







一、实验目的
1、掌握数据合并的原理与方法;
2、掌握数据清洗的基本方法;
3、掌握常用的数据转换方法;
4、理解数据预处理对数据处理的影响。
二、实验要求
1、完成任务5.1-5.4代码操作实现并编程完成第五章实训内容;
2、写出实验报告,内容要求有Python 代码和实验结果
3、鼓励大家给出不同的,更优的代码实现。
三、实验内容
1、读取用户电量数据并插补缺失值(具体要求见第五章实训1的内容)
(1)掌握缺失值识别方法;
(2)掌握对缺失值数据处理的方法。
import pandas as pd
import numpy as np
from scipy.interpolate import lagrange
arr = np.array([0, 1, 2])
missing_data = pd.read_csv(r'C:\Users\xf224\Desktop\第5章数据\missing_data.csv', names=arr)
# 查询缺失值所在位置
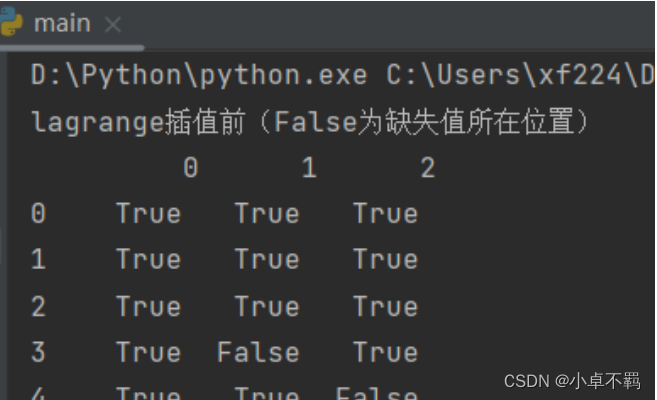
print("lagrange插值前(False为缺失值所在位置)", '\n', missing_data.notnull())
for i in range(0, 3):
la = lagrange(missing_data.loc[:, i].dropna().index, missing_data.loc[:, i].dropna().values)
list_d = list(set(np.arange(0, 21)).difference(set(missing_data.loc[:, i].dropna().index)))
missing_data.loc[list_d, i] = la(list_d)
# 输出插值后的数据到CSV文件
missing_data.to_csv("data.csv", index=False)
data = missing_data.fillna(missing_data.mean())
print(data)
print("lagrange插值后的数据已保存到data.csv 文件")
运行图如下图所示:
2、合并线损、用电量趋势与线路警告数据(具体要求见第五章实训2的内容)。
(1)掌握主键合并的几种方法;
(2)掌握多键值的主键和合并方法。
-*- coding: gbk -*-
import pandas as pd
ele_loss = pd.read_csv(r'C:\Users\xf224\Desktop\第5章数据\ele_loss.csv')
alarm = pd.read_csv(r'C:\Users\xf224\Desktop\第5章数据\alarm.csv', encoding='gbk')
# 查看两个表的形状
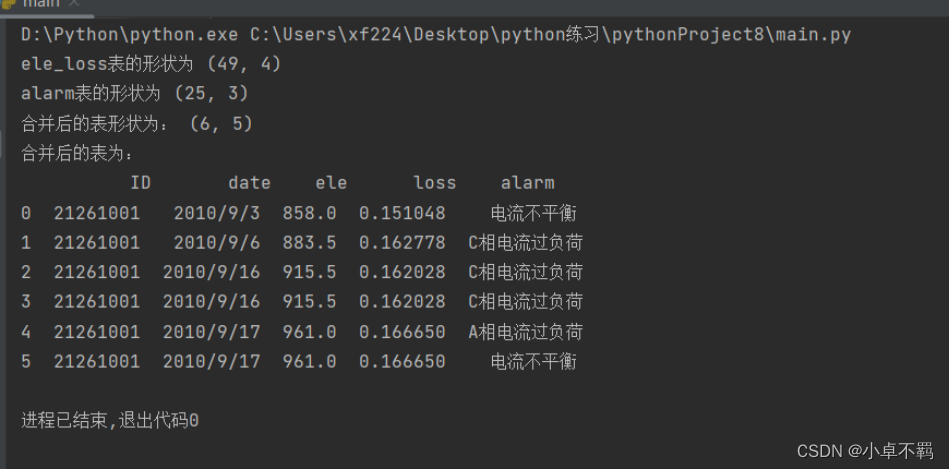
print("ele_loss表的形状为", ele_loss.shape)
