






 欢迎来到雲闪世界。Andrej Karpathy 是人工智能 (AI) 领域的顶尖研究人员之一。他是 OpenAI 的创始成员之一,曾领导特斯拉的 AI 部门,目前仍处于 AI 社区的前沿。
欢迎来到雲闪世界。Andrej Karpathy 是人工智能 (AI) 领域的顶尖研究人员之一。他是 OpenAI 的创始成员之一,曾领导特斯拉的 AI 部门,目前仍处于 AI 社区的前沿。
在第一部分中,我们重点介绍如何实现 GPT-2 的架构。虽然 GPT-2 于 2018 年由 OpenAI 开源,但它是用 Tensor Flow 编写的,这是一个比 PyTorch 更难调试的框架。因此,我们将使用更常用的工具重新创建 GPT-2。仅使用我们今天要创建的代码,您就可以创建自己的 LLM!
块大小— 告诉我们 Transformer 可以处理输入长度中的多少个位置。一旦超过此限制,性能就会下降,因为您必须回绕(您可以在我的 Long RoPE 博客中详细了解我们如何扩展此限制,而无需从头开始训练新模型)
词汇量——告诉我们模型能够理解和使用多少个独特的标记。一般来说,研究人员发现,词汇量越大,模型对语言的理解就越精确,并且能够捕捉到响应中的更多细微差别。
层 —我们神经网络的隐藏层的一部分。具体来说,我们指的是下面灰色框中显示的重复计算的次数:
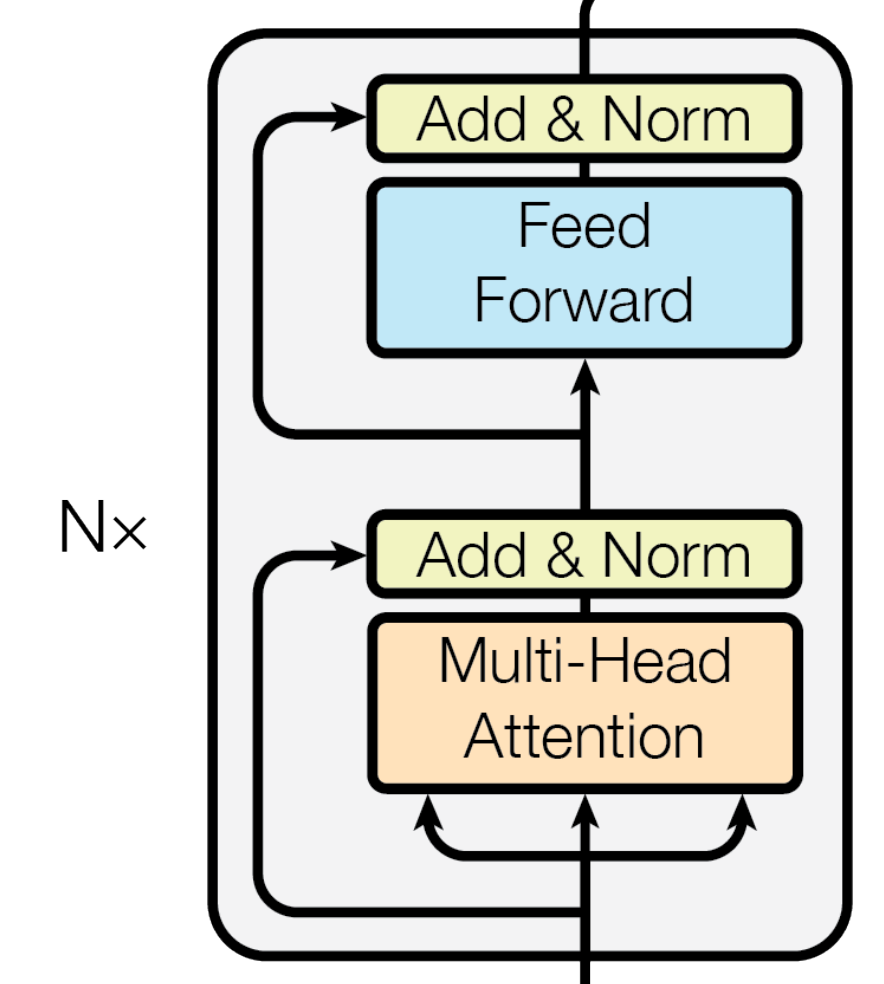
我们的模型中的一层
嵌入——我们传递给模型的数据的向量表示。
多头注意力——我们不是运行一次注意力,而是运行 n 次,然后将所有结果连接在一起以获得最终结果。
让我们进入代码吧!
