






大模型与AI:历史与可应用程度
ChatGPT标志着人类文明正式进入了第四次工业革命,即智能革命。之所以这样讲,并不是因为以ChatGPT为代表的大模型当下非常热门,而是因为大模型能让人工智能(AI)真正落地应用,产生巨大的应用价值和商业价值,进而产生巨大的社会价值。
在大模型这一波AI技术之前,人们往往更加关注AI的热度。众所周知,人工智能经历过三次波峰,两次波谷。而自从2010年左右深度学习技术兴起之后,虽然也有波折,但是整体来说,人工智能一路欣欣向荣,高奏凯歌。事实上,人们更应该关心人工智能的应用度。之所以关注热度,大抵上是因为之前的人工智能还停留在技术层面,无法在应用和商业层面引领颠覆性革命。热度会有波折,但应用度基本上单调上升,因为技术一直在发展。
如图1所示,人工智能虽然诞生才短短60多年的,但其发展历史是一个跌宕起伏的过程,也经历过很多风格迥异的技术流派。例如,上世纪80年代的专家系统,也曾让人工智能风靡全球,在应用上也有一些可圈可点的实战案例。为此,日本甚至提出了基于专家系统的第五代计算机计划。
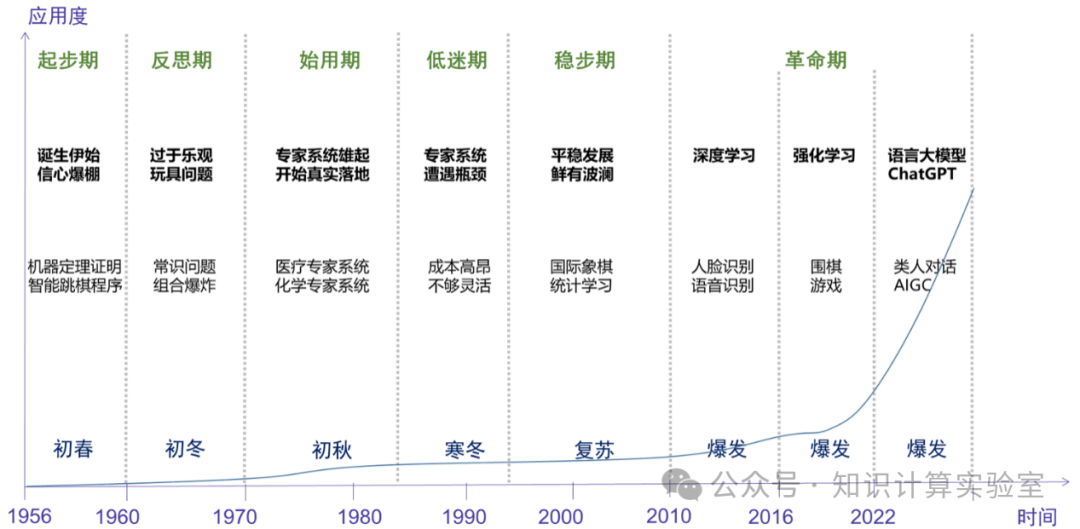
图1:人工智能极简史与应用度分析
让人工智能走向商业,真正开始落地的是始于2010年左右的深度学习技术。深度学习让机器在人脸识别、语音识别等一系列模式识别任务里达到了人类水准,从而被广泛地应用在如安防、人机交互等领域。但是,这些任务主要停留在感知层,而深度学习在认知层和决策层效果并不理想。感知固然重要,也有一定的商业价值,但是更大的价值蕴藏在“感知-认知-决策-行动”的智能体闭环中。所以感知深度学习虽然能落地,但是难以大规模产生巨大价值。
另一个值得一提的是在2016年左右兴起的以AlphaGo为代表的强化学习技术。AlphaGo在围棋上击败了人类世界冠军,这在当时认为是不可能的事,引起了巨大轰动。
强化学习极度重要,是人工智能的一项关键技术,在将来都会产生深远的价值和影响。但是AlphaGo的强化学习只是稠密强化,即其强化学习的奖惩函数较易获得。而大部分有价值的强化学习问题(包括如何解数学题和如何成功等)属于稀疏强化,随机的蒙特卡洛方法和强化学习策略极大概率无法得到奖惩。这也使得强化学习的应用度大打折扣。如果能很好地解决稀疏强化的问题,那么强化学习的应用度会非常高。
而以ChatGPT为代表的大模型则很不一样。首先,大模型已经能产生巨大的应用价值。以本文章为例,就用到了大模型打了底稿和拓宽了思路。虽然仍然需要润色、修改和勘误,但是已经能够节省了部分时间和启发了部分内容。无独有偶,在很多领域,如办公、文案、电商、法律、金融、剪辑等等,大模型都能有所帮助。其次,大模型有更广阔的前景。2023年好莱坞大罢工,其中一部分原因就是担心AI会抢走饭碗。这种担心绝非杞人忧天。
