






在这篇文章,我们将对《Large Language Diffusion Models》这篇论文进行解析,介绍首个基于扩散模型的 LLM,该模型可与强大的 LLM 相媲美。

引言
近年来,大语言模型(LLMs)变得极其强大,为通向通用人工智能(AGI)铺平了道路。这些模型本质上是自回归的,即根据给定的 token 序列预测下一个 token。我们可以把这个过程想象成它们在一个词一个词地生成回答内容,其中的每个新词都基于前面已有的词汇。事实证明,这种方法非常强大,让我们取得了今天的成就。
然而,这种方法也面临着一些挑战。例如,按顺序逐个生成 token 的计算成本很高。此外,**固有的从左到右的建模方式限制了模型在逆向推理(reversal reasoning)任务中的有效性。**后文将提到一个案例 —— 逆向诗歌补全任务,即给定诗歌中的一句话,模型需要预测诗中这句话前一句的内容。无论如何,有一点值得探讨:自回归建模是否唯一可行的方式?
《Large Language Diffusion Models》对这一假设提出了挑战。正如 LLMs 是自然语言处理的基石一样,扩散模型则是计算机视觉领域的王者,是顶级文生图模型的核心技术。在本文中,我们将解读研究人员如何将扩散模型应用于语言建模领域。
2、什么是扩散模型?
让我们先快速回顾一下计算机视觉中的扩散模型,这将有助于我们理解本文的核心思想。
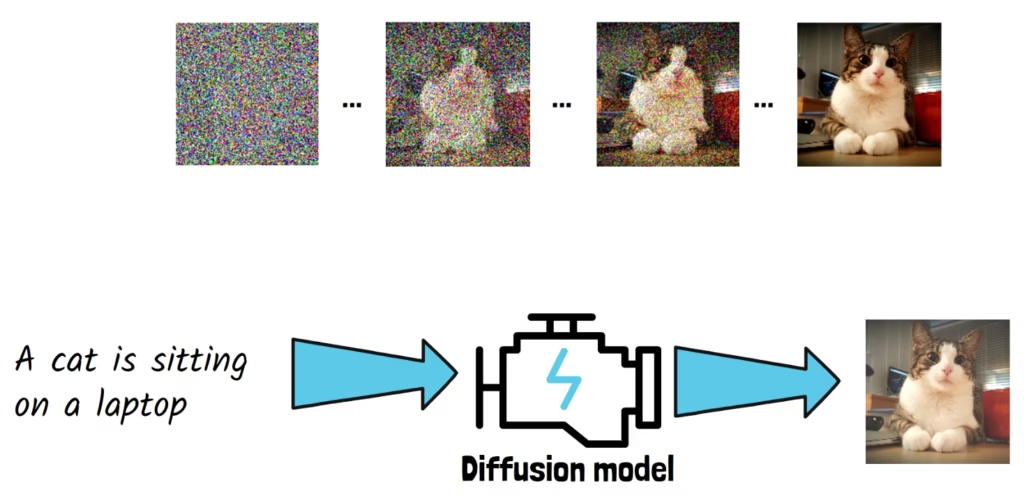
扩散模型逐步去除图像中的噪声(Cat images source[2])
扩散模型以提示词作为输入,例如“一只猫坐在一台笔记本电脑上”。模型通过学习逐步去除图像中的噪声来生成清晰的图像。模型从最左侧所示的随机噪声图像开始,每一步都去除部分噪声。去噪过程是以输入提示词为条件的,因此最终生成的图像会匹配提示词内容。上图中的三个点(…)表示本例中我们跳过了一些中间步骤。最终我们得到一张清晰的猫图像,这就是扩散模型根据给定提示词生成的最终输出。
在训练过程中,为了学习如何去除噪声,我们会逐步向清晰图像添加噪声,这个过程称为扩散过程。该领域已取得一系列进展,但这不是本文的重点。
3、大型语言扩散模型的直观理解
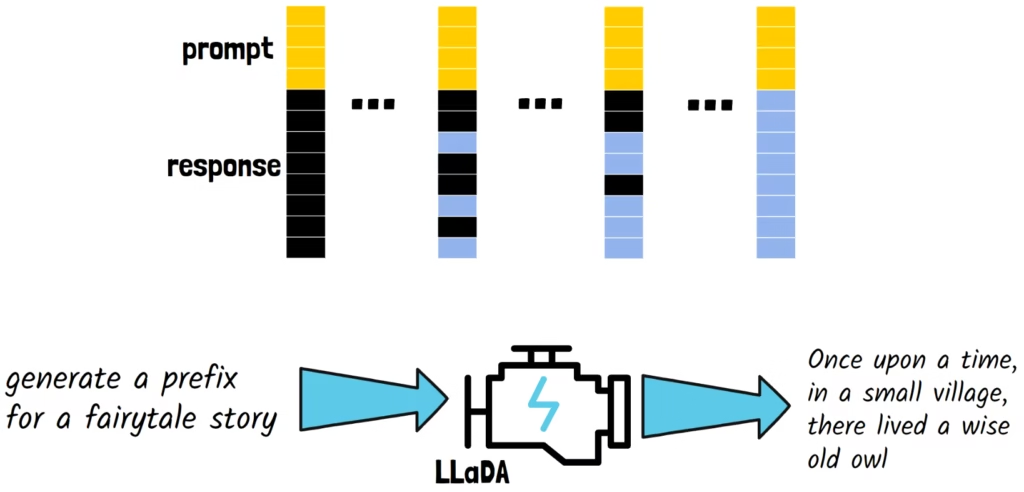
LLaDA 逐步去除 token 序列中的掩码
