






在大模型技术走向生产化的过程中,企业在实际落地应用时往往会面临一系列挑战:响应延迟、任务混乱、系统监控不足、业务逻辑与 AI 流程混杂等问题。这些挑战直接影响到用户体验和系统稳定性。为应对这些问题,顶尖大厂通过不断优化架构,总结出了四项关键决策。
本文将结合 Uber、LinkedIn、Elastic、AppFolio 和 Replit 等知名企业的 LangChain 实践案例,从实际落地应用遇到的问题出发,详细解析这四个决策如何有效提升企业级 AI 助理的性能和可靠性。
实际落地大模型面临的挑战
- 实时响应瓶颈: 在高并发和大数据处理场景下,同步执行引擎容易出现阻塞,导致整体响应速度下降。
- 任务分解难题: 单一代理在处理复杂、跨部门的任务时往往力不从心,容易造成任务混淆和错误率上升。
- 监控与故障排查不足: 传统日志系统在大规模向量检索和数据分析过程中,难以捕捉到所有细微问题,导致故障难以及时定位。
- 业务与 AI 混杂: 业务逻辑(如订单管理、数据查询)与 AI 流程(如自然语言处理)的混合使用,极大增加了系统复杂度和维护难度。
针对上述痛点,顶尖企业提出了四个架构决策,既解决了实际问题,也为构建高效、稳定的企业级 AI 助理奠定了基础。
四个关键决策
决策一:异步流水线化执行引擎
场景痛点
在高并发实时响应场景中,传统的同步执行引擎往往会陷入阻塞。当系统需要依赖多个异步操作时,任何一个操作的延迟都可能拖慢整个流程。Uber 的开发平台 AI 团队在大规模代码迁移和数据查询时,就曾遭遇这一问题,严重影响了系统吞吐量和用户体验。

解决方案
采用 LangChain 的 AsyncPipeline,实现异步流水线化执行,引入并行处理机制,从而大幅提升系统响应速度。
from langchain_core.runnables import RunnableSequence
from langchain_core.language_models import BaseChatModel
from langchain_core.prompts import ChatPromptTemplate
# 创建异步组件
prompt = ChatPromptTemplate.from_template("Hello, {name}")
model = ChatModel() # 假设是一个支持异步的模型
# 构建异步管道
async_pipeline = prompt | model
# 使用 ainvoke 进行异步调用
result = await async_pipeline.ainvoke({"name": "World"})
# 使用 astream 进行异步流式输出
async for chunk in async_pipeline.astream({"name": "World"}):
print(chunk)
