






1.单智能体
连续动作(赛车游戏中方向盘的角度,油门,刹车控制信息,通信中功率控制,可由policy gradient、DDPG、A3C、PPO算法做决策)和离散动作(围棋、贪吃蛇游戏,Alpha Go,可通过算法Q-Learning、DQN、A3C及PPO算法做决策)。
算法分类:
强化学习中有很多算法来寻找最优策略。另外,算法有很多分类。
1、按照有无模型分:有模型(事先知道转移概率P,并且作为输入,算法为动态规划)、无模型(试错,事先不知道转移概率P,算法为:蒙特卡罗算法、Q-Learning、Sarsa、Policy Gradients);
2、基于策略(输出下一步所采取的各种动作的概率,根据概率来采取动作:Policy Gradients)和基于价值(输出所有动作的价值,根据最高价值来选动作,不适用于连续动作:Q-Learning,Sarsa等)(由于基于策略和价值的算法都各有优缺点,由此集合在一起就有了Actor-Critic算法,其中Actor可以基于概率做出动作,而Critic会对做出的动作做出动作的价值,这就在前述的policy gradients上加速了学习过程);
3、单步更新(游戏中每一步都在更新,可以边玩边学习:QLearning、Sarsa、升级版的policy
gradients)和回合更新(游戏开始后,等游戏结束,再总结所有转折点,在更新行为准则:基础版的policy gradients、Monte-carlo learning);
4、在线学习(必须我本人在场,边玩边学:一般只有一个策略,最常见的是e-贪婪,即SARSA算法)、离线学习(从过往的经验里,但是过往的经验没必要是自己的:一般有两个策略,常见的是e-贪婪来选择新的动作,另一个贪婪法更新价值函数,即,常见的Q-Learning)。
5、千万注意,一定要明确不同的强化学习算法的优缺点以便于求解不同类型的问题。比如:Q-Learning适合解决低纬度且离散动作及状态空间,DQN适合解决低纬度动作和高纬度状态空间、DDPG适合求解高纬度(连续)动作空间及状态空间。
产生问题:
1–传统的多智能体RL算法中,每个智能体走势在不断学习且改进其策略。由此,从每个智能体的角度来看,环境是不稳定的,不利于收敛。而传统的单智能体强化学习,需要稳定的环境
2–由于环境的不稳定,无法通过仅改变智能体本身的策略来适应动态不稳定的环境。
3–由于环境的不稳定,无法直接使用经验回放等DQN技巧。
4–因为大量智能体的交互会导致不可避免的反馈开销。更重要的是,生成的马尔可夫过程通常很难处理。用于MDP的数值求解技术遭受所谓的“维数诅咒”,这使它们在计算上不可行。
2.多智能体
(转)
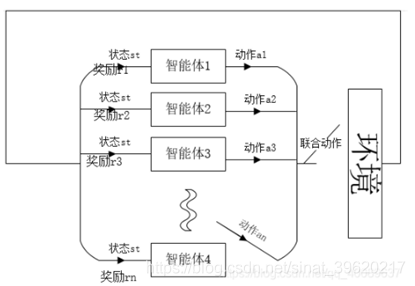
1-如图所示,多智能体系统中至少有两个智能体。另外,智能体之间存在着一定的关系,如合作关系,竞争关系,或者同时存在竞争与合作的关系。每个智能体最终所获得的回报不仅仅与自身的动作有关系,还跟对方的动作有关系。
2-多智能体强化学习的描述:马尔可夫博弈。状态转换符合马尔可夫过程,关系符合博弈。可以表示为<N,S,A,Ri,T>,其中,N表示的是智能体的集合,S表示的是环境的状态空间、Ai表示的是智能体i的动作空间,A=A1A2…An表示为联合动作,R表示智能体i的奖励,T为状态转换函数。
3-一般来说,在马尔可夫博弈中,每个智能体的目标为找到最优策略来使它在任意状态下获得最大的长期累积奖励。
2.1 Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments
论文下载:【https://download.csdn.net/download/sinat_39620217/16203960】
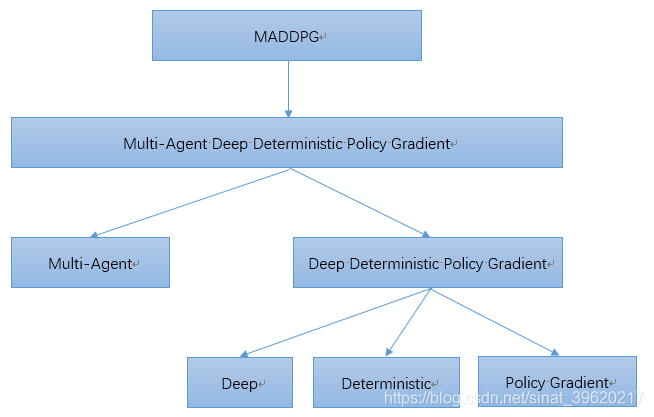
- Multi-Agent:多智能体
- Deep:与DQN类似,使用目标网络+经验回放
- Deterministic:直接输出确定性的动作
- Policy Gradient: 基于策略Policy来做梯度下降从而优化模型
1.不过传统的RL方法,比如Q-Learning或者policy gradient都不适用于多智能体环境。主要的问题是,在训练过程中,每个智能体的策略都在变化,因此从每个智能体的角度来看,环境变得十分不稳定(其他智能体的行动带来环境变化)。对DQN来说,经验重放的方法变的不再适用(如果不知道其他智能体的状态,那么不同情况下自身的状态转移会不同),而对PG的方法来说,环境的不断变化导致了学习的方差进一步增大。
\2. 本文提出的方法框架是集中训练,分散执行的。我们先回顾一下DDPG的方式,DDPG本质上是一个AC方法。训练时,Actor根据当前的state选择一个action,然后Critic可以根据state-action计算一个Q值,作为对Actor动作的反馈。Critic根据估计的Q值和实际的Q值来进行训练,Actor根据Critic的反馈来更新策略。测试时,我们只需要Actor就可以完成,此时不需要Critic的反馈。因此,在训练时,我们可以在Critic阶段加上一些额外的信息来得到更准确的Q值,比如其他智能体的状态和动作等,这也就是集中训练的意思,即每个智能体不仅仅根据自身的情况,还根据其他智能体的行为来评估当前动作的价值。分散执行指的是,当每个Agent都训练充分之后,每个Actor就可以自己根据状态采取合适的动作,此时是不需要其他智能体的状态或者动作的。DQN不适合这么做,因为DQN训练和预测是同一个网络,二者的输入信息必须保持一致,我们不能只在训练阶段加入其他智能体的信息。
\3. DDPG它是Actor-Critic 和 DQN 算法的结合体。
我们首先来看Deep,正如Q-learning加上一个Deep就变成了DQN一样,这里的Deep即同样使用DQN中的经验池和双网络结构来促进神经网络能够有效学习。
再来看Deterministic,即我们的Actor不再输出每个动作的概率,而是一个具体的动作,这更有助于我们连续动作空间中进行学习。
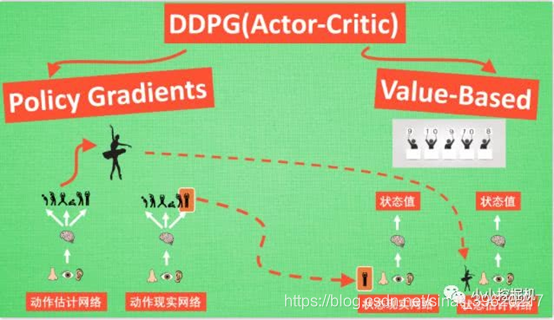
采用了类似DQN的双网络结构,而且Actor和Critic都有target-net和eval-net。我们需要强调一点的事,我们只需要训练动作估计网络和状态估计网络的参数,而动作现实网络和状态现实网络的参数是由前面两个网络每隔一定的时间复制过去的。
我们先来说说Critic这边,Critic这边的学习过程跟DQN类似,我们都知道DQN根据下面的损失函数来进行网络学习,即现实的Q值和估计的Q值的平方损失:

上面式子中Q(S,A)是根据状态估计网络得到的,A是动作估计网络传过来的动作。而前面部分R + gamma * maxQ(S’,A’)是现实的Q值,这里不一样的是,我们计算现实的Q值,不在使用贪心算法,来选择动作A’,而是动作现实网络得到这里的A’。总的来说,Critic的状态估计网络的训练还是基于现实的Q值和估计的Q值的平方损失,估计的Q值根据当前的状态S和动作估计网络输出的动作A输入状态估计网络得到,而现实的Q值根据现实的奖励R,以及将下一时刻的状态S’和动作现实网络得到的动作A’ 输入到状态现实网络 而得到的Q值的折现值加和得到(这里运用的是贝尔曼方程)。

(DDPG)
传统的DQN采用target-net网络参数更新,即每隔一定的步数就将eval-net中的网络参数赋值过去,而在DDPG中,采用的target-net网络参数更新,即每一步都对target-net网络中的参数更新一点点,这种参数更新方式经过试验表明可以大大的提高学习的稳定性。

每个Agent的训练同单个DDPG算法的训练过程类似,不同的地方主要体现在Critic的输入上:在单个Agent的DDPG算法中,Critic的输入是一个state-action对信息,但是在MADDPG中,每个Agent的Critic输入除自身的state-action信息外,还可以有额外的信息,比如其他Agent的动作。
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1370
1370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









