






1 引言
大模型无疑是当前最热门的话题之一。无论是响应公司高层的战略要求,还是出于对前沿技术的持续探索,我们在项目中都需要主动挖掘大模型的应用机会。既然大模型已成趋势,那就从现在开始,积极拥抱变化吧!
这篇文章主要作为入门分享,内容包括:大模型的概念和主要类别、技术发展历程,以及业界的一些典型应用案例。希望能为同样想要入门大模型的朋友们提供一些参考。
正文如下。
2 大模型基本概念
2.1 大模型定义
既然是入门,第一步当然要先明确什么是“大模型”。
DeepSeek 对“大模型”的定义如下:大模型(Large Models)是指拥有大量参数的机器学习模型,通常应用于处理复杂任务,如自然语言处理(NLP)、计算机视觉(CV)和语音识别等。这类模型通过在大规模数据集上的训练,能够捕捉数据中的复杂模式和关系,因此在各类任务中表现优异。
本质上,大模型仍然是机器学习模型,只是它们在训练完成后具备了更强的任务处理能力。为了实现这样的能力,大模型相比传统机器学习模型,需要更丰富的训练数据、更庞大的参数量和更强大的计算资源,相应的训练成本也更高。
以 DeepSeek V3 为例:
- 训练 Token 数(可理解为训练数据量)达到 14.8 万亿(14.8T),
- 模型参数量为 6710 亿(671B),
- 总训练时长为 278.8 万(2.788M)GPU 小时,
- 总训练成本高达 557.6 万美元。
相比之下,我们日常使用的机器学习模型,训练数据量通常只有亿级,参数量在万级,总训练时长也多为分钟级。大模型在规模和资源消耗方面,远远超出了传统机器学习模型的范畴。
2.2 大模型分类
市面上的大模型实在太多,令人眼花缭乱,想要全面了解几乎不可能。幸运的是,我偶然发现了一篇文章,已经对截至2025年2月的大模型进行了系统梳理,并且还在持续更新。为了便于大家理解,我在此基础上绘制了如下思维导图,其中国产大模型用“红框+!”做了特别标注。
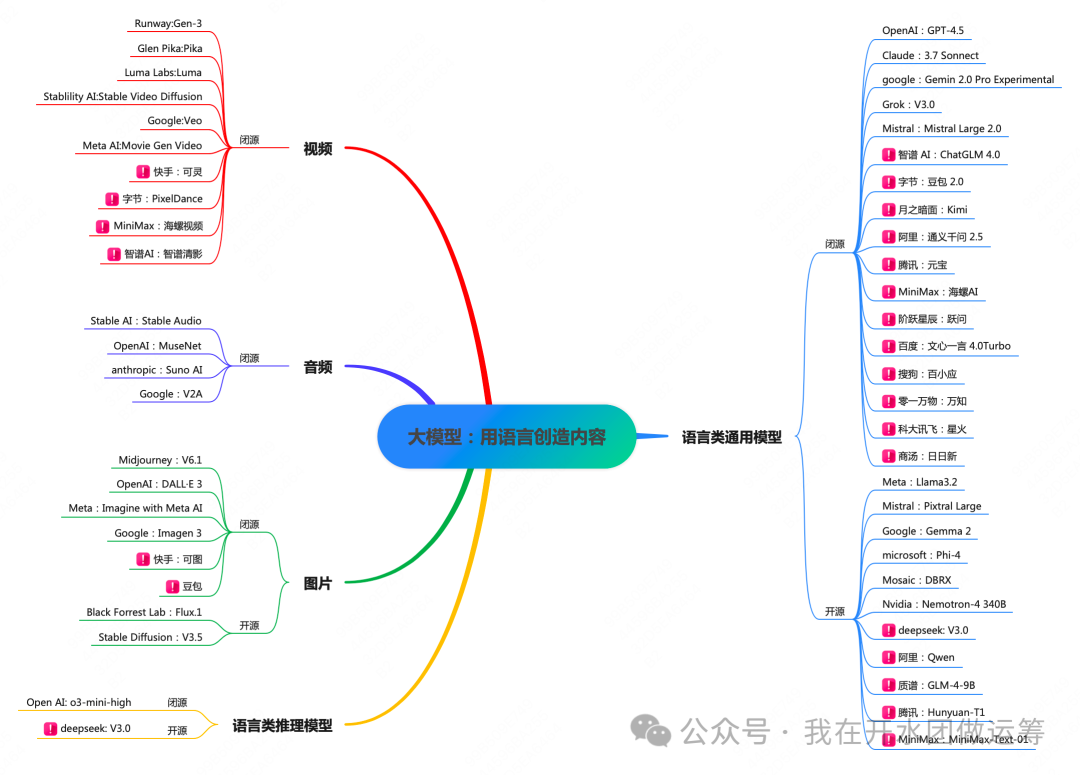
从导图可以看出,大模型是通过语言创造内容。按照内容类型划分,可以将大模型分为四类:语言、图片、音频和视频。其中,大语言模型又可以细分为通用模型和推理模型。
