






Andrej Karpathy 的“让我们重现 GPT-2 (124M)”第 2 部分中的硬件优化

欢迎来到雲闪世界。为了撰写这篇博文,我在 Google Colab 免费提供的 NVIDIA T4 GPU 和 Lambda Labs 的 NVIDIA A100 GPU 40GB SXM4 上都进行了优化。Karpathy 介绍的大多数优化都是针对 A100 或更高版本的,但在性能较弱的 GPU 上仍可取得一些进步。
计时代码
首先,我们要创建一种方法来查看我们的优化效果。为此,我们将在训练循环中添加以下代码:
for i in range(50):
t0 = time.time() # start timer
x, y = train_loader.next_batch()
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
logits, loss = model(x, y)
loss.backward()
optimizer.step()
torch.cuda.synchronize() # synchronize with GPU
t1 = time.time() # end timer
dt = (t1-t0)*1000 # milliseconds difference
print(f"loss {loss.item()}, step {i}, dt {dt:.2f}ms")我们首先捕获循环开始时的时间,但在捕获结束时间之前,我们运行torch.cuda.synchronize()。默认情况下,我们只关注 CPU 何时停止。由于我们将大部分主要计算移至 GPU,因此我们需要确保此处的计时器考虑到 GPU 何时停止计算。同步将使 CPU 等待,直到 GPU 完成其工作队列,从而为我们提供循环完成的准确时间。一旦我们有了准确的时间,我们自然就会计算开始和结束之间的差异。
批次大小
我们还希望确保每轮都输入尽可能多的数据。我们实现这一点的方法是设置批处理大小。在我们的DataLoaderLite课程中,我们可以调整 2 个参数(B 和 T),以便在不超出范围的情况下使用 GPU 中的最大内存量。
使用 A100 GPU,您可以遵循 Karpathy 的示例,其中我们将 T 设置为最大值block_size1024,并将 B 设置为 16,因为它是一个“好”数字(很容易被 2 的幂整除)并且它是我们可以在内存中容纳的最大的“好”数字。
