






目录
前言
在现实生活中收集到的数据往往存在这数据不完整(有缺失值)、数据不一致、数据异常等情况,如果用这种异常数据进行建模分析,那么可能会影响建模的执行效率,甚至可能会造成分析结果出现偏差。如何对数据进行预处理,提高数据质量,是数据分析工作中常见的问题。本文章将给大家介绍数据合并、数据清洗、数据标准化和数据变化这四种预处理操作。
思维导图:

一、数据加载与初步探索
1.1数据加载
使用Pandas的read_系列函数(如read_csv、read_excel等)可以轻松加载各种格式的数据集。加载出想要进行数据预处理的表格数据。
import pandas as pd
# 加载CSV文件
data = pd.read_csv('data.csv')
# 查看前5行数据
print(data.head())
# 查看数据集的形状(行数和列数)
print(data.shape)输出结果如下

1.2初步探索
使用info()方法查看数据集的基本信息,如数据类型、缺失值等。
print(data.info())输出结果如下
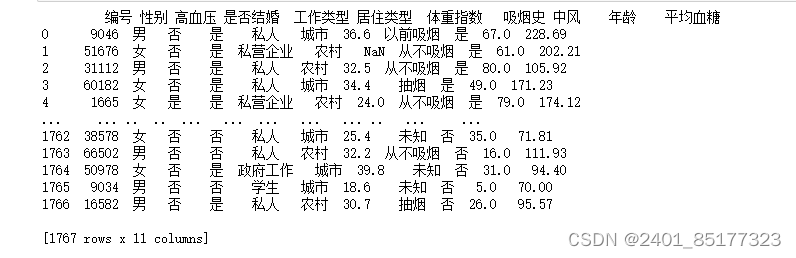
二、数据清洗
清理加载出来的异常值数据,以下分三种情况
第一种情况:当数据中有出现缺失值的情况,可以使用2.1来解决
2.1处理缺失值
-
使用
dropna()方法删除包含缺失值的行或列。 -
使用
fillna()方法填充缺失值,可以指定填充值或使用列的平均值、中位数等。
# 删除所有包含缺失值的行
data_clean = data.dropna()
# 使用列的平均值填充缺失值
data_clean['column_name'].fillna(data['column_name'].mean(), inplace=True)输出结果如下

第二种情况:当数据中出现重复值时可以使用2.2
2.2处理重复值
使用duplicated()和drop_duplicates()方法识别和处理重复值。
# 查找重复行
duplicates = data[data.duplicated()]
# 删除重复行
data_unique = data.drop_duplicates()输出结果如下

第三种情况:当数据中出现异常值(不同于同列或同行的数据类型)时,可以使用2.3
2.3处理异常值
使用IQR(四分位距)等方法识别异常值,并视情况选择删除或替换。
# 计算IQR并识别异常值
Q1 = data['column_name'].quantile(0.25)
Q3 = data['column_name'].quantile(0.75)
IQR = Q3 - Q1
lower_limit = Q1 - 1.5 * IQR
upper_limit = Q3 + 1.5 * IQR
outliers = data[(data['column_name'] < lower_limit) | (data['column_name'] > upper_limit)]
# 处理异常值(如删除)
data_no_outliers = data[~((data['column_name'] < lower_limit) | (data['column_name'] > upper_limit))]
三、数据转换
3.1数据的类型转换
使用astype()或to_numeric()等方法转换数据类型。
# 将字符串列转换为整数列
data['column_name'] = pd.to_numeric(data['column_name'], errors='coerce')输出结果如下

3.2特征编码
对于分类特征,可以使用map()、replace()或CategoricalDtype等方法进行编码。
# 使用map方法进行编码
data['category_column'] = data['category_column'].map({'category1': 1, 'category2': 2, 'category3': 3})输出结果如下

3.3特征缩放
对于需要特征缩放的算法,可以使用Pandas结合NumPy进行Min-Max缩放或Z-score缩放。
import numpy as np
# Min-Max缩放
data['scaled_column'] = (data['column_name'] - data['column_name'].min()) / (data['column_name'].max() - data['column_name'].min())
# Z-score缩放(需要额外导入scipy库)
from scipy import stats
data['z_score_column'] = stats.zscore(data['column_name'])输出结果如下

