






你真懂Transformer吗?
我不知道点开这篇文章的同学们;
有多少敢说自己完全学会并理解了Transformer模型。
反正根据我的讲课经验和开发经验;
我敢说100个宣称自己学过Transformer的同学;
真理解Transformer的,可能不足10人。
甚至哪怕你发了一篇基于Transformer的论文;
或者微调了一个基于Transformer的模型;
但对于一些基础问题,可能也没法思路清晰的完整回答出来。
不信,咱们就试试**~ _**
问题1:
任何深度学习模型,都要讨论模型的训练流程和推理计算流程。
那么对于Transformer模型;
在“训练模型的过程中”与“训练完成后使用模型进行推理计算时”;
对于这两个流程,具体有哪些不同的地方呢?
请基于Transformer模型的推理模式,即自回归,Autoregressive模式;
与Transformer模型的训练模式,即教师强制,Teacher Forcing模式;
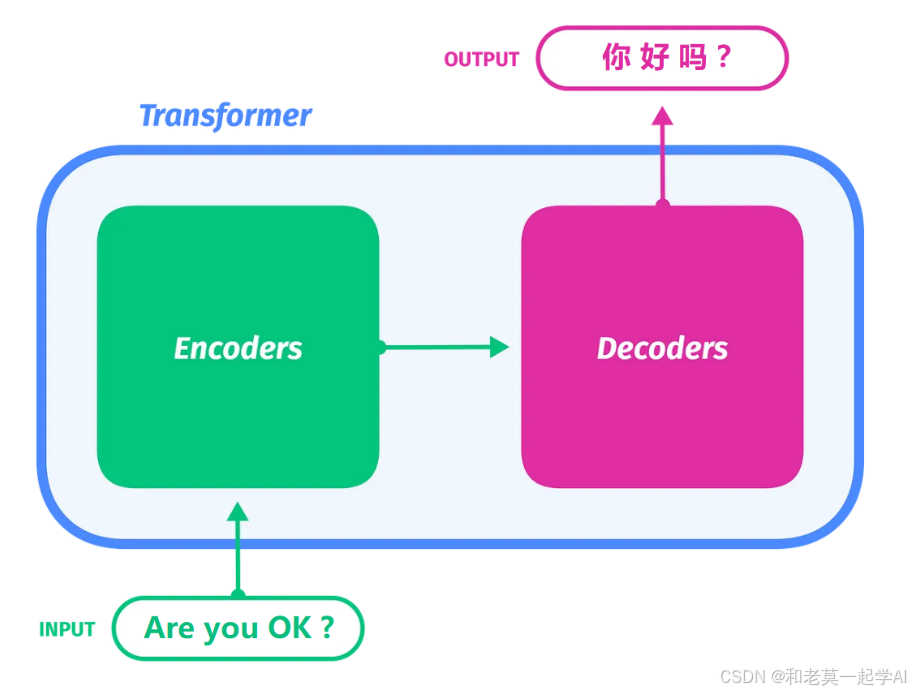
在英译汉机器翻译问题的业务场景下,深入回答这个问题。
问题2:
观察Transformer会看到3个橙色的矩形,它们是多头注意力模块;
