







Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理。通过 Xorbits Inference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。无论你是研究者,开发者,或是数据科学家,都可以通过 Xorbits Inference 与最前沿的 AI 模型,发掘更多可能。
说人话:Xinference是一款模型部署框架,可以一键部署想要的开源大模型。
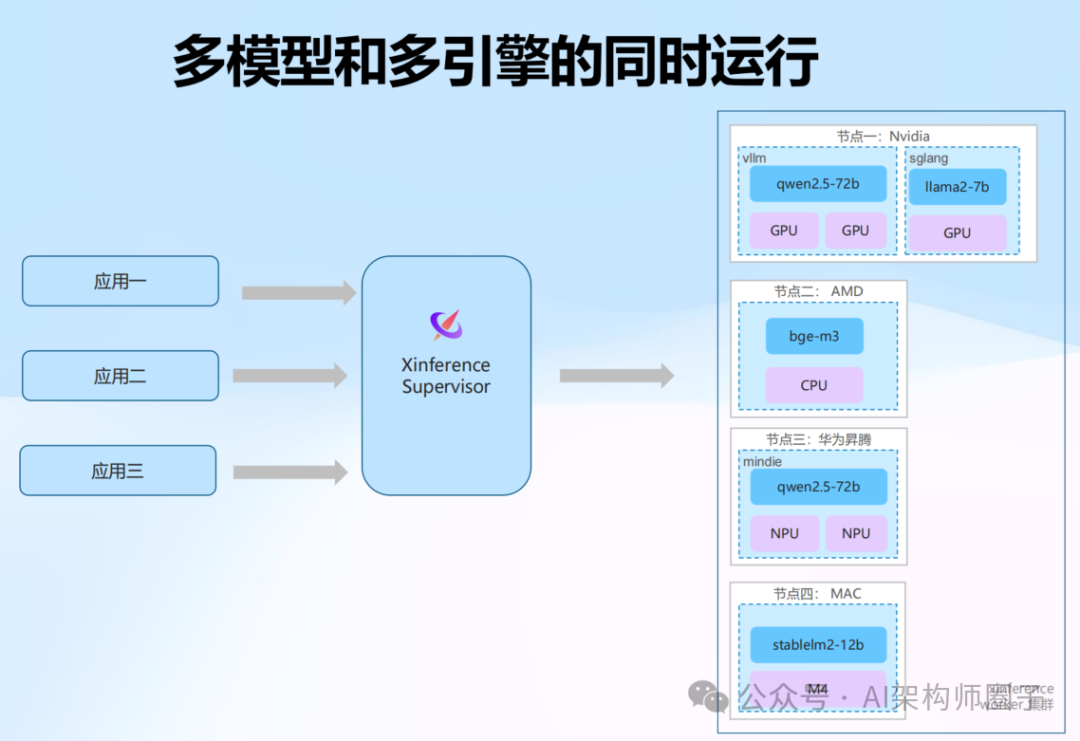
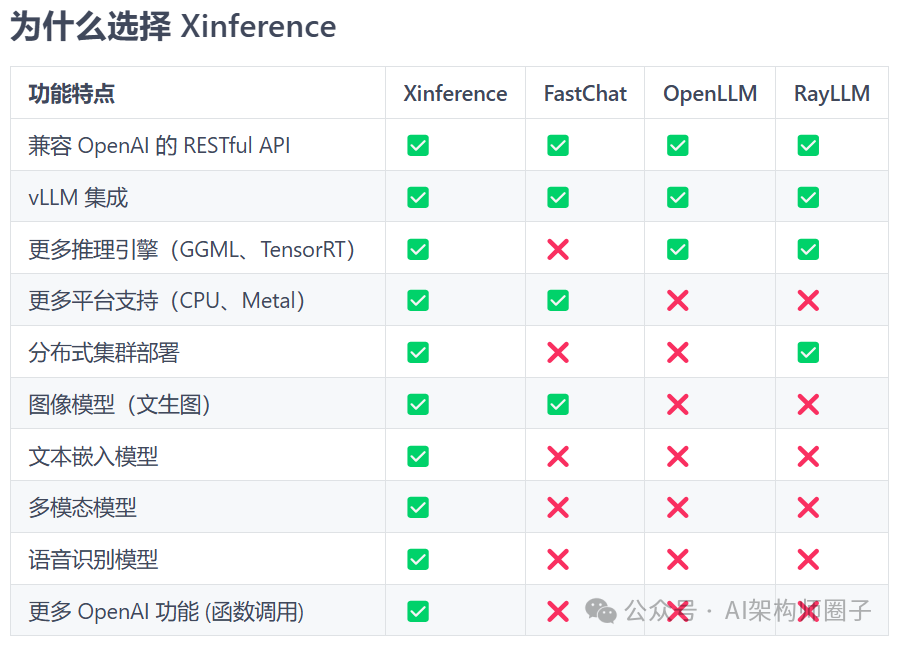
Xinference能做什么
准备工作
-
Xinference 使用 GPU 加速推理,该镜像需要在有 GPU 显卡并且安装
-
CUDA 的机器上运行。
-
保证 CUDA 在机器上正确安装。可以使用
nvidia-smi检查是否正确运行。 -
镜像中的 CUDA 版本为
12.4。为了不出现预期之外的问题,请将宿主机的 CUDA 版本和 NVIDIA Driver 版本分别升级到12.4和550以上。
Docker 镜像
当前,可以通过两个渠道拉取 Xinference 的官方镜像。1. 在 Dockerhub 的 xprobe/xinference 仓库里。2. Dockerhub 中的镜像会同步上传一份到阿里云公共镜像仓库中,供访问 Dockerhub 有困难的用户拉取。拉取命令:docker pull registry.cn-hangzhou.aliyuncs.com/xprobe_xinference/xinference:<tag> 。目前可用的标签包括:
-
nightly-main: 这个镜像会每天从 GitHub main 分支更新制作,不保证稳定可靠。 -
v<release version>: 这个镜像会在 Xinference 每次发布的时候制作,通常可以认为是稳定可靠的。 -
latest: 这个镜像会在 Xinference 发布时指向最新的发布版本 -
对于 CPU 版本,增加
-cpu后缀,如nightly-main-cpu。
自定义镜像
如果需要安装额外的依赖,可以参考 xinference/deploy/docker/Dockerfile(https://inference.readthedocs.io/zh-cn/latest/getting_started/using_docker_image.html) 。请确保使用 Dockerfile 制作镜像时在 Xinference 项目的根目录下。比如:
git clone https://github.com/xorbitsai/inference.gitcd inferencedocker build --progress=plain -t test -f xinference/deploy/docker/Dockerfile .
使用镜像
你可以使用如下方式在容器内启动 Xinference,同时将 9997 端口映射到宿主机的 9998 端口,并且指定日志级别为 DEBUG,也可以指定需要的环境变量。
docker run -e XINFERENCE_MODEL_SRC=modelscope -p 9998:9997 --gpus all xprobe/xinference:v<your_version> xinference-local -H 0.0.0.0 --log-level debug
警告
-
--gpus必须指定,正如前文描述,镜像必须运行在有 GPU 的机器上,否则会出现错误。 -
-H 0.0.0.0也是必须指定的,否则在容器外无法连接到 Xinference 服务。 -
可以指定多个
-e选项赋值多个环境变量。
当然,也可以运行容器后,进入容器内手动拉起 Xinference。
挂载模型目录