GPT 类及其参数
@dataclass
class GPTConfig:
block_size : int = 1024
vocab_size : int = 50257
n_layer : int = 12
n_head : int = 12
n_embd : int = 768首先,我们在 GPTConfig 类中设置 5 个超参数。block_size似乎与 和 一样有些随意n_layer。n_head换句话说,这些值是根据研究人员认为具有最佳性能的值经验选择的。 此外,我们选择 786,因为n_embd这是为 GPT-2 论文选择的值,我们决定模仿它。
但是,是根据我们将使用的 GPT-2 标记器vocab_size设置的。GPT-2 标记器是使用字节对编码算法创建的(在此处阅读更多信息)。它从一组初始词汇开始(在我们的例子中是 256 个),然后根据新词汇出现在训练集中的频率,通过训练数据创建新词汇。它会一直这样做,直到达到极限(在我们的例子中是 50,000)。最后,我们将词汇留作内部使用(在我们的例子中是结束标记字符)。把它们加起来,我们得到了 50,257。tiktoken
class GPT(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
# ...设置好配置后,我们创建一个 GPT 类,它是 torchnn.Module类的一个实例。这是所有 PyTorch 神经网络的基类,因此通过使用它,我们可以访问 PyTorch 针对这些类型的模型的所有优化。每个优化nn.Module都有一个forward函数来定义模型前向传递期间发生的情况(稍后会详细介绍)。
我们首先运行基类中的超级构造函数,然后创建一个transformer对象ModuleDict。创建它是因为它可以让我们像对象一样进行索引transformer,当我们想要从 HuggingFace 加载权重时,以及当我们想要调试并快速浏览我们的模型时,它都会派上用场。
class GPT(nn.Module):
def __init__(self, config):
# ...
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(config.vocab_size, config.n_embd),
wpe = nn.Embedding(config.block_size, config.n_embd),
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
ln_f = nn.LayerNorm(config.n_embd)
))这里transformer有 4 个主要部分需要加载:token 嵌入的权重 ( wte)、位置编码的权重 ( wpe)、隐藏层 ( h) 和层规范化 ( )。此设置主要ln_f遵循“Attention is All You Need”中 Transformer 架构的解码器部分(输出嵌入 ~ 、位置编码 ~ 、隐藏层 ~ )。一个关键的区别是,在我们的架构中,所有隐藏层完成后,我们还有一个额外的规范化层。wtewtehln_f
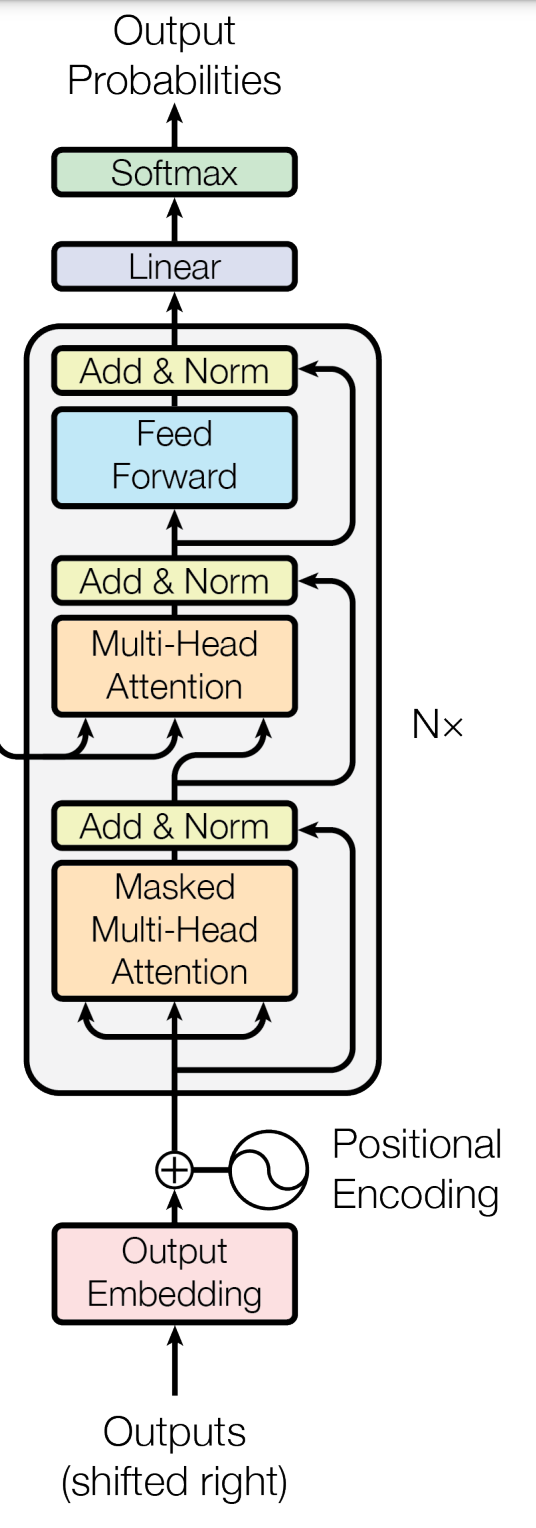
“Attention is All You Need”中展示的解码器架构的一半
wte和都是wpe嵌入,因此我们自然nn.Embedding会使用 类 来表示它们。我们的隐藏层是 Transformer 的大部分逻辑所在,所以我稍后会详细介绍。现在,只需注意我们正在创建对象的循环,以便Block我们拥有n.layer。最后,我们使用内置的nn.LayerNorm,ln_f它将根据以下等式对我们的输出进行规范化(其中 x 和 y 是输入和输出,E[x] 是平均值,γ 和 β 是可学习的权重)。
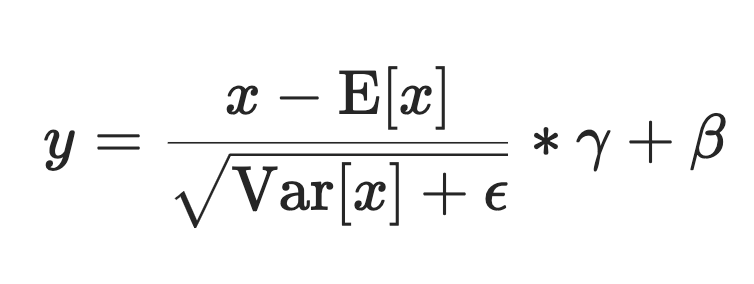
class GPT(nn.Module):
def __init__(self, config):
# ...
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
# weight sharing scheme
self.transformer.wte.weight = self.lm_head.weight