print("alarm表的形状为", alarm.shape)
# 合并后的数据
merge = pd.merge(ele_loss, alarm, left_on=["ID", "date"], right_on=["ID", "date"], how="inner")
print("合并后的表形状为:", merge.shape)
print("合并后的表为:"'\n', merge)
运行图如下图所示:
3、标准化建模专家样本数据(具体要求第五章实训3的内容)
(1)掌握数据标准化的基本原理;
(2)掌握数据标准化的Python实现方法。
import pandas as pd
model = pd.read_csv(r'C:\Users\xf224\Desktop\第5章数据\model.csv', encoding="utf-8")
def Standard(data):
data = (data - data.mean()) / data.std()
return data
S = Standard(model)
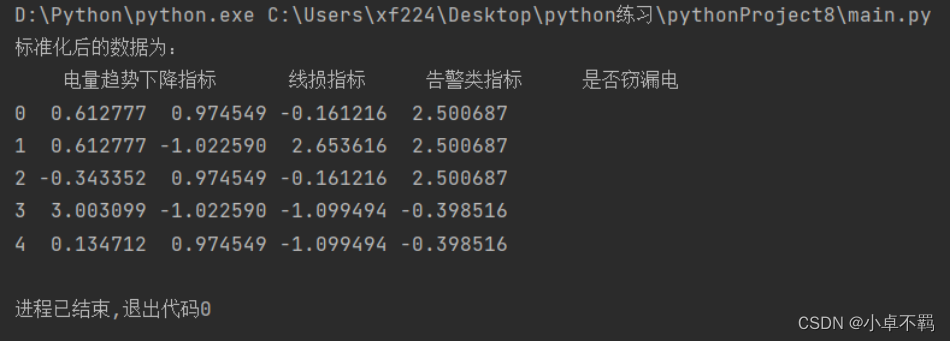
print("标准化后的数据为:", '\n', S.head())
运行图如下图所示:
4、进一步对数据集Mushroom进行相关操作:
(1)进行特征转换,将文本类型数据转为数值型;
(2)查看转换后的各字段数据分布(可箱型图展示);
(3)归一化(Normalization)、标准化(Standardization)操作;
(4)进行主成份分析(PCA)并可视化展示各属性的贡献度。
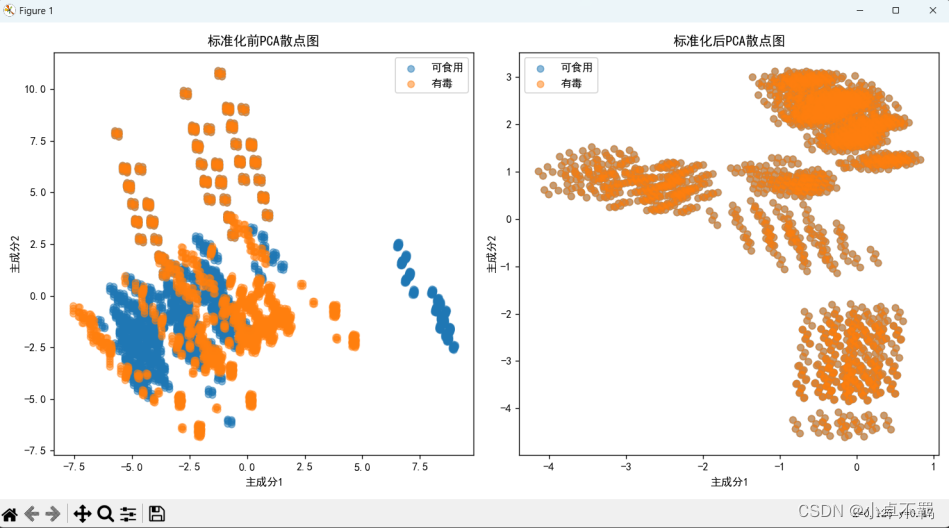
(5)将Mushroom数据在标准化前后的PCA后第一、第二维投影,分析数据标准化前后分类精度变化情况并可视化相应结果。
import pandas as pd
model = pd.read_csv(r'C:\Users\xf224\Desktop\第5章数据\model.csv', encoding="utf-8")
def Standard(data):
data = (data - data.mean()) / data.std()
return data
S = Standard(model)
print("标准化后的数据为:", '\n', S.head())
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
data = pd.read_csv(r'C:\Users\xf224\Desktop\第5章数据\mushrooms.csv', header=None)
plt.rcParams['font.sans-serif'] = 'SimHei'
# 特征转换,将文本类型数据转为数值型
label_encoder = LabelEncoder()
for column in data.columns:
data[column] = label_encoder.fit_transform(data[column])
