






构建代理时,开发者不仅需要决定使用的模型、用例和架构,还必须选择合适的框架。

是选择经验丰富的 LangGraph,还是尝试新兴的 LlamaIndex 工作流?又或者,走传统路线,完全手动编写代码?为了简化这一决策过程,我在过去几周里使用各大主流框架构建了相同的代理程序,并深入分析了它们的优缺点。
第一个选项是完全跳过框架,完全自己构建代理。在开始这个项目时,这就是我开始采用的方法。
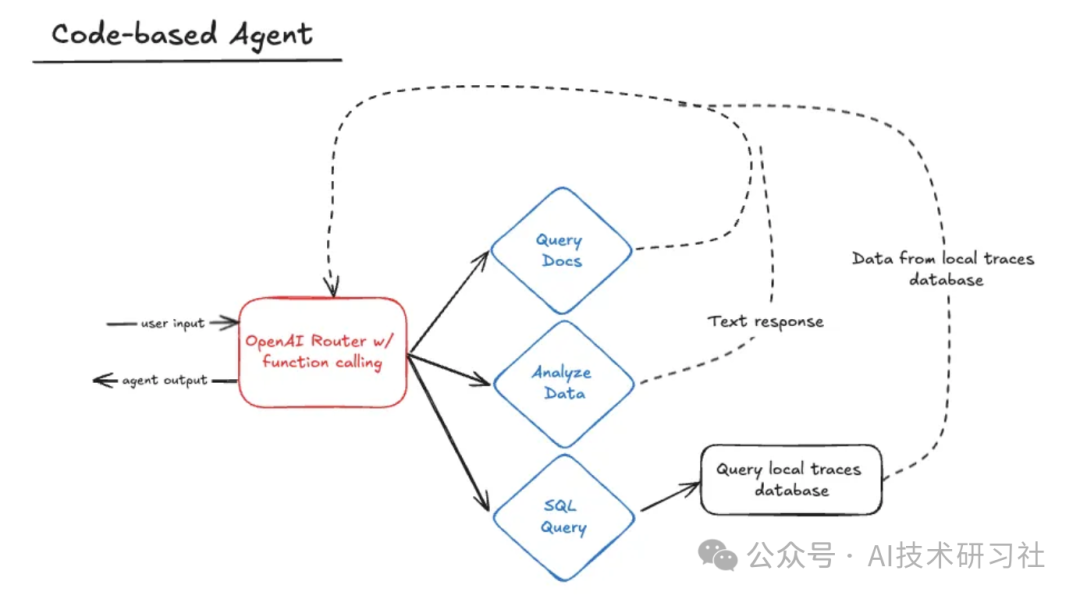
下面基于代码的代理由一个 OpenAI 驱动的路由器组成,该路由器使用函数调用来选择要使用的正确技能。该技能完成后,它会返回路由器以调用其他技能或响应用户。
def router(messages):` `if not any(` `isinstance(message, dict) and message.get("role") == "system" for message in messages` `):` `system_prompt = {"role": "system", "content": SYSTEM_PROMPT}` `messages.append(system_prompt)`` ` `response = client.chat.completions.create(` `model="gpt-4o",` `messages=messages,` `tools=skill_map.get_combined_function_description_for_openai(),` `)`` ` `messages.append(response.choices[0].message)` `tool_calls = response.choices[0].message.tool_calls` `if tool_calls:` `handle_tool_calls(tool_calls, messages)` `return router(messages)` `else:` `return response.choices[0].message.content