# 获取异步事件流
async for event in async_pipeline.astream_events({"name": "World"}, version="v2"):
print(event)
实际案例
Uber 的开发平台 AI 团队借助异步流水线化引擎,有效缓解了大规模操作中因单点延迟导致的阻塞问题,从而在处理代码迁移和实时数据查询时取得了显著性能提升。
决策二:使用代码维度可控的代理架构
场景痛点
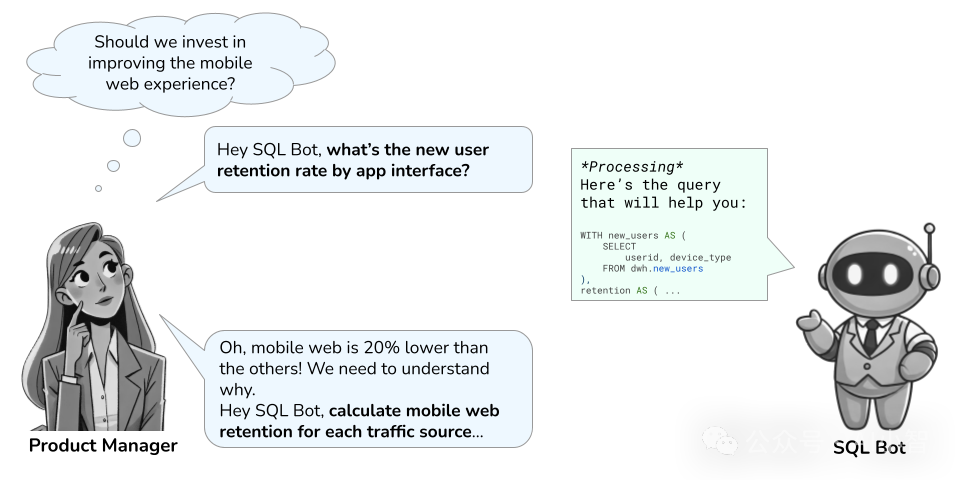
在跨部门数据查询和复杂任务场景中,单一代理难以同时满足多任务需求,容易造成任务混淆与执行错误。LinkedIn 在内部推出的 SQL Bot 正是为了解决这一问题,通过多代理协同,实现了自然语言转 SQL 的高效分工和协作。
解决方案
使用 LangChain 的 AgentExecutor,构建可控的多代理架构。通过规划代理、研究代理和工具调用代理的协同配合,实现任务的合理分解与高效执行。
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain_openai import ChatOpenAI
from langchain import hub
# 选择语言模型
llm = ChatOpenAI(temperature=0)
# 获取提示模板
prompt = hub.pull("langchain-ai/openai-functions-template")
# 准备工具
tools = [...] # 您需要的工具列表
# 创建代理
agent = create_openai_functions_agent(llm, tools, prompt)
# 创建 AgentExecutor
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True, # 可选:显示详细执行过程
max_iterations=5 # 可选:限制最大迭代次数
)
# 单次调用
result = agent_executor.invoke({"input": "您的任务描述"})
# 流式调用(显示中间步骤)
for chunk in agent_executor.stream({"input": "您的任务描述"}):
print(chunk)

实际案例
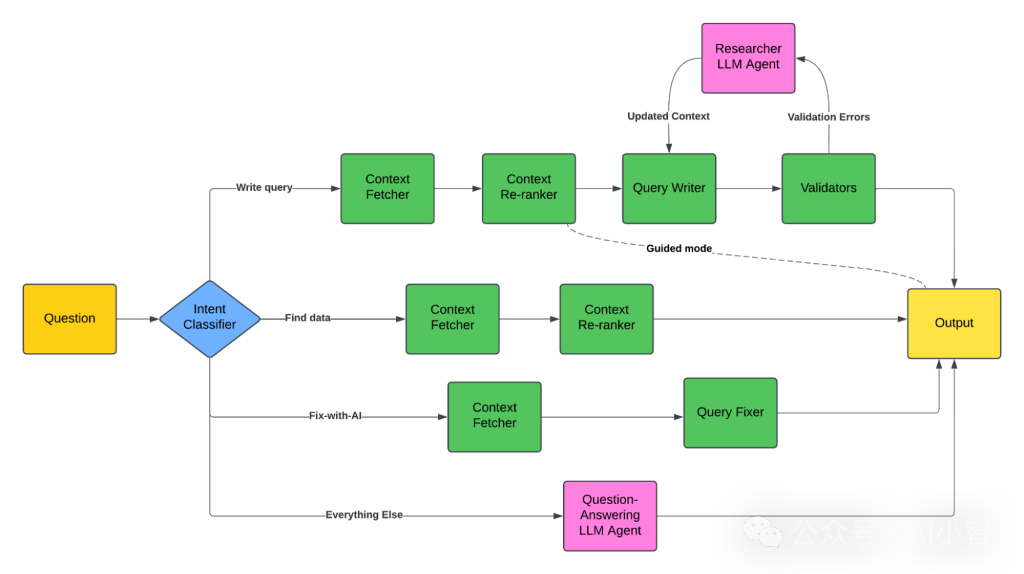
LinkedIn 的 SQL Bot 通过多代理架构,将自然语言解析、查询生成和错误修正等各个环节分工协作,大大提升了跨部门数据访问的效率和准确率,使得员工能够在权限范围内便捷地获取数据洞察。
决策三:可观测性增强框架
场景痛点
在大规模向量检索和日志分析过程中,传统日志体系往往难以及时捕捉到细微的性能问题,导致故障定位困难和系统响应下降。Elastic 的 AI 助手在实际应用中就曾面临此类挑战。
解决方案