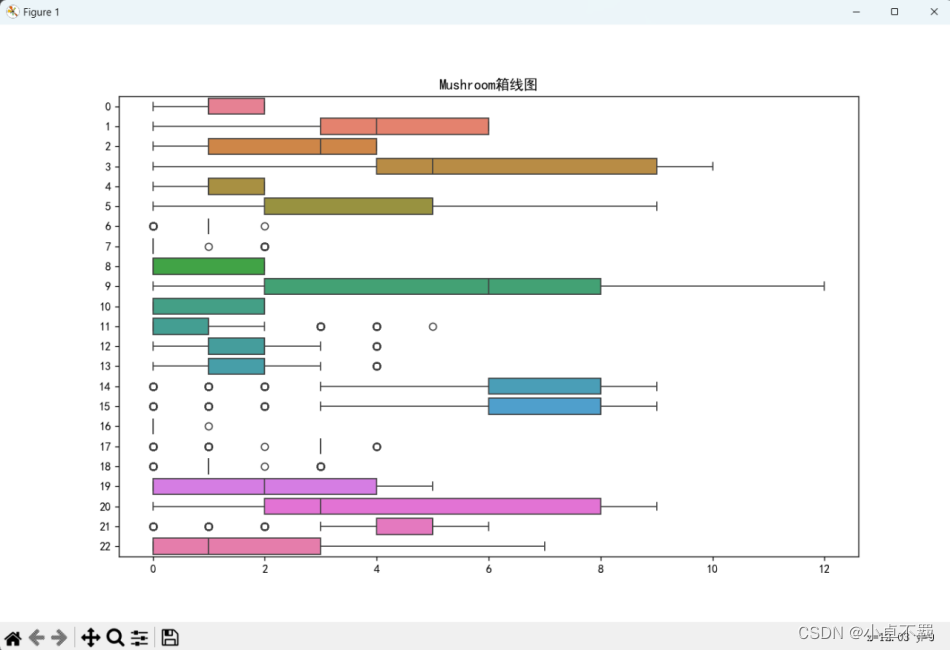
# 查看转换后的各字段数据分布(箱型图展示)
plt.figure(figsize=(12, 8))
sns.boxplot(data=data, orient="h")
plt.title("Mushroom箱线图")
plt.show()
data.to_csv('mushrooms_numerical.csv', index=False)
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, StandardScaler
import matplotlib.pyplot as plt
# 加载数值数据
data = pd.read_csv('mushrooms_numerical.csv')
plt.rcParams['font.sans-serif'] = 'SimHei'
target = data.iloc[:, -1]
data = data.iloc[:, :-1]
# 归一化
min_max_scaler = MinMaxScaler()
data_normalized = min_max_scaler.fit_transform(data)
data_normalized = pd.DataFrame(data_normalized, columns=data.columns)
data_normalized = pd.concat([data_normalized, target], axis=1)
data_normalized.to_csv('mushrooms_1.csv', index=False)
# 标准化
standard_scaler = StandardScaler()
data_standardized = standard_scaler.fit_transform(data)
data_standardized = pd.DataFrame(data_standardized, columns=data.columns)
data_standardized = pd.concat([data_standardized, target], axis=1)
data_standardized.to_csv('mushrooms_2.csv', index=False)
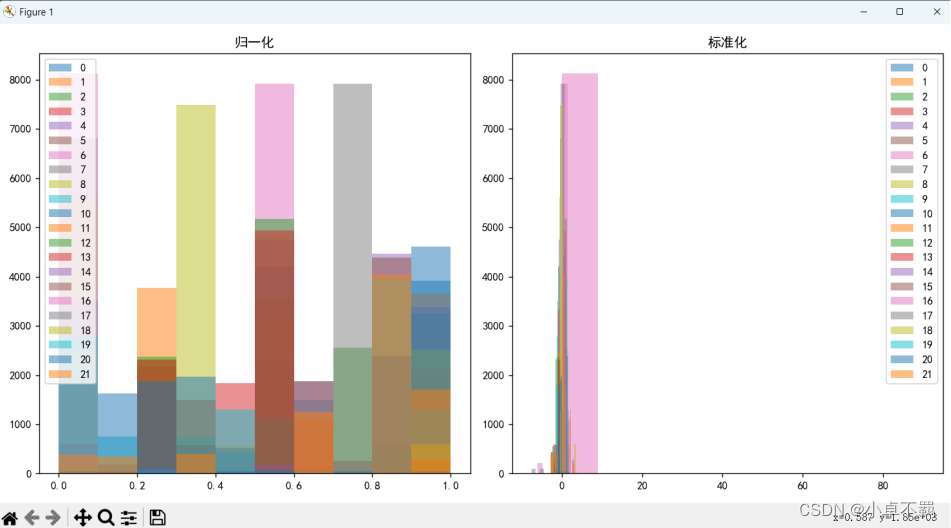
# 可视化归一化后的数据
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title('归一化')
for column in data_normalized.columns[:-1]:
plt.hist(data_normalized[column], alpha=0.5, label=column)
plt.legend()
# 可视化标准化后的数据
plt.subplot(1, 2, 2)
plt.title('标准化')