从应用角度来看,大语言模型(Large Language Model, LLM)已经广泛融入我们的日常生活和工作。而其他类型的大模型,我个人此前并未实际体验过,于是尝试用“王者荣耀场景,安琪拉大战小卤蛋”作为输入进行测试,结果却一塌糊涂,可见这些方向还有很大的提升空间。
3 LLM技术发展史
在上一章中,我们已经对大模型的概念和分类有了初步了解。作为算法方向的从业者,接下来是时候系统梳理一下大模型背后的技术发展脉络了。鉴于目前LLM是发展最为成熟的方向,下面将重点围绕 LLM 的技术演进进行介绍。
从整体方案来看,LLM的发展大致可以分为三个阶段:
- 规则驱动阶段:以 ELIZA 为代表,通过人工设定规则和模板来实现简单的语言理解与生成。
- 统计学习阶段:以 n-gram 算法为代表,基于统计方法建模词语之间的概率关系,实现了更自然的文本生成。
- 深度学习阶段:以 GPT 为代表,采用神经网络和大规模数据进行端到端训练,极大提升了模型的理解和生成能力。
这三个阶段见证了大语言模型从手工规则到数据驱动、再到深度学习智能化的演进过程。
3.1 规则驱动
ELIZA 是一个早期的聊天机器人,由 MIT 人工智能实验室开发,历时三年(1964-1966),主要贡献者是 Joseph Weizenbaum。ELIZA 能够模拟心理咨询师与用户对话,虽然技术简单,但在当时引起了广泛关注。下面是一个经典对话示例,可以看到 ELIZA 的回复看似合理,甚至带有一定的安慰性:
人:Men are all alike.
ELIZA:IN WHAT WAY
人:They’re always bugging us about something or other.
ELIZA:CAN YOU THINK OF A SPECIFIC EXAMPLE
人:Well my boyfriend made me come here.
ELIZA:YOUR BOYFRIEND MADE YOU COME HERE
人:He says I’m depressed much of the time.