# initalize weights
self.apply(self._init_weights)接下来,我们设置网络的最后一个线性层,它将生成模型的逻辑。在这里,我们从模型的嵌入维度(768)投影到模型的词汇量(50,257)。这里的想法是,我们采用了隐藏状态并将其扩展以映射到我们的词汇表上,以便我们的解码器头可以使用每个词汇表上的值来确定下一个标记应该是什么。
最后,在我们的构造函数中,我们有一个有趣的优化,我们告诉模型使标记器权重与线性层权重相同。这样做是因为我们希望线性层和标记器对标记有相同的理解(如果两个标记在输入模型时相似,则模型输出时相同的两个标记也应该相似)。最后,我们初始化模型的权重,以便我们可以开始训练。
class GPT(nn.Module):
# ...
def forward(self, idx, targets=None):
B, T = idx.size()
assert T <= self.config.block_size, f"maximum sequence length breached"
pos = torch.arange(0, T, dtype=torch.long, device=idx.device)
pos_emb = self.transformer.wpe(pos)
tok_emb = self.transformer.wte(idx)
x = tok_emb + pos_emb # hidden broadcast
for block in self.transformer.h:
x = block(x)
x = self.transformer.ln_f(x)
logits = self.lm_head(x)
loss = None
if targets is not None:
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1))
return logits, loss我们的前向函数精确地说明了我们的模型在前向传递过程中的行为方式。我们首先验证我们的序列长度不大于我们配置的最大值 ( block_size)。一旦验证通过,我们将创建一个值为 0 到 T-1 的张量(例如,如果 T = 4,我们将有 tensor([0, 1, 2, 3]) 并通过我们的位置嵌入权重运行它们。完成后,我们将通过 token 嵌入权重运行输入张量。
我们将 token 和位置嵌入组合成x,需要广播来组合它们。由于 大于tok_emb(pos_emb在我们的示例中为 50257 vs 1024),x 的尺寸为tok_emb。现在是我们的隐藏状态,我们将通过 for 循环将其传递到隐藏层。我们小心地在每次通过一个块后x进行更新。x
接下来,我们x通过 LayerNormalization进行归一化ln_f,然后进行线性投影以获得预测下一个标记所需的 logit。如果我们正在训练模型(我们通过参数发出信号targets),我们将计算我们刚刚生成的 logit 和变量中保存的地面真实值之间的交叉熵targets。我们通过损失函数实现这一点cross_entropy。为了正确做到这一点,我们需要通过 将logits和转换target为正确的形状.view()。我们要求 pytorch 在通过 -1 时推断出正确的大小。
这个类中还有一个函数,即初始化函数,但我们稍后会讨论初始化逻辑。现在,让我们深入研究 Block 逻辑,它将帮助我们实现多头注意力和 MLP。
块类
class Block(nn.Module):
def __init__(self, config):
super().__init__()
self.ln_1 = nn.LayerNorm(config.n_embd)
self.attn = CausalSelfAttention(config)
self.ln_2 = nn.LayerNorm(config.n_embd)
self.mlp = MLP(config)
# ...Block 被实例化为nn.Module,因此我们也在开始时调用超级构造函数进行优化。接下来,我们设置与“Attention is All You Need”论文中所述的相同计算 — 2 层规范化、注意力计算和通过 MLP 的前馈层。
《注意力就是一切》中的隐藏层
class Block(nn.Module):