train_loader = DataLoaderLite(B=16, T=1024)如果您尝试输入一个过大的值,您最终会OutOfMemoryError在终端中看到来自 CUDA 的结果。我发现我能得到的 T4 GPU 的最佳值是 B =4 和 T =1024(在 Google Colab 中尝试不同的 B 值时,请注意您可能需要重新启动会话以确保您没有得到OutOfMemoryError误报)
在下面的 A100 和 T4 上运行时,我得到了以下图表,显示了开始训练的时间(T4 上平均大约 1100 毫秒,A100 上平均大约 1040 毫秒)
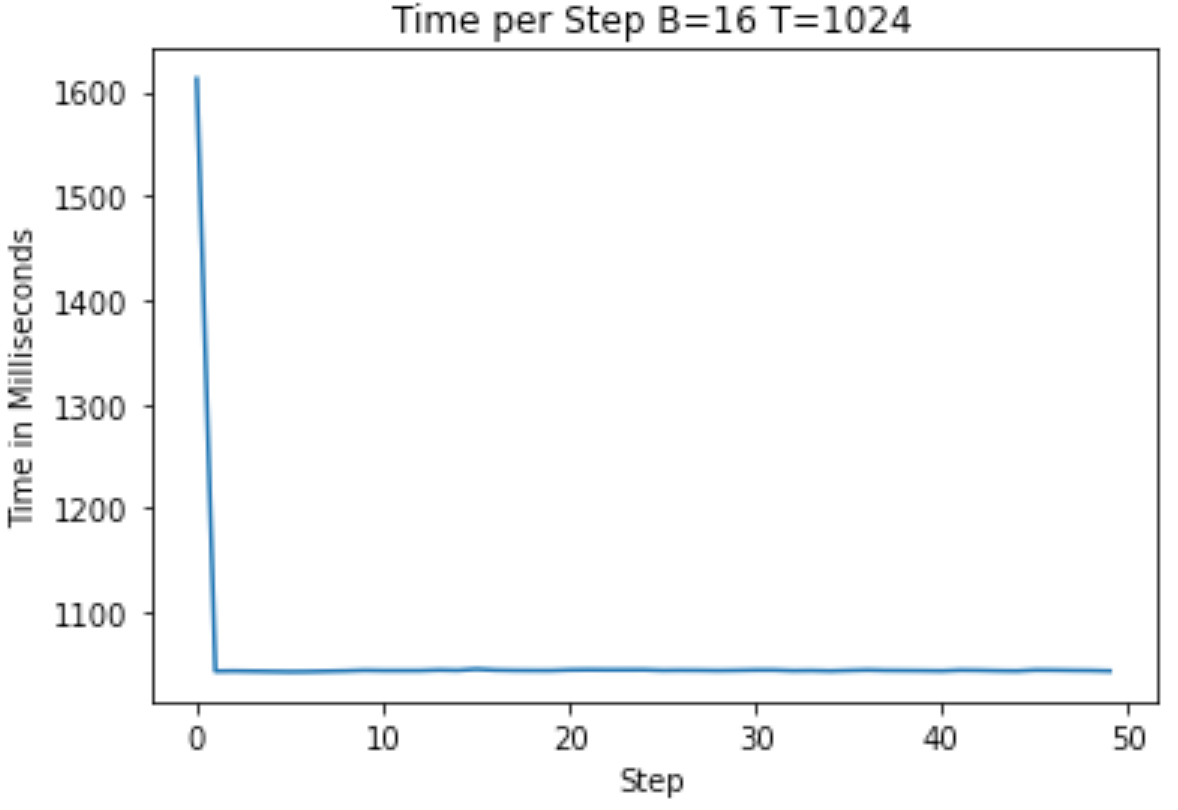
作者提供的图片 — 未经优化的 A100 训练
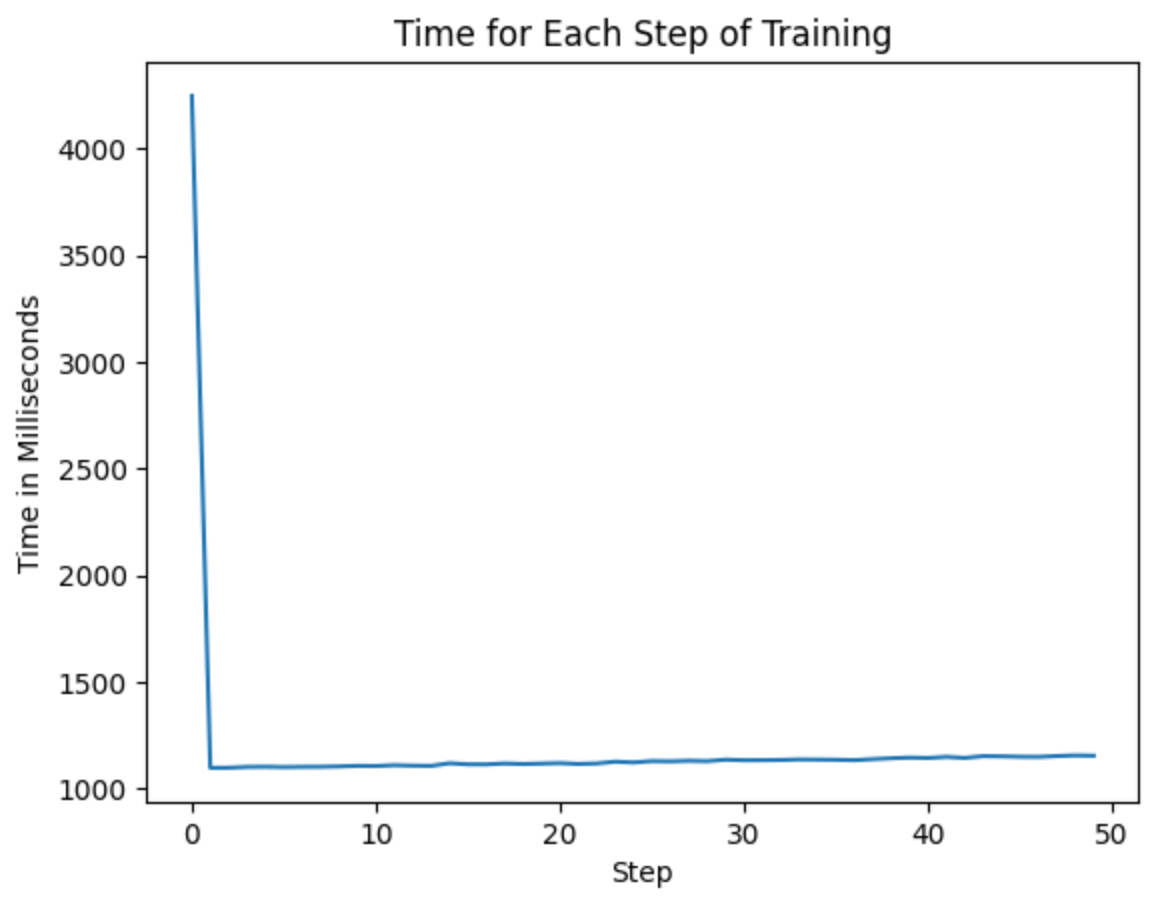
作者提供的图片 — 未经优化的 T4 训练
浮点优化
现在我们将重点关注对模型内数据内部表示所做的改变。
如果您查看dtype第 1 节中代码中的权重,您会发现我们默认使用浮点 32 (fp32)。Fp32 表示我们按照以下 IEEE 浮点标准使用 32 位表示数字:

作者提供的图片 — IEEE 浮点 32 表示法 (FP32)
正如 Karpathy 在视频中所说,我们已经从经验中看到,fp32 对于训练高质量模型来说并不是必需的——我们可以使用更少的数据来表示每个权重,同时仍然获得高质量的输出。加快计算速度的一种方法是使用 NVIDIA 的 TensorCore 指令。这将通过将操作数转换为如下所示的 Tensor Float 32 (TF32) 形式来处理矩阵乘法:

作者提供的图片 — Tensor Float 32 (TF32)
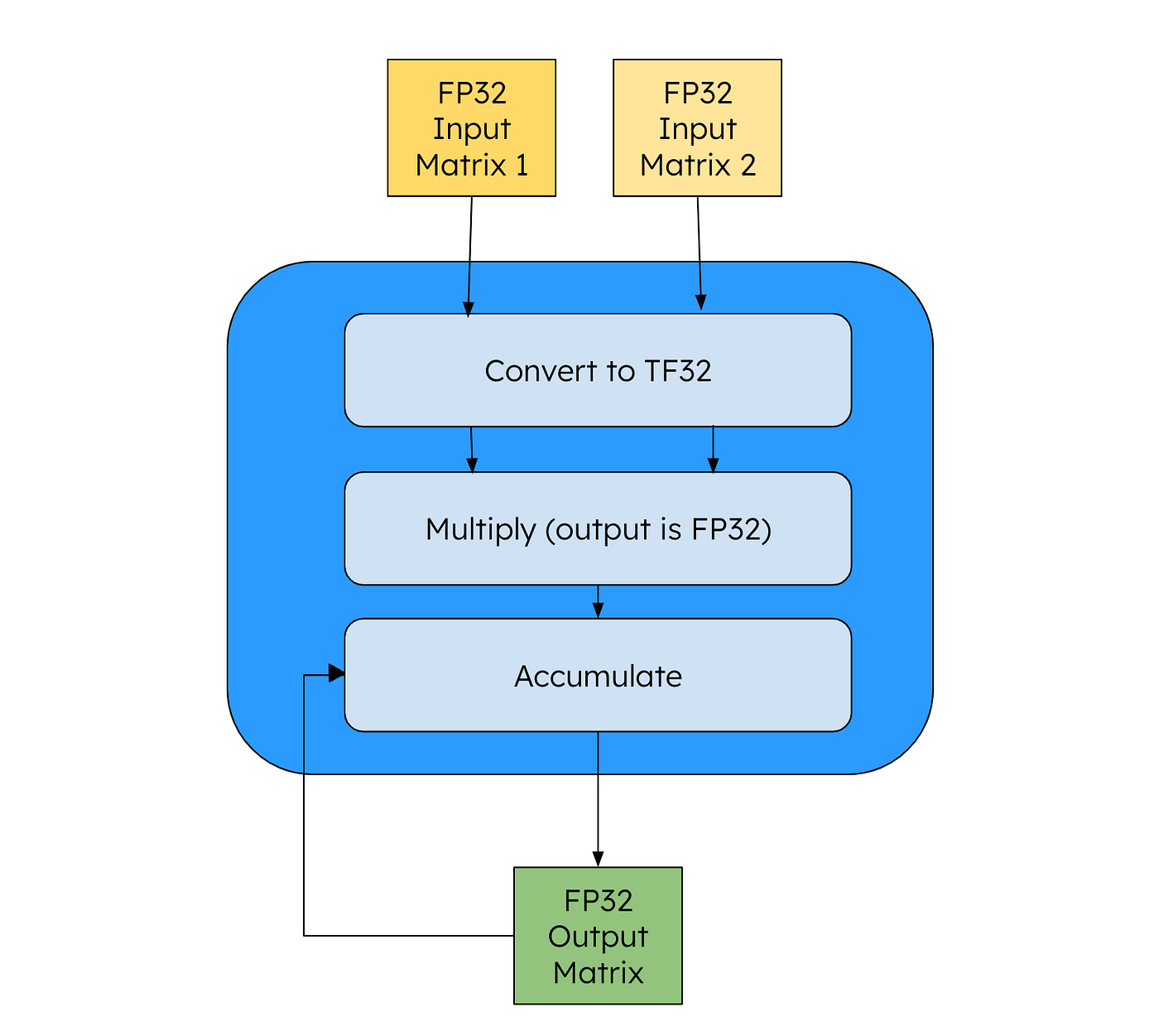
作者提供的图片 — TF32 数据流经 Tensor Core 后优化
从代码的角度来看,我们所有的变量(输入、输出)都是 FP32,但 NVIDIA GPU 会将中间矩阵转换为 TF32 以加快速度。根据 NVIDIA 的说法,与 FFMA 指令相比,这可实现 8 倍加速。要在 PyTorch 中启用 TF32,我们只需添加以下行(高 = TF32,最高 = FP32,中等 = BF16(稍后会详细介绍)):
for i in range(50):
t0 = time.time()
x, y = train_loader.next_batch()
