






前言
你是否困惑:为何AI既能和你聊哲学、写科幻,但面对财报里“伪装”成正常数据的债务危机,或是法律条款间环环相扣的侵权陷阱时,却像“博而不精”的优等生,答案总差半步精准?这就像一位“通才学霸”虽然知识面广,但遇到具体学科难题时也需要“补课”——而模型微调(Fine-tuning)就是给AI“精准补课”的技术。
一、概念解读
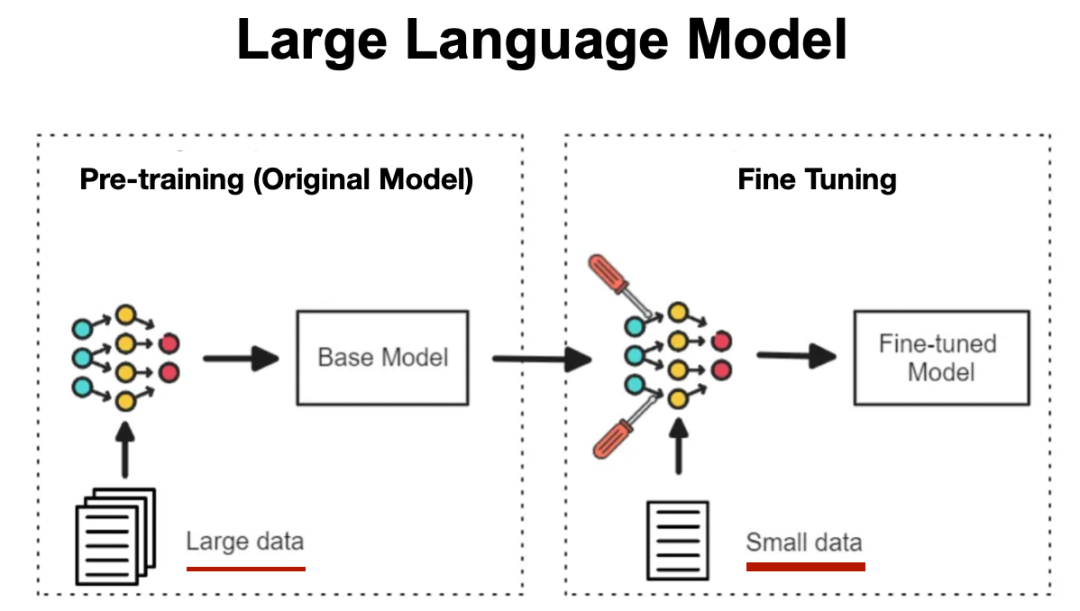
Fine-tuning(模型微调)到底是个啥? 模型微调是在预训练大模型(如DeepSeek、LLaMA、Qwen等)的基础上,用特定领域或任务的数据集对模型参数进行二次训练,让大模型“从通才成为专家”。
- 预训练模型: 已在大规模无标注数据上学习通用特征(如语言规则、物体识别)。
- 微调: 注入领域专属知识(如医疗术语、金融逻辑),使模型具备特定场景下的专业能力。
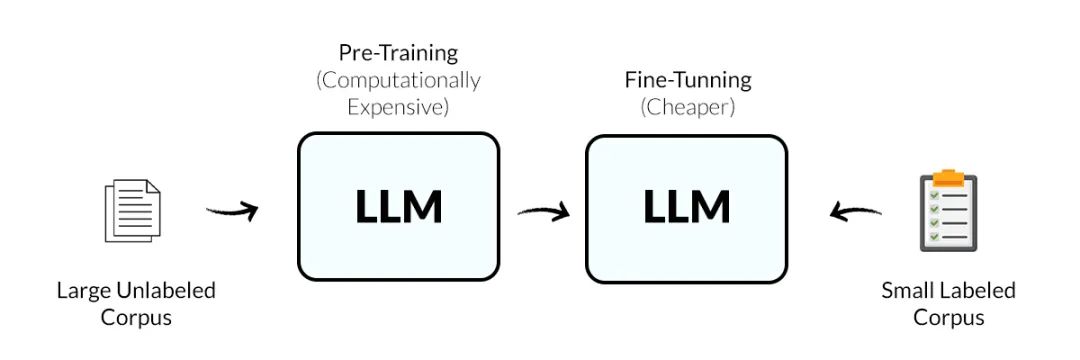
模型微调的本质是通过参数优化、数据适配与领域约束,将通用大模型的能力“聚焦”到特定场景,使其在保持基础能力的同时,精准适配行业需求。
1. 参数优化:从“泛化”到“特化”
大模型预训练时学习了全网海量数据(如满血版DeepSeek的6710亿参数),但这些知识是“泛化”的,微调通过调整部分参数(如1%-10%的参数),让模型在保留基础能力的同时,强化对领域数据的敏感度。
2. 数据适配:从“通用语料”到“领域知识库”