# ...
def forward(self, x):
x = x + self.attn(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x然后,我们定义一个forward函数,PyTorch 将在模型的每次前向传递中调用该函数。请注意,这里我们做的事情与“注意力就是你所需要的一切”不同。我们分别将层规范化设置为在注意力和前馈之前发生。这是 GPT-2 论文见解的一部分,你可以看到,像这样进行微小的改变会带来巨大的不同。请注意,原始张量的添加保持在相应的相同位置。当我们设置权重初始化函数时,这 2 个添加将非常重要。
这个类是一个很好的抽象,因为它让我们可以交换注意力的实现或者选择除了 MLP 之外的另一种前馈函数,而不必大规模重构代码。
CausalSelfAttention 类
class CausalSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
assert config.n_embd % config.n_head == 0
self.c_attn = nn.Linear(config.n_embd, 3*config.n_embd)
self.c_proj = nn.Linear(config.n_embd, config.n_embd)
self.c_proj.NANOGPT_SCALE_INIT = 1
self.n_head = config.n_head
self.n_embd = config.n_embd
self.register_buffer('bias', torch.tril(torch.ones(config.block_size, config.block_size))
.view(1,1, config.block_size, config.block_size))
# ...注意力是我们模型的重要组成部分,因此这里自然有许多配置。我们使用 assert 语句作为调试工具,以确保我们传递的配置维度是兼容的。然后我们创建一些辅助函数,这些函数将在我们进行自我注意力时为我们提供帮助。首先,我们有c_attn和,c_proj它们是线性投影,可将我们的隐藏状态转换为注意力计算所需的新维度。c_proj.NANOGPT_SCALE_INIT是我们在此处和 MLP 中设置的标志,它将帮助我们稍后进行权重初始化(实际上,这可以命名为任何名称)。
最后,我们告诉 torch 创建一个名为 的缓冲区,该缓冲区在训练期间不会更新bias。偏差将是一个尺寸为block_sizex的下三角矩阵block_size,然后我们将其转换为尺寸为 1 x 1 x block_sizex 的4D 张量block_size。1 x 1 已完成,以便我们可以在单个通道中批量计算这些。此缓冲区将用于对我们的多头注意力应用掩码。
class CausalSelfAttention(nn.Module):
# ...
def forward(self, x):
B, T, C = x.size() # batch size, sequence length, channels
qkv = self.c_attn(x)
q, k, v = qkv.split(self.n_embd, dim=2)
# transpose is done for efficiency optimization
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
att = (q @ k.transpose(-2,-1)) * (1.0 / math.sqrt(k.size(-1)))
att = att.masked_fill(self.bias[:, :, :T, :T] == 0, float("-inf"))
att = F.softmax(att, dim=-1)
y = att @ v
y = y.transpose(1,2).contiguous().view(B, T, C)
y = self.c_proj(y)
return y现在开始实现注意力机制,重点是让它在 torch 中表现优异。逐行来看,我们首先找到输入张量 x 中的批处理大小、序列长度和通道。然后,我们将调用c_attn之前的函数将隐藏状态投影到我们需要的维度中。然后,我们将结果拆分为 3 个 (B、T、C) 形状的张量(具体来说,一个用于查询,一个用于键,一个用于值)。
然后,我们调整 q、k 和 v 的维度,以便能够高效地对这些维度进行多头注意。通过将维度从 (B, T, C) 更改为 (B, T, self.n_head, C // self.n_head),我们正在划分数据,以便每个头部都有自己独特的数据来操作。我们转置视图,以便我们可以制作T第三维度和self.n_head第二维度,从而让我们更容易地连接头部。
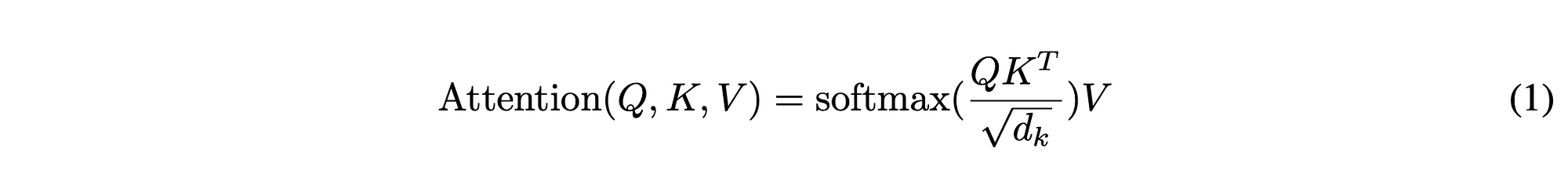
注意力方程式来自“注意力就是你所需要的一切”
现在我们有了值,我们可以开始计算了。我们在查询和键之间执行矩阵乘法(确保将键转置为正确的方向),然后除以 k 大小的平方根。经过此计算后,我们应用来自寄存器的偏差,以便未来 token 的注意力数据不会影响当前的 token(这就是为什么我们只对时间和通道维度大于 T 的 token 应用掩码的原因)。完成后,我们应用 softmax 仅传递某些信息。
一旦打开掩码,我们将值乘以 v,然后将值转置回 (B, T, self.n_head, C // self.n_head) 设置。我们调用.contiguous()以确保内存中的所有数据都彼此相邻排列,最后将张量转换回它所带的 (B, T, C) 维度(因此,在此步骤中连接我们的注意力头)。
最后,我们使用线性投影c_proj转换回隐藏状态的原始维度。
MLP 类
class MLP(nn.Module):
def __init__(self, config):
super().__init__()
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd)
self.gelu = nn.GELU(approximate="tanh")
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd)
self.c_proj.NANOGPT_SCALE_INIT = 1