ELIZA:I AM SORRY TO HEAR YOU ARE DEPRESSED
ELIZA 背后的核心原理其实是基于规则的匹配和转换。简单来说,就是通过一系列预设的模式,将用户输入映射为相应的回复。例如:
(0 YOU 0 ME) # [pattern]
(1 2 3 4) # [index]
->
(WHAT MAKES YOU THINK I 3 YOU) # [transform]
意思是,如果用户输入符合“A YOU B ME”这样的模式,ELIZA 就会生成“WHAT MAKES YOU THINK I B YOU”这样的回复。比如:
用户输入:You hate me
ELIZA 回复:WHAT MAKES YOU THINK I HATE YOU
基于规则的方法整体上显得比较刻板,开发和维护都非常耗时,且难以应对语言的多样性和复杂语境,覆盖能力有限。这也是后续统计学习方法和深度学习方法不断发展的原因之一。
3.2 统计学习
在 n-gram 算法中,首先会将语言内容建模为由一系列词元(Token)组成的序列数据。例如,原句:
这课好难
可以分解为词元序列:
{这, 课, 好, 难}
n-gram 算法的核心思想是:通过统计语料库中词元序列的出现频率,估计在给定前 n-1 个词元的情况下,下一个词元出现的概率,并选择概率最大的词元作为预测结果。
举个例子,假设前 n-1 个词元为:
{我, 考, 了, 99, 分, 这, 课, 好}
通过统计语料库发现,下一个词元为 {难} 的概率为 0.1,为 {简单} 的概率为 0.9,那么 n-gram 算法最终会返回概率更高的 {简单},即:
①这课好难
②这课好简单
最终会选择“这课好简单”。
接下来,再举一个例子,说明如何通过语料库计算词元序列出现的概率。假设语料库如下:
| 序号 | 语料库 |
|---|---|
| 1 | 脖子长是长颈鹿最醒目的特征之一。 |
| 2 | 脖子长使得长颈鹿看起来非常优雅,并为其在获取食物带来便利。 |
| 3 | 有了长脖子的加持,长颈鹿可以观察到隐蔽的角落里发生的事情。 |
| 4 | 长颈鹿脖子和人类脖子一样,只有七节颈椎,也容易患颈椎病。 |