这个矩形的下方,有三个分叉,对应了Q、K、V。
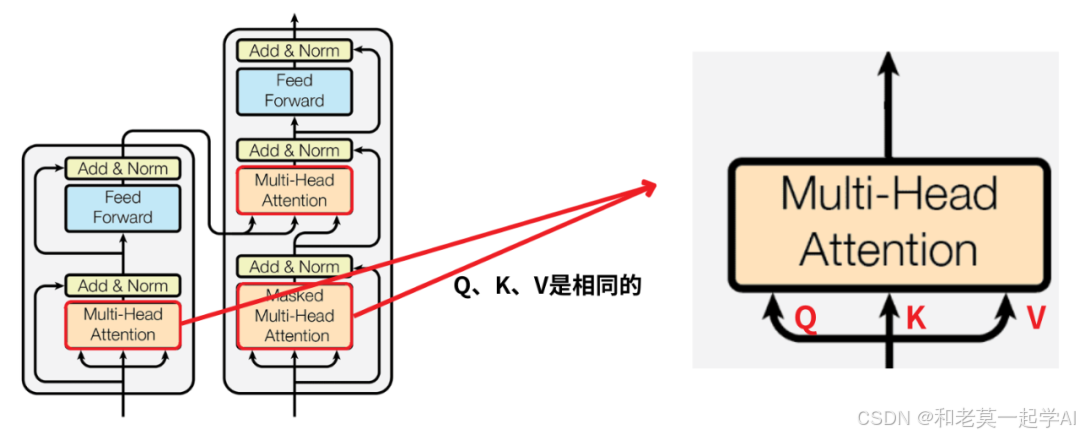
我们会发现,下面两个橙色的多头注意力的Q、K、V输入,都是一样的。
而右上方的橙色矩形的3个输入,也就是那3个分叉;
其中两个来自于左边的编码器,用红色圈标记;
一个来自于下方的解码器,用蓝色圈标记。
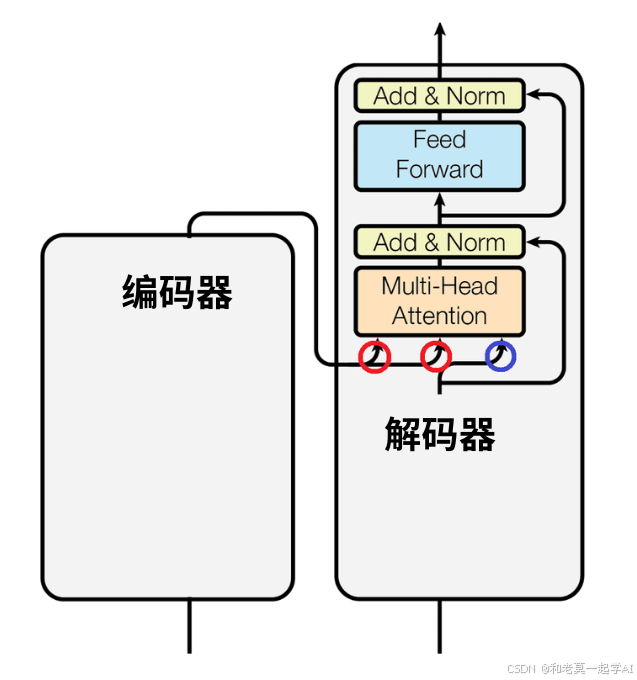
我的问题是,对于这三个分叉,谁是Q、谁是K、谁是V?
换句话说,蓝色圈标记的那个分叉,是Q、是K,还是V?
请基于Scaled Dot Product Attention,深入回答这个问题。
再多的问题,我就不问了。
上面这两个问题,如果同学们能思路清晰的回答出来;
那就说明同学们真正理解了Transformer。
实际上,问题1和问题2,它们分别从宏观和微观的角度;
对Transformer背后的原理提出了问题。
对于刚刚初学Transformer的同学;
需要先宏观的了解Transformer的工作原理;
再微观的研究Transformer中每个组件的计算过程和细节。
接下来,我就以第1个问题为前提,给大家讲讲Transformer。