# ...与之前的所有类一样,MLP 继承自nn.Module。我们首先设置一些辅助函数——特别是c_fc和c_proj线性投影层,分别从我们的嵌入扩展到 4 倍大小,然后再扩大回来。接下来,我们有 GELU。Karpathy 强调说,这里的近似参数只是为了让我们能够紧密匹配 GPT-2 论文而设置的。虽然当时 GELU 的近似是必要的,但现在我们不再需要近似——我们可以精确计算。
class MLP(nn.Module):
# ...
def forward(self, x):
x = self.c_fc(x)
x = self.gelu(x)
x = self.c_proj(x)
return x那么我们的前向传递就相对简单了。我们在输入张量上调用每个函数并返回最终结果。
拥抱脸部连接代码
由于 GPT-2 是开源的,因此可以在 Hugging Face 上使用。虽然我们的目标是训练我们自己的模型,但能够将我们的结果与 OpenAI 在训练中发现的结果进行比较还是不错的。为了做到这一点,我们有下面的函数来提取权重并将其填充到我们的GPT类中。
此代码还允许我们重复使用此代码来从 Hugging Face 中提取基础模型并对其进行微调(进行了一些修改,因为目前它仅针对 gpt-2 进行了优化)。
class GPT(nn.Module):
# ...
@classmethod
def from_pretrained(cls, model_type):
"""Loads pretrained GPT-2 model weights from huggingface"""
assert model_type in {'gpt2', 'gpt2-medium', 'gpt2-large', 'gpt2-xl'}
from transformers import GPT2LMHeadModel
print("loading weights from pretrained gpt: %s" % model_type)
# n_layer, n_head and n_embd are determined from model_type
config_args = {
'gpt2': dict(n_layer=12, n_head=12, n_embd=768), # 124M params
'gpt2-medium': dict(n_layer=24, n_head=16, n_embd=1024), # 350M params
'gpt2-large': dict(n_layer=36, n_head=20, n_embd=1280), # 774M params
'gpt2-xl': dict(n_layer=48, n_head=25, n_embd=1600), # 1558M params
}[model_type]
config_args['vocab_size'] = 50257 # always 50257 for GPT model checkpoints
config_args['block_size'] = 1024 # always 1024 for GPT model checkpoints
# create a from-scratch initialized minGPT model
config = GPTConfig(**config_args)
model = GPT(config)
sd = model.state_dict()
sd_keys = sd.keys()
sd_keys = [k for k in sd_keys if not k.endswith('.attn.bias')] # discard this mask / buffer, not a param
# ...从顶部开始,我们引入 HuggingFace 的transformers库并设置在 GPT-2 模型的不同变体之间变化的超参数。由于和vocab_size没有block_size变化,您可以看到我们将它们硬编码进去。然后我们将这些变量传递到GPTConfig之前的类中,然后实例化模型对象(GPT)。最后,我们从模型中删除所有以结尾的键.attn.bias,因为这些不是权重,而是我们之前设置的寄存器,用于帮助我们的注意力函数。
class GPT(nn.Module):
# ...
@classmethod
def from_pretrained(cls, model_type):
# ...
model_hf = GPT2LMHeadModel.from_pretrained(model_type)
sd_hf = model_hf.state_dict()
# copy while ensuring all of the parameters are aligned and match in names and shapes
sd_keys_hf = sd_hf.keys()
sd_keys_hf = [k for k in sd_keys_hf if not k.endswith('.attn.masked_bias')] # ignore these, just a buffer
sd_keys_hf = [k for k in sd_keys_hf if not k.endswith('.attn.bias')] # same, just the mask (buffer)
transposed = ['attn.c_attn.weight', 'attn.c_proj.weight', 'mlp.c_fc.weight', 'mlp.c_proj.weight']
# basically the openai checkpoints use a "Conv1D" module, but we only want to use a vanilla Linear
# this means that we have to transpose these weights when we import them
assert len(sd_keys_hf) == len(sd_keys), f"mismatched keys: {len(sd_keys_hf)} != {len(sd_keys)}"接下来,我们从 HuggingFace 类中加载模型GPT2LMHeadModel。我们从这个模型中取出键,同样忽略attn.masked_bias和attn.bias键。然后我们有一个断言来确保 hugging face 模型中的键数与我们模型中的键数相同。
class GPT(nn.Module):
