






概述
HuggingFace是一个开源社区,提供了开源的AI研发框架、工具集、可在线加载的数据集仓库和预训练模型仓库。HuggingFace提出了一套可以依照的标准研发流程,按照该框架实施工程,能够在一定程度上规避开发混乱、开发人员水平不一致的问题,降低了项目实施的风险及项目和研发人员的耦合度,让后续的研发人员能够更容易地介入,即把HuggingFace的标准研发流程变成所有研发人员的公共知识,不需要额外地学习。
HuggingFace开发流程
HuggingFace标准开发流程如下:
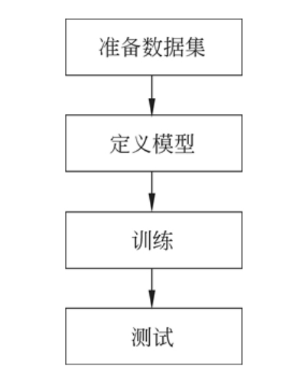
大致可细化如下:
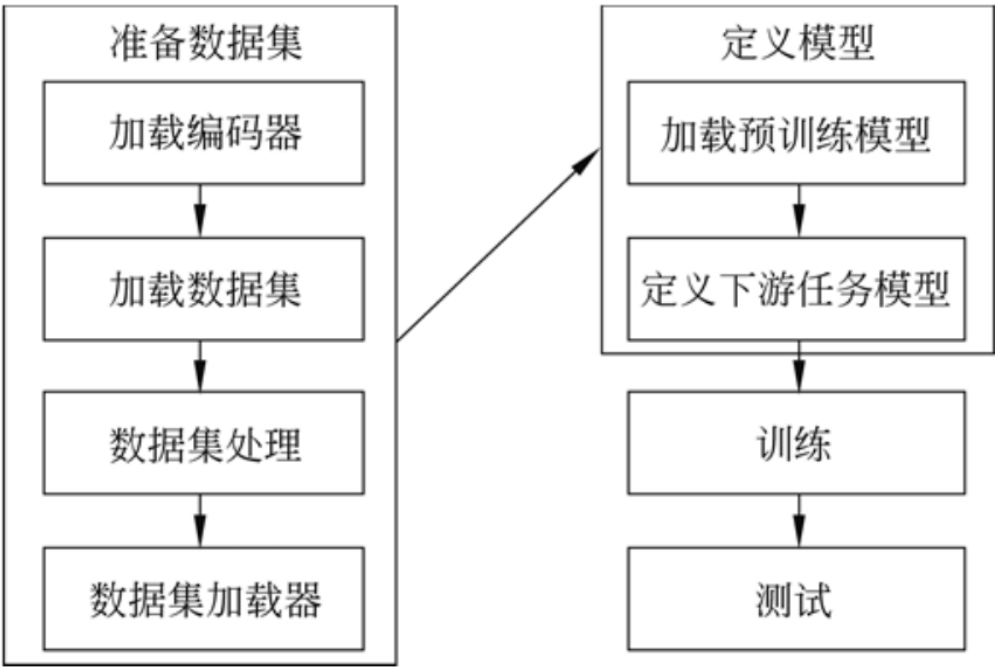
针对流程中的各个节点,HuggingFace都提供了很多工具类,能够帮助研发人员快速地实施。如下所示:
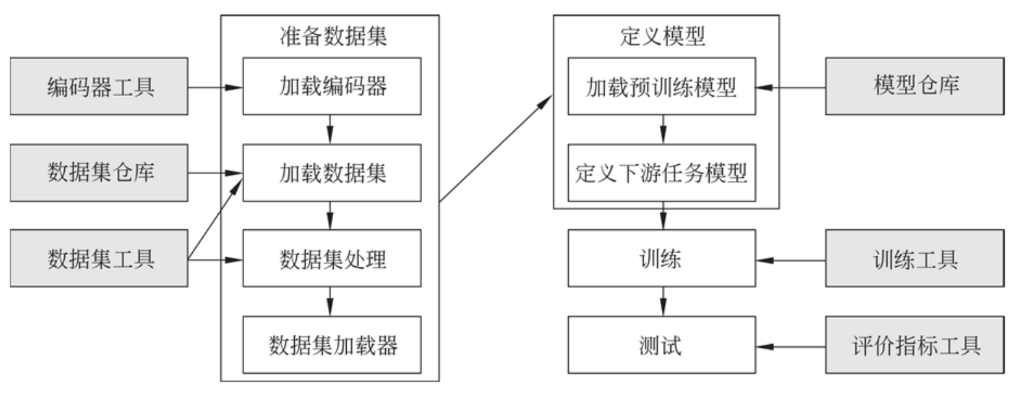
可以看出,HuggingFace提供的工具集基本囊括了标准流程中的各个步骤,使用HuggingFace工具集能够极大地简化代码复杂度,让研发人员能把更多的精力集中在具体的业务问题上,而不是陷入琐碎的细节中。在我理解看来,与Spring全家桶的作用是类似的。
HuggingFace产品
主要产品包括Hugging Face Dataset、Hugging Face Tokenizer、Hugging Face Transformer和Hugging Face Accelerate。
- Hugging Face Dataset是一个库,用于轻松访问和共享音频、计算机视觉和自然语言处理(NLP)任务的数据集。只需一行代码即可加载数据集,并使用强大的数据处理方法快速准备好数据集,以便在深度学习模型中进行训练。在Apache Arrow格式的支持下,以零拷贝读取处理大型数据集,没有任何内存限制,以实现最佳速度和效率。
- Hugging Face Tokenizer是一个用于将文本转换为数字表示形式的库。它支持多种编码器,包括BERT、GPT-2等,并提供了一些高级对齐方法,可以用于映射原始字符串(字符和单词)和标记空间之间的关系。
- Hugging Face Transformer是一个用于自然语言处理(NLP)任务的库。它提供了各种预训练模型,包括BERT、GPT-2等,并提供了一些高级功能,例如控制生成文本的长度、温度等。
- Hugging Face Accelerate是一个用于加速训练和推理的库。它支持各种硬件加速器,例如GPU、TPU等,并提供了一些高级功能,例如混合精度训练、梯度累积等。
Dataset
Hugging Face Dataset是一个公共数据集仓库,用于轻松访问和共享音频、计算机视觉和自然语言处理(NLP)任务的数据集。只需一行代码即可加载数据集,并使用强大的数据处理方法快速准备好数据集,以便在深度学习模型中进行训练。
在Apache Arrow格式的支持下,以零拷贝读取处理大型数据集,没有任何内存限制,以实现最佳速度和效率。Hugging Face Dataset还与拥抱面部中心深度集成,使您可以轻松加载数据集并与更广泛的机器学习社区共享数据集。
在花时间下载数据集之前,快速获取有关数据集的一些常规信息通常会很有帮助。数据集的信息存储在 DatasetInfo 中,可以包含数据集描述、要素和数据集大小等信息。
使用 load_dataset_builder() 函数加载数据集构建器并检查数据集的属性,而无需提交下载:
from datasets import load_dataset
dataset = load_dataset("rotten_tomatoes", split="train")
Tokenizer
Tokenizers 提供了当今最常用的分词器的实现,重点是性能和多功能性。这些分词器也用于Transformers。