| 5 | 如同长颈鹿脖子由短变长的进化历程一样,语言模型在不断进化。 |
如果我们要计算“{长颈鹿, 脖子}”这个词元序列出现的概率,计算公式如下:
长颈鹿脖子长颈鹿脖子长颈鹿
其中, 表示该词元或词元序列在语料库中出现的次数。
如果我们要计算“{脖子, 长}”这个词元序列出现的概率,计算公式如下:
脖子长脖子长脖子
如果我们要计算“{长颈鹿, 脖子, 长}”这个词元序列出现的概率,并设定n=1,计算公式如下:
长颈鹿脖子长长颈鹿脖子脖子长
总体来看,当文本较短时,n-gram 算法的计算效率较高,能够较好地建模词元之间的关系。但对于较长的句子或篇章,n-gram 算法很难捕捉长距离依赖和整体语义,表现会受到一定限制。
3.3 深度学习
GPT 的问世让大模型真正走进大众视野,但在此之前,底层技术经历了多个里程碑式的发展,包括 RNN(递归神经网络)、LSTM(长短时记忆网络) 和 Transformer。GPT 爆火之后,OpenAI 又推出了具备更强推理能力的 OpenAI-o1 模型。
3.3.1 RNN
下图左侧展示的是经典的 RNN 结构。RNN 以序列方式输入文本,每一步的输出(如 )不仅依赖当前输入(),还会受到前面所有输入的影响。右侧是 RNN 的一种变体,虽然结构略有不同,但本质上依然是顺序输入、依赖历史信息。
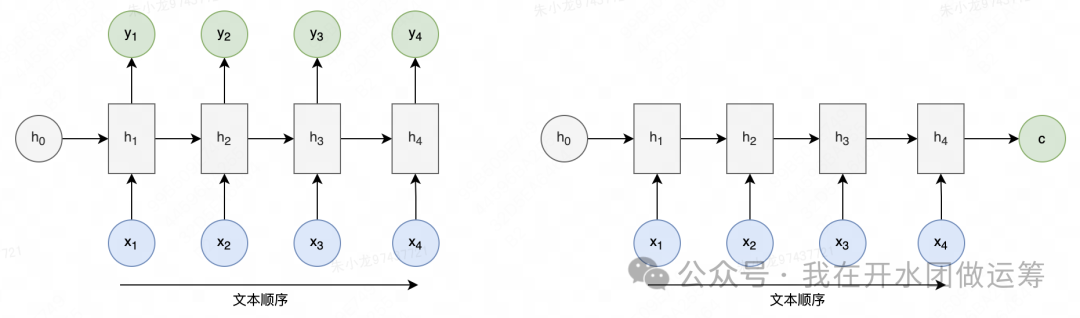
与 n-gram 相比,RNN 理论上能够捕捉更长距离的依赖关系,因此具备更广阔的应用前景。但在实际训练中,RNN 仍然难以处理长距离依赖。这是因为 RNN 在参数优化时高度依赖梯度传递:如果梯度持续变小,最终会消失(梯度消失);如果持续变大,则会爆炸(梯度爆炸),导致模型难以收敛。
3.3.2 LSTM
为了解决 RNN 的梯度消失和爆炸问题,LSTM应运而生。相较于 RNN,LSTM 对每个隐藏状态 进行了扩展,引入了四个核心模块:
- 遗忘门(forget gate):决定需要丢弃哪些信息,
- 输入门(input gate):决定存储哪些新信息,
- 输出门(output gate):决定输出哪些信息,
- 记忆单元(memory cell):用于长期记忆的存储。