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
with torch.autocast(device_type=device, dtype=torch.bfloat16): # bf16 change
logits, loss = model(x, y)
loss.backward()
optimizer.step()
torch.cuda.synchronize()
t1 = time.time()
dt = (t1-t0)*1000
print(f"loss {loss.item()}, step {i}, dt {dt:.2f}ms")
loss_arr.append(loss.item())TensorCore 是 NVIDIA 独有的,您只能在 A100 GPU 或更高版本的 GPU 上运行 TF32,因此一些开发人员使用浮点 16 (FP16) 作为训练方式。这种表示的问题在于 FP16 可以捕获的数据范围小于 FP32,导致无法表示训练所需的相同数据范围。虽然您可以使用梯度扩展来解决这个问题,但这需要更多的计算,因此您最终会陷入前进 1 步,后退 2 步的情况。

作者提供的图片 — IEEE 浮点 16 表示法 (FP16)
相反,Karpathy 在他的视频中使用的数据优化是大脑浮点 (BF16)。在这里,我们拥有与 FP32 相同的指数位数,因此我们可以表示相同的范围,但尾数位数较少。这意味着虽然我们的位数较少,但我们表示数字的精度较低。从经验上讲,这并没有导致性能大幅下降,因此这是我们愿意做出的权衡。要在 NVIDIA 芯片上使用它,您需要拥有 A100。

作者提供的图片 — Brain Floating Point 16 (BF16)
使用 PyTorch,我们不需要大幅更改代码即可使用新数据类型。文档建议我们仅在模型的前向传递和损失计算期间使用这些数据类型。由于我们的代码在一行中完成这两项操作,我们可以按如下方式修改代码:
# ...
model = GPT(GPTConfig(vocab_size=50304))
model.to(device)
model = torch.compile(model) # new line here
# ...就这样,我们的代码现在使用 BF16 运行。
在 A100 上运行,我们现在看到平均每步大约需要 330 毫秒!我们已经将运行时间缩短了约 70%,而这才刚刚开始!