利用 LangSmith 的 Tracer 实现系统全链路的实时监控和故障排查,帮助开发者快速定位和解决问题,保障系统稳定运行。
# 设置 LangSmith 跟踪
os.environ["LANGSMITH_TRACING"] = "true"
os.environ["LANGSMITH_API_KEY"] = "<YOUR-API-KEY>"
os.environ["LANGSMITH_ENDPOINT"] = "https://api.smith.langchain.com"
# LangChain 自动集成
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(temperature=0)
response = chat.predict("你好")
# 自动在 LangSmith 记录跟踪信息
# 创建评估
from langsmith import Client
client = Client()
dataset = client.create_dataset("my_dataset")
实际案例
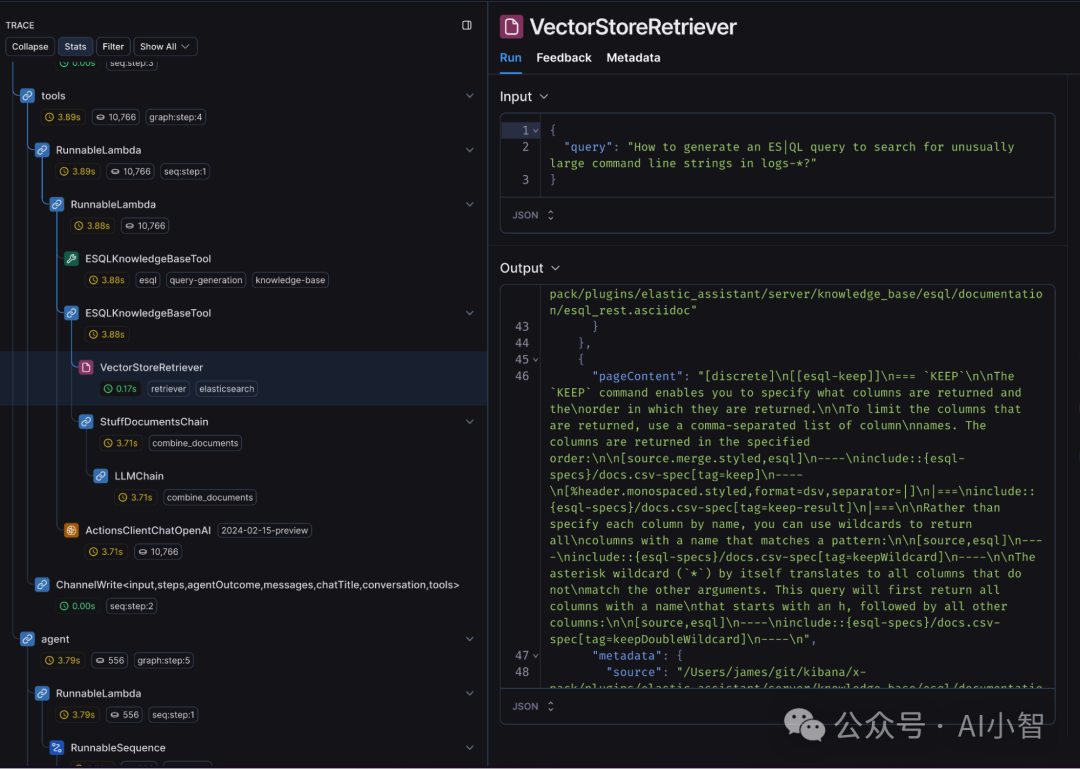
Elastic 在其 AI 助手中引入了增强型可观测性框架,通过详细的追踪数据,实现了对向量检索及数据处理流程的全局监控,确保了系统在高并发场景下依然能够高效运行。
决策四:隔离精确型业务与 AI 流程驱动
场景痛点
在某些垂直行业中,如房地产管理,精确型业务逻辑(如订单管理、账单处理)与 AI 流程(如自然语言交互)的混合,往往会增加系统复杂性和维护成本。AppFolio 的 AI 助手 Realm-X 就曾遇到这一困境。
解决方案
通过 LangChain 的 APIWrapper,将业务逻辑封装成独立的 API 服务,实现与 AI 流程的有效隔离,从而降低系统耦合度并提高维护效率。
from langchain.tools import BaseTool
from typing import Optional, Dict, Any
class MyCustomAPIWrapper(BaseTool):
base_url: str
api_key: Optional[str] = None
def _make_request(self, endpoint: str, params: Dict[str, Any] = None):
# 实现具体的 API 请求逻辑
import requests
headers = {
"Authorization": f"Bearer {self.api_key}" if self.api_key else None
}
response = requests.get(
f"{self.base_url}/{endpoint}",
headers=headers,
params=params
)
return response.json()