四、两张不同的数据表的数据预处理
4.1两张表进行合并
- 使用merge函数进行主键合并
- 使用join()方法合并
- 使用combine_first()方法合并
#merge方法
import pandas as pd
df1= pd.read_excel('./healthcare-dataset-stroke.xlsx')
df2 = pd.read_excel('./healthcare-dataset-age_abs.xlsx')
merge_df = pd.merge(df1,df2,on='编号',how='outer')
print(merge_df)
#join()方法
join_df = pd.join(df1,df2,on='编号',rsuffix=‘1’)
#combine_first()方法
import numpy as np
dict1 = {'ID':[1,2,3,4,5,6,7,8,9],'System':['win10','win10',np.nan,'win10',np.nan,np.nan,'win7','win7','win8'],'cpu':['i7','i5',np.nan,'i7',np.nan,np.nan,'i5','i5','i3']}
dict2 = {'ID':[1,2,3,4,5,6,7,8,9],'System':[np.nan,np.nan,'win7',np.nan,'win8','win7',np.nan,np.nan,np.nan],'cpu':[np.nan,np.nan,'i3',np.nan,'i7','i5',np.nan,np.nan,np.nan]}
df1 = pd.DataFrame(dict1)
df2 = pd.DataFrame(dict2)
print(df1.combine_first(df2))输出结果如下:

五、标准化数据
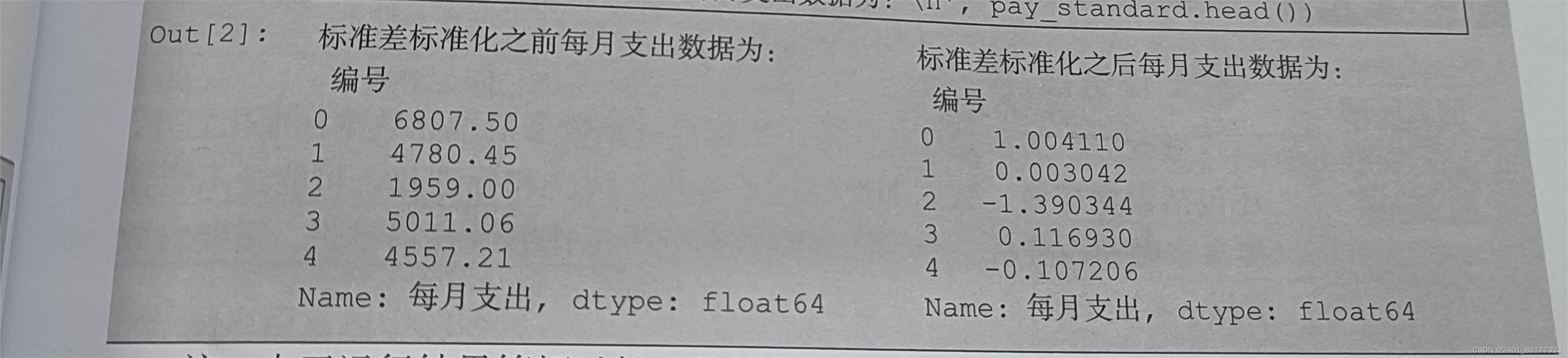
5.1标准差标准化

输出效果如下
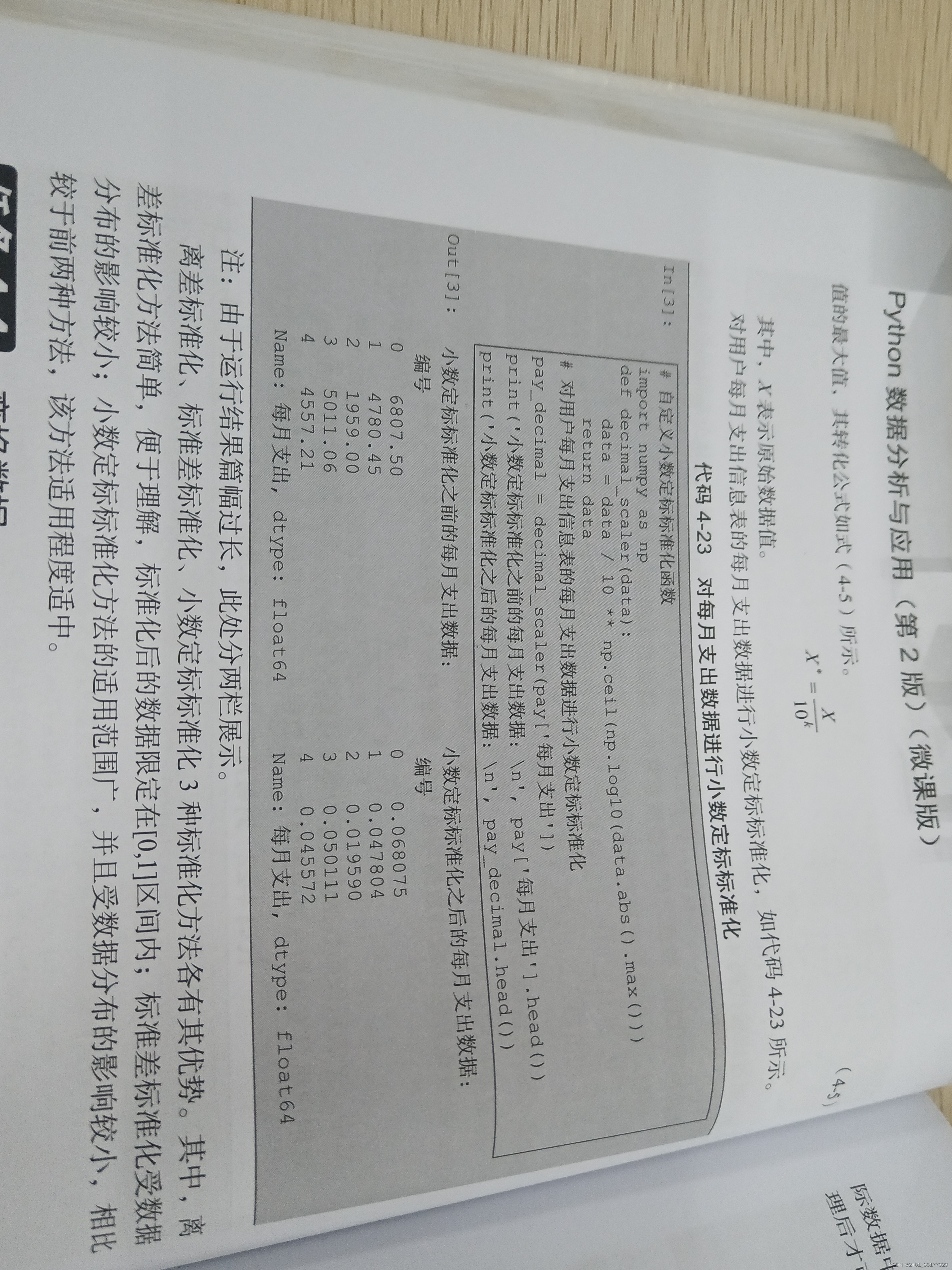