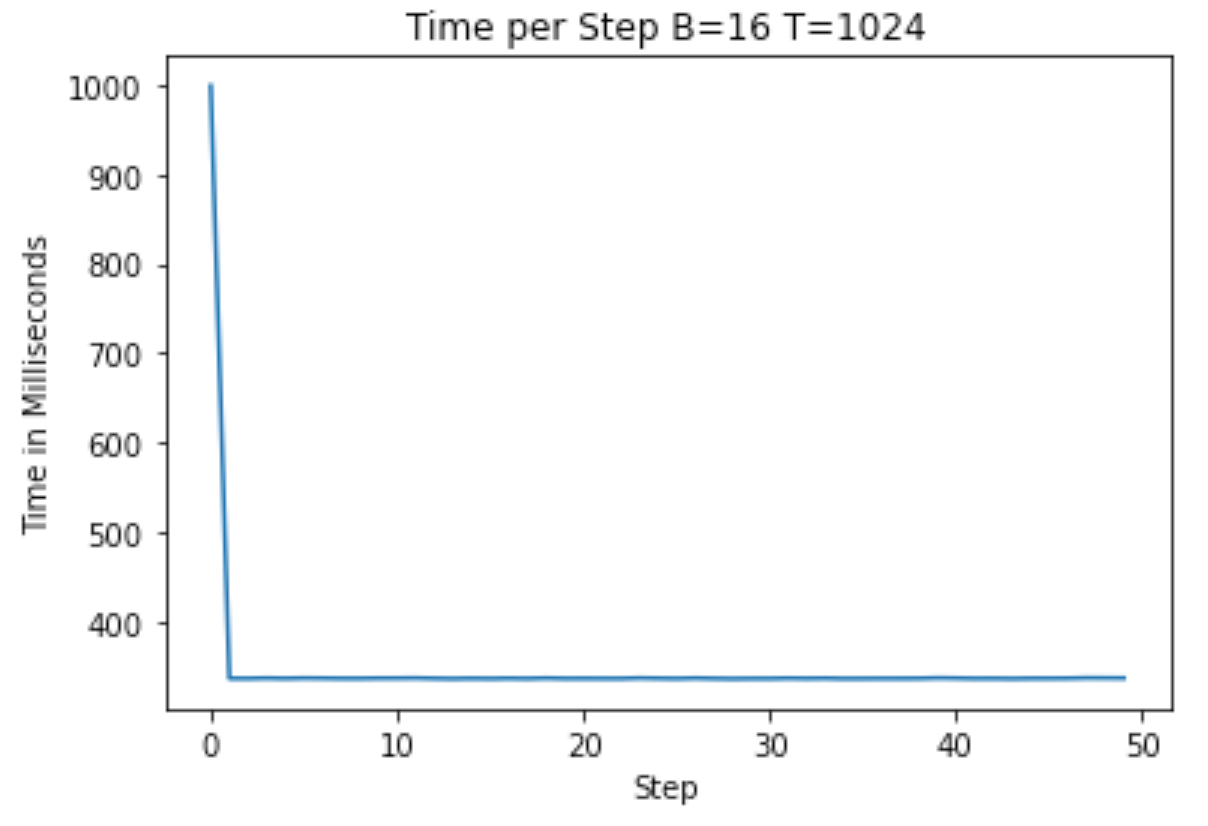
作者提供的图片 — 经过数据类型优化后的 A100 训练
Torch 编译
我们可以利用 PyTorch 编译功能进一步缩短训练时间。这将为我们带来相当大的性能提升,而无需调整我们的代码。
从高层次上讲,每个计算机程序都是以二进制执行的。由于大多数人觉得用二进制编码很困难,所以我们创造了更高级的语言,让我们能够以人们更容易思考的形式编码。当我们编译这些语言时,它们会被转换回我们实际运行的二进制。有时在这种转换中,我们可以找到更快的方式来进行相同的计算——比如重用某个变量,甚至干脆一开始就不做某个变量。