for column in data_standardized.columns[:-1]:
plt.hist(data_standardized[column], alpha=0.5, label=column)
plt.legend()
plt.tight_layout()
plt.show()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# 加载数据集
data = pd.read_csv('mushrooms_numerical.csv')
plt.rcParams['font.sans-serif'] = 'SimHei'
# 提取目标变量(如果适用)
target = data.iloc[:, -1]
data = data.iloc[:, :-1]
# 标准化数据
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)
# 执行PCA
pca = PCA()
pca_result = pca.fit_transform(data_scaled)
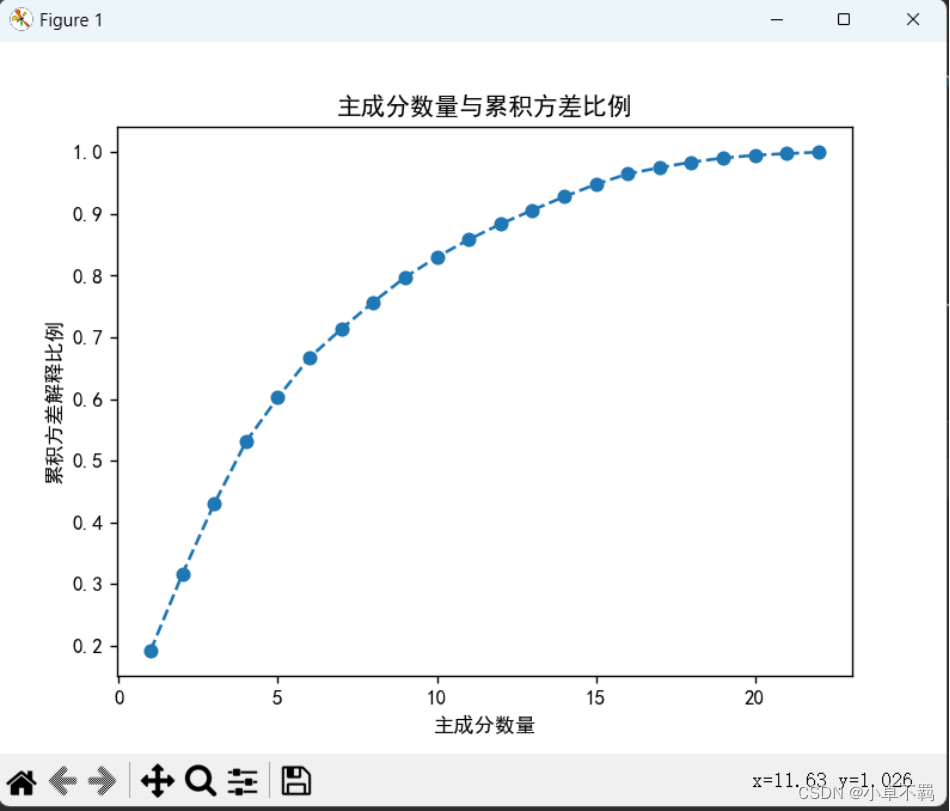
# 计算各主成分的方差贡献度
explained_variance_ratio = pca.explained_variance_ratio_
# 绘制累积方差贡献度的可视化图
cumulative_variance = np.cumsum(explained_variance_ratio)
plt.plot(range(1, len(cumulative_variance) + 1), cumulative_variance, marker='o', linestyle='--')
plt.xlabel('主成分数量')
plt.ylabel('累积方差解释比例')
plt.title('主成分数量与累积方差比例')
plt.show()
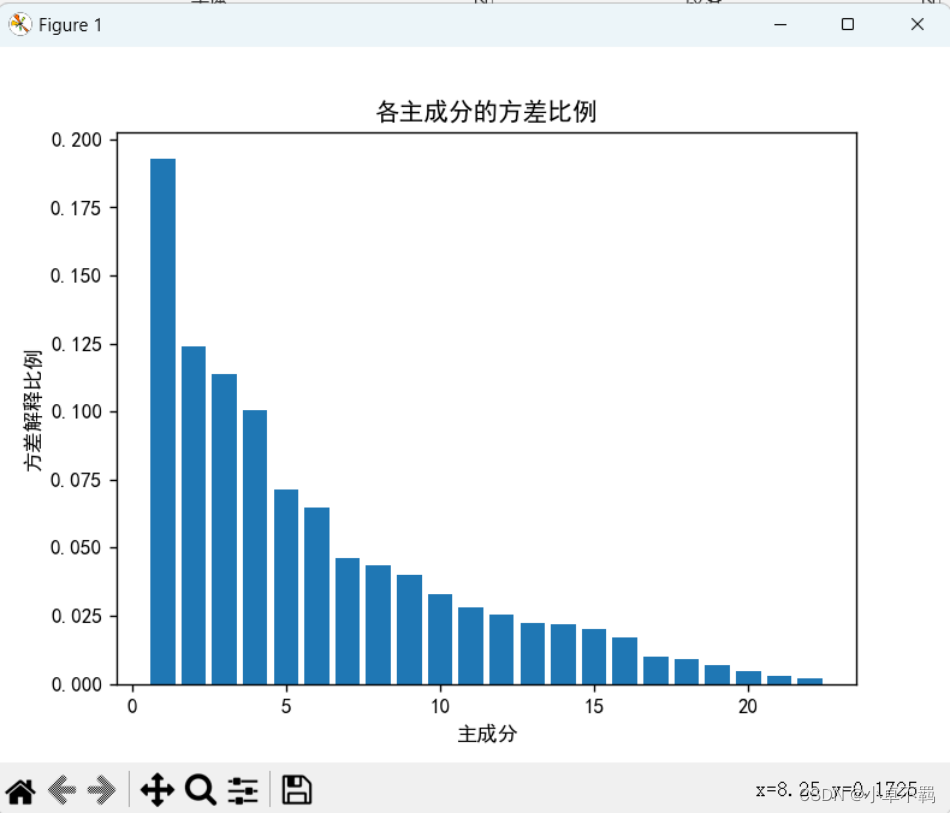
# 绘制各主成分的方差贡献度
plt.bar(range(1, len(explained_variance_ratio) + 1), explained_variance_ratio)
plt.xlabel('主成分')
plt.ylabel('方差解释比例')
plt.title('各主成分的方差比例')
plt.show()
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
# 加载原始数据集
data_original = pd.read_csv('mushrooms_numerical.csv')
# 提取目标变量(如果适用)
target_original = data_original.iloc[:, -1]
data_original = data_original.iloc[:, :-1]
# 加载标准化后的数据集
data_standardized = pd.read_csv('mushrooms_2.csv')
