






由于互联网在技术、内容、渠道等方面越来越多样化,并且不断在演变。传统的爬虫大多时候都要根据网页进行定制开发。这种道高一尺魔高一丈的循环,意味着要把有限精力投入到无限的变化中,难以动态响应互联网的变化。基于AI的网页数据提取可以像人类一样动态地浏览数据、理解数据。其优势主要有:实时适应不断变化的网站结构,精确提取需要的内容,用类似人类的方法解析内容,以多种格式生成干净的结构化数据,轻松处理海量数据抓取。
为了便于学习借鉴,下面主要推荐几个比较好的开源的AI爬虫项目。
01
crawl4ai
https://github.com/unclecode/crawl4ai
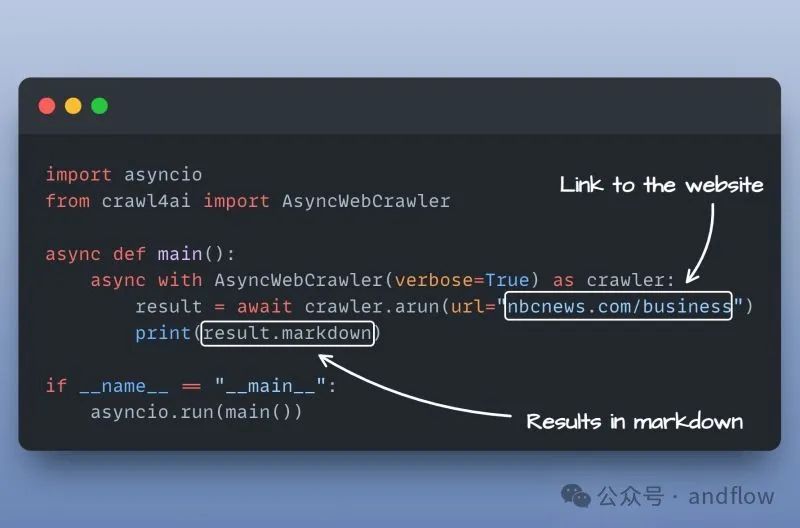
Crawl4AI简化了Web数据异步提取的过程,使Web数据提取简单高效,非常适合AI和LLM应用程序。
优势特征:
-
100%开源免费。
-
闪电般的性能:在快速可靠的抓取方面优于许多付费服务。
-
基于AI LLM构建:以JSON、HTML或markdown格式输出数据。
-
多浏览器支持:可与Chromium、Firefox和WebKit无缝配合。
-
可同时抓取多个URL:一次处理多个网站,以实现高效的数据提取。
-
全媒体支持:轻松提取图像、音频、视频以及所有HTML媒体标签。
-
提取链接:获取所有内部和外部链接以获得更深入的数据挖掘。
-
XML元数据检索:捕获页面标题、描述和其他元数据。
-
可定制:添加用于身份验证、标题或自定义页面修改的功能。
-
支持匿名:自定义用户代理设置。
-
支持截图:具备强大的错误处理功能,拍摄页面快照。
-
自定义JavaScript:在抓取定制结果之前执行脚本。
-
结构化数据输出:根据规则生成良好的JSON数据。
-
智能提取:使用LLM、集群、正则表达式或CSS选择器进行准确的数据抓取。
-
代理验证:通过安全代理支持访问受保护的内容。
-
会话管理:轻松处理多页导航。