本文介绍的模型名为 LLaDA,全称是 Large Language Diffusion with mAsking。我们从最左侧的 token 序列开始,其中黑色部分表示被掩码的 token。黄色的未掩码 token 代表提示词,黑色的被掩码 token 代表待生成的响应。请注意,这里的被掩码的 token 由特殊符号表示,不同于我们之前提到的图像中叠加的噪声。
我们逐步去除 token 序列中的掩码,蓝色代表已解除掩码的 token。最终,我们移除所有掩码,得到针对输入提示词的完整响应。在本例中,清晰的响应 token 序列对应文字为:“从前,在一个小村庄里,住着一只聪明的老猫头鹰(Once upon a time, in a small village, there lived a wise old owl)”。
4、LLaDA 训练与推理过程概述
让我们来深入探讨大型语言扩散模型的更多细节。下图展示了该模型的两个训练阶段(预训练与监督式微调)以及推理过程。

LLaDA 训练过程与推理示意图(Source[1])
4.1 LLaDA 训练阶段1 —— 预训练阶段
我们从预训练阶段开始,如上图最左侧所示。
顶部是训练集中的一个样本序列。我们随机选择掩码比例 t(0 到 1 之间的值),随后独立地为每个 token 随机决定是否掩码,概率为 t。这一步会产生部分被掩码的 token 序列。该序列被输入模型的核心组件 —— mask predictor(这是一个基于 Transformer 的模型),该模型通过计算掩码 token 上的交叉熵损失,训练其还原被掩码的 token。预训练数据集规模为 2.3 万亿 token。
4.2 LLaDA 训练阶段2 —— 监督式微调
第二个训练阶段是监督式微调,如上图中间部分所示。此阶段的目的是增强 LLaDA 遵循指令的能力。
顶部是包含提示词和响应的样本。我们希望训练模型根据提示词生成响应。与预训练类似,我们随机掩码样本中的部分 token,但此次仅掩码响应部分的 token,保留提示词完整。随后,我们将提示词和部分被掩码的响应输入 mask predictor,以恢复响应中被掩码的 token。此过程与预训练阶段非常相似,区别在于此过程仅掩码样本的响应部分。
训练过程的掩码比例(决定多少 token 被掩码)对每个样本都是随机的。这意味着在训练过程中,模型会接触到几乎未掩码的样本和高度掩码的样本。