近期,在视频平台上涌现了一些AI创作的有声读物和短视频,颇具吸引力。以Sora为代表的图像与视频生成大模型,极有可能改变影视行业的格局。借助AI,个人和一个小组就有望创作高质量的短视频与电影。影视行业绝非个例,游戏、小说等也难以幸免,甚至已经出现了借助大模型写的学术论文。
应用价值并不完全等同于商业价值。截至目前,大模型的巨大投入和付费意愿并不成正比。其中一个重要的原因在于AI并没有打通“技术-估值-商业模式”的闭环。无独有偶,互联网在“连接-流量-(广告/电商/…)变现”闭环打通之前,也遇到过类似的阵痛。
饶是如此,整体上来讲,大模型技术已经能让AI大规模落地应用,从而引领了第四次工业革命。与之前的AI技术相比,这一次,是真的来了。
02
大模型:基础技术
大模型是深度学习的一种,就像深度学习是神经网络的一种一样。如图2所示,神经网络由很多个人工神经元连接组成。每个神经元简单地接受多个信号输入,通过加权和阈值函数调整,转化成一个输出。这样,整个神经网络也是接收一组信号输入,通过神经元计算,输出另一组信号。也就是说,神经网络计算了一个从输入到输出的函数。
与传统的基于图灵机的确定性的计算方式相比,神经网络具有可变的学习能力。当神经网络计算一个特定输入的时候,如果输出与事先知道的值产生了偏差的话,那么这种偏差可以通过反向传播等算法,用来修正神经网络的每条边上附带的权重,从而得到一个结构相同,但权重更优的网络。这种事先知道的输入输出对就是数据,而边上的权重就是参数。
虽然形式简单,但是神经网络功能强大。理论上已经证明,神经网络不仅是一个与图灵机等价的计算模型,也是通用的函数近似模型。当然,更重要的实际的应用效果。事实上,在深度学习爆发以前,神经网络的效果并不如人意,以至于有较长一段时间,整个神经网络领域都处在一个低谷,几乎无人问津。
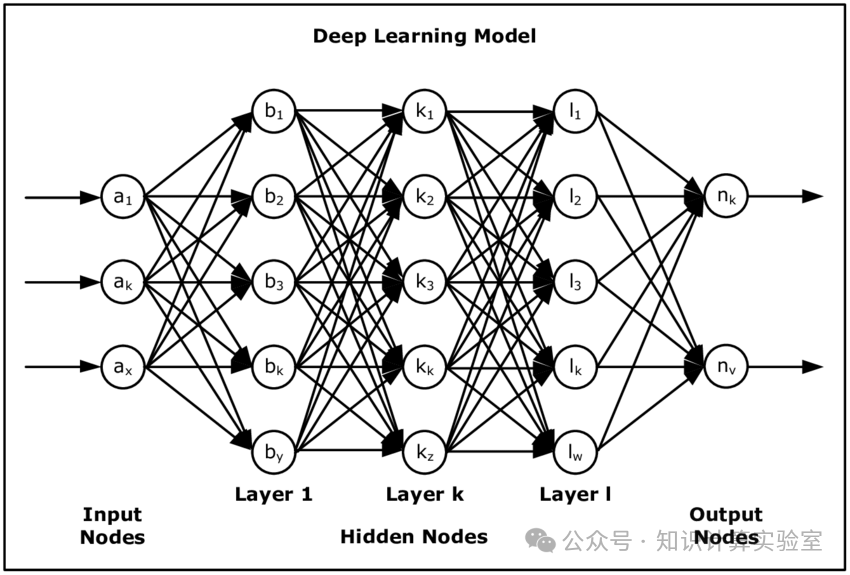
图2:神经网络如深度学习
深度学习特指层数很深的神经网络。传统的神经网络只有3层:输入层、输出层和隐藏层。深度学习大幅度增加了隐藏层的层数。例如,图2中的神经网络隐藏层数为3,总层数为5。当然,神经网络的结构也不仅限于图2中的分层形态,存在很多变种,比如循环神经网络中的LSTM、为防止梯度消失等构建的ResNet、以及在大模型中广泛应用的Transformer等等。
通过加深神经网络,深度学习的效果也大幅度得到了提升。事实上,这种提升并不只是得益于神经网络结构的加深和变种,某种意义上,更加重要的是数据的累积和标准化。当然,也离不开强大的算力对于这种大规模计算的支撑。