def _process_response(self, response):
# 处理 API 响应
if response.get("error"):
raise ValueError(f"API Error: {response['error']}")
return response.get("data")
def run(self, query: str) -> str:
# 主要执行方法
try:
params = {"query": query}
raw_response = self._make_request("search", params)
processed_response = self._process_response(raw_response)
return processed_response
except Exception as e:
return f"Error occurred: {str(e)}"
from langchain.agents import initialize_agent, AgentType
from langchain_openai import ChatOpenAI
# 创建 API Wrapper 实例
api_wrapper = MyCustomAPIWrapper(
base_url="https://api.example.com",
api_key="your_api_key"
)
# 创建 LLM
llm = ChatOpenAI(temperature=0)
# 创建代理
agent = initialize_agent(
tools=[api_wrapper],
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION
)
# 执行查询
result = agent.run("使用我的 API Wrapper 执行搜索")
实际案例
AppFolio 的 Realm-X 将订单管理、账单处理等精确型业务通过独立 API 进行封装,与自然语言处理等 AI 流程实现解耦。这种设计使得系统在应对复杂客户需求时更为稳定、高效,并大幅降低了后续维护难度。
结论
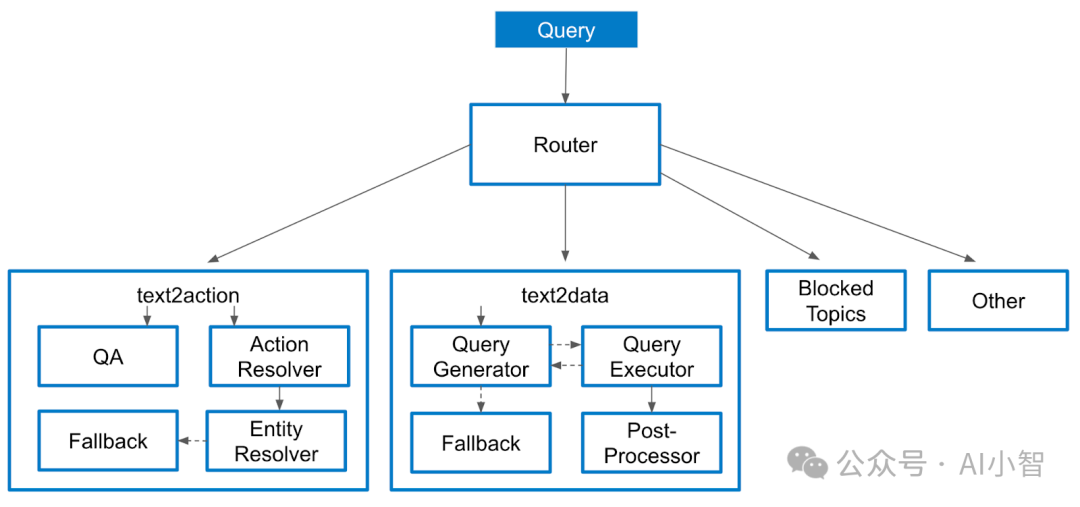
企业在构建 AI 助手的过程中,必须面对诸多实际落地的挑战。顶尖大厂通过采用异步流水线化执行、多代理协同、可观测性增强、业务逻辑隔离这四项关键决策,成功解决了响应延迟、任务混乱、监控不足、业务与 AI 混合难题以及缓存瓶颈等问题。Uber、LinkedIn、Elastic、AppFolio 和 Replit 等实践案例充分证明了这些架构决策的有效性。随着大模型技术的不断成熟,这些设计理念必将为更多行业带来革命性的变革,为企业级 AI 助手的发展指明方向。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









