






Stable Diffusion是什么?
Stable Diffusion是一类生成图像的模型。它可以做到文生图、图生图、inpaiting、去噪等等一系列图像操作。
千言万语不如图直观,下面用一系列生成的图来展示Stable Diffusion的冰山一角。
图像都使用SDXL生成,简单的给出了prompt,复杂的是使用ComfyUI工作流生成。
prompt: 1girl,upper body,best quality,masterpiece,simple background high quality, detailed
negative prompt:
blurry, noisy, messy, lowres, jpeg, artifacts, ill, distorted, malformed

prompt: photorealistic beach sunlight light particles warm pastel colors
1girl Chinese smile
negative prompt:
blurry, noisy, messy, lowres, jpeg, artifacts, ill, distorted, malformed

prompt: photorealistic beach sunlight light particles warm pastel colors
1girl Chinese smile high quality, detailed
negative prompt:
blurry, noisy, messy, lowres, jpeg, artifacts, ill, distorted, malformed

使用ipadapter,以下面的卡通古风图片作为控制图

使用的prompt如下
prompt:
photorealistic
1girl Chinese smile detailed face slim high quality
negative prompt:
text, logo, watermark, digit, multiple views, monochrome, bad proportions, anatomical nonsense, bad hands, bad face, blurry, noisy, messy, lowres, jpeg, artifacts, ill, distorted, malformed
最后可以得到

使用下面的真人图片,并把prompt里面的smile去掉

可以得到

使用现代的图片

可以得到

IPAdapter+Human Segmentation+BrushNet换妆换头发

还可以实现换装+换发型+换背景
原始图片

换完以后

上面是一些实示例,可以看到,stable diffusion再配合其它一些技术,不敢说无所不能吧,还是可以生成很多很有创意的图片。
在看到了它可以干什么之后,我们可以简单了解一下它的发展历史。
发展历史

Deep Unsupervised Learning using Nonequilibrium Thermodynamics
在它之前,已经有两种生成图像的主流算法。一种是VAE以及其变种,一类是GAN。可以说,在21年之前,GAN是绝对的主流。但是早在15年,这篇文章就提扩散模型算法,当然了,在当时没什么水花。
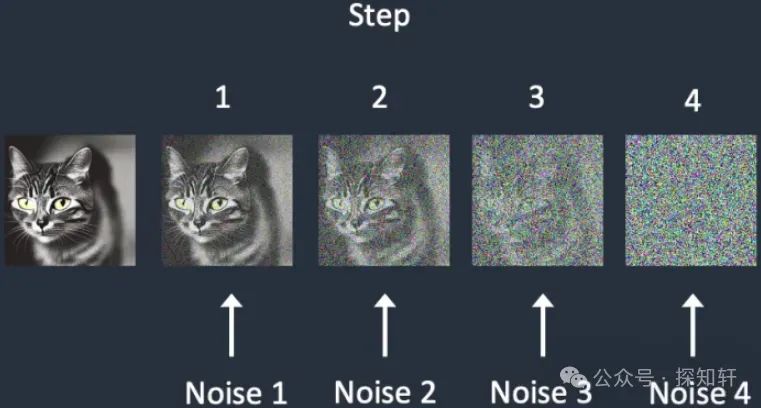
Denoising Diffusion Probabilistic Models
作者在21年重新提出使用扩散模型来生成图像。其实这么说并不严谨,因为在21年之前也一直都有人在做这方面的工作。但是这篇文章提出的DDPM是任何要研究sampler都绕不开的文章。文章里面把采样前向加噪推导出了闭式解,时候来所有训练工作的基石之一。另外,这篇文章提出了网络估计噪声,而不是像之前的文章那样从噪声图像直接估计原始图像。这部分工作也是后来的工作一直遵循的做法。