大模型特指参数量很大的深度神经网络。在大模型之前,常用的深度学习神经网络的参数量一般在十万到百万级,顶多到数千万。如152层的ResNet参数量大致在6千万左右。但是,大模型将这个量级提升了很多倍。
以OpenAI的GPT系列为例,初代GPT大致参数量在一亿多,第三代的GPT3.5立马飙升至1750亿,第四代则据称达到2万亿规模。就像n元线性方程组需要至少n+1元互相独立的方程来求解一样,这样大的神经网络对数据量的要求也是一个天文数字。ChatGPT背后的GPT3.5清洗了大约40T的数据,用到了570G的高质量数据进行训练。显然,无论是40T,还是570G的数据,用人工标注的方式确定其输入输出不太现实,成本过于高昂。这是因为大模型用到了划时代的预训练(Pre-training)技术。
如图3所示,给定一句话“how are you doing today”。可以通过掩码(masking)抹掉其中的几个单词,如“you”,就能得到一个残缺的句子。这些残缺的句子配对,就能得到不同的输入输出对,即数据。而这种得到数据的方式的成本极低,因为我们只要有原始的不用标注的语句即可。假设能够把所有的语句都拿来掩码和预训练,那么就能得到一个学习到所有语句上下文信息的神经网络。事实上,大模型就是这么做的。
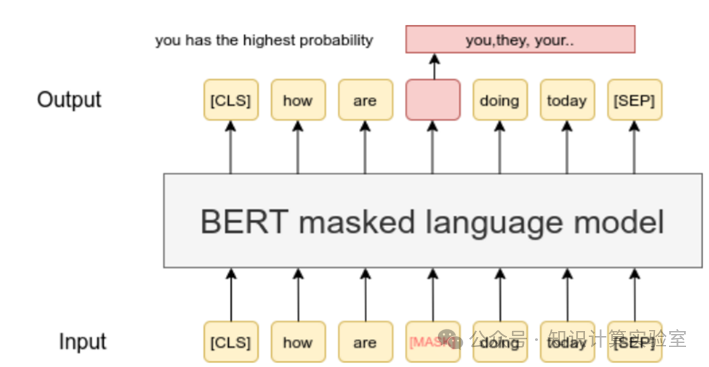
图3:掩码与预训练
预训练是大模型的第一步,所得到的称之为基座模型。如图4所示,在领域内,往往需要针对特定领域和特定问题类进行分类学习。针对特定领域,一般会使用标注好的数据进行微调,也会用到基于人类或AI反馈的强化学习机制,所得到的模型一般称之为领域微调模型。针对特定的问题类,比如数学答题,有时会将这些问题类的问题与解决方案通过提示词(Prompt)的方式继续学习与微调模型,从而得到针对这类问题有更好效果的模型。有一类特别的提示词,将解决方案的思维过程以范例的方式给出,这种思维过程称之为思维链(Chain of Thought,CoT)。思维链对有推理过程的问题类往往能起到更好的效果。
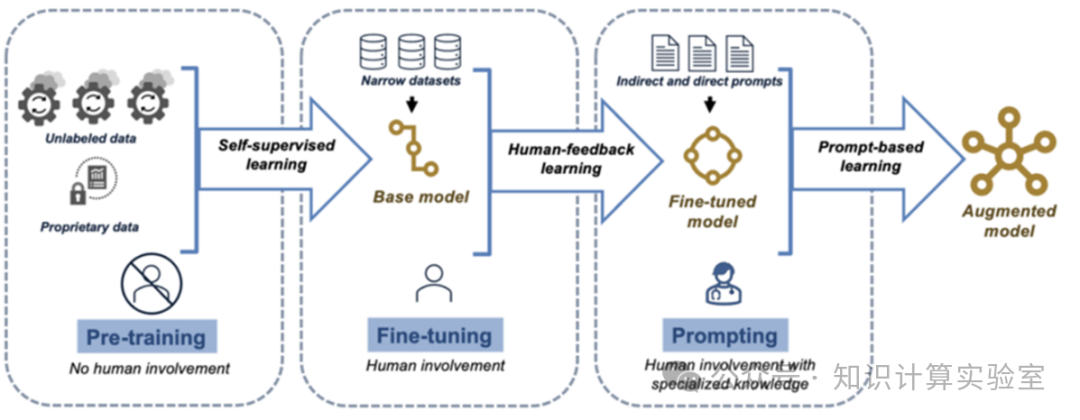
图4:大模型训练三部曲
对大模型而言,不仅训练重要,使用也相当关键。同样的问题,不同的提问方法,大模型给出的回答也差距悬殊。这就是提示词工程(Prompt Engineering)。甚至还有专门的针对大模型的提示词工程比赛。随着技术的飞速发展,提示词也越来越趋向于自动化。然而,迄今为止,提示词依然是大模型使用的关键步骤。
03
大模型:前沿进展