Tokenizer 把文本序列输入到模型之前的预处理,相当于数据预处理的环节,因为模型是不可能直接读文字信息的,还是需要经过分词处理,把文本变成一个个token,每个模型比如BERT、GPT需要的Tokenizer都不一样,它们都有自己的字典,因为每一个模型它的训练语料库是不一样的,所以它的token和它的字典大小、token的格式都会各有不同,整体来讲,就是给各种各样的词进行分词,然后编码,以123456来代表词的状态,这个就是Tokenizer的作用。
所以,Tokenizer的任务就是把输入的文本转换成一个一个的标记,它还可以负责对文本序列的清洗、截断、填充进行处理。简而言之,就是为了满足具体模型所要求的格式。
主要特点:
- 使用当今最常用的分词器训练新的词汇表并进行标记化。
- 由于Rust实现,因此非常快速(训练和标记化),在服务器CPU上对1GB文本进行标记化不到20秒。
- 易于使用,但也非常多功能。
- 旨在用于研究和生产。
- 完全对齐跟踪。即使进行破坏性规范化,也始终可以获得与任何令牌对应的原始句子部分。
- 执行所有预处理:截断、填充、添加模型所需的特殊令牌。
这里演示如何使用 BPE 模型实例化一个:classTokenizer
from tokenizers import Tokenizer
from tokenizers.models import BPE
tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
Transformer
Transformers提供API和工具,可轻松下载和训练最先进的预训练模型。使用预训练模型可以降低计算成本、碳足迹,并节省训练模型所需的时间和资源。这些模型支持不同模态中的常见任务,例如:
- 自然语言处理:文本分类、命名实体识别、问答、语言建模、摘要、翻译、多项选择和文本生成。
- 计算机视觉:图像分类、目标检测和分割。
- 音频:自动语音识别和音频分类。
- 多模式:表格问答、光学字符识别、从扫描文档中提取信息、视频分类和视觉问答。
Transformers支持PyTorch、TensorFlow和JAX之间的框架互操作性。这提供了在模型的每个阶段使用不同框架的灵活性;在一个框架中用三行代码训练一个模型,在另一个框架中加载它进行推理。模型还可以导出到ONNX和TorchScript等格式,以在生产环境中部署。
# 导入必要的库
from transformers import AutoModelForSequenceClassification
# 初始化分词器和模型
model_name = "bert-base-cased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 将文本编码为模型期望的张量格式
inputs = tokenizer(dataset["train"]["text"][:10], padding=True, truncation=True, return_tensors="pt")
# 将编码后的张量输入模型进行预测
outputs = model(**inputs)
# 获取预测结果和标签
predictions = outputs.logits.argmax(dim=-1)
Accelerate
Accelerate 是一个库,只需添加四行代码,即可在任何分布式配置中运行相同的 PyTorch 代码!简而言之,大规模的训练和推理变得简单、高效和适应性强。
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, training_dataloader, scheduler = accelerator.prepare(
model, optimizer, training_dataloader, scheduler
)
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 6203
6203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