-
图像优化:支持延迟加载和响应式图像。
-
动态内容处理:管理交互式页面的延迟加载。
-
对LLM友好的头文件:为特定于LLM的交互传递自定义头文件。
-
精确提取:使用关键字或指令优化结果。
-
️灵活的设置:调整超时和延迟,以实现更流畅的抓取。
-
iframe支持:提取iframe中的内容,以获得更深入的数据提取。
02
Scrapegraph-ai
https://github.com/ScrapeGraphAI/Scrapegraph-ai
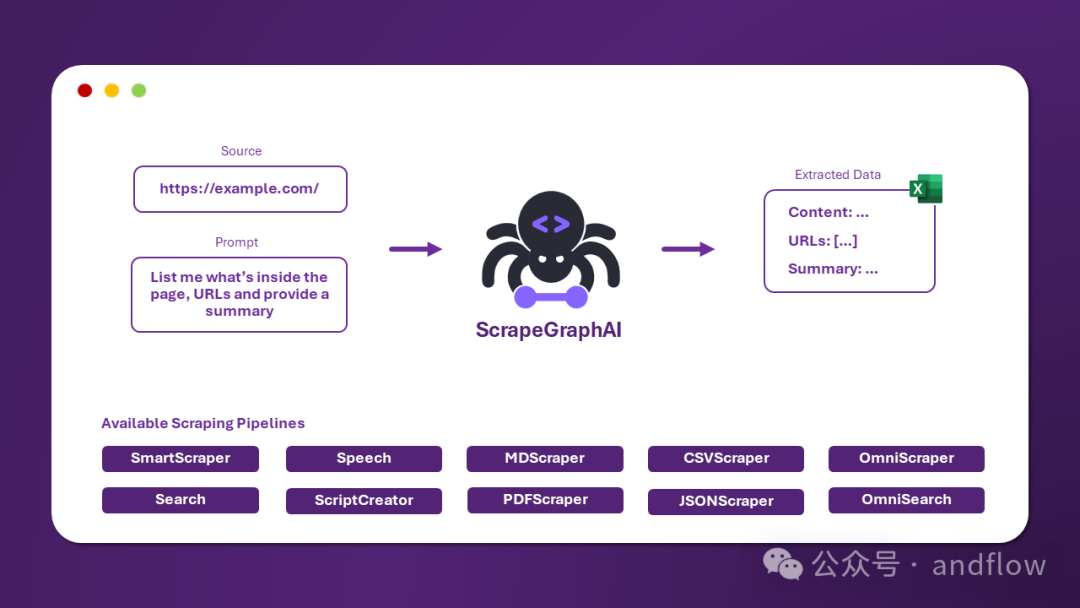
ScrapeGraphAI是一个用于web数据爬取python库,它使用LLM和逻辑图为网站或者本地文档(XML,HTML,JSON,Markdown等)创建抓取流程。
03
llm-scraper
https://github.com/mishushakov/llm-scraper
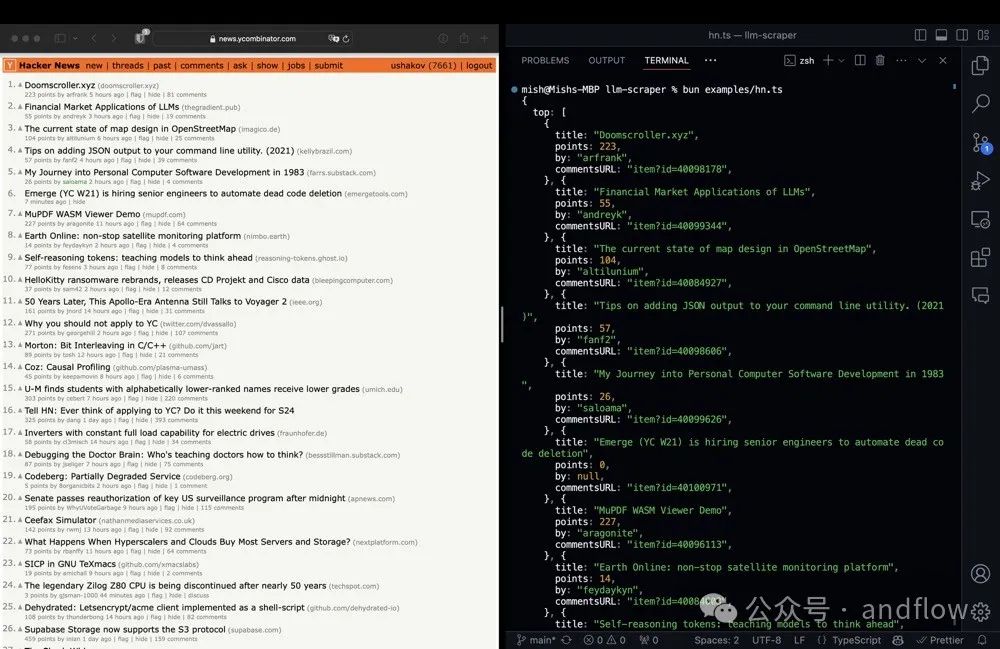
LLM Scraper是一个基于LLM的爬虫TypeScript库。并且支持代码生成功能。
优势特征:
-
支持本地或者MaaS提供商:Ollama、GGUF、OpenAI、Vercel AI SDK
-
使用Zod定义的模式
-
使用TypeScript实现完全类型安全
-
基于Playwright框架
-
流式对象
-
支持代码生成
-
支持4种数据格式化模式:
-
html用于加载原始HTML
-
markdown用于加载markdown
-
text用于加载提取的文本(使用Readability.js)
-
image用于加载屏幕截图(仅限多模式)
04
crawlee-python
https://github.com/apify/crawlee-python