# 提取目标变量(如果适用)
target_standardized = data_standardized.iloc[:, -1]
data_standardized = data_standardized.iloc[:, :-1]
# 执行PCA(原始数据集)
pca_original = PCA(n_components=2)
pca_result_original = pca_original.fit_transform(data_original)
# 执行PCA(标准化后的数据集)
pca_standardized = PCA(n_components=2)
pca_result_standardized = pca_standardized.fit_transform(data_standardized)
# 绘制原始数据集的PCA结果散点图
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.scatter(pca_result_original[target_original == 0][:, 0],
pca_result_original[target_original == 0][:, 1],
label='可食用', alpha=0.5)
plt.scatter(pca_result_original[target_original == 1][:, 0],
pca_result_original[target_original == 1][:, 1],
label='有毒', alpha=0.5)
plt.title('标准化前PCA散点图')
plt.xlabel('主成分1')
plt.ylabel('主成分2')
plt.legend()
# 绘制标准化后的数据集的PCA结果散点图
plt.subplot(1, 2, 2)
plt.scatter(pca_result_standardized[target_standardized == 1][:, 0],
pca_result_standardized[target_standardized == 1][:, 1],
label='可食用', alpha=0.5)
plt.scatter(pca_result_standardized[target_standardized == 1][:, 0],
pca_result_standardized[target_standardized == 1][:, 1],
label='有毒', alpha=0.5)
plt.title('标准化后PCA散点图')
plt.xlabel('主成分1')
plt.ylabel('主成分2')
plt.legend()
plt.tight_layout()
plt.show()
运行图如下图所示:


















 2452
2452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









