数每个计数是 4 个字节,16 个字节大概需要 26 个字节就行了,但是用 Redis 存大概需要 200 多个字节。
后来我们通过自己研发的 Counter Service,内存降至 Redis 的五分之一到十五分之一以下,而且进行冷热分离,热数据存在内存里,冷数据如果重新变热,就把它放到 LRU 里去。
落地 RDB、AOF,实现全增量复制,通过这种方式,热数据单机可以存百亿级,冷数据可以存千亿级。
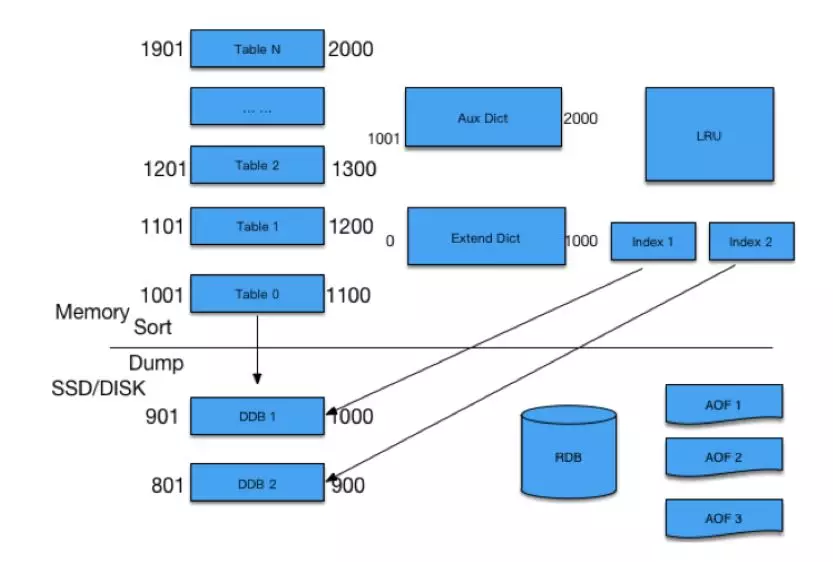
整个存储架构大概是上图这样,上面是内存,下面是 SSD,在内存里是预先把它分成 N 个 Table,每个 Table 根据 ID 的指针序列,划出一定范围。
任何一个 ID 过来先找到它所在的 Table,如果有直接对它增增减减,有新的计数过来,发现内存不够的时候,就会把一个小的 Table Dump((内存信息)转储,转存 ) 到 SSD 里去,留着新的位置放在最上面供新的 ID 来使用。
有些人疑问说,如果在某个范围内,我的 ID 本来设的计数是 4 个字节,但是微博特别热,超过了 4 个字节,变成很大的一个计数怎么处理?
对于超过限制的,我们把它放在 Aux dict 进行存放,对于落在 SSD 里的 Table,我们有专门的 IndAux 进行访问,通过 RDB 方式进行复制。
其他数据类型:存在性判断
=============

除了计数,微博还有一些业务,一些存在性判断。比如一条微博展现的,有没有点赞、阅读、推荐,如果这个用户已经读过这个微博了,就不要再显示给他。
这种有一个很大的特点,它检查是否存在,每条记录非常小,比如 Value 1 个 bit 就可以了,但总数据量巨大。
比如微博每天新发表微博 1 亿左右,读的可能有上百亿、上千亿这种总的数据需要判断。
怎么来存储是个很大的问题,而且这里面很多存在性就是 0。还是前面说的,0 要不要存?
如果存了,每天就存上千亿的记录;如果不存,那大量的请求最终会穿透 Cache 层到 DB 层,任何 DB 都没办法抗住那么大的流量。