微调需使用领域专属数据(如法律需判例库),而非通用文本。数据需“小而精”,而非“大而杂”。例如,1000条标注的法律案例数据,可能比100万条通用文本更有效。
3. 领域约束:从“自由联想”到“专业逻辑”
通用模型可能生成**“看似合理但错误”的答案(如法律条款引用错误)。微调通过损失函数设计(如增加法律条款一致性约束),让模型输出更符合领域逻辑(如引用《民法典》第X条)****。**
为什么需要Fine-tuning(模型微调)? 通用模型难以适配细分场景的专业需求,而微调能以极少量领域数据(1000+标注)和超低计算成本(节省90%+资源),快速定制出高精度、可落地的行业专家模型。
通过合理选择数据策略和微调方法,即使新手也能在1周内完成首个定制化模型。随着QLoRA等PEFT技术的发展,微调门槛持续降低。最新数据显示,80%的企业级AI应用已采用微调方案。
二、技术实现
Fine-tuning(模型微调)如何进行技术实现?资源受限时,优先用QLoRA通过‘量化压缩’与‘LoRA精调’降低显存需求;快速验证任务可行性时,用Prompt Engineering低成本试水;LlamaFactory则用“工具箱”实现一站式微调。
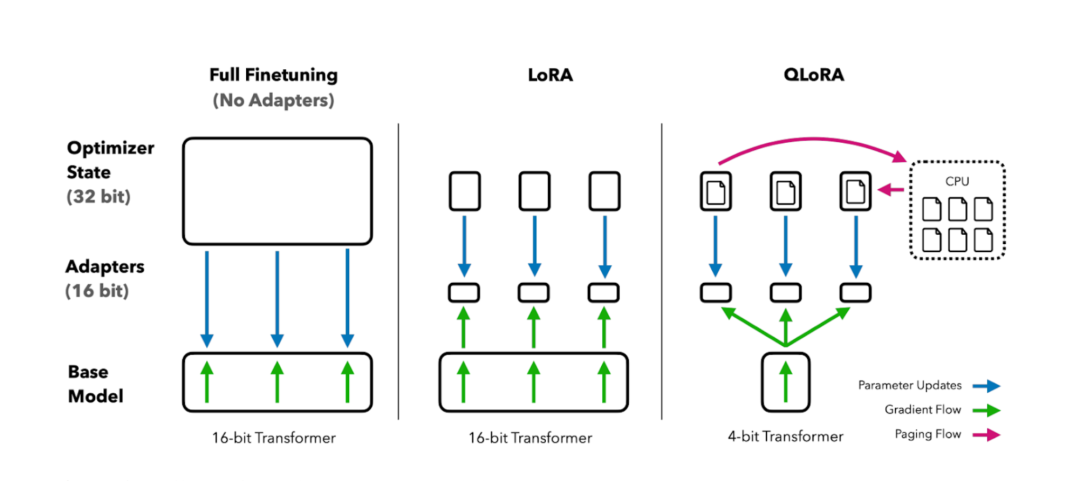
1. QLoRA——用“手术刀”式微调突破硬件瓶颈
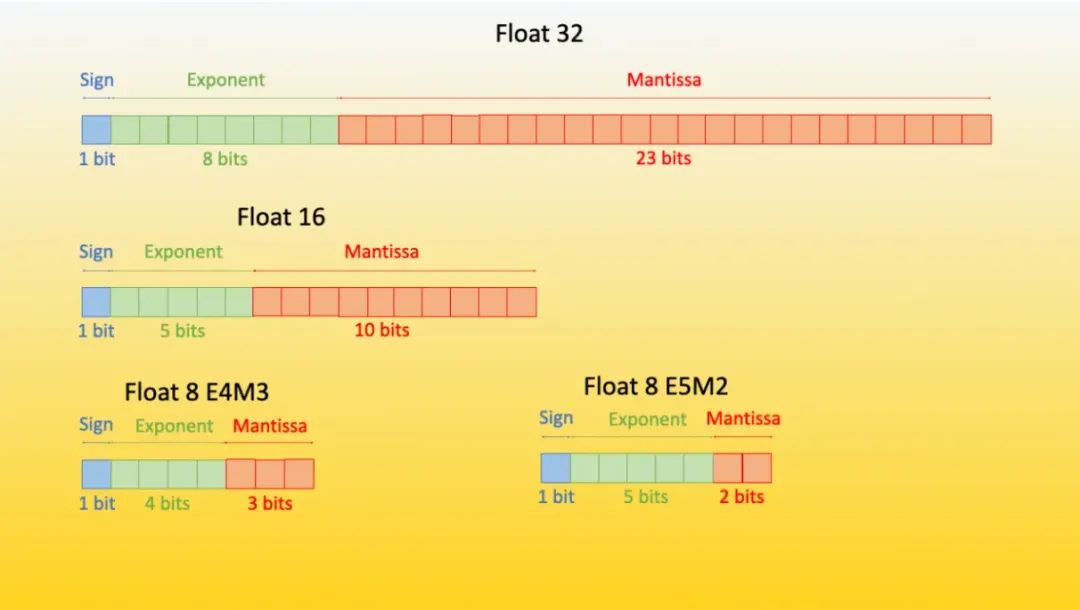
(1)量化:将模型参数从16-bit压缩至4-bit(33B模型显存占用从128GB降至24GB),类似“压缩饼干”技术,推理时解压无损精度。