Denoising Diffusion Implicit Models
DDPM是假设前向加噪声是马尔科夫链,这篇文章打破这个假设。最大的成就就是把推理步骤从1000多步减少到了大约50步,为实用提供了坚实的基础。
Diffusion Models Beat GANs on Image Synthesis
提出了使用类别(class)来做导向,让生成的图像受到类别的影响。这部分工作我认为是一个很重要的工作是因为基本上后面所有的模型都遵循了使用外部信息导向的的方法。
Classifier-Free Diffusion Guidance
这篇文章是在上一篇文章上的改进,上一篇文章还需要单独训练一个分类器,而这篇文章提出只需要使用一个扩散模型就可以了,不再需要单独训练分类器。
相信使用过stable diffusion模型的同学都见过CFG这个参数,对应的就是这篇文章(diffuser实现的公式不是根据这篇文章,而是根据GLIDE里面的公式)。
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
个人觉得这篇文章是pixel space的集大成者,利用上了之前的所有技术。还对比了使用clip做guidance以及使用CFG做guidance的区别,应该是当时生成质量最好的方法之一。
==High-Resolution Image Synthesis with Latent Diffusion Models==
尽管是站在巨人的肩膀上,其光芒依然无法掩盖!
2021年12月提交了文章的第一个版本,间隔一个月又提交了v2版本。它就是著名的stable diffusion的理论基础。文章中创新地提出了
-
使用latent space而非原始的像素空间来做去噪。这极大地减少了计算量;
-
使用cross attention来把外部的信息进行引入,这使得外部的时间、文本、图像等任何信息都可以通过这个机制引入到去噪模型里面。
stable diffusion
从2022年6月就在不断放新的版本,官方正式宣布是2022年8月v1.4版本出来的时候。实际上,现在用的最多的版本是v1.5版本(runwayml/stable-diffusion-v1-5)。
下面是这几个版本官方给出的区别:
-
stable-diffusion-v1-1: 237,000 steps at resolution256x256on laion2B-en. 194,000 steps at resolution512x512on laion-high-resolution (170M examples from LAION-5B with resolution>= 1024x1024). -
stable-diffusion-v1-2: Resumed fromstable-diffusion-v1-1. 515,000 steps at resolution512x512on “laion-improved-aesthetics” (a subset of laion2B-en, filtered to images with an original size>= 512x512, estimated aesthetics score> 5.0, and an estimated watermark probability< 0.5. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using an improved aesthetics estimator). -
stable-diffusion-v1-3: Resumed fromstable-diffusion-v1-2- 195,000 steps at resolution512x512on “laion-improved-aesthetics” and 10 % dropping of the text-conditioning to improve classifier-free guidance sampling. -
stable-diffusion-v1-4Resumed fromstable-diffusion-v1-2- 225,000 steps at resolution512x512on “laion-aesthetics v2 5+” and 10 % dropping of the text-conditioning to improve classifier-free guidance sampling. -
stable-diffusion-v1-5Resumed fromstable-diffusion-v1-2- 595,000 steps at resolution512x512on “laion-aesthetics v2 5+” and 10 % dropping of the text-conditioning to improve classifier-free guidance sampling.
1.x系列模型有大致860 million参数,使用 ViT-L/14 CLIP model 作为文本编码器生成512x512的图像。
2.x系列模型有大致860 million参数,使用ViT-H/14 作为编码器生成768x768的图像。但是由于改了clip编码器,让大家很难从1.x系列迁移,而1.5才是使用率最高的版本。这就导致2.x系列其实没有多大的影响。
2023年7月出来的SDXL是除了1.5版本之外使用最多的版本。实际上,后面出来的主要偏运用的controlnet, ipadapter,brushnet这些主要支持的版本就是这两个版本,由此可见sdxl的地位。之前的模型都只使用一个文本编码器,sdxl却使用了两个( OpenCLIP-ViT/G, CLIP-ViT/L,最后的embedding是两个编码器的结果concat得到)。
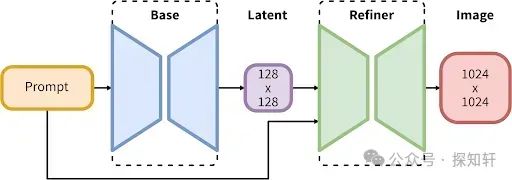
它包含一个Base的去噪UNET,还包含一个Refiner。Base Model是3.5B,整个pipeline加起来是6.6B。整个模型生成1024x1024尺寸的图像。
SDXL Turbo是SDXL 1.0的蒸馏版本,可以单步生成质量不错的512x512大小图像。Cascade模型就是个纯研究的模型,没啥浪花。
收到sora的影响,Stability AI在2024年2月声明了Stable Diffusion 3.0的存在,并在2024年6月17日开源了Stable Diffusion 3.0 Medium,一个有20亿参数的模型。其采用与Sora一样的**Diffusion Transformer(DiT)**架构。
SD3 Medium 的优点包括:
-
图像质量整体提升,能生成照片般细节逼真、色彩鲜艳、光照自然的图像;能灵活适应多种风格,无需微调,仅通过提示词就能生成动漫、厚涂等风格化图像;具有 16 通道的 VAE,可以更好地表现手部以及面部细节。
-
能够理解复杂的自然语言提示,如空间推理、构图元素、姿势动作、风格描述等。对于“第一瓶是蓝色的,标签是“1.5”,第二瓶是红色的,标签是“SDXL”,第三瓶是绿色的,标签是“SD3””这样复杂的内容,SD3 依旧能准确生成,而且文本效果比 Midjourney 还要准确。
-
通过 Diffusion Transformer 架构,SD3 Medium 在英文文本拼写、字距等方面更加正确合理。Stability AI 在发布 SD3 官方公告时,头图就是直接用 SD3 生成的,效果非常惊艳。
写在最后
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除















 4102
4102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









