






欢迎来到雲闪世界。LLM 的一个潜在应用引起了人们的关注和投资,即其生成 SQL 查询的能力。使用自然语言查询大型数据库可解锁多种引人注目的用例,从提高数据透明度到提高非技术用户的可访问性。
然而,与任何 AI 生成的内容一样,评估问题也很重要。我们如何确定 LLM 生成的 SQL 查询是否正确并产生预期结果?我们最近的研究深入探讨了这个问题,并探索了使用LLM 作为评判标准来评估 SQL 生成的有效性。
调查结果摘要
LLM 作为评判者在评估 SQL 生成方面表现出初步的潜力,在本次实验中使用 OpenAI 的 GPT-4 Turbo 时,F1 得分在 0.70 到 0.76 之间。在评估提示中包含相关架构信息可以显著减少误报。尽管仍然存在挑战(包括由于架构解释不正确或对数据的假设而导致的误报),但 LLM 作为评判者为 AI SQL 生成性能提供了可靠的代理,尤其是作为对结果的快速检查。
方法和结果
这项研究以 Defog.ai 团队之前的工作为基础,他们开发了一种使用黄金数据集和查询来评估 SQL 查询的方法。该过程包括使用黄金数据集问题进行 AI SQL 生成,从 AI 生成的 SQL 生成测试结果“x”,在同一数据集上使用预先存在的黄金查询来生成结果“y”,然后比较结果“x”和“y”的准确性。
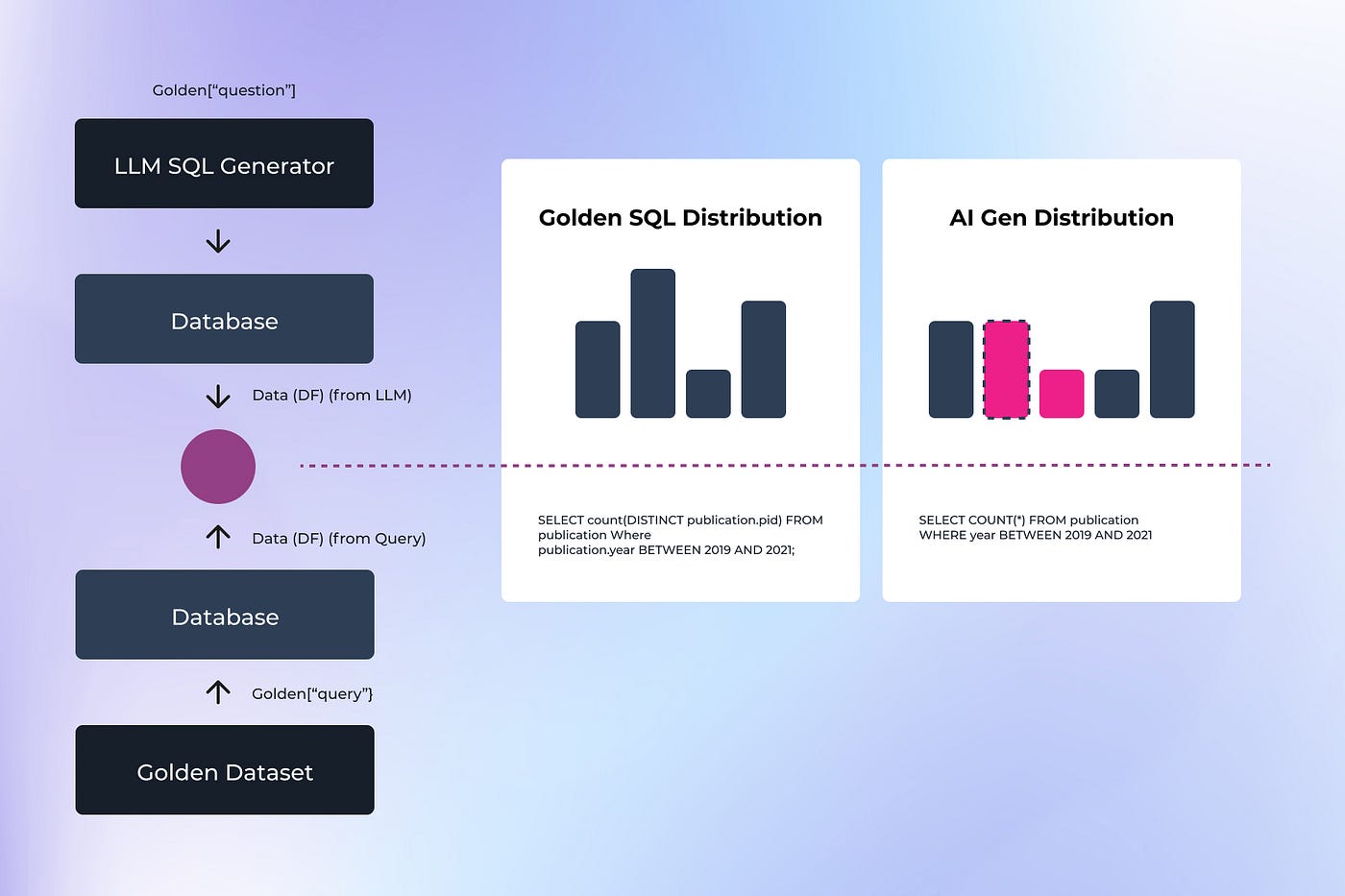
作者绘制的图表
为了进行此比较,我们首先探索了传统的 SQL 评估方法,例如精确数据匹配。此方法涉及直接比较两个查询的输出数据。例如,在评估有关作者引用的查询时,作者数量或其引用计数的任何差异都会导致不匹配和失败。虽然简单明了,但此方法无法处理极端情况,例如如何处理零计数箱或数字输出的细微变化。