# ...
model = GPT(GPTConfig(vocab_size=50304))
model.to(device)
model = torch.compile(model) # new line here
# ...现在,我们来谈谈机器学习和 PyTorch。Python 是一种高级语言,但我们仍在用它进行计算密集型计算。运行时,torch compile我们会花更多时间来编译代码,但最终我们会发现我们的运行时间(这里的训练)会快得多,因为我们为找到这些优化做了额外的工作。
Karpathy 给出了以下示例,说明 PyTorch 如何改进计算。我们的 GELU 激活函数可以写成如下形式:
class TanhGELU(nn.Module):
def forward(self, input):
return 0.5 * input * (1.0 + torch.tanh(math.sqrt(2.0/math.pi) * (input + 0.044715 * torch.pow(input, 3.0))))对于上述函数中看到的每个计算,我们必须在 GPU 中调度一个内核。这意味着当我们开始对输入进行三次方运算时,我们会将输入从高带宽内存 (HBM) 拉入 GPU 内核并进行计算。然后,我们在开始下一个计算之前将其写回到 HBM,并重新开始整个过程。自然,这种排序导致我们花费大量时间等待内存传输发生。
PyTorch 编译让我们看到了这样的低效率,并且在启动新内核时更加小心,从而显著提高速度。这称为内核融合。