自2022年年底ChatGPT问世以来,大模型成为了全世界最瞩目也是投入最多的技术。据不完全统计,短短两年时间,国内就涌现了200多个大模型,而这个数字还在持续增长。大模型的投入也相当惊人。甲骨文CEO埃里森曾说,大模型的入场券至少需要1000亿美元。当然,这个说法有点夸张,也仅仅指的是具有世界顶尖水准的基座模型而不代表大模型的周边和应用。但是,这也一定程度上反应了大模型赛道的烧钱能力。
在如此巨大投入的基础上,大模型相关技术的发展用日新月异来形容,一点也不过分,甚至过于保守了。这些发展大致可以分为以下几类。
一个必然的的方向一定是更大的模型,包括更多的参数和更多的数据。在2023年以前,大模型的参数量大致每3-4个月翻一番,远超摩尔定律每两年翻一番的速度。更大的模型在2023年以前屡试不爽。然而,自2024年起出现了一定的变化。
首先,模型参数与性能的关系大致遵循对数规律,即参数的指数增加只能导致效果的线性叠加,而成本却是实打实的翻倍。其次,数据也达到了一个瓶颈。目前,通用的存量文本数据基本已经完全使用,难以找到更多的高质量语料。领域数据虽然是一个重要的方向,但是领域数据一方面获取成本过高,另一方面也或导致通用性能下降。比尔盖茨曾说大模型到了一个平缓期(Plateau);原OpenAI首席科学家苏茨克维也近期声称大模型预训练的时代已经结束。这或许也是OpenAI的GPT 5迟迟未能面世的原因之一。
与之相关的一个方向是合成数据。前面提到,好用的存量数据已经差不多用完了,所以必须考虑增量数据。由于对数据量要求巨大,人来构造新的增量数据成本过于高昂,不太现实。所以,AI和大模型能否完成这个任务?这是当下争议极大的问题。正反都有很多支持者和证据。正方观点认为通过强化学习等技术,能够判别由AI生成的数据是否质量可控,而反方认为合成数据会导致数据污染,甚至放大大模型本已存在的幻觉问题。无论如何,合成数据都是大模型值得进一步深入探索的方向,也是接下来大模型技术发展的热点之一。
算法和模型架构也无疑是一个重要方向。当前,包括OpenAI的GPT系列在内的主流大模型无一例外采用的是基于注意力机制的Transformer基础架构。主要通过累积堆叠Transformer的部分结构,构建大模型的主体神经网络。然而,这并不是天经地义的,完全有可能出现新的更好的大模型网络结构。只是由于试错成本过高,目前都相对谨慎。
值得一提的是国内DeepSeek开源模型所用的混合专家系统(Mixture-of-Experts,MoE),虽然仍然是基于Transformer,但不是简单的堆叠,而是采用了多个子模型混合的思想,在同等资源下取得了非常好的效果。而非Transformer架构的大模型也可圈可点,包括MIT提出的LFM以及国内的RWKV等等。