5.2小数定标标准化
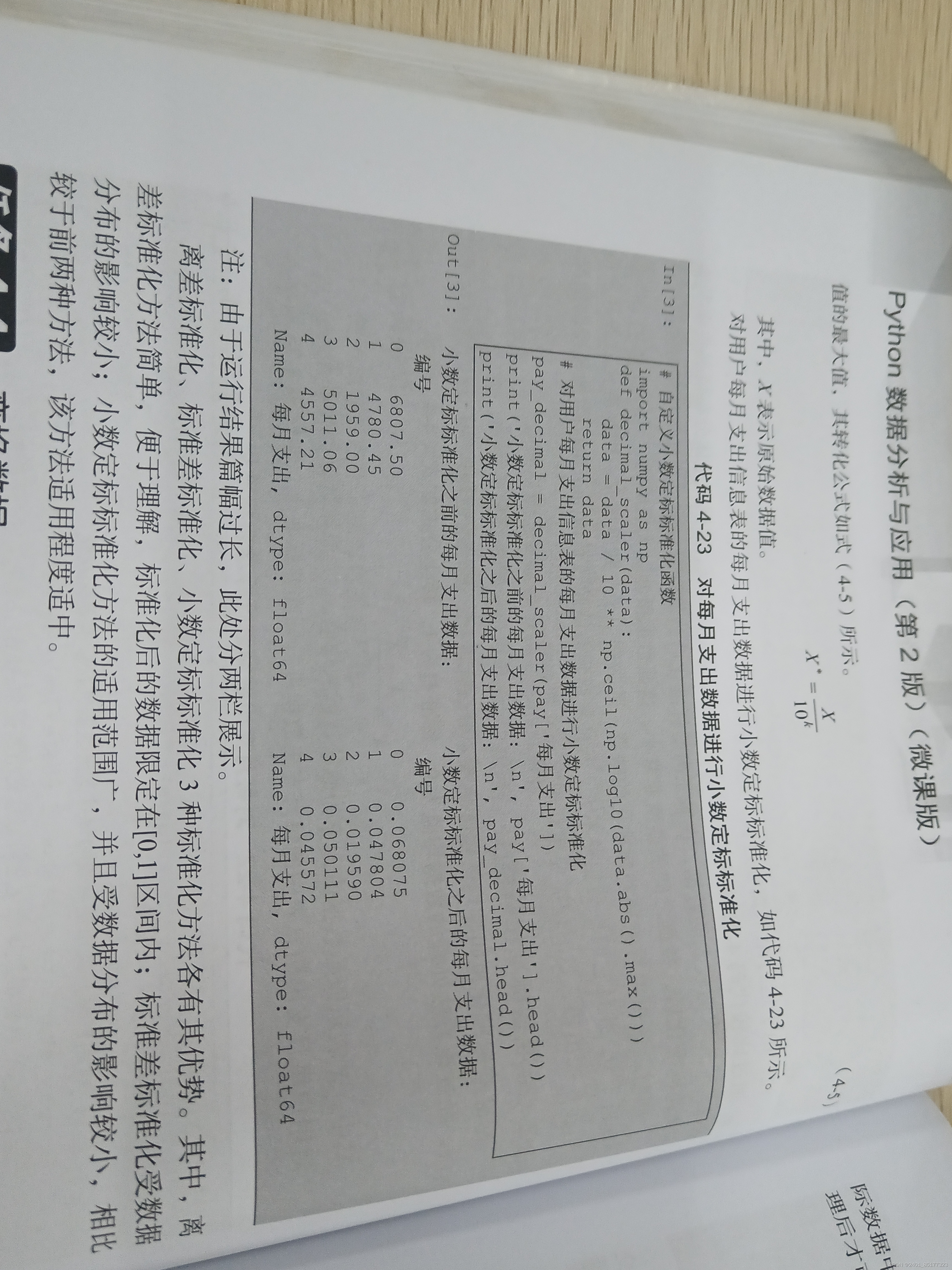
输出效果如下
六、变换数据
6.1利用get—dummies函数进行哑变量处理