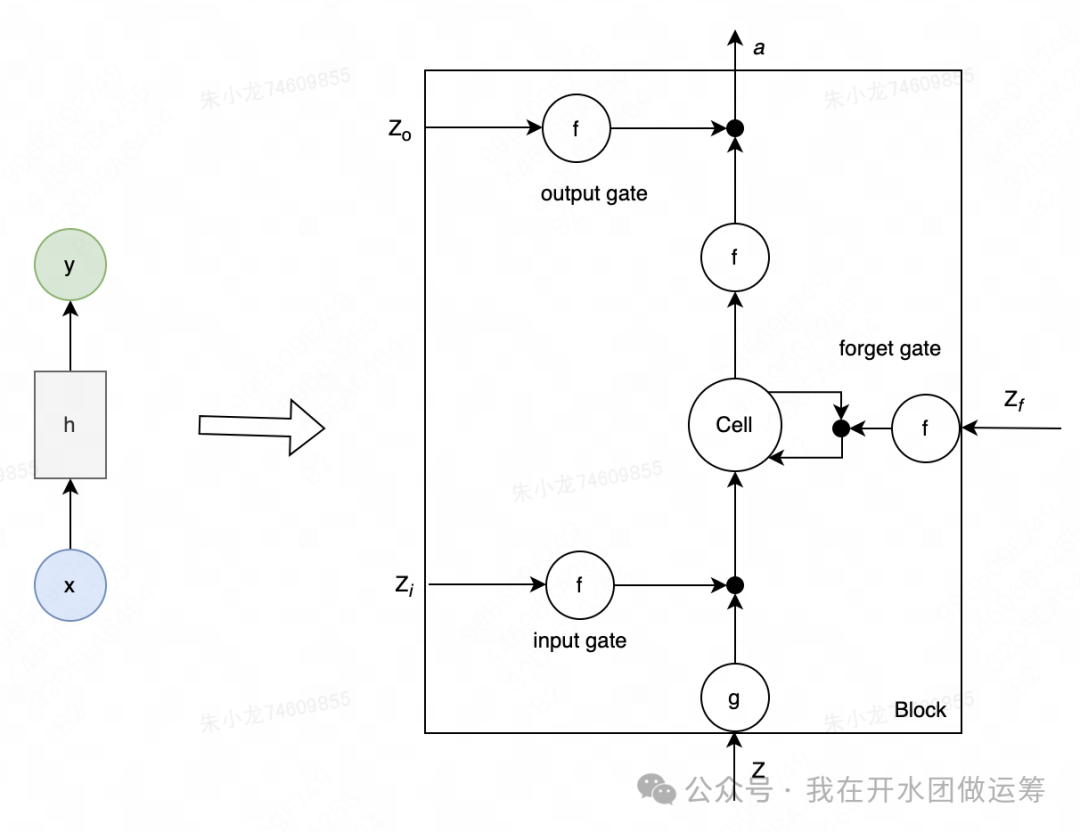
为了便于理解 RNN 和 LSTM 的差异,可以做一个类比:RNN 像一个拾荒者,什么信息都不加区分地收集,而 LSTM 更像一个贵族,只保留对自己有价值的信息,主动筛选和遗忘。
3.3.3 Transformer
如果说 LSTM 解决了 RNN 的梯度问题,那么 Transformer 则解决了RNN计算效率低的问题。
RNN 的每一步计算都依赖前面的结果,只能串行进行,效率较低。而 Transformer 引入了自注意力机制,使得序列中所有位置的输出都可以并行计算,极大提升了训练和推理效率。
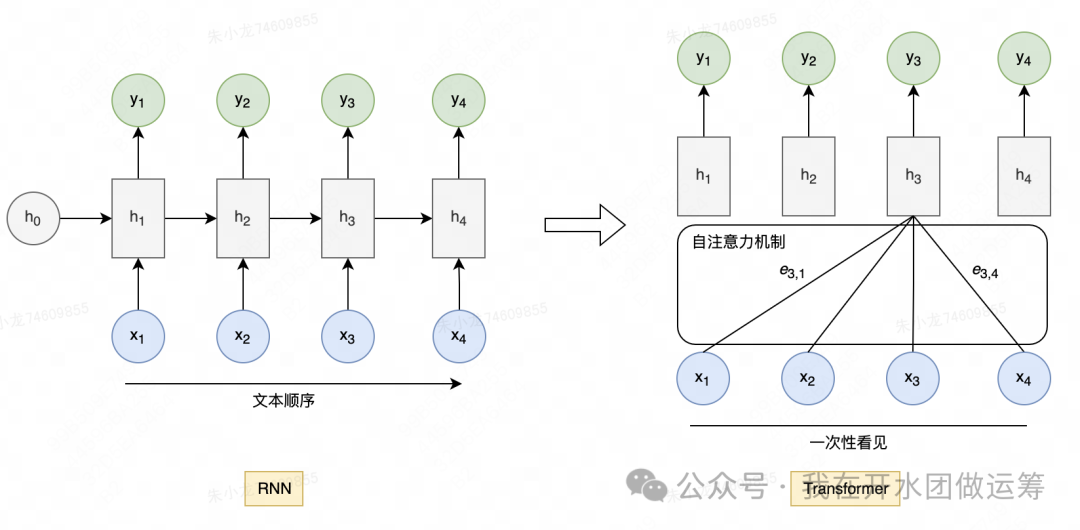
用公式表达,RNN 的计算方式为:
而 Transformer 的输出为:
3.3.4 GPT
从能力上看,Transformer 已经是非常强大的学习框架,可以说是“万能的锤子”,几乎可以适应各种任务。
GPT(Generative Pre-trained Transformer)就是基于 Transformer 架构,主要预测序列中的下一个词。例如,对于“我喜欢*”,GPT 需要预测 * 处应该填什么。
作为对比,BERT 也是基于 Transformer,但它预测的是句子中被随机掩盖(mask)的词元。例如,“我*你”,BERT 需要预测 * 处的词。
事实证明,GPT 的眼光非常独到。即使如此,从 2018 年 6 月第一版发布,到 2022 年 11 月 ChatGPT 引爆全球,也历经了 4 年、4个版本的持续迭代和完善。

3.3.5 OpenAI-o1
ChatGPT 爆火后,母公司OpenAI 于 2024 年 12 月发布了 OpenAI-o1 模型,其核心创新是引入了“思维链”(Chain of Thought, CoT)机制,显著增强了模型的推理能力。
如果用《思考,快与慢》中的观点来类比 GPT 系列与 OpenAI-o1 的差异:GPT 更像“系统1”,依赖经验和直觉,反应迅速但有时不够准确;而 OpenAI-o1 更像“系统2”,通过有条理的分析和推理,虽然慢一些,但更可靠,更擅长解决复杂问题。