上文提到对于大模型,不仅训练重要,使用也很关键。大模型的使用,从人类用户的视角就是如何使用更好的提示词和CoT,但从大模型的视角不仅仅是直接通过用户给的提示词回答问题,而且可以某种程度上改写用户的提问,以期得到更好的答案。前文提到的自动化提示词就是其中之一。这种思想可以持续深入,例如,根据用户提问生成不是一个而是很多个可能的提示词和CoT,然后通过强化学习算法比较这些CoT的优劣,选择最好的。这就是大模型在使用侧或者称之为推理侧的优化。OpenAI近期提出的o1和o3,虽然没有公布具体技术细节,但大抵上应该采用了这种思路,在推理能力上取得了惊人的效果。
以上是大模型,特别是大语言模型,在训练和推理方面的主要方向。当然,除了语言模型之外,包括图像、视频等在内的多模态大模型也是一个重要的方向和热点,甚至在直接的应用和商业价值上或许更大。
04
大模型:应用现状与分析
之所以大模型受到如此关注,其关键在于其强大的能力,从而给人工智能真正大规模落地应用带来无限可能。ChatGPT是人工智能历史乃至人类历史上的一个划时代工作。首先,ChatGPT毫无疑问通过了图灵测试。之前工作虽然偶有端倪,但是备受争议。其次,ChatGPT具有很好的通用性和泛化能力。它的出现,标志着通用人工智能正式来临,而在之前只是个传说。从细分能力上,值得一提的是ChatGPT的常识能力,大致具有初中生水准。与专业知识相反,常识是指那些绝大部分人知道和公认的知识。对于机器而言,常识知识的处理远难于专业知识,因为人们都不知道需要把哪些常识喂给机器,也很难给准和给全。
既然大模型有这么强大的能力,自然而然人们希望将其应用起来,并产生商业价值。应用价值前文已经论述,而商业价值却要复杂许多。总体来说,目前纯大模型技术主要在3个方面有较大商业价值。
1、内容生成(AIGC):(多模态)大模型已经颠覆了许多与内容生成相关的行业。内容生成包括很多方面,如问答、对话、文案、图片、视频、音乐、PPT、漫画、论文、小说、电影、短视频、广告等等。因此,这是一个很大的领域,与很多工作直接相关。大模型在一些基本的内容生成领域已经达到了人类水准。例如,ChatGPT的文本、suno的音乐、Midjourney的图像、sora的视频,都让人叹为观止。与此同时,也带来了可观的收入。Midjourney在23年的营收约 2亿美元,而他们当时只有十来号人;ChatGPT23年营收据测算为16亿美元。大模型目前在复杂的内容生成任务上仍然效果不够理想,但是其迭代速度将会非常之快。