输出结果如下
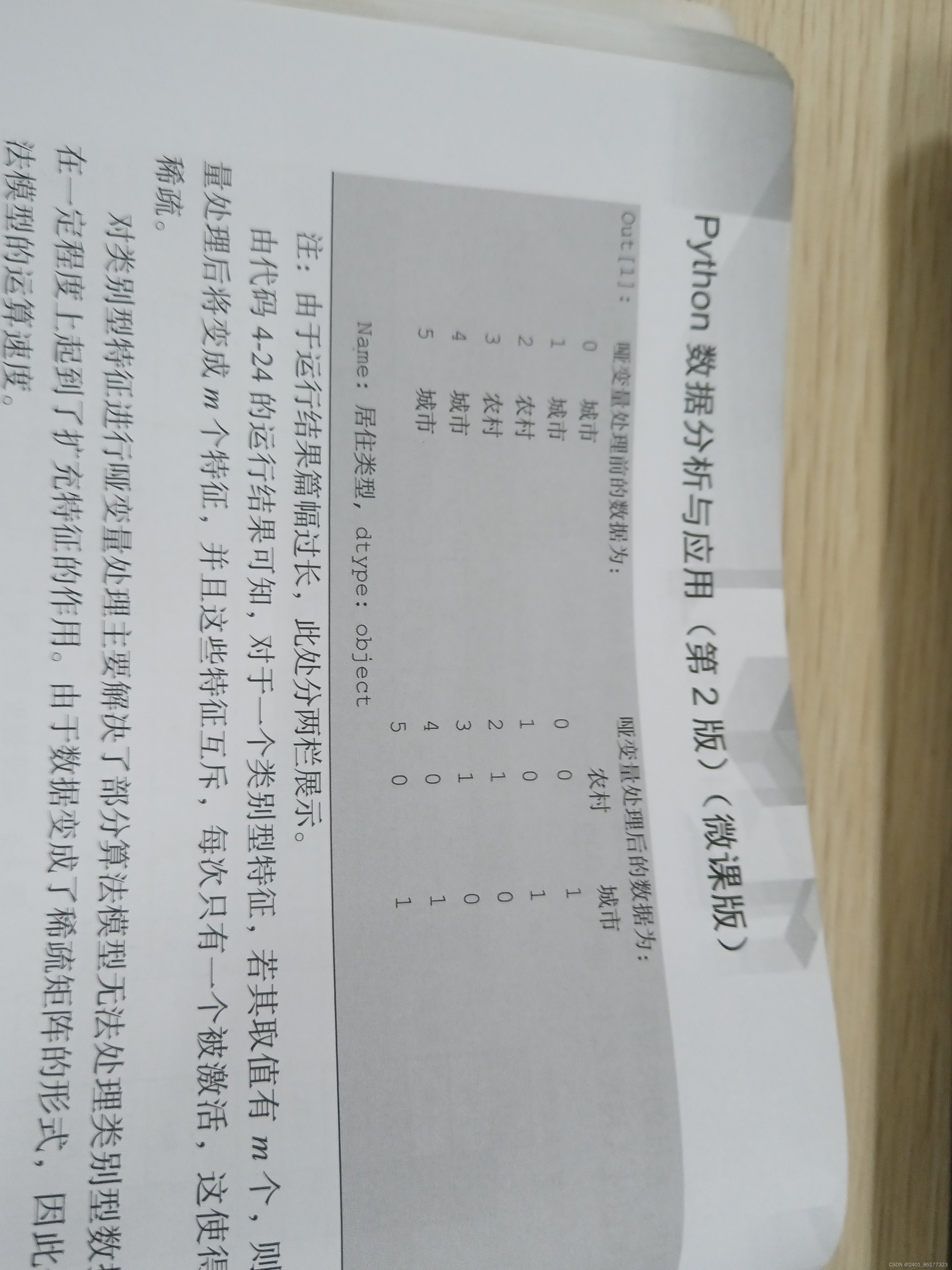
七、离散化连续性数据
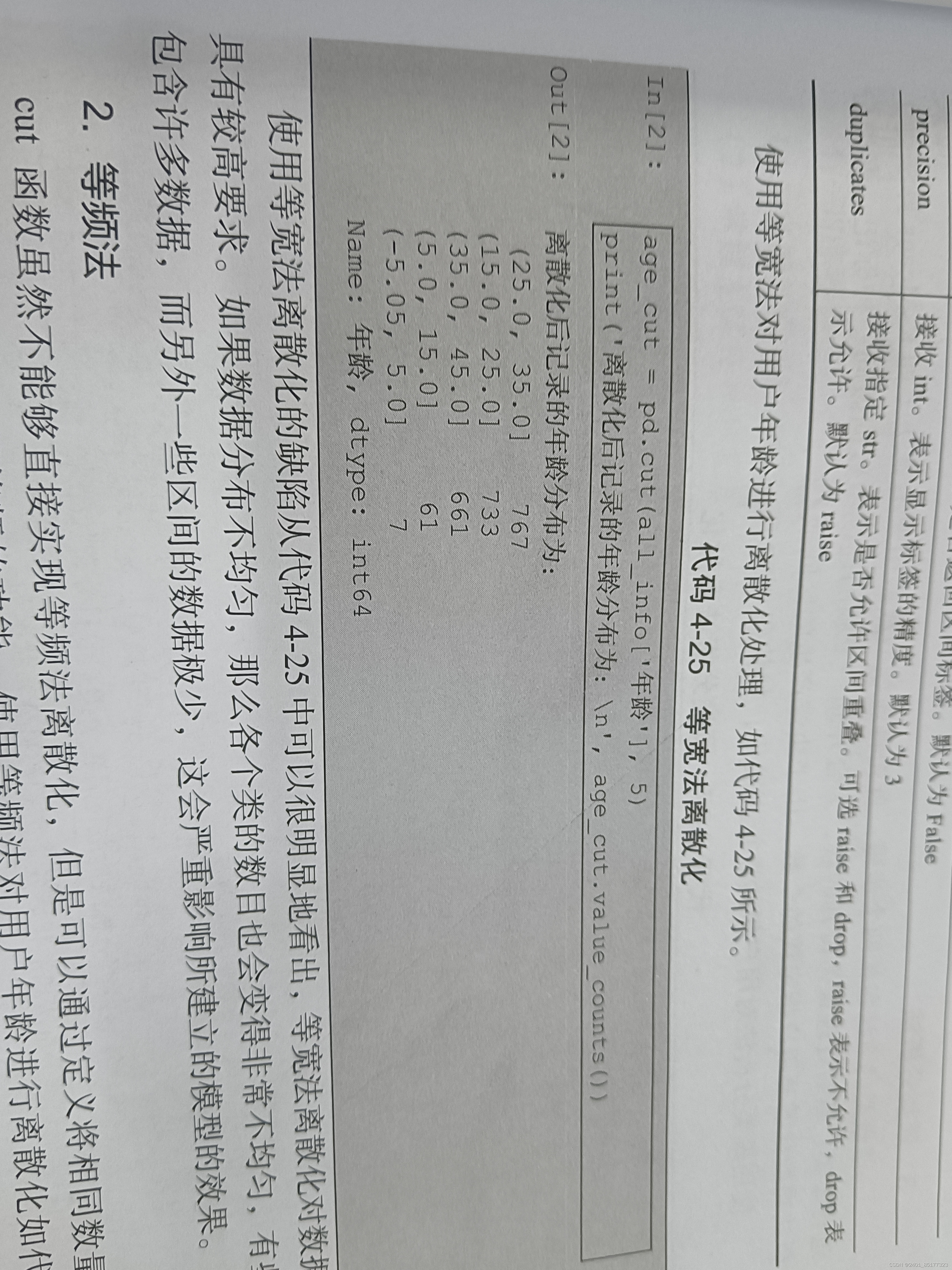
