










 该博客提供了一个强化学习的全面指南,包括单智能体和多智能体算法的原理与实战项目。内容涵盖TensorFlow Gym基础、DDPG、DQN等主流算法,以及调参、画图技巧。此外,还涉及趣味项目如超级玛丽和学术应用项目如无人机调度。
该博客提供了一个强化学习的全面指南,包括单智能体和多智能体算法的原理与实战项目。内容涵盖TensorFlow Gym基础、DDPG、DQN等主流算法,以及调参、画图技巧。此外,还涉及趣味项目如超级玛丽和学术应用项目如无人机调度。

【强化学习原理+项目专栏】必看系列:单智能体、多智能体算法原理+项目实战、相关技巧(调参、画图等、趣味项目实现、学术应用项目实现
对于深度强化学习这块规划为:
- 基础单智能算法教学(gym环境为主)
- 主流多智能算法教学(gym环境为主)
- 主流算法:DDPG、DQN、TD3、SAC、PPO、RainbowDQN、QLearning、A2C等算法项目实战
- 一些趣味项目(超级玛丽、下五子棋、斗地主、各种游戏上应用)
- 单智能多智能题实战(论文复现偏业务如:无人机优化调度、电力资源调度等项目应用)
本专栏主要方便入门同学快速掌握强化学习单智能体|多智能体算法原理+项目实战。后续会持续把深度学习涉及知识原理分析给大家,让大家在项目实操的同时也能知识储备,知其然、知其所以然、知何由以知其所以然。

-
专栏订阅(按需选择):
0.tensorflow_gym-强化学习基础入门(推荐新人看)
【二】gym初次入门一学就会—代码详细解析简明教程----平衡杆案例
【四】gym搭建自己的环境,全网最详细版本,3分钟你就学会了!
【五】gym搭建自己的环境之寻宝游戏,详细定义自己myenv.py文件以及算法实现
【六】gym搭建自己环境升级版设计,动态障碍------强化学习
【七】强化学习、gym学习平台扩充,更好的玩转虚拟环境,关于mujoco、mujoco-py、baselines安装配置----待更新------

1.强化学习单智能体算法原理+项目实战
1.1 前置教学:
【一】飞桨paddle【GPU、CPU】安装以及环境配置+python入门教学
【二】强化学习之Parl基础命令–PaddlePaddlle及PARL框架{飞桨}
【三】强化学习之PaddlePaddlle-Notebook、&pdb、ipdb 调试—及PARL框架
1.2 理论知识篇
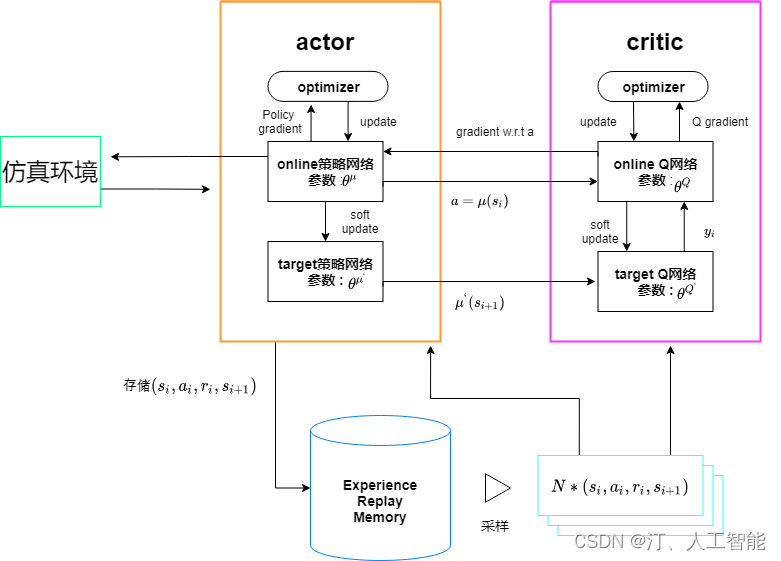
强化学习从基础到进阶-案例与实践[1]:强化学习概述、序列决策、动作空间定义、策略价值函数、探索与利用、Gym强化学习实验
强化学习从基础到进阶-常见问题和面试必知必答[1]:强化学习概述、序列决策、动作空间定义、策略价值函数、探索与利用、Gym强化学习实验
强化学习从基础到进阶-案例与实践[2]:马尔科夫决策、贝尔曼方程、动态规划、策略价值迭代
强化学习从基础到进阶-常见问题和面试必知必答[2]:马尔科夫决策、贝尔曼方程、动态规划、策略价值迭代
强化学习从基础到进阶-案例与实践[3]:表格型方法:Sarsa、Qlearning;蒙特卡洛策略、时序差分等以及Qlearning项目实战
强化学习从基础到进阶-常见问题和面试必知必答[3]:表格型方法:Sarsa、Qlearning;蒙特卡洛策略、时序差分等以及Qlearning项目实战
强化学习从基础到进阶-案例与实践[4]:深度Q网络-DQN、double DQN、经验回放、rainbow、分布式DQN
强化学习从基础到进阶-案例与实践[4.1]:深度Q网络-DQN项目实战CartPole-v0
强化学习从基础到进阶-案例与实践[4.2]:深度Q网络DQN-Cart pole游戏展示
强化学习从基础到进阶-常见问题和面试必知必答[4]::深度Q网络-DQN、double DQN、经验回放、rainbow、分布式DQN
强化学习从基础到进阶-案例与实践[5]:梯度策略、添加基线(baseline)、优势函数、动作分配合适的分数(credit)
强化学习从基础到进阶-案例与实践[5.1]:Policy Gradient-Cart pole游戏展示
强化学习从基础到进阶-常见问题和面试必知必答[5]::梯度策略、添加基线(baseline)、优势函数、动作分配合适的分数(credit)
强化学习从基础到进阶-案例与实践[6]:演员-评论员算法(advantage actor-critic,A2C),异步A2C、与生成对抗网络的联系等详解
强化学习从基础到进阶-常见问题和面试必知必答[6]:演员-评论员算法(advantage actor-critic,A2C),异步A2C、与生成对抗网络的联系等详解
强化学习从基础到进阶–案例与实践[7]:深度确定性策略梯度DDPG算法、双延迟深度确定性策略梯度TD3算法详解
强化学习从基础到进阶–案例与实践[7.1]:深度确定性策略梯度DDPG算法、双延迟深度确定性策略梯度TD3算法详解项目实战
强化学习从基础到进阶-常见问题和面试必知必答[7]:深度确定性策略梯度DDPG算法、双延迟深度确定性策略梯度TD3算法详解
强化学习从基础到进阶–案例与实践[8]:近端策略优化(proximal policy optimization,PPO)算法
强化学习从基础到进阶-常见问题和面试必知必答[8]:近端策略优化(proximal policy optimization,PPO)算法
强化学习从基础到进阶–案例与实践含面试必知必答[9]:稀疏奖励、reward shaping、curiosity、分层强化学习HRL
强化学习从基础到进阶–案例与实践含面试必知必答[10]:模仿学习、行为克隆、逆强化学习、第三人称视角模仿学习、序列生成和聊天机器人
强化学习从基础到进阶–案例与实践[11]:AlphaStar论文解读、监督学习、强化学习、模仿学习、多智能体学习、消融实验
1.3 RL项目实战(本地版含码源)-old
【四】强化学习入门简介—PaddlePaddlle强化学习及PARL框架
【五】强化学习之Sarsa、Qlearing详细讲解----PaddlePaddlle【PARL】框架{飞桨}
【六】强化学习之DQN—PaddlePaddlle【PARL】框架{飞桨}
【七】强化学习之Policy Gradient—PaddlePaddlle【PARL】框架{飞桨}
【八】强化学习之DDPG—PaddlePaddlle【PARL】框架{飞桨}
【九】强化学习之TD3算法四轴飞行器仿真—PaddlePaddlle【PARL】框架
部分效果展示:



基于TD3强化学习算法解决四轴飞行器悬浮任务
基于多智能体(无人机群)路径探索的深度强化学习
1.4 RL项目实战云端+本地版-new
待更新
2.强化学习多智能体原理+项目实战
2.1 理论原理篇
多智能体强化学习算法【一】【MAPPO、MADDPG、QMIX】
多智能体强化学习算法【二】【MADDPG、QMIX、MAPPO】
多智能体强化学习算法【三】【QMIX、MADDPG、MAPPO】
【二】最新多智能体强化学习文章如何查阅{顶会:AAAI、 ICML }
【三】多智能体强化学习(MARL)近年研究概览 {Analysis of emergent behaviors(行为分析)_、Learning communication(通信学习)}
【四】多智能体强化学习(MARL)近年研究概览 {Learning cooperation(协作学习)、Agents modeling agents(智能体建模)}
2.2 MARL项目实战
2.2.1MADDPG
【二】MADDPG多智能体算法实现(parl)【追逐游戏复现】
【三】补发一篇tensorflow下MADDPG环境搭建配置

3.强化学习相关技巧(调参、画图等)
强化学习调参技巧一: DDPG算法训练动作选择边界值_分析解决
强化学习技巧四:模型训练速度过慢、GPU利用率较低,CPU利用率很低问题总结与分析。
强化学习技巧五:numba提速python程序
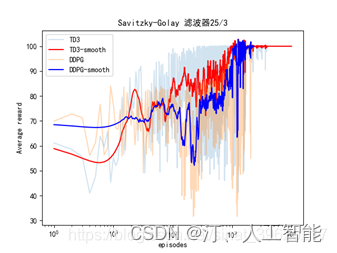
python生成数据曲线平滑处理——(Savitzky-Golay 滤波器、convolve滑动平均滤波)方法介绍,推荐玩强化学习的小伙伴收藏
4.后续趣味项目实现(尝鲜看)
MarLio 马里奥的强化学习冒险






4.学术应用项目实现(计划中)
单智能多智能题实战(论文复现偏业务如:无人机优化调度、电力资源调度等项目应用)
敬请期待


















 1954
1954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