2、智能辅助系统(CoPilot):例如,微软推出了Microsoft 365 CoPilot,辅助用户使用Office等工具。按照5%的转化率,2023年也为微软带来了73亿美元的增收。严格意义上,CoPilot也是内容生成的一种特殊应用,但与常见的相比,它往往附着在一款成熟的软件或应用之上。因此,其价值也主要取决于该软件的价值与转化率,基本与创业公司无缘。
3、智能人机交互(Human Computer Interaction):人是社会性动物。因此,交互是人类的基本需求之一。(多模态)大模型给人机交互带来了很多新的可能性。美国网红Marjorie利用AI技术,构建数字人分身,并向每位用户收取每分钟1美元的费用,为其带来了可观的收入。Character.ai融资1.5亿美元,构建虚拟人物与用户交互,月活用户超过350万,于2024年8月被Google收购。智能人机交互也是内容生成的一类特殊应用。由于其需要和场景结合,以及面向的客户群体与需求明确,因此有必要单列出来。
然而,在以上领域之外,目前,纯大模型技术的应用举步维艰,尤其在行业领域之上。
先分析一下为什么纯大模型技术在上述领域能够获得成功。其原因主要有两点。第一,这些领域可以一定程度容忍不准确。例如,Midjourney生成十张图片,里面有两张满意的就够了,并不需要每张图片都很好。CoPilot毕竟只是智能辅助,有人兜底。即使不那么可靠,也能够产生一定的价值。第二,这些领域主要面向C端用户。除了有冲动消费的因素之外,C端用户相对而言容忍程度较高。
然而,行业领域往往是B端用户,而且对准确性要求非常高。不仅是准确性与可靠性,行业领域还要求可解释性与可调式性等。例如,医疗诊断,哪怕是辅助系统,不仅需要高准确率,也需要解释为什么得到该结论;先进制造业领域,一个小错误或带来巨大的损失;交通领域,一点差池也会人命关天。而以上这些,都是纯大模型技术与生俱来的劣势。
如前文所述,大模型本质上就是深度神经网络。在预训练的基础上,用概率来预测下一单词(Next Token Prediction)。虽然其表现远超预期,但是只要是概率预测,就无法保证所预测的信息准确。因此,大模型技术的原罪就是可靠性(准确性),也就是俗称的“幻觉”问题。大模型有时候会一本正经地胡说八道,或张冠李戴。也因此,大模型在处理长链条的数学与逻辑推理上也遇到很大的困难。对于一个10步推理的任务,哪怕是每一步都有95%的准确率,0.95的10次方也不到60%。此外,作为一个神经网络黑盒模型,大模型有着黑盒模型统一的可解释性差与可调式性差等问题。