# ...
@classmethod
def from_pretrained(cls, model_type):
# ...
for k in sd_keys_hf:
if any(k.endswith(w) for w in transposed):
# special treatment for the Conv1D weights we need to transpose
assert sd_hf[k].shape[::-1] == sd[k].shape
with torch.no_grad():
sd[k].copy_(sd_hf[k].t())
else:
# vanilla copy over the other parameters
assert sd_hf[k].shape == sd[k].shape
with torch.no_grad():
sd[k].copy_(sd_hf[k])
return model为了完善该函数,我们循环遍历 Hugging Face 模型中的每个键,并将其权重添加到我们模型中的相应键。有些键需要进行操作,以便它们适合我们使用的数据结构。我们运行该函数.t()将 hugging face 矩阵转置为我们所需的尺寸。对于其余部分,我们直接复制它们。你会注意到我们正在使用torch.no_grad()。这告诉 torch 它不需要缓存模型反向传播的值,这是另一个使其运行更快的优化。
生成我们的第一个预测(采样循环)
有了现在的类,我们可以运行模型并让它给我们输出标记(只需确保如果你按顺序执行此操作,请在 GPT 构造函数中注释掉 _init_weights 调用)。下面的代码显示了我们如何做到这一点。
device = "cpu"
if torch.cuda.is_available():
device = "cuda"
elif hasattr(torch.backends, "mps") and torch.backends.mps.is_available():
device = "mps"
print(f"device {device}")
torch.manual_seed(1337)
model = GPT(GPTConfig())
model.eval()
model.to(device)我们首先确定可以使用哪些设备。Cuda 是 NVIDIA 的平台,可以运行极快的 GPU 计算,因此如果我们可以使用使用 CUDA 的芯片,我们就会使用它们。如果我们无法访问,但我们使用的是 Apple Silicon,那么我们将使用它。最后,如果我们两者都没有,那么我们会回到 CPU(这将是最慢的,但每台计算机都有一个,所以我们知道我们仍然可以在它上面进行训练)。
然后,我们使用默认配置实例化我们的模型,并将模型置于“ eval”模式 —(这会执行许多操作,例如禁用 dropout,但从高层次来看,它可以确保我们的模型在推理过程中更加一致)。设置完成后,我们将模型移动到我们的设备上。请注意,如果我们想使用 HuggingFace 权重而不是我们的训练权重,我们将修改倒数第三行以读取:model = GPT.from_pretrained(‘gpt2’)
import tiktoken
enc = tiktoken.get_encoding('gpt2')
tokens = enc.encode("Hello, I'm a language model,")
tokens = torch.tensor(tokens, dtype=torch.long)
tokens = tokens.unsqueeze(0).repeat(num_return_sequences, 1)
x = tokens.to(device)我们现在引入tiktokengpt2 编码并让其标记化我们的提示。我们获取这些标记并将其放入张量中,然后在下面的行中将其转换为批次。unsqueeze()将向张量添加一个大小为 1 的新的第一个维度,并将在第一个维度内repeat重复整个张量num_return_sequences时间,在第二个维度内重复一次。我们在这里所做的是格式化我们的数据以适合我们的模型期望的批处理模式。具体来说,我们现在匹配 (B, T) 格式:num_return_sequencesx 编码的提示长度。一旦我们将输入张量传递到模型的开头,我们的wte和wpe将创建 C 维度。
while x.size(1) < max_length:
with torch.no_grad():
logits, _ = model(x)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
topk_probs, topk_indices = torch.topk(probs, 50, dim=-1)
ix = torch.multinomial(topk_probs, 1)
xcol = torch.gather(topk_indices, -1, ix)
x = torch.cat((x, xcol), dim=1)现在它们已经准备好了,我们将它们发送到设备并开始采样循环。该循环将完全是前向传递,因此我们将其包装在中torch.no_grad以阻止其缓存任何后向传播。我们的 logits 形状为 (batch_size, seq_len, vocab_size) — (B,T,C),其中 C 位于模型的前向传递之后。