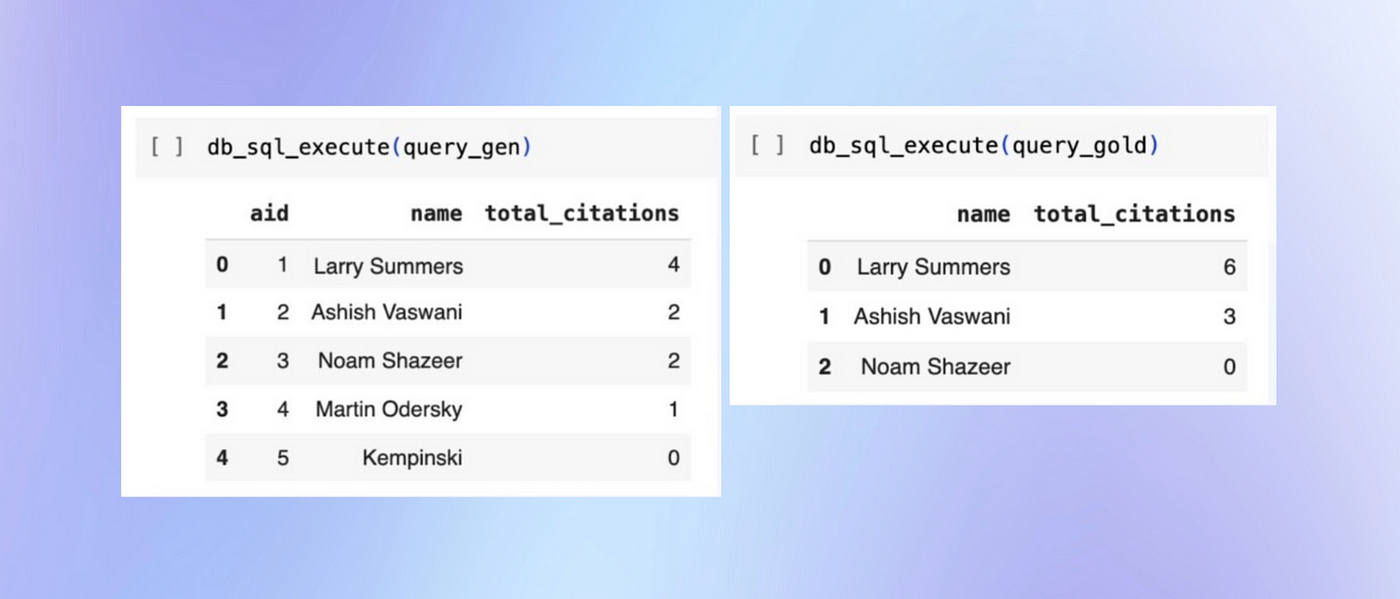
作者绘制的图表
然后,我们尝试了一种更细致的方法:使用 LLM 作为评判员。我们使用此方法进行了初步测试,使用 OpenAI 的 GPT-4 Turbo,而不在评估提示中包含数据库架构信息,结果令人满意,F1 分数在 0.70 到 0.76 之间。在此设置中,LLM 通过仅检查问题和结果查询来评判生成的 SQL。
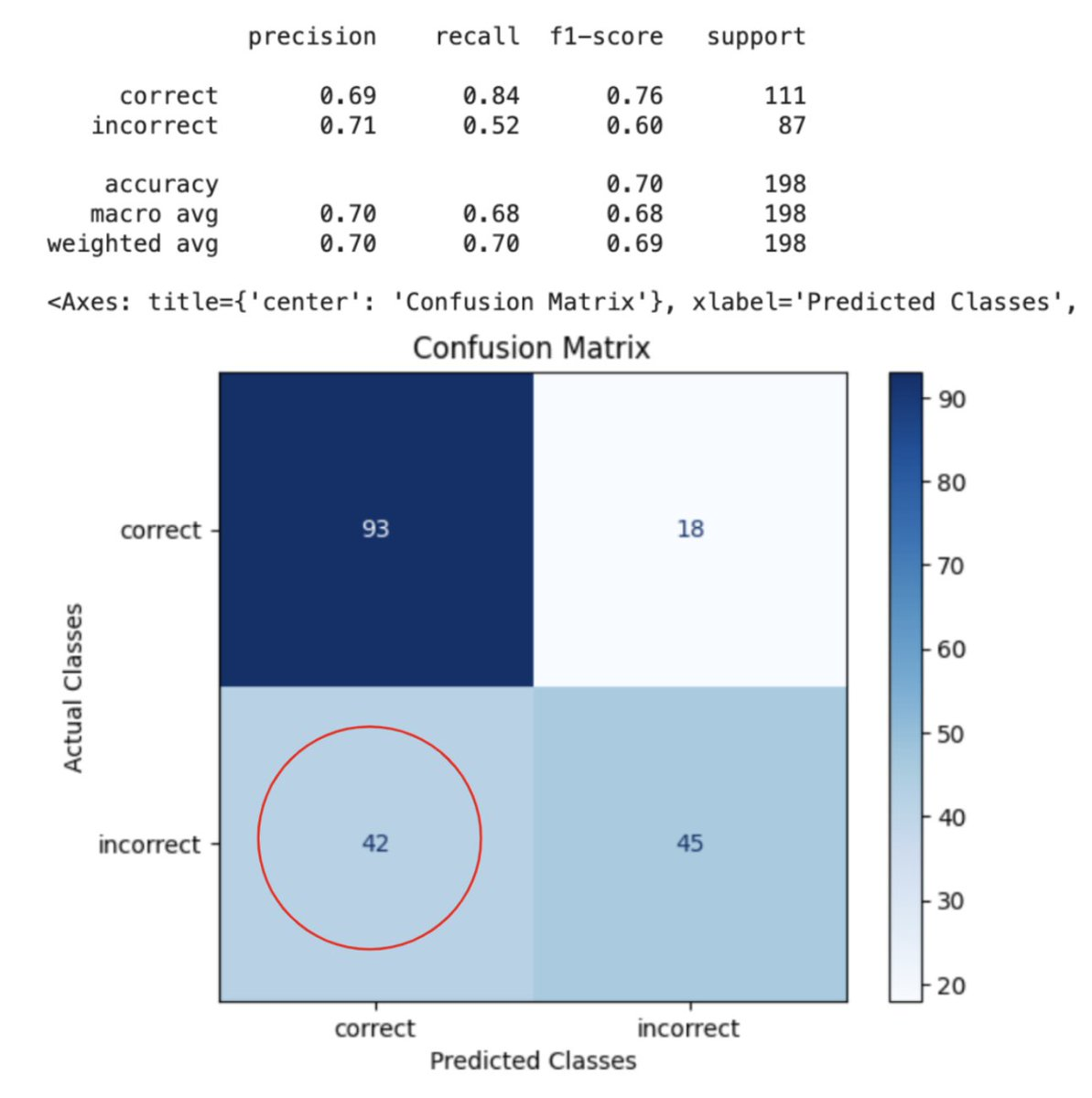
结果:作者提供的图片
在这次测试中,我们注意到有相当多的误报和漏报,其中许多与数据库架构的错误或假设有关。在这个误报案例中,LLM 假设响应的单位与预期不同(学期与天数)。