Crawlee是一个Web爬虫以及浏览器自动化Python库。通过AI、LLM、RAG或GPT提取网页数据,包括从网站下载HTML、PDF、JPG、PNG和其他文件。适用于BeautifulSoup、Playwright和原始HTTP。支持有头和无头模式,支持代理轮换规则。
05
CyberScraper
https://github.com/itsOwen/CyberScraper-2077
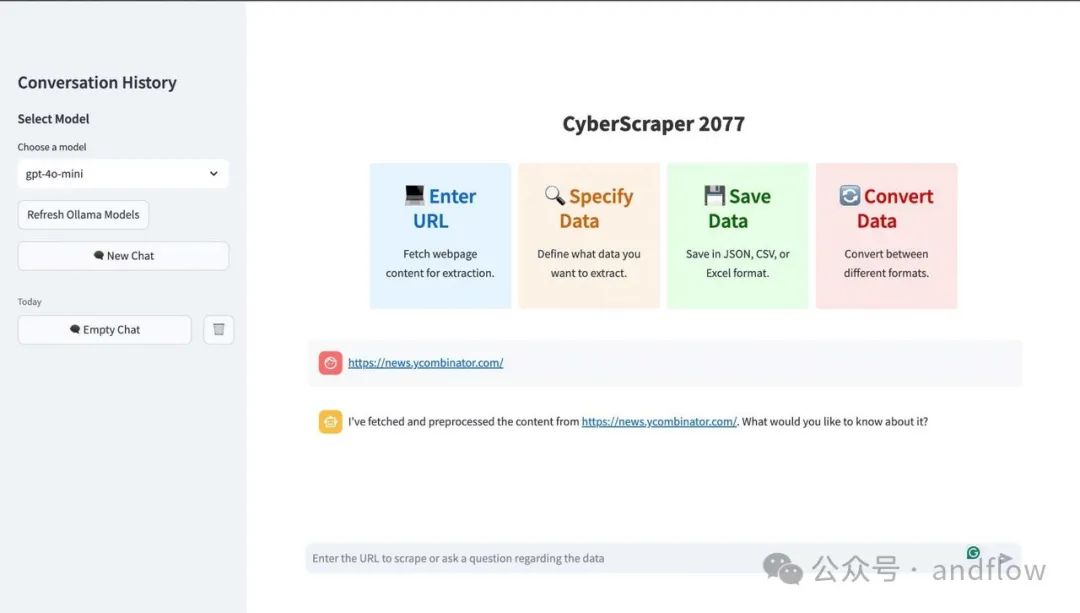
CyberScraper 2077是一款基于OpenAI、Gemini和或者本地大模型的Web爬取工具。它专为精确高效的数据提取而设计,适合数据分析师、技术爱好者和任何需要简化在线信息访问的人。
优势特点:
-
基于人工智能的提取:利用人工智能模型来智能地理解和解析Web内容。
-
流畅的流线型界面:友好的用户GUI。
-
多格式支持:以JSON、CSV、HTML、SQL或Excel格式导出数据。
-
Tor网络支持:通过Tor网络安全地抓取.onion网站,并提供自动路由和安全功能。
-
隐身模式:实现了隐身模式参数,有助于避免被检测为机器人。
-
LLM支持:提供一个支持各种LLM的功能。
-
异步操作:异步操作以实现闪电般的快速操作。
-
智能解析:抓取内容,就好像它是直接从主自己的记忆中提取的一样。
-
缓存:使用LRU缓存和自定义字典实现了基于内容和基于查询的缓存,以减少冗余的API调用。
-
支持上传到Google表格:可以轻松地将提取的CSV数据上传到Google表格。
-
验证码绕过:可通过使用URL末尾的captcha来绕过验证码。(目前只能在本地工作,不能在Docker上工作)
-
当前浏览器:可以使用运行环境中的本地浏览器环境,帮助绕过99%的机器人检测。
-
代理模式(即将推出):内置的代理支持,让你绕过网络限制。
-
浏览页面:浏览网页并从不同页面抓取数据。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