我们只需要序列中的最后一项来预测下一个标记,因此我们取出[:, -1, :]然后我们获取这些 logit 并将其运行softmax以获得标记概率。取前 50 名,然后我们选择前 50 名的随机索引并将其选为我们的预测标记。然后我们获取有关该信息并将其添加到我们的张量中x。通过连接xcol到x,我们可以根据我们刚刚预测的内容进入下一个标记。这就是我们编写自回归的方法。
for i in range(num_return_sequences):
tokens = x[i, :max_length].tolist()
decoded = enc.decode(tokens)
print(f">> {decoded}")采样循环完成后,我们可以遍历每个选定的标记并对其进行解码,向用户显示响应。我们从i批处理中的第个标记中抓取数据并对其进行解码以获取下一个标记。
如果您在我们的初始模型上运行采样循环,您会注意到输出有很多不足之处。这是因为我们还没有训练任何权重。接下来的几节课将展示如何开始对模型进行简单的训练。
数据加载器精简版
所有训练都需要高质量的数据。对于 Karpathy 的视频,他喜欢使用公共领域的莎士比亚文本(更纤细的数据可在此处找到)。
class DataLoaderLite:
def __init__(self, B, T):
self.B = B
self.T = T
with open('shakespeare.txt', "r") as f:
text = f.read()
enc = tiktoken.get_encoding('gpt2')
tokens = enc.encode(text)
self.tokens = torch.tensor(tokens)
print(f"1 epoch = {len(self.tokens) // B * T} batches")
self.current_position = 0我们首先简单地打开文件并读入文本。此数据源仅为 ASCII,因此我们不必担心任何意外的二进制字符。我们使用tiktoken来获取正文的编码,然后将这些标记转换为张量。然后,我们创建一个名为的变量current_position,它将让我们知道我们当前正在从标记张量中的哪个位置进行训练(自然,这被初始化为开头)。请注意,此类不是从继承的nn.Module,主要是因为我们这里不需要该forward函数。与采样循环的提示部分一样,我们的 DataLoaderLite 类只需要生成形状为 (B, T) 的张量。
class DataLoaderLite:
# ...
def next_batch(self):
B, T = self.B, self.T
buf = self.tokens[self.current_position: self.current_position+(B*T + 1)]
x = (buf[:-1]).view(B, T)
y = (buf[1:]).view(B,T)
self.current_position += B * T
if self.current_position + (B*T+1) > len(self.tokens):
self.current_position = 0
return x,y在上面我们定义了next_batch帮助训练的函数。为了让程序运行得更快,我们喜欢批量运行计算。我们使用 B 和 T 字段来确定我们将要训练的批次大小 (B) 和序列长度 (T)。使用这些变量,我们创建一个缓冲区来保存我们将要训练的标记,将维度设置为行 B 和列 T。请注意,我们从 读取到current_position,current_position + (B*T + 1)其中 +1 是为了确保我们拥有批次的所有基本事实值B*T。
然后,我们按照相同的方式设置模型输入 ( x) 和预期输出 ( )。是除最后一个字符之外的整个缓冲区,是除第一个字符之外的整个缓冲区。基本思想是,给定令牌缓冲区中的第一个值,我们期望从模型中获取令牌缓冲区中的第二个令牌。yxy
最后,我们更新current_position并返回x和y。
权重初始化
因为我们处理的是概率,所以我们想要为权重选取初始值,这样就可能需要更少的训练次数才能正确计算。我们的_init_weights函数可以帮助我们做到这一点,方法是用零或正态分布初始化权重。
class GPT(nn.Module):
# ...
def _init_weights(self, module):
# layer norm is by default set to what we want, no need to adjust it
if isinstance(module, nn.Linear):
std = 0.02
if hasattr(module, "NANOGPT_SCALE_INIT"):
std *= (2 * self.config.n_layer) ** -0.5 # 2 * for 2 additions (attention & mlp)
torch.nn.init.normal_(module.weight, mean=0.0, std=std)