(2)LoRA:冻结99.9%参数,仅在注意力层插入低秩矩阵(200万可调参数),显存消耗降低90%,类似“给模型戴眼镜聚焦领域任务”。
(3)单卡微调:用1张RTX 4090(24GB显存)微调DeepSeek-70B,相同精度下,QLora训练速度提升3倍,硬件成本降低85%。
2. Prompt Engineering——用“钥匙”解锁领域能力**(1)任务约束:通过提示词模板强制模型输出特定格式(如法律AI提示“根据《专利法》第22条分析”),条款引用准确率从55%提升至82%。(2)零参数调整:无需训练,仅需设计3-5组提示词对比效果,成本接近于零。 3. LlamaFactory——用“工具箱”实现一站式微调(1)方法集成:内置LoRA、全量微调、RLHF(偏好对齐)等6种策略,支持“即插即用”式组合(如LoRA+RLHF提升对话一致性)。(2)配置化训练:通过YAML文件定义参数(如学习率1e-5、批次大小32),避免代码级开发,效率提升60%。
3. LlamaFactory——用“工具箱”实现一站式微调(1)方法集成:内置LoRA、全量微调、RLHF(偏好对齐)等6种策略,支持“即插即用”式组合(如LoRA+RLHF提升对话一致性)。(2)配置化训练:通过YAML文件定义参数(如学习率1e-5、批次大小32),避免代码级开发,效率提升60%。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