在这一阶段,研究人员使用了 450 万样本训练 LLaDA。由于样本长度不一致,因此研究人员使用特殊的序列结束 tokens 填充样本。通过这种方式,模型就能在人类设置的固定长度的(artificial fixed-length)输入上进行训练,并能预测序列结束 tokens,从而终止生成过程。
4.3 推理阶段:LLaDA 如何生成文本
了解完 LLaDA 的训练方式后,接下来让我们回顾一下上图右侧所示的推理过程。
给定提示词后,会创建包含完整提示词和被完全掩码的响应的样本。然后通过称为逆向扩散过程(reverse diffusion process)的迭代流程,逐步解除响应部分的掩码。每次迭代开始时,我们会得到一个包含完整提示词和被部分掩码的响应的序列。将其输入 mask predictor 后,它会预测出所有被掩码的 token。然而,部分预测出的 token 会被重新掩码,因此响应仍保持部分掩码状态,直到最后一次迭代,我们才会获得完整响应。
4.4 推理期间的重新掩码策略
迭代次数是模型的超参数,需要在计算成本与生成质量间权衡(更多迭代次数可提升生成质量)。在每次迭代中,重新掩码的 token 数量基于总迭代次数。但如何决定哪些 token 需要重新掩码?研究者未采用随机方法,而是使用了两种更有效的策略:
- 低置信度重新掩码(Low-confidence remasking) —— 此方法中,预测置信度最低的 token 会被重新掩码。对于每个 token,mask predictor 都会从词表中选择概率最高的 token 作为预测结果。此处的最高概率代表 token 预测的置信度,反映模型对此 token 相较于其他选项的正确性确定程度。
- 半自回归重新掩码(Semi-autoregressive remasking) —— 响应长度可能因提示词而异。对于需要简短回答的提示词,大部分响应内容可能是序列结束标记。为避免生成过多高置信度的序列结束标记,会将待生成的响应划分为多个区块,并按从左到右顺序依次处理。在每个区块内部应用逆向扩散过程进行采样。
5、LLaDA Results
5.1 Benchmark Results
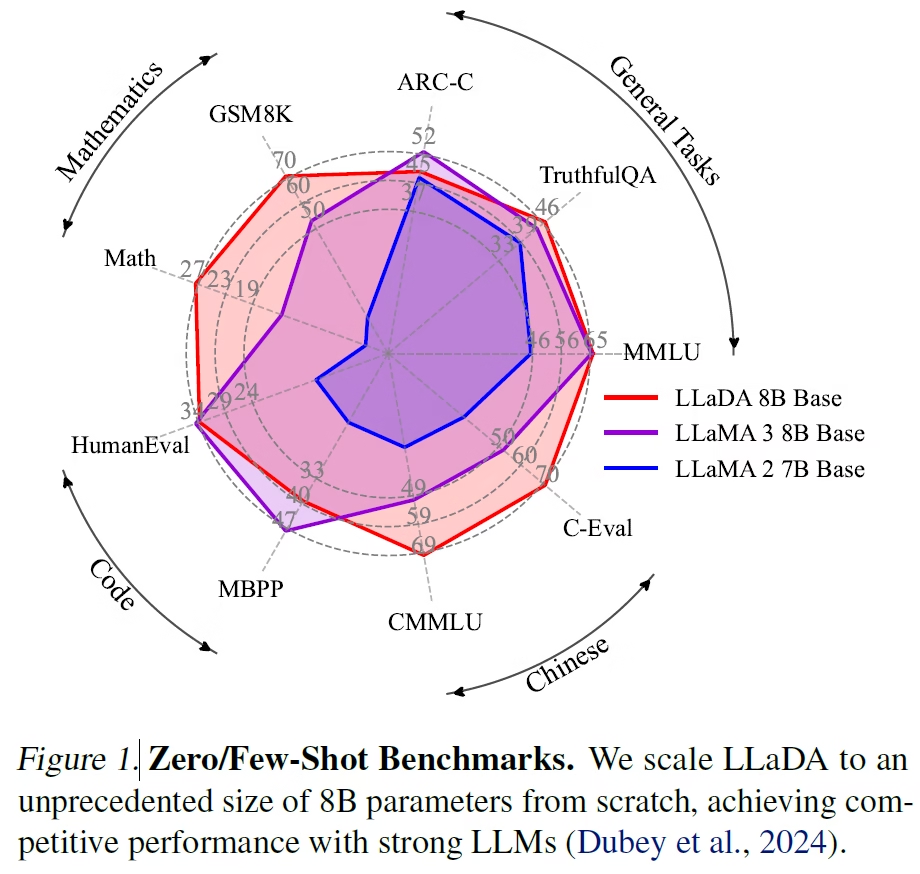
LLaDA 与 LLaMA 模型对比(Source[1])