默认情况下,镜像中不包含任何模型文件,使用过程中会在容器内下载模型。如果需要使用已经下载好的模型,需要将宿主机的目录挂载到容器内。这种情况下,需要在运行容器时指定本地卷,并且为 Xinference 配置环境变量。
docker run -v </on/your/host>:</on/the/container> -e XINFERENCE_HOME=</on/the/container> -p 9998:9997 --gpus all xprobe/xinference:v<your_version> xinference-local -H 0.0.0.0
上述命令的原理是将主机上指定的目录挂载到容器中,并设置 XINFERENCE_HOME 环境变量指向容器内的该目录。这样,所有下载的模型文件将存储在您在主机上指定的目录中。您无需担心在 Docker 容器停止时丢失这些文件,下次运行容器时,您可以直接使用现有的模型,无需重复下载。
如果你在宿主机使用的默认路径下载的模型,由于 xinference cache 目录是用的软链的方式存储模型,需要将原文件所在的目录也挂载到容器内。例如你使用 huggingface 和 modelscope 作为模型仓库,那么需要将这两个对应的目录挂载到容器内,一般对应的 cache 目录分别在 <home_path>/.cache/huggingface 和 <home_path>/.cache/modelscope,使用的命令如下:
docker run\-v</your/home/path>/.xinference:/root/.xinference\-v</your/home/path>/.cache/huggingface:/root/.cache/huggingface\-v</your/home/path>/.cache/modelscope:/root/.cache/modelscope\-p9997:9997\--gpusall\xprobe/xinference:v<your_version>\xinference-local-H0.0.0.0
开始部署:
mkdir /data/xinference & cd /data/xinferencedocker run -d --privileged --gpus all --restart always \-v /data/xinference/.xinference:/root/.xinference \-v /data/xinference/.cache/huggingface:/root/.cache/huggingface \-v /data/xinference/.cache/modelscope:/root/.cache/modelscope \-p 9997:9997 \xprobe/xinference:v1.5.0 \xinference-local -H 0.0.0.0
docker run -d --privileged --gpus all --restart always -v /data/xinference/.xinference:/root/.xinference -v /data/xinference/.cache/huggingface:/root/.cache/huggingface -v /data/xinference/.cache/modelscope:/root/.cache/modelscope -p 9997:9997 xprobe/xinference:v1.5.0 xinference-local -H 0.0.0.0
![]()

到此Xinference部署成功,用http://ip:9997即可访问。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 7716
7716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