一个有力的例证是:针对2024 年美国数学奥林匹克(AIME)中的15 道高难度数学题,GPT-4o(2024年5月发布)仅答对 2 题,而 OpenAI-o1 答对了 13 题,成绩已可进入美国前 500 名学生之列,展现出卓越的推理能力。
4 大模型业界应用
最后,我们再来看一下大模型在业界的应用情况。
关于这方面的市场调研报告非常多,偶然间发现了这张图,总结得相对全面,值得参考:
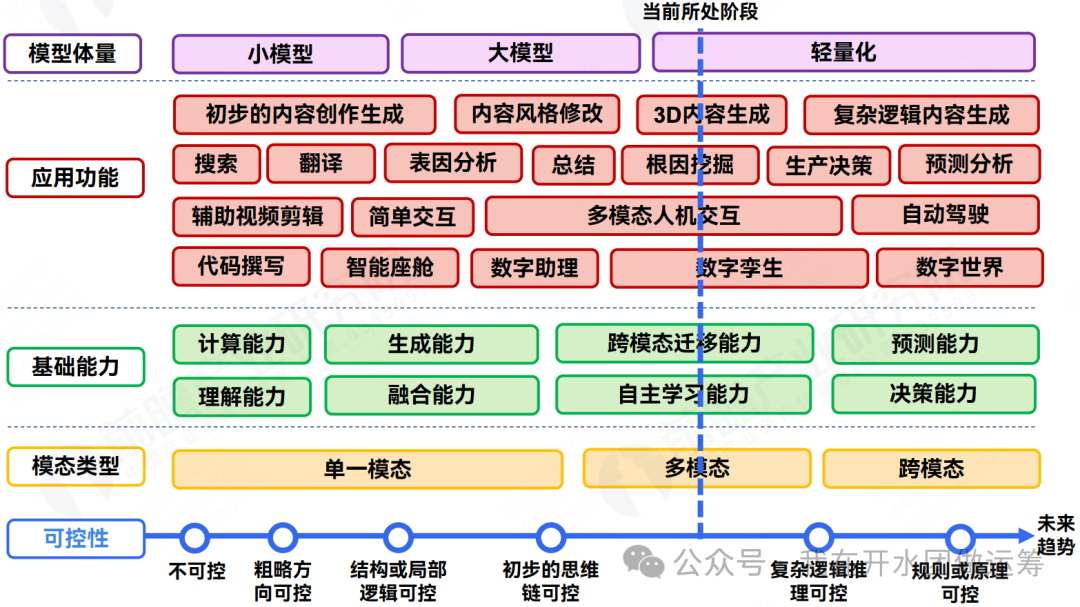
在《中国信通院华东分院》公众号(主页回复“2024案例集”)发布的《2024大模型典型示范应用案例集》中,汇总了99个大模型在业界的具体应用案例。其中,45个属于“行业赋能”,46个属于“智能应用”,涵盖了新型工业化、能源、医疗和政务等多个重要领域。总体来看,这些案例中的应用功能基本都可以在上面那张图上找到对应内容。下表列举了其中的3个具体案例,供参考:
| 案例名称 | 公司 | 应用场景 | 业务效益 | 应用功能归类 |
|---|---|---|---|---|
| “珠玑”大模型在搜推场景的赋能应用 | 小红书 | 对新笔记进行内容总结、特征提取,帮助推荐系统对新笔记进行精准推送 | 新笔记 0-1 互动数提升10.8% | 总结 |
| 支小宝 2.0- 智能金融助理 | 蚂蚁财富 | 为客户获取金融信息、完成投资分析、量身定制理财和保险方案 | 资产配置的合理度提升 5%,频繁交易比例下降 60% | 交互、分析 |
| 文修大模型赋能出版行业新未来 | 蜜度 | 校对出版物中存在的文字标点差错、知识性差错以及内容导向风险 | 日均审稿 100 万篇、审校字数超 2 亿 | 修改 |
5 总结
正文到此结束,以下是核心内容总结:
- 大模型本质上是具备更强任务处理能力的机器学习模型,目前发展最为成熟的是大语言模型(LLM)。
- LLM 的技术发展大致经历了三个阶段:规则驱动(以 ELIZA 为代表)、数据驱动(以 n-gram 为代表)以及深度学习阶段(以 GPT 为代表)。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