谈到这个话题,我想指出一个叫 Luminal 的优秀开源项目,它更进一步推进了这个想法。Luminal是一个独立的框架,您可以在其中编写训练/推理。通过使用此框架,您可以访问其编译器,该编译器会为您找到更多优化,因为它需要考虑的计算数量更少。如果您喜欢通过编译快速 GPU 代码来改进运行时间的想法,请看一下这个项目。
现在,当我们运行上述代码时,我们发现每一步大约需要 145 毫秒(比以前减少了 50%,比原来减少了约 86%)。为此,我们付出了第一次迭代的代价,大约需要 40,000 毫秒才能运行!由于大多数训练序列的步骤远多于 50,因此我们愿意做出这种权衡。
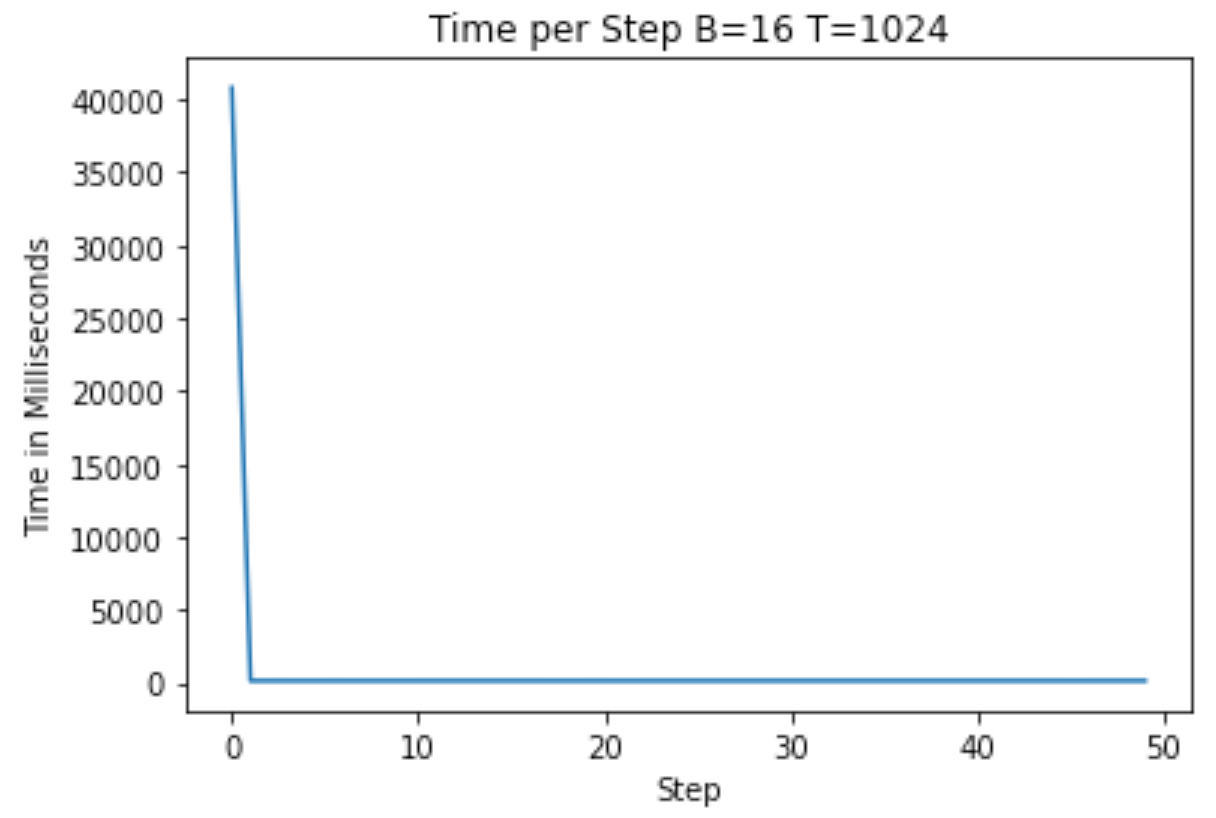
作者提供的图片 — Torch Compile 优化后运行的 A100 训练
闪光注意
我们做的另一个优化是使用 Flash Attention。代码更改本身对我们来说非常简单,但其背后的思考值得探索。
y = F.scaled_dot_product_attention(q, k, v, is_causal=True)类似于我们将TanhGELU类压缩为尽可能少的内核的方式,我们对注意力机制也采用了同样的思路。在他们的论文《FlashAttention:具有 IO 感知的快速且内存高效的精确注意力机制》中,作者展示了如何通过融合内核来实现 7.6 倍的速度提升。虽然从理论上讲,torch compile 应该能够找到这样的优化,但在实践中我们还没有看到它找到这样的优化。
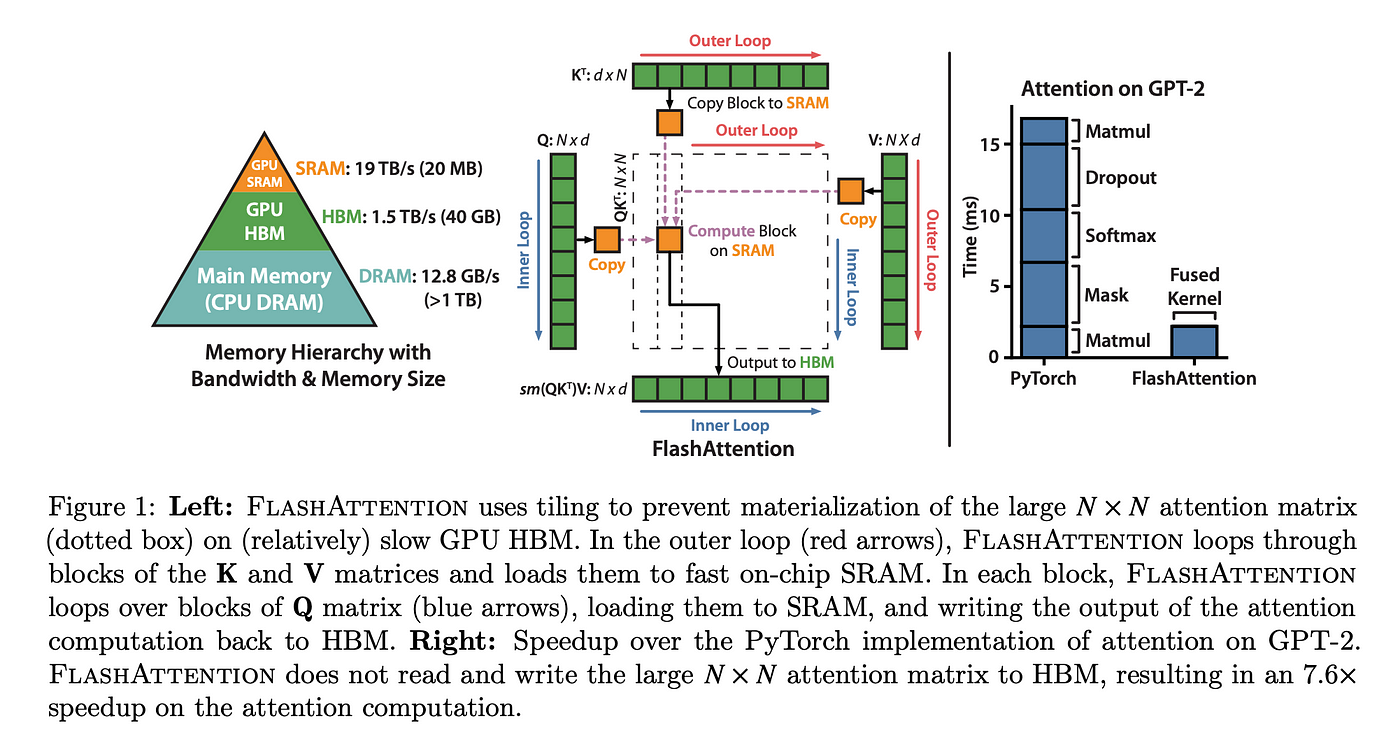