# reasonable values are set based off a certain equation
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02 )如果您还记得之前的内容,我们将 GPT 类的每个字段都传入了_init_weights,因此我们正在处理nn.Modules 。我们使用 Xavier 方法来初始化我们的权重,这意味着我们将采样分布的标准差设置为1 / sqrt(hidden_layers)。您会注意到,在代码中,我们经常使用硬编码的 0.02 作为标准差。虽然这看起来可能很随意,但从下表中您可以看到,由于 GPT-2 使用的隐藏维度都大约为 0.02,因此这是一个很好的近似值。
查看代码时,我们首先检查nn.Module正在操作的模块属于哪种子类型。
如果模块是线性的,那么我们将检查它是否是我们从MLP或CasualSelfAttention类中投影的投影之一(通过检查它是否设置了NANO_GPT_INIT标志)。如果是,那么我们的 0.02 近似值将不起作用,因为这些模块中的隐藏层数量正在增加(这是我们在类中添加张量的函数Block)。因此,GPT-2 论文使用缩放函数来解释这一点:1/sqrt(2 * self.config.n_layer)。2*是因为我们的Block有 2 个地方我们要添加张量。
如果线性模块中有偏差,我们将首先将它们全部初始化为零。
如果我们有一个Embedding模块(如令牌或位置编码部分),我们将使用相同的正态分布(标准差为 0.02)对其进行初始化。
如果您还记得的话,我们的模型中还有另一种模块子类型:nn.LayerNorm。此类已使用正态分布进行了初始化,因此我们认为这已经足够好了,不需要进行任何更改。
训练循环
现在我们已经设置了训练基础,让我们组合一个快速训练循环来训练我们的模型。
device = "cpu"
if torch.cuda.is_available():
device = "cuda"
elif hasattr(torch.backends, "mps") and torch.backends.mps.is_available():
device = "mps"
print(f"device {device}")
num_return_sequences = 5
max_length = 30
torch.manual_seed(1337)
train_loader = DataLoaderLite(B=4, T=32)
model = GPT(GPTConfig())
model.to(device)您可以看到,我们重复设备计算以获得最佳性能。然后,我们将数据加载器设置为使用批处理大小 4 和序列长度 32(任意设置,尽管 2 的幂对内存效率最好)。
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4)
for i in range(50):
x, y = train_loader.next_batch()
x, y = x.to(device), y.to(device)
optimizer.zero_grad() #have to start with a zero gradient
logits, loss = model(x, y)
loss.backward() #adds to the gradient (+=, which is why they must start as 0)
optimizer.step()
print(f"loss {loss.item()}, step {i}")现在我们有了优化器,它将帮助我们训练模型。优化器是一个 PyTorch 类,它接收应该训练的参数(在我们的例子中是从类中给出的参数GPT),然后接收学习率,它是训练期间的一个超参数,决定了我们应该以多快的速度调整参数——学习率越高意味着每次运行后权重的变化越大。我们根据 Karpathy 的建议选择了我们的值。
然后我们使用 50 个训练步骤来训练模型。我们首先获取训练批次并将其移动到我们的设备上。我们将优化器的梯度设置为零(pytorch 中的梯度是总和,因此如果我们不将其归零,我们将从上一批中携带信息)。我们计算模型的 logits 和损失,然后运行反向传播以确定新的权重模型应该是什么。最后,我们运行optimizer.step()以更新我们所有的模型参数。
完整性检查
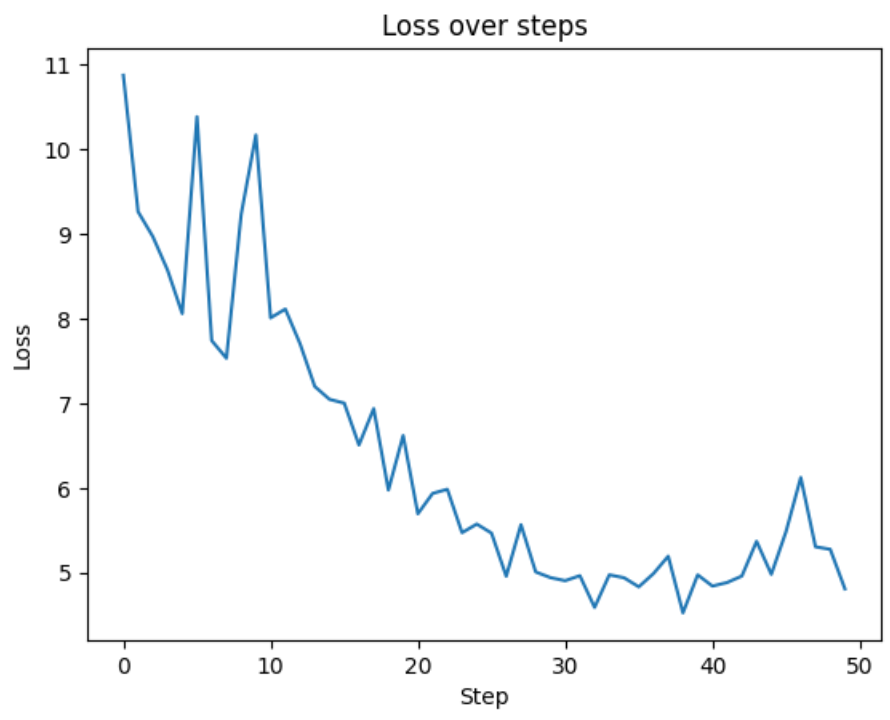
要查看上述所有代码的运行情况,您可以查看我的 Google Colab,我将所有这些代码组合起来并在 NVIDIA T4 GPU 上运行。运行我们的训练循环,我们看到损失从 ~11 开始。为了进行合理性测试,我们预计在开始时预测正确标记的几率是 (1/ vocab_size)。通过简化的损失函数-ln,我们得到 ~10.88,这正是我们开始的地方!
感谢关注雲闪世界。(亚马逊aws和谷歌GCP服务协助解决云计算及产业相关解决方案)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)















 8069
8069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