7.1等宽法
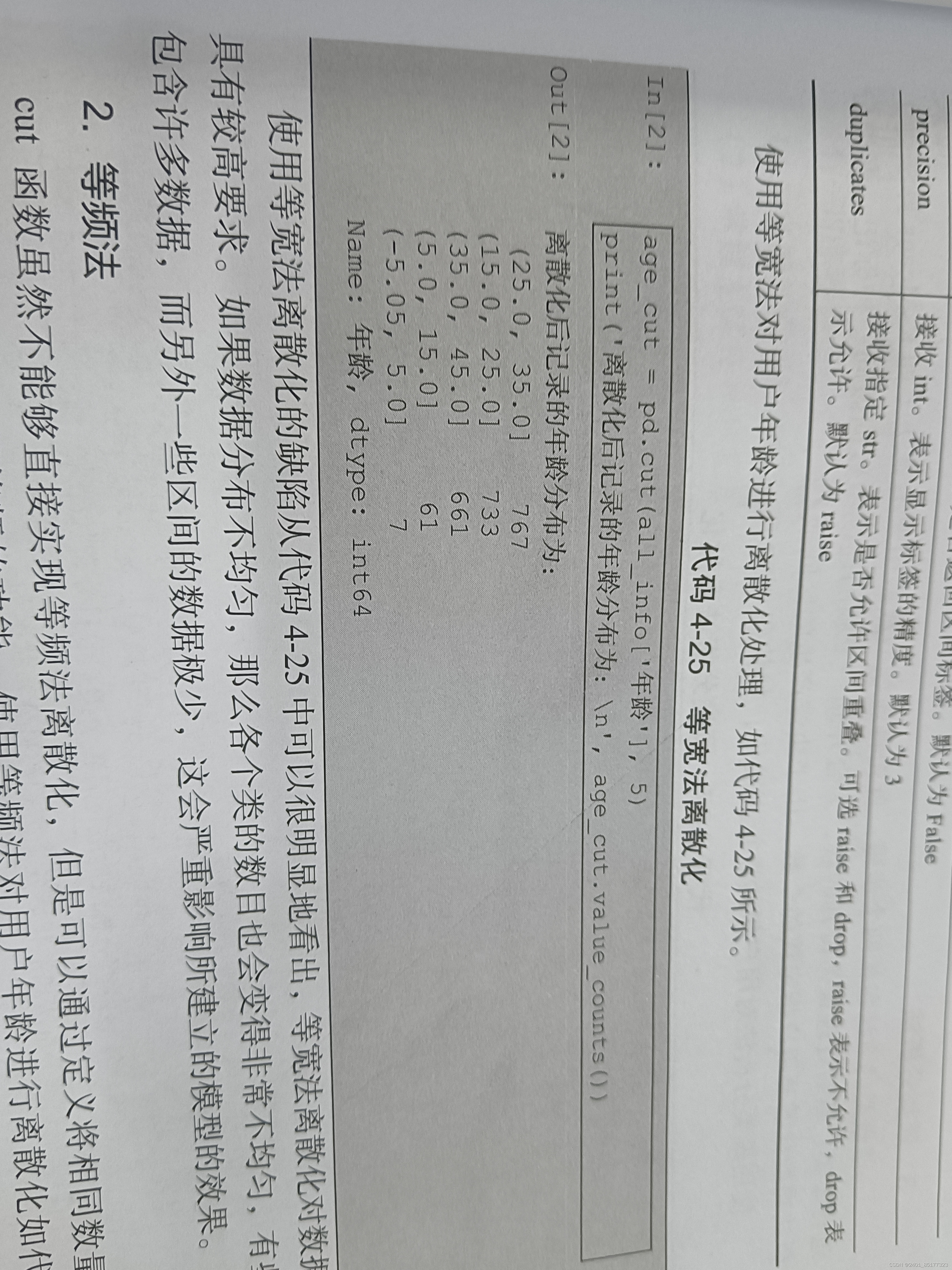
输出效果如下
7.2等频法