**我们也进行了一些选型:**首先直接考虑能不能用 Redis。单条 KV 65 个字节,一个 KV 可以 8 个字节的话,Value 只有 1 个 bit,这样算下来每日新增内存有效率是非常低的。
第二种我们新开发的 Counter Service,单条 KV Value 1 个 bit,我就存 1 个 byt,总共 9 个 byt 就可以了。
这样每日新增内存 900G,存的话可能就只能存最新若干天的,存个三天差不多快 3 个 T 了,压力也挺大,但比 Redis 已经好很多。
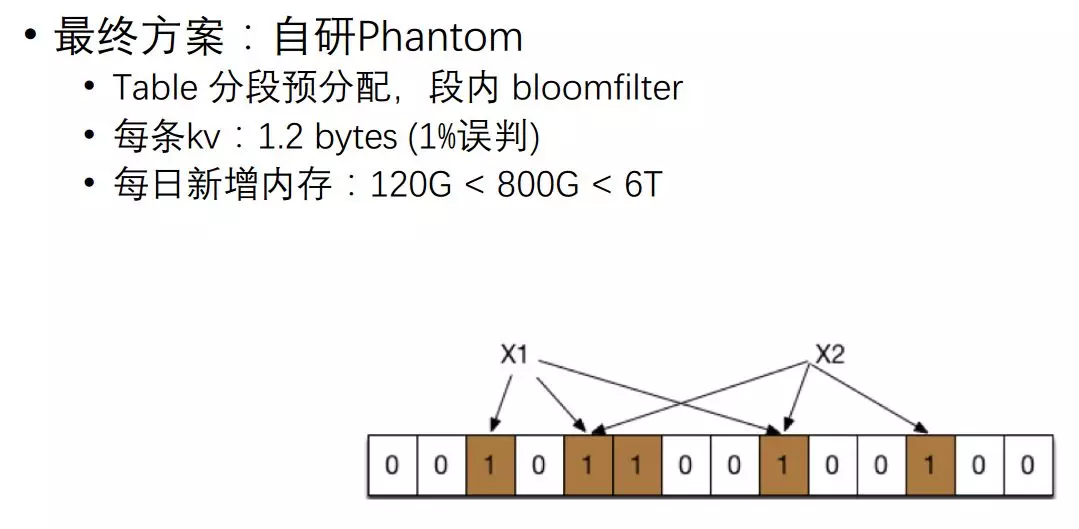
我们最终方案是自己开发 Phantom,先采用把共享内存分段分配,最终使用的内存只用 120G 就可以。
算法很简单,对每个 Key 可以进行 N 次哈希,如果哈希的某一个位它是 1,那么进行 3 次哈希,三个数字把它设为 1。
把 X2 也进行三次哈希,后面来判断 X1 是否存在的时候,从进行三次哈希来看,如果都为 1 就认为它是存在的;如果某一个哈希 X3,它的位算出来是 0,那就百分百肯定是不存在的。
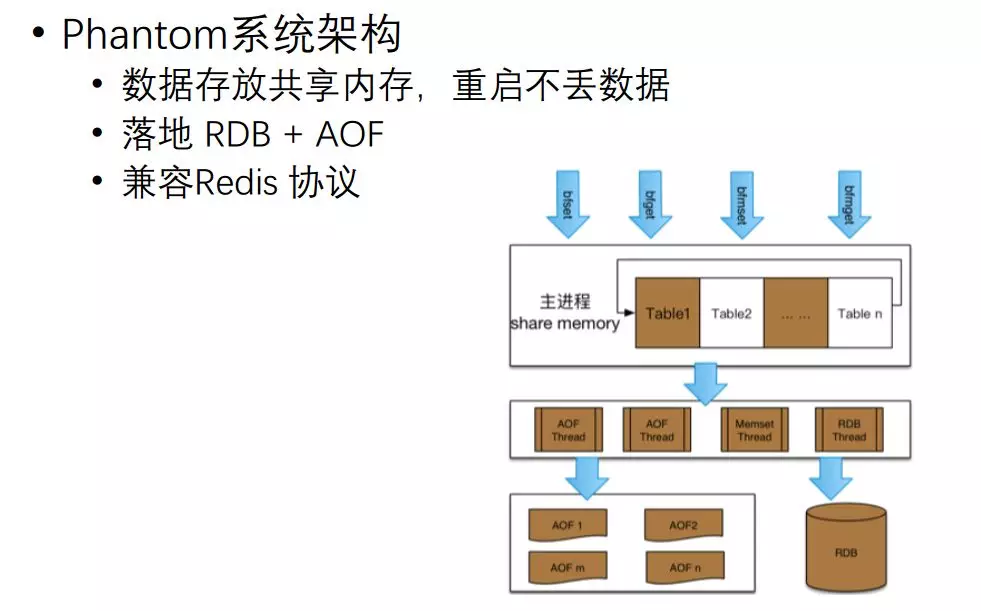
它的实现架构比较简单,把共享内存预先拆分到不同 Table 里,在里面进行开方式计算,然后读写,落地的话采用 AOF+RDB 的方式进行处理。
整个过程因为放在共享内存里面,进程要升级重启数据也不会丢失。对外访问的时候,建 Redis 协议,它直接扩展新的协议就可以访问我们这个服务了。