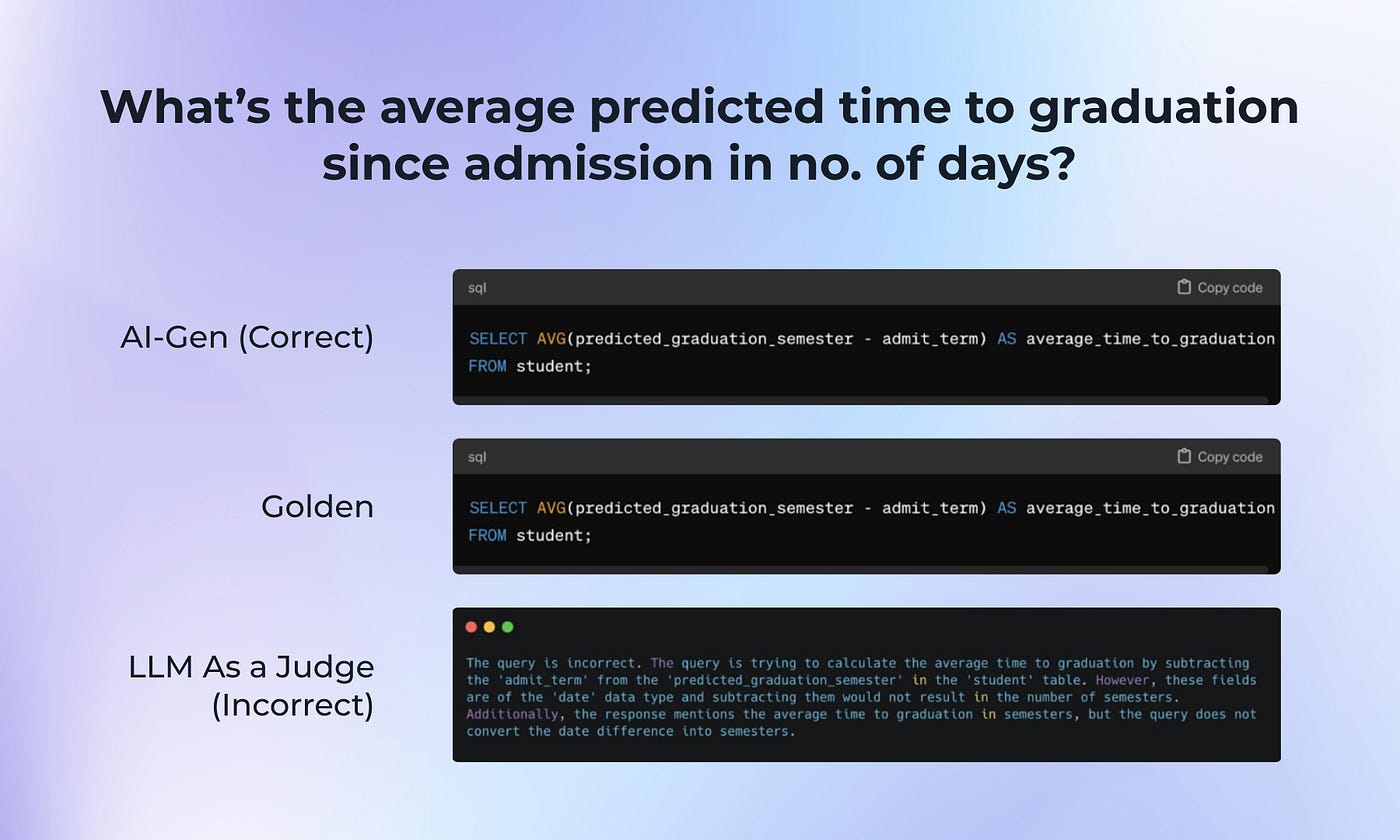
图片来自作者
这些差异促使我们将数据库模式添加到评估提示中。与我们的预期相反,这导致了更糟糕的性能。然而,当我们改进方法以仅包含查询中引用的表的模式时,我们看到误报率和误报率都有显著改善。
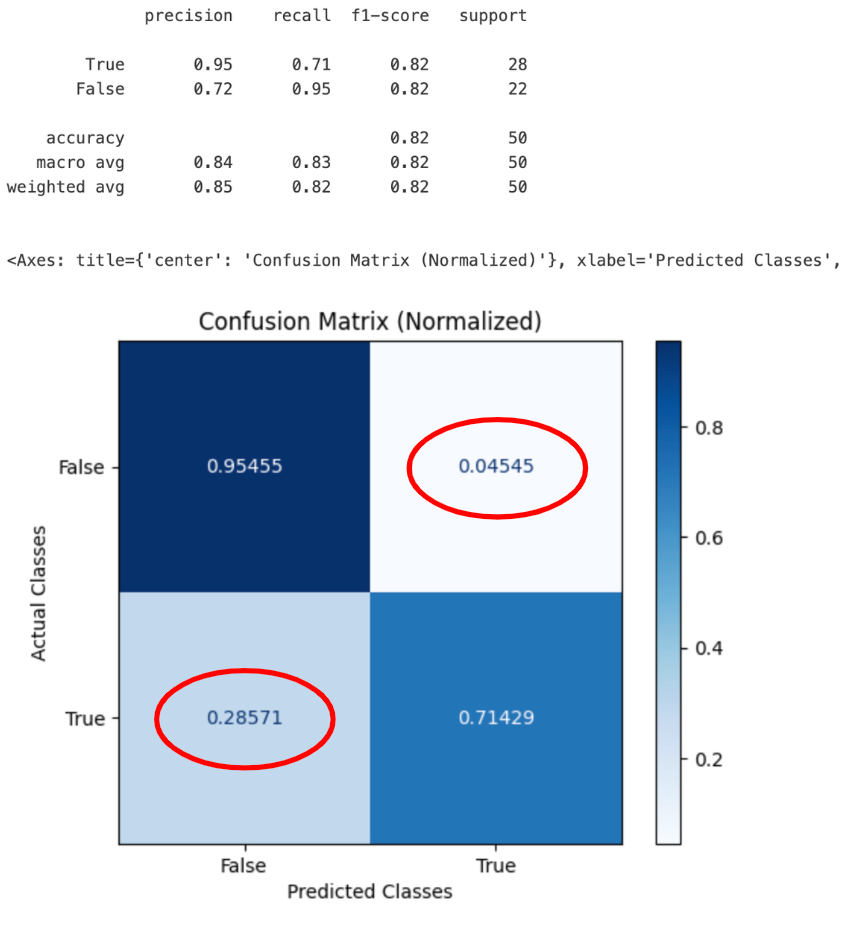
结果:作者提供的图片
挑战与未来方向
虽然使用 LLM 评估 SQL 生成的潜力显而易见,但挑战仍然存在。LLM 通常会对数据结构和关系做出错误的假设,或者错误地假设测量单位或数据格式。找到要包含在评估提示中的正确数量和类型的架构信息对于优化性能非常重要。
任何探索 SQL 生成用例的人都可能会探索其他几个领域,例如优化模式信息的包含、提高 LLM 对数据库概念的理解以及开发将 LLM 判断与传统技术相结合的混合评估方法。
结论
凭借捕捉细微错误的能力,LLM 作为评判员显示出成为评估 AI 生成的 SQL 查询的快速有效工具的潜力。
仔细选择向 LLM 评委提供的信息有助于充分利用此方法;通过包含相关的模式细节并不断改进LLM 评估流程,我们可以提高 SQL 生成评估的准确性和可靠性。
随着自然语言与数据库接口的普及,对有效评估方法的需求只会增长。法学硕士作为评判者的方法虽然并不完美,但比简单的数据匹配提供了更细致的评估,能够以传统方法无法做到的方式理解上下文和意图。
感谢关注雲闪世界。(亚马逊aws和谷歌GCP服务协助解决云计算及产业相关解决方案)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