输出效果如下

7.3聚类分析法

输出效果如下

八、箱线图分析
在Pandas中,直接绘制箱线图(Boxplot)的功能并不直接提供,但你可以结合Matplotlib或Seaborn等库来绘制。箱线图是一种用于显示一组数据分散情况资料的统计图,由一组数据的最大值、最小值、中位数、及上下四分位数绘制而成。
import pandas as pd
import matplotlib.pyplot as plt
# 假设你有一个DataFrame,其中包含一些列,你想对这些列进行箱线图分析
data = {
'A': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'B': [2, 3, 2, 5, 6, 5, 7, 8, 7, 9],
'C': [1, 4, 5, 4, 5, 6, 7, 8, 9, 10],
'D': [8, 7, 6, 5, 4, 3, 2, 1, 0, -1]
}
df = pd.DataFrame(data)
# 使用Matplotlib绘制箱线图
plt.figure(figsize=(10, 6)) # 设置图像大小
df.boxplot(rot=45) # rot参数用于旋转x轴标签的角度
plt.title('Boxplot of DataFrame Columns') # 设置标题
plt.xlabel('Columns') # 设置x轴标签
plt.ylabel('Values') # 设置y轴标签
plt.show()九、总结
本文详细介绍了使用Pandas进行高效数据预处理的各个步骤,包括数据加载、初步探索、数据清洗、数据转换等。Pandas的强大功能和灵活性使得数据预处理变得简单而高效。希望本文能够帮到各位看官老爷。















 610
610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