图5比较了OpenAI自ChatGPT发布以来的GPT-3.5、GPT-4与OpenAI o1三个里程碑大模型的能力,主要考察基础语言能力、信息抽取、语义理解以及推理能力。左边的并不是代表能解决问题的百分比,而是代表大致的解决问题的能力。100代表能找出最优解完美解决;90大致代表与人类顶尖水准相当;70大致代表与人类平均水准相当;30大致代表展现出一定的能力。从图5中可以看出,一方面,可以看到这些大模型能力飞速发展,尤其是在复杂的推理能力上。但是,另一方面,也可以看到,它们在这些复杂能力上仍然有不少欠缺。而这,对很多行业领域的核心应用而言,还存在很大的距离。
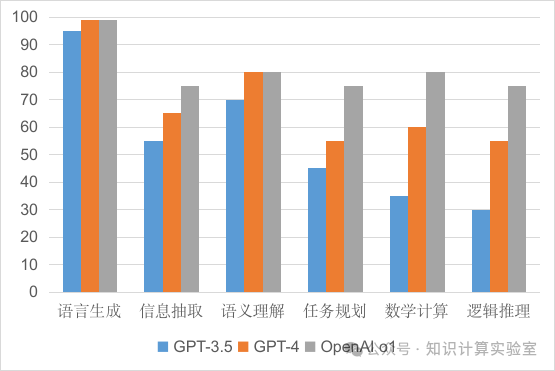
图5:OpenAI三个里程碑大模型能力对比
05
大模型增强:技术与应用分析
以上讨论的是纯大模型的技术、能力与应用度。大模型是AI的一项技术,不代表整个AI。例如,获得2024年诺贝尔化学奖的工作AlphaFold预测蛋白质结构,用的就是非大模型的深度学习。图5阐明,大模型在某些能力上还有所欠缺。因此,针对不同场景,利用其它AI和计算机技术增强大模型的能力,是大模型相关研究与应用的重要方向。
检索增强(Retrieval Augmented Generation,RAG)是针对大模型幻觉问题在领域问答上的一项关键技术。如图6所示,针对查询,大模型并不直接生成回答,而是扮演两个角色。其一,将原任务转换和分解成相关查询集,再使用搜索工具从本地或互联网上查询相应信息。其二,聚合上述信息,并用大模型生成回答。与纯大模型方法相比,RAG在假设信息可以被(在本地或互联网)查询到的情况下,可以大幅度减缓幻觉问题。
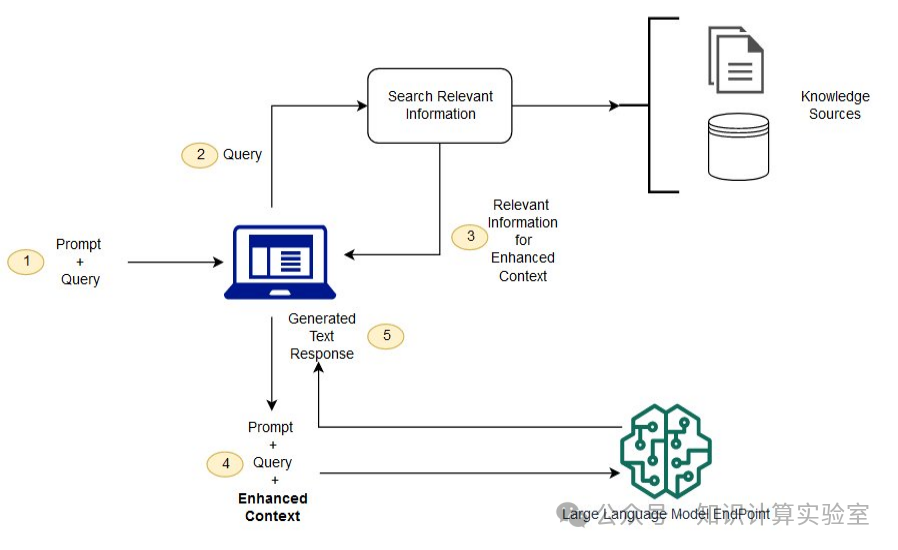
图6:检索增强(RAG)流程框架
RAG可以看作是大模型和(本地或互联网)搜索引擎的结合,两者互相补充。后者管信息检索,前者管信息综合和人机交互。这种理念可以拓广到大模型和其它人工智能与计算机技术的分工与合作,这就是智能体(Agent)。
广义上,就像质点是物体运动研究的抽象对象一样,Agent是AI研究的抽象对象,从环境中获得信息,并做出行动影响环境。狭义上,Agent是指利用大模型和其它AI或计算机技术与模块协同完成任务。图7是一个经典的Agent框架示意图。除了大模型之外,Agent可以调用各种工具和模块,包括但不限于信息检索、数学求解、数值分析、逻辑证明等等。
同时,就像计算机一样,Agent也可以有一个记忆模块,而纯大模型并不带有显式的记忆。Agent使用大模型和其它工具,基于记忆,对给定的任务进行规划,然后交给执行器做出行动。通过协同大模型与其它AI工具,Agent技术可以显著弥补大模型的不足,特别是在数学计算与逻辑推理上。例如,Agent可以调用Mathematica等工具,求解大模型不擅长的数学方程,从而使AI系统整体能力大幅度提升。因此,Agent也成为了当前最炙手可热的AI方向。
