






前言
这里说的微调主要是指参数微调,参数微调的方法主要有以下几种:
-
Adapter
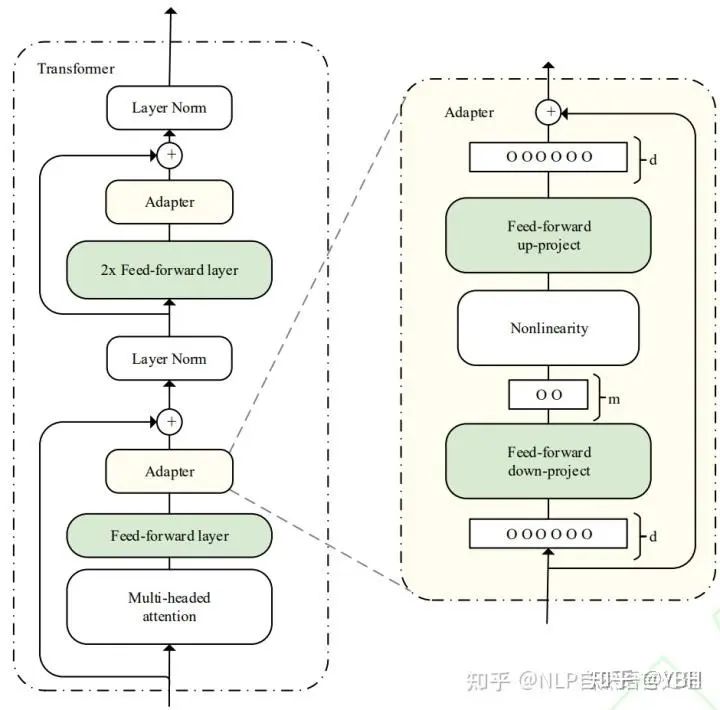
在预训练模型每一层(或某些层)中添加Adapter模块(如上图左侧结构所示),微调时冻结预训练模型主体,由Adapter模块学习特定下游任务的知识。每个Adapter模块由两个前馈子层组成。具体使用了Adapter的模型结构如下所示:
 给每个任务定义了自己的Prompt,拼接到输入数据一起作为输入,同时freeze预训练模型进行训练
给每个任务定义了自己的Prompt,拼接到输入数据一起作为输入,同时freeze预训练模型进行训练 -
Prefix-tunning 前缀微调将一个连续的特定于任务的向量序列添加到输入,称之为前缀,如下图中的红色块所示。与提示(prompt)不同的是,前缀完全由自由参数组成,与真正的token不对应。相比于传统的微调,前缀微调只优化了前缀。因此,我们只需要存储一个大型Transformer和已知任务特定前缀的副本,对每个额外任务产生非常小的开销。

-
P-tuning/P-tuning V2
P-tuning V1直接对embedding层进行优化存在两个挑战:embedding层已经经过预训练,如果直接对输入的prompt embedding进行随机初始化训练,容易陷入局部最优;没法捕捉到prompt embedding之间的相关性。
P-Tuning V2是升级版本,主要解决P-Tuning V1在小参数量模型上表现差的问题。V2在每一层上都加了一个残差连接,每一层都加上prompts,使特征更充分。
P-tuning模型加入embedding位置不固定,可以加在整个输入的前面或者后面,用法比较灵活,且其通过MLP+LSTM的方式对加入的embedding进行了学习,以提高收敛性。整体框架如下图所示: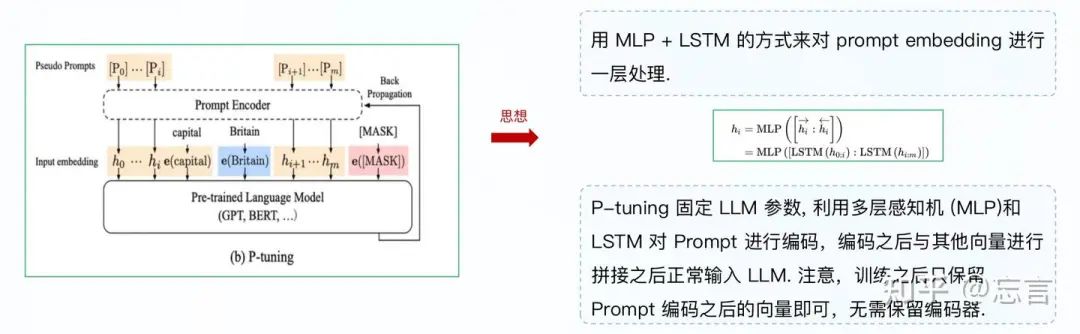
-
LORA
采用低秩矩阵近似的思想,冻结一个预训练模型的矩阵参数,并选择用A和B矩阵来替代,在下游任务时只更新A和B。流程如下:

最后
为了助力朋友们跳槽面试、升职加薪、职业困境,提高自己的技术,本文给大家整了一套涵盖AI大模型所有技术栈的快速学习方法和笔记。目前已经收到了七八个网友的反馈,说是面试问到了很多这里面的知识点。
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇


面试题展示
1、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
2、什么是序列到序列模型(Seq2Seq),并举例说明其在自然语言处理中的应用。
答案:Seq2Seq模型是一种将一个序列映射到另一个序列的模型,常用于机器翻译、对话生成等任务。例如,将英文句子翻译成法文句子。
3、请解释一下Transformer模型的原理和优势。
答案:Transformer是一种基于自注意力机制的模型,用于处理序列数据。它的优势在于能够并行计算,减少了训练时间,并且在很多自然语言处理任务中表现出色。
4、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
5、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
6、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
7、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
8、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
9、解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
10、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
11、请解释一下LSTM(Long Short-Term Memory)模型的原理和应用场景。
答案:LSTM是一种特殊的循环神经网络结构,用于处理序列数据。它通过门控单元来学习长期依赖关系,常用于语言建模、时间序列预测等任务。
12、请解释一下BERT模型的原理和应用场景。
答案:BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,通过双向Transformer编码器来学习文本的表示。它在自然语言处理任务中取得了很好的效果,如文本分类、命名实体识别等。
13、什么是注意力机制(Attention Mechanism),并举例说明其在深度学习中的应用。
答案:注意力机制是一种机制,用于给予模型对不同部分输入的不同权重。在深度学习中,注意力机制常用于提升模型在处理长序列数据时的性能,如机器翻译、文本摘要等任务。
14、请解释一下生成对抗网络(GAN)的原理和应用。
答案:GAN是一种由生成器和判别器组成的对抗性网络结构,用于生成逼真的数据样本。它在图像生成、图像修复等任务中取得了很好的效果。
15、请解释一下卷积神经网络(CNN)在计算机视觉中的应用,并说明其优势。
答案:CNN是一种专门用于处理图像数据的神经网络结构,通过卷积层和池化层提取图像特征。它在计算机视觉任务中广泛应用,如图像分类、目标检测等,并且具有参数共享和平移不变性等优势。
16、请解释一下强化学习(Reinforcement Learning)的原理和应用。
答案:强化学习是一种通过与环境交互学习最优策略的机器学习方法。它在游戏领域、机器人控制等领域有广泛的应用。
17、请解释一下自监督学习(Self-Supervised Learning)的原理和优势。
答案:自监督学习是一种无需人工标注标签的学习方法,通过模型自动生成标签进行训练。它在数据标注困难的情况下有很大的优势。
18、请解释一下迁移学习(Transfer Learning)的原理和应用。
答案:迁移学习是一种将在一个任务上学到的知识迁移到另一个任务上的学习方法。它在数据稀缺或新任务数据量较小时有很好的效果。
19、请解释一下模型蒸馏(Model Distillation)的原理和应用。
答案:模型蒸馏是一种通过训练一个小模型来近似一个大模型的方法。它可以减少模型的计算和存储开销,并在移动端部署时有很大的优势。
20、请解释一下BERT中的Masked Language Model(MLM)任务及其作用。
答案:MLM是BERT预训练任务之一,通过在输入文本中随机mask掉一部分词汇,让模型预测这些被mask掉的词汇。
由于文章篇幅有限,不能将全部的面试题+答案解析展示出来,有需要完整面试题资料的朋友,可以扫描下方二维码免费领取哦!!! 👇👇👇👇




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