这篇论文值得深入研究,但简单概括一下,FlashAttention 被设计为具有 IO 感知能力,从而避免了不必要的(且耗时的)内存调用。通过减少这些调用,它们可以大大加快计算速度。
实现这一点之后,我们发现现在平均步长约为 104ms。
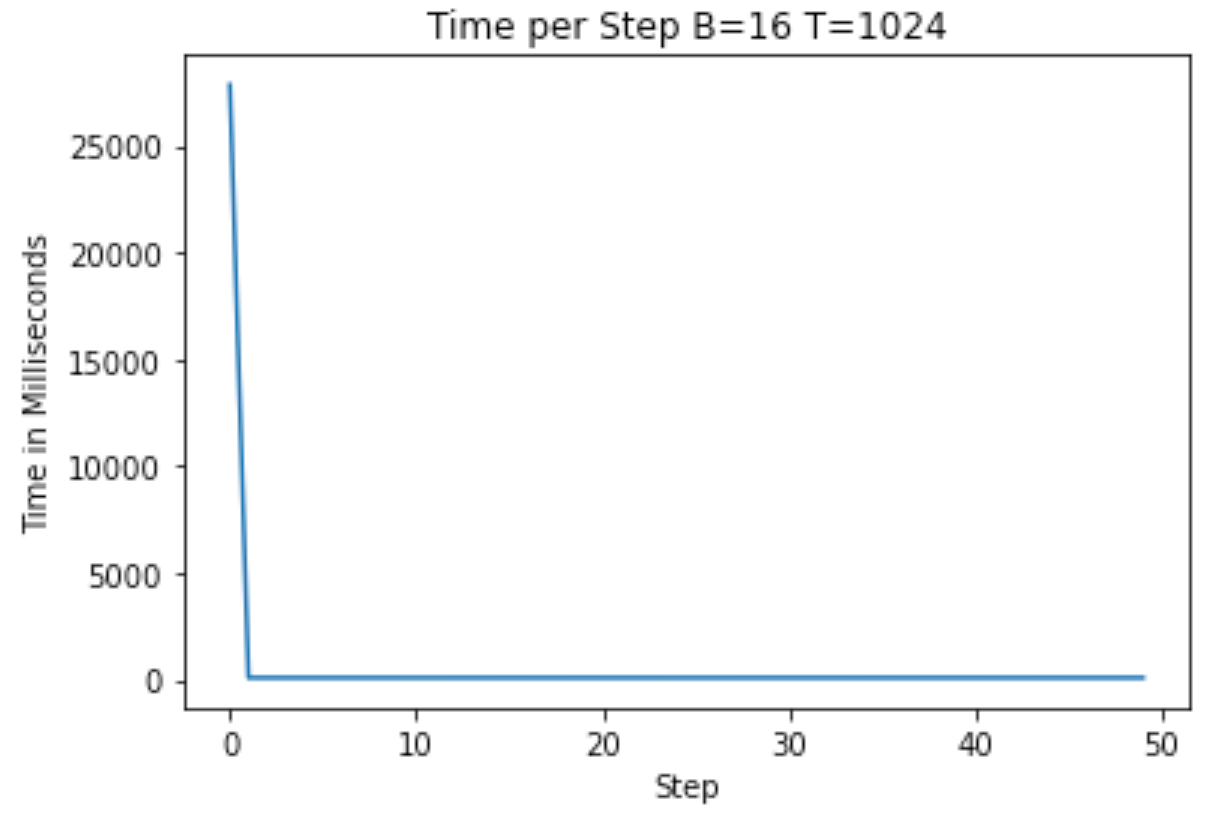
作者提供的图片 — Flash 注意力优化后的 A100 训练
词汇量变化
最后,我们可以检查所有硬编码的数字,并评估它们的“好”程度。当我们这样做时,我们发现词汇量不能被 2 的许多次方整除,因此我们的 GPU 内存加载会更耗时。我们通过将词汇量从 50,257 改为下一个“好”数字 50,304 来解决这个问题。这是一个好数字,因为它可以被 2、4、8、16、32、64 和 128 整除。
model = GPT(GPTConfig(vocab_size=50304))现在你可能还记得上一篇博文中提到,我们的词汇量不是一个任意值——它是由我们使用的标记器决定的。因此,问题来了,当我们任意为词汇量添加更多值时,会发生什么?在训练过程中,模型会注意到这些新词汇从未出现,因此它会开始将这些标记的概率推至 0——因此我们的性能是安全的。但这并不意味着没有权衡。通过加载从未使用过的词汇,我们是在浪费时间。然而,从经验上看,我们可以看到加载“好”数字足以弥补这一成本。
通过上次的优化,我们现在每步平均大约有 100 毫秒。
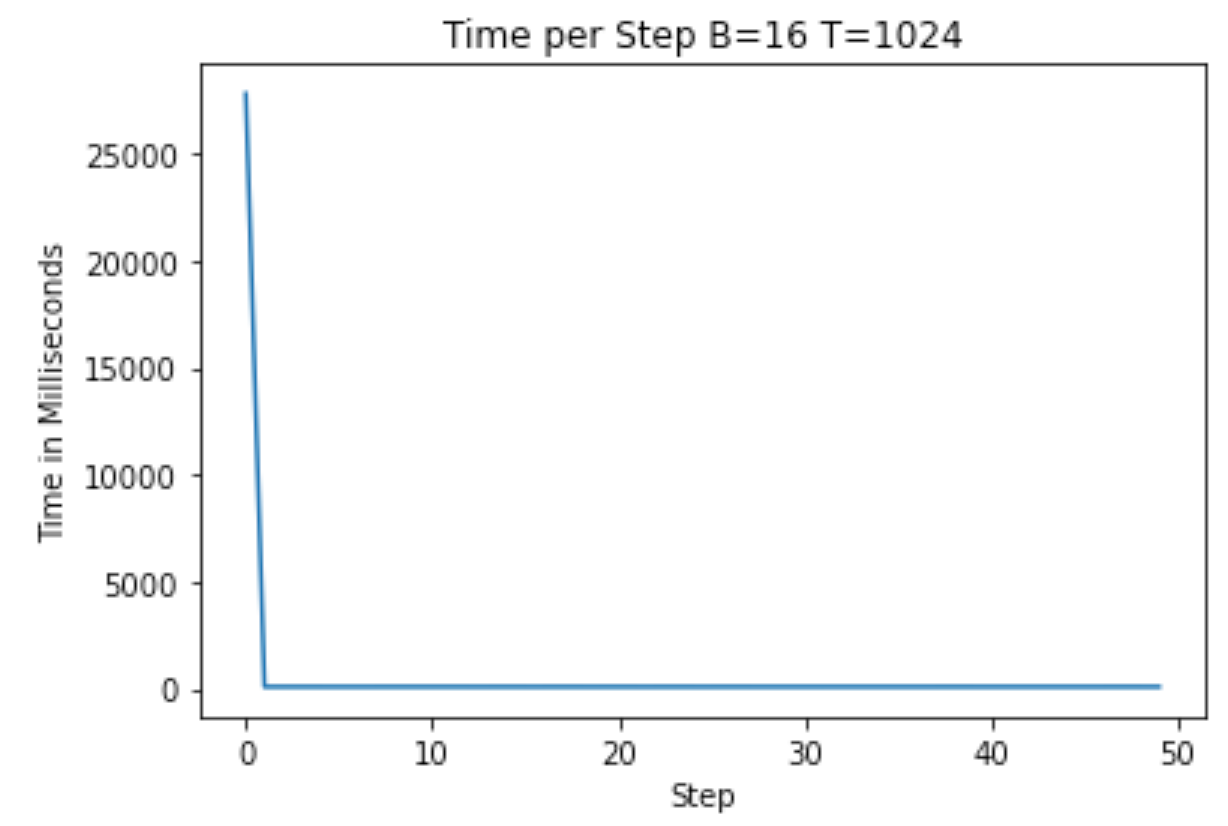
作者提供的图片 — 词汇量优化后的 A100 训练
通过最后的优化,我们发现我们的训练比一开始提高了约 10 倍!