技能本身在它们自己的类(例如 GenerateSQLQuery)中定义,这些类共同保存在 SkillMap 中。路由器本身只与 SkillMap 交互,它用于加载技能名称、描述和可调用函数。这种方法意味着,向代理添加新技能就像将该技能编写为自己的类一样简单,然后将其添加到 SkillMap 中的技能列表中即可。这里的想法是让添加新技能变得容易,而不会干扰 router 代码。
class SkillMap:` `def __init__(self):` `skills = [AnalyzeData(), GenerateSQLQuery()]`` ` `self.skill_map = {}` `for skill in skills:` `self.skill_map[skill.get_function_name()] = (` `skill.get_function_dict(),` `skill.get_function_callable(),` `)`` ` `def get_function_callable_by_name(self, skill_name) -> Callable:` `return self.skill_map[skill_name][1]`` ` `def get_combined_function_description_for_openai(self):` `combined_dict = []` `for _, (function_dict, _) in self.skill_map.items():` `combined_dict.append(function_dict)` `return combined_dict`` ` `def get_function_list(self):` `return list(self.skill_map.keys())`` ` `def get_list_of_function_callables(self):` `return [skill[1] for skill in self.skill_map.values()]`` ` `def get_function_description_by_name(self, skill_name):` `return str(self.skill_map[skill_name][0]["function"])
总的来说,这种方法的实现相当简单,但也带来了一些挑战。基于代码的方法提供了一个很好的基线和起点,提供了一种很好的方法来了解代理的工作原理,而无需依赖来自主流框架的固定代理教程。尽管说服 LLM 运行可能具有挑战性,但代码结构本身足够简单,并且可能对某些用例有意义。
LangGraph 是历史最悠久的代理框架之一,于 2024 年 1 月首次发布。该框架旨在通过采用 Pregel 图形结构来解决现有管道和链的非循环性质。LangGraph 通过添加节点、边和条件边的概念来遍历图形,可以更轻松地在代理中定义循环。LangGraph 构建在 LangChain 之上,并使用该框架中的对象和类型。
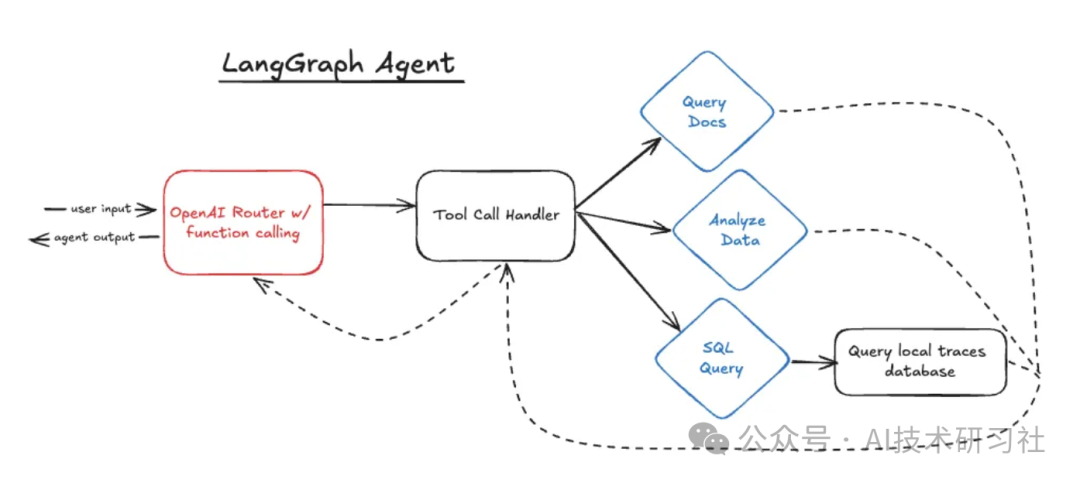
LangGraph 代理看起来与纸上基于代码的代理相似,但其背后的代码却截然不同。LangGraph 在技术上仍然使用“路由器”,因为它使用函数调用 OpenAI,并使用响应继续新的步骤。但是,程序在技能之间移动的方式完全不同。
tools = [generate_and_run_sql_query, data_analyzer]``model = ChatOpenAI(model="gpt-4o", temperature=0).bind_tools(tools)`` ``def create_agent_graph():` `workflow = StateGraph(MessagesState)`` ` `tool_node = ToolNode(tools)` `workflow.add_node("agent", call_model)` `workflow.add_node("tools", tool_node)`` ` `workflow.add_edge(START, "agent")` `workflow.add_conditional_edges(` `"agent",` `should_continue,` `)` `workflow.add_edge("tools", "agent")`` ` `checkpointer = MemorySaver()` `app = workflow.compile(checkpointer=checkpointer)` `return app
此处定义的图形有一个用于初始 OpenAI 调用的节点,上面称为“agent”,还有一个用于工具处理步骤的节点,称为“tools”。LangGraph 有一个名为 ToolNode 的内置对象,它获取可调用工具的列表,并根据 ChatMessage 响应触发它们,然后再次返回到 “agent” 节点。
def should_continue(state: MessagesState):` `messages = state["messages"]` `last_message = messages[-1]` `if last_message.tool_calls:` `return "tools"` `return END`` ``def call_model(state: MessagesState):` `messages = state["messages"]` `response = model.invoke(messages)` `return {"messages": [response]}
LangGraph 的主要好处之一是它易于使用。图形结构代码干净且易于访问。特别是如果您具有复杂的节点逻辑,则拥有图形的单一视图可以更轻松地了解代理是如何连接在一起的。LangGraph 还使转换在 LangChain 中构建的现有应用程序变得简单明了。
Workflows 是代理框架领域的新进入者,于今年夏天早些时候首次亮相。与 LangGraph 一样,它旨在使循环代理更易于构建。工作流还特别关注异步运行。
Workflows 的一些元素似乎是对 LangGraph 的直接响应,特别是它使用事件而不是边缘和条件边缘。工作流使用步骤(类似于 LangGraph 中的节点)来容纳逻辑,并使用发出和接收的事件在步骤之间移动。
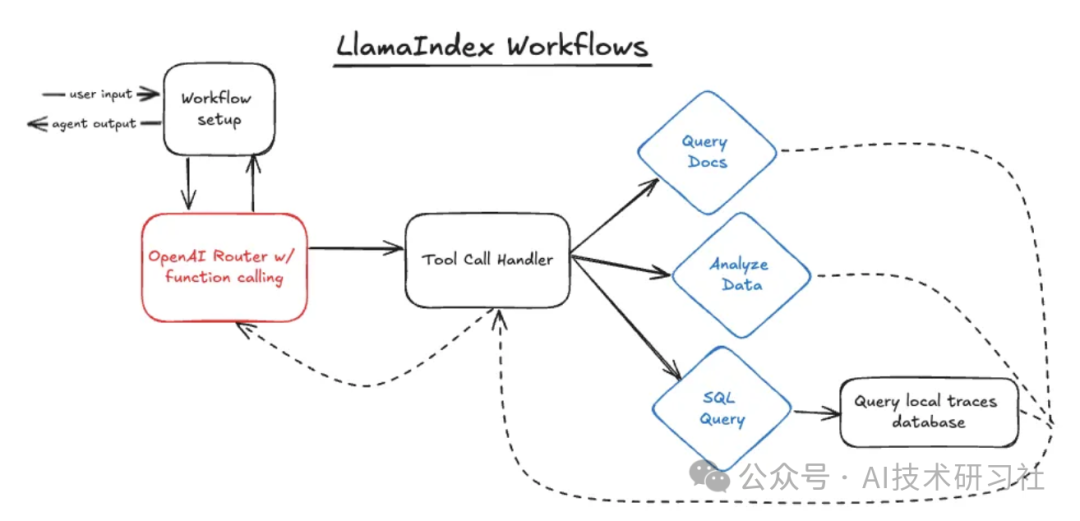