**小结一下:**到目前为止,我们关注了 Cache 集群内的高可用、扩展性、组件高性能,还有一个特别重要就是存储成本,还有一些我们没有关注到的,比如运维性如何,微博现在已经有几千差不多上万台服务器等。
进一步优化
======

服务化
====

采取的方案首先就是对整个 Cache 进行服务化管理,对配置进行服务化管理,避免频繁重启,另外如果配置发生变更,直接用一个脚本修改一下。
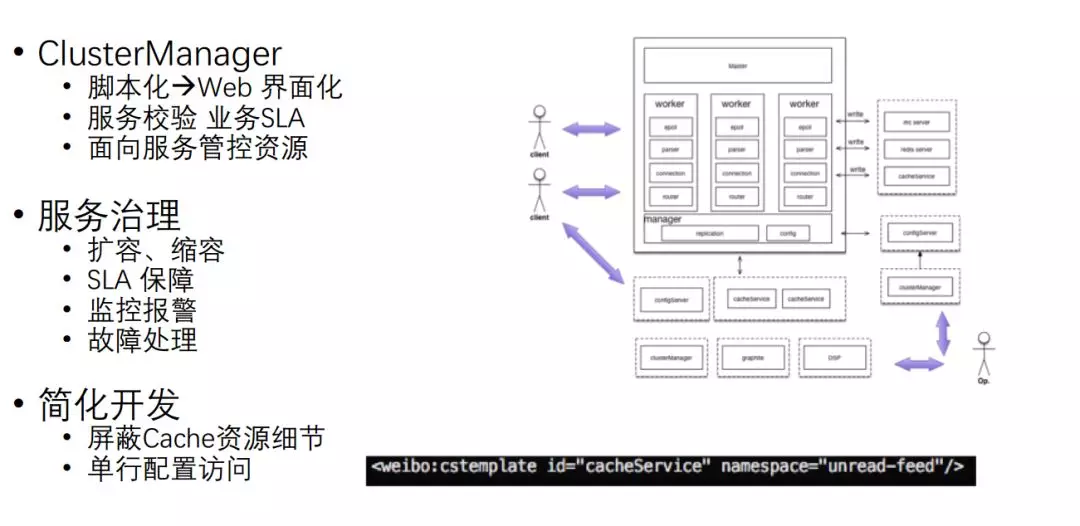
服务化还引入 Cluster Manager,实现对外部的管理,通过一个界面来进行管理,可以进行服务校验。
服务治理方面,可以做到扩容、缩容,SLA 也可以得到很好的保障。另外,对于开发来说,现在就可以屏蔽 Cache 资源。
总结与展望
======
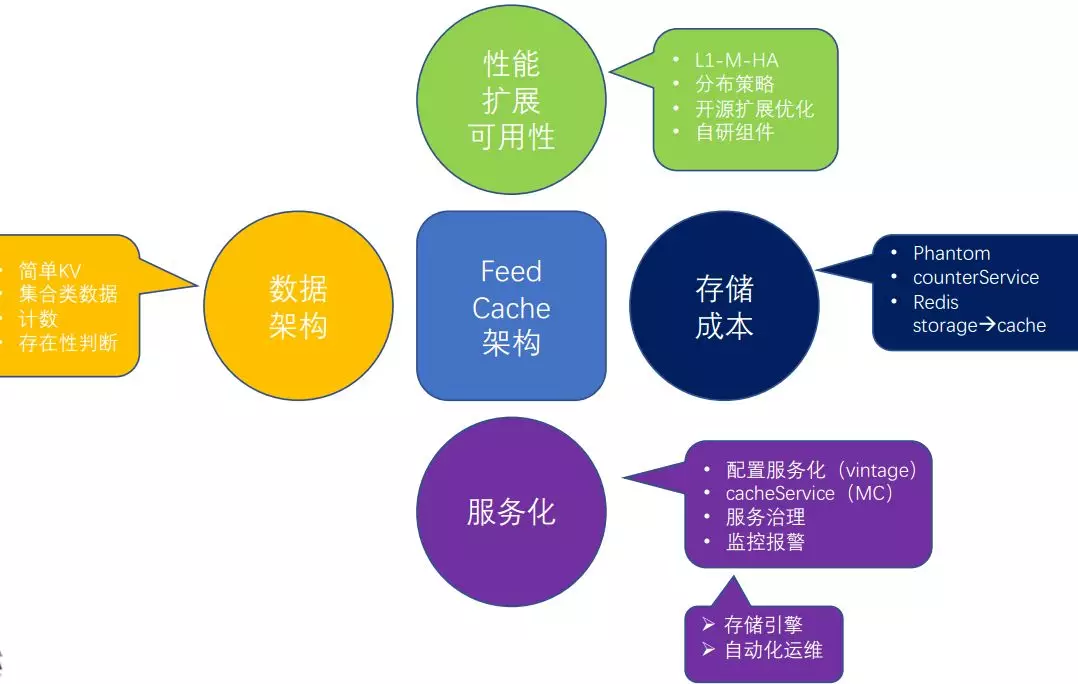
最后简单总结一下,对于微博 Cache 架构来说,我们从它的数据架构、性能、储存成本、服务化等不同方面进行了优化增强。















 794
794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