T4 GPU 上有哪些优化?
如果您一直在关注但只能使用消费级 T4 GPU,您可能会想知道可以使用哪些优化。总结一下,我们不能使用 BF16 表示,但我们可以使用词汇表大小更改、Flash 注意力和 Torch 编译。(详细内容可联系博主获取)要查看此代码的实际效果,请查看我的 Google Colab 笔记本,它仅针对 T4 使用进行了优化
我们从下图中可以看出,虽然 torch 编译在第一轮确实花费了大量时间,但接下来的几轮并没有比未优化的版本好多少(T4 下降了大约 8%,而 A100 下降了 90%)。
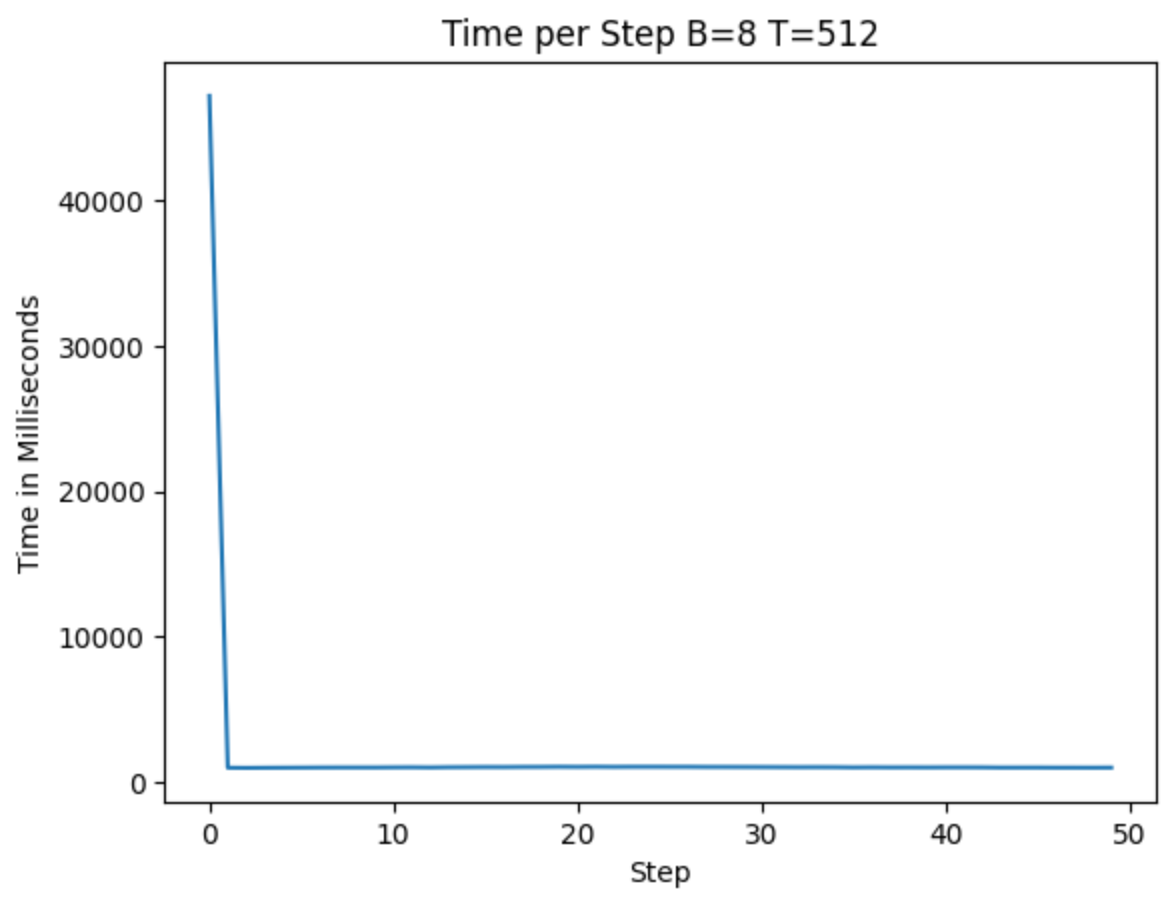
作者提供的图片 — 在 T4 GPU 上优化运行
尽管如此,OpenAI 在训练 GPT-2 时使用的硬件远比 T4 先进。如今我们可以在 T4 上运行这种工作负载,这表明硬件要求正在降低,这有助于创造一个硬件不再成为机器学习工作障碍的未来。
结束语
通过优化代码,我们看到了显著的速度提升,同时也了解了训练中最大的瓶颈所在。首先,数据类型对于速度至关重要,因为这种变化本身就对速度提升做出了重大贡献。其次,我们看到硬件优化可以在加快计算速度方面发挥重要作用——因此 GPU 硬件是无价之宝。最后,编译器优化在这里也发挥着重要作用。
要查看我在 A100 中运行的代码,请查看此处的要点。如果您对如何进一步优化硬件有任何建议,我很乐意在评论中看到它们!
感谢关注雲闪世界。(亚马逊aws和谷歌GCP服务协助解决云计算及产业相关解决方案)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