在上图中,我们对比了 8B 参数的 LLaDA 基础模型与规模相近的 LLaMA 3 和 LLaMA 2 在多项任务上的表现。使用红色标注的 LLaDA 明显优于使用蓝色标注的 LLaMA 2,并与使用紫色标注的 LLaMA 3 表现相当,甚至在部分任务上优于 LLaMA 3。
图中结果为各模型基础版本的测试结果。未在此图表展示的经过指令调优的模型性能对比中,LLaMA 3 更具优势。但需注意,指令调优版 LLaMA 3 在预训练阶段后既进行了监督式微调也进行了强化学习训练,而指令调优版 LLaDA 仅在预训练阶段后进行了监督式微调。
5.2 LLaDA 在不同规模下的性能扩展规律(LLaDA Scaling Trends)
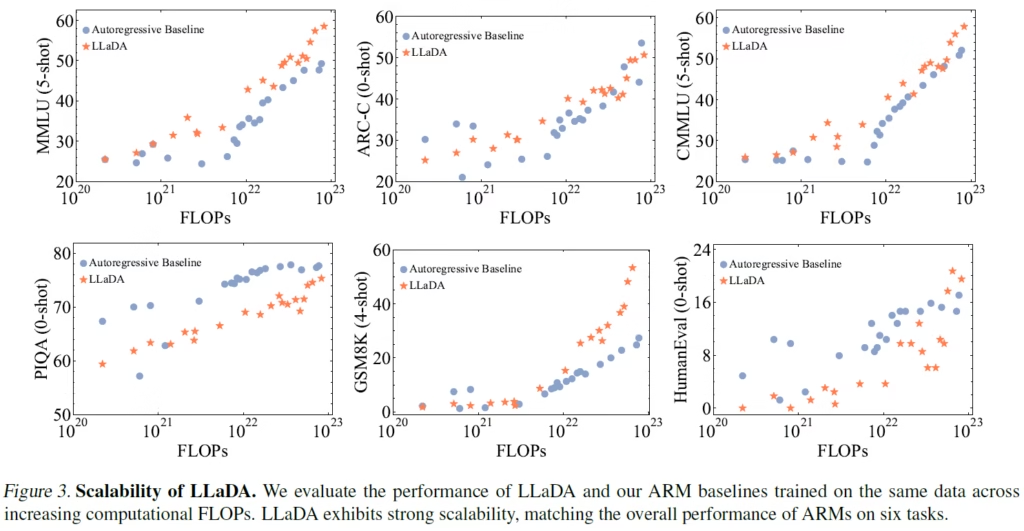
LLaDA 在语言任务上的性能扩展规律(Source[1])
论文中另一张有趣的图表展示了 LLaDA 在语言任务上的扩展能力。研究人员以不同训练计算资源(x 轴显示)训练了规模相近的 LLaDA 和自回归基线模型(autoregressive baselines)。每张子图代表不同任务,y 轴显示模型性能。**LLaDA 展现出强大的扩展能力,与自回归基线模型竞争力相当。**在数学数据集 GSM8K 上,LLaDA 的扩展优势尤为显著;而在推理数据集 PIQA 上,LLaDA 稍落后于自回归模型,但随着浮点运算量(FLOPs)的增加,差距逐渐缩小。
5.3 打破「逆向诅咒」
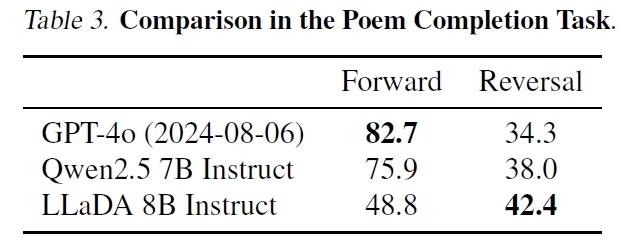
诗歌补全任务上的模型性能对比(Source[1])
上表展示了诗歌补全任务上的模型性能对比。该任务要求模型根据给定诗句生成下一句(正向任务)或前一句(逆向任务)。观察 GPT-4o 的表现,其在正向任务中的性能显著优于逆向任务,这是自回归训练固有的局限性。LLaDA 则在此取得突破,在正向和逆向任务中表现更均衡,并在逆向任务中超越 GPT-4o 和 Qwen 2.5。大型语言扩散模型在更大规模的模型训练中表现如何,让我们拭目以待!
结语:语言模型迎来新时代?
LLaDA 通过将扩散模型应用于文本生成任务,掀起了语言建模的范式转变。其双向推理能力与强大的扩展性,向传统的自回归模型发起了挑战。虽然该模型尚处探索初期,但这场技术跃迁或将定义 AI 发展的下一程,未来可期。
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