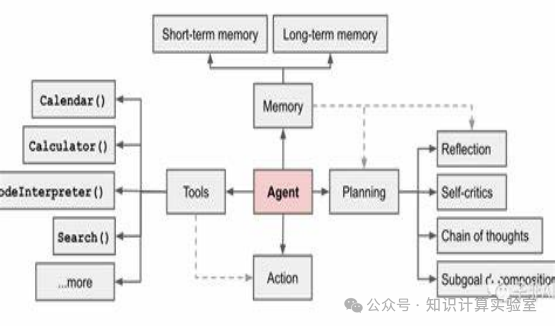
图7:智能体(Agent)框架示意图
RAG和Agent仍然存在问题。RAG只能查询信息,难以推理,即生成新的信息,且饱受版本问题和错误信息的困扰。Agent目前缺乏一个合适的主框架。以大模型为主框架会遇到因大模型幻觉问题所造成的信息误差叠加;以应用程序为主框架不失为一条路径,但又回到了原来的软件设计之上,成本高昂且缺乏泛化能力。Agent的另一个问题在于各种AI模块的接口并没有统一的体系,更缺乏准确的语义信息和边界定义,在对接和调用时会造成很大困扰。
大抵上,目前RAG和Agent的能力如图8所示。RAG在信息检索(包括未列在表中的信息定位、实体识别、信息查询、信息抽取)等能力上有显著增强,但对语义理解和推理能力帮助甚少。因为可以调用其它AI模块和工具补充,Agent在各项能力上都有显著增强,在某些行业领域场景中有较强的落地应用和商业价值。
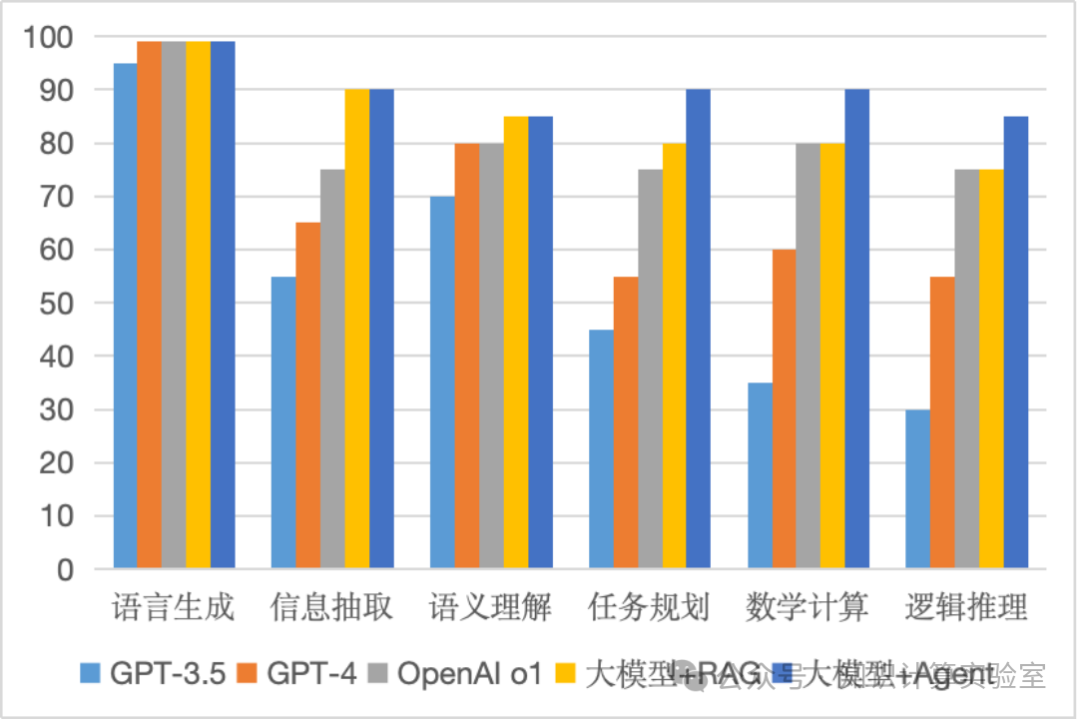
图8:大模型与增强技术能力对比
然而,这些技术离100分,也就是最优解,仍然有很大的差距。从可以有,到勉强可用,再到做得好,最后到接近完美,每一步都有很大的鸿沟。如前文所述,行业领域往往对可靠性/准确性要求非常高。更进一步,行业领域更看重的其实是错误率。从80%到90%不是10%的提升,而是错误率20%降到10%的一倍的提升。对于像芯片这样的先进制造业,哪怕是每一步都有99%的准确率,多步叠加也会造成灾难性后果;对于医疗、交通这样的人命关天的领域则更是如此。因此,大模型和AI技术的行业领域落地之路,依然任重而道远。
06
小结
以ChatGPT为代表的大模型是划时代的AI技术,标志着AI有能力大规模落地应用,从而打开了人类智能时代的大门。大模型在(多模态)内容生成等领域已经能产生一定的商业价值。然而,就像任何其它AI技术一样,大模型也绝非一招鲜。大模型概率预测和黑盒模型的本质导致其在信息抽取、语义理解和逻辑推理等能力上存在诸多缺陷,包括著名的幻觉问题。因此,大模型在行业领域的落地举步维艰。RAG和Agent等技术能一定程度上弥补这种不足,却也远非一路高奏凯歌。
路漫漫其修远兮,吾将上下而求索。智能时代才刚刚来临,大模型也只是一个引子。在将来必定会涌现更多AI技术,将具备更强的能力,从而让大模型和AI技术真正能在行业领域大规模应用落地,产生巨大的商业价值和社会价值。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