下面的代码定义了 Workflow 结构。与 LangGraph 类似,这是我准备状态并将技能附加到 LLM。
class AgentFlow(Workflow):` `def __init__(self, llm, timeout=300):` `super().__init__(timeout=timeout)` `self.llm = llm` `self.memory = ChatMemoryBuffer(token_limit=1000).from_defaults(llm=llm)` `self.tools = []` `for func in skill_map.get_function_list():` `self.tools.append(` `FunctionTool(` `skill_map.get_function_callable_by_name(func),` `metadata=ToolMetadata(` `name=func, description=skill_map.get_function_description_by_name(func)` `),` `)` `)`` ` `@step` `async def prepare_agent(self, ev: StartEvent) -> RouterInputEvent:` `user_input = ev.input` `user_msg = ChatMessage(role="user", content=user_input)` `self.memory.put(user_msg)`` ` `chat_history = self.memory.get()` `return RouterInputEvent(input=chat_history)
设置 Workflow 后,我定义了路由代码:
@step``async def router(self, ev: RouterInputEvent) -> ToolCallEvent | StopEvent:` `messages = ev.input`` ` `if not any(` `isinstance(message, dict) and message.get("role") == "system" for message in messages` `):` `system_prompt = ChatMessage(role="system", content=SYSTEM_PROMPT)` `messages.insert(0, system_prompt)`` ` `with using_prompt_template(template=SYSTEM_PROMPT, version="v0.1"):` `response = await self.llm.achat_with_tools(` `model="gpt-4o",` `messages=messages,` `tools=self.tools,` `)`` ` `self.memory.put(response.message)`` ` `tool_calls = self.llm.get_tool_calls_from_response(response, error_on_no_tool_call=False)` `if tool_calls:` `return ToolCallEvent(tool_calls=tool_calls)` `else:` `return StopEvent(result=response.message.content)
@step``async def tool_call_handler(self, ev: ToolCallEvent) -> RouterInputEvent:` `tool_calls = ev.tool_calls`` ` `for tool_call in tool_calls:` `function_name = tool_call.tool_name` `arguments = tool_call.tool_kwargs` `if "input" in arguments:` `arguments["prompt"] = arguments.pop("input")`` ` `try:` `function_callable = skill_map.get_function_callable_by_name(function_name)` `except KeyError:` `function_result = "Error: Unknown function call"`` ` `function_result = function_callable(arguments)` `message = ChatMessage(` `role="tool",` `content=function_result,` `additional_kwargs={"tool_call_id": tool_call.tool_id},``)`` ` `self.memory.put(message)`` ` `return RouterInputEvent(input=self.memory.get())
选择代理框架只是影响生成式 AI 系统生产结果的众多选择之一。与往常一样,拥有强大的护栏和 LLM 跟踪是值得的,并且在新的代理框架、研究和模型颠覆现有技术时保持敏捷。
参考资料:
1.https://towardsdatascience.com/choosing-between-llm-agent-frameworks-69019493b259
零基础如何学习大模型 AI
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
⑤AI+零售:智能推荐系统和库存管理优化了用户体验和运营成本。AI可以分析用户行为,提供个性化商品推荐,同时优化库存,减少浪费。
⑥AI+交通:自动驾驶和智能交通管理提升了交通安全和效率。AI技术可以实现车辆自动驾驶,并优化交通信号控制,减少拥堵。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。

三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


四、LLM面试题

如果二维码失效,可以点击下方链接,一样的哦
【CSDN大礼包】最新AI大模型资源包,这里全都有!无偿分享!!!
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