帮助同学们快速了解Transformer是如何工作的。
讲解包括了3个部分:
1.基于“英译汉”机器翻译任务;
快速认识Transformer。
2.详细讨论,Transformer的推理模式;
即自回归,Autoregressive模式。
3.详细讨论,Transformer的训练模式;
即教师强制,Teacher Forcing模式。

1.快速认识Transformer
我们以“英译汉”机器翻译任务为前提来说明Transformer。
首先绘制一个简洁版的Transformer模型架构图:
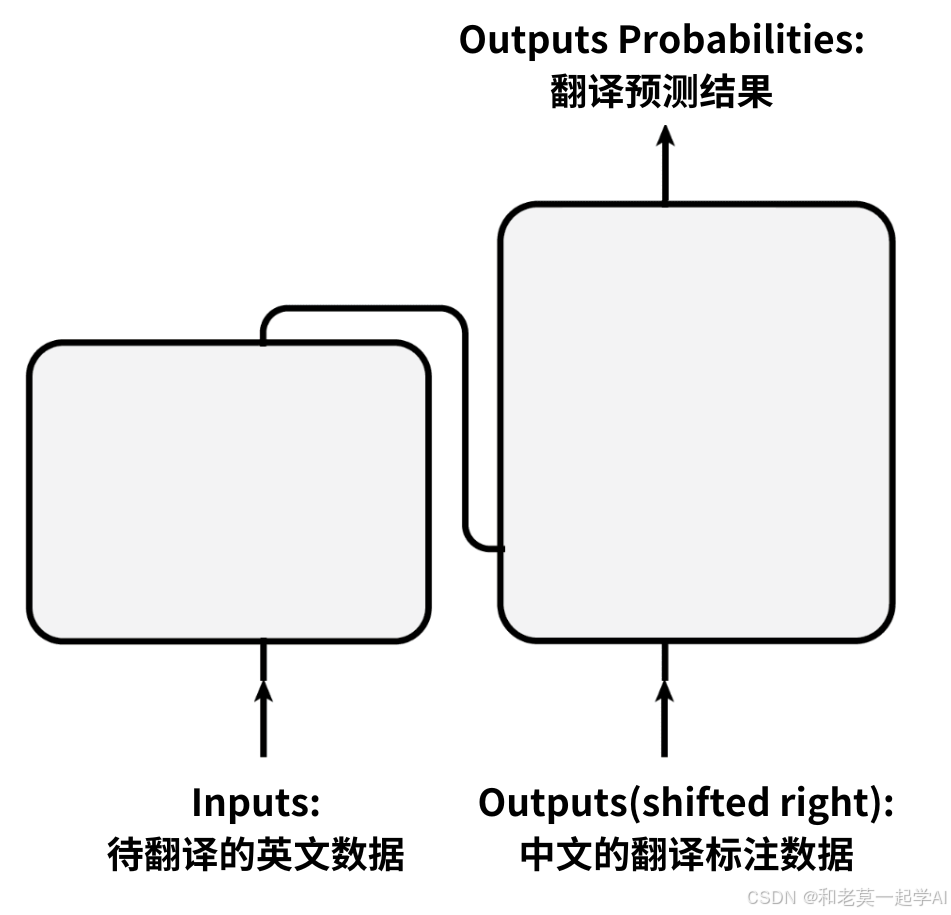
这个架构图只表现出Transformer的大体结构和输入、输出数据;
忽略掉了Transformer模型中包含的各个具体的组件;
将Transformer模型看做是一个整体,进行讨论。
举例说明:
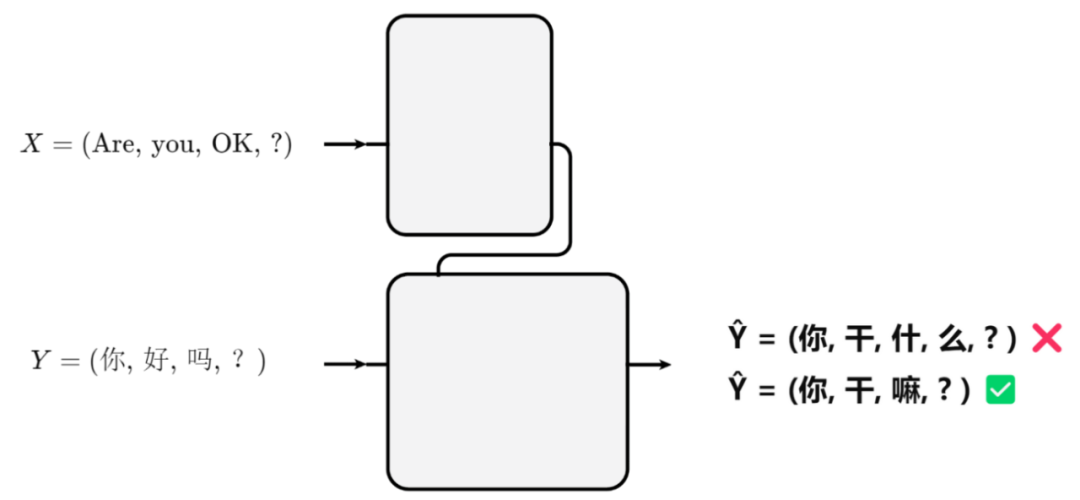
设待翻译的英文数据是“Are you OK ?”;
中文的翻译标注数据是“你好吗?”;
它们会从模型的左下方“Inputs”和右下方“Outputs shifted right”;
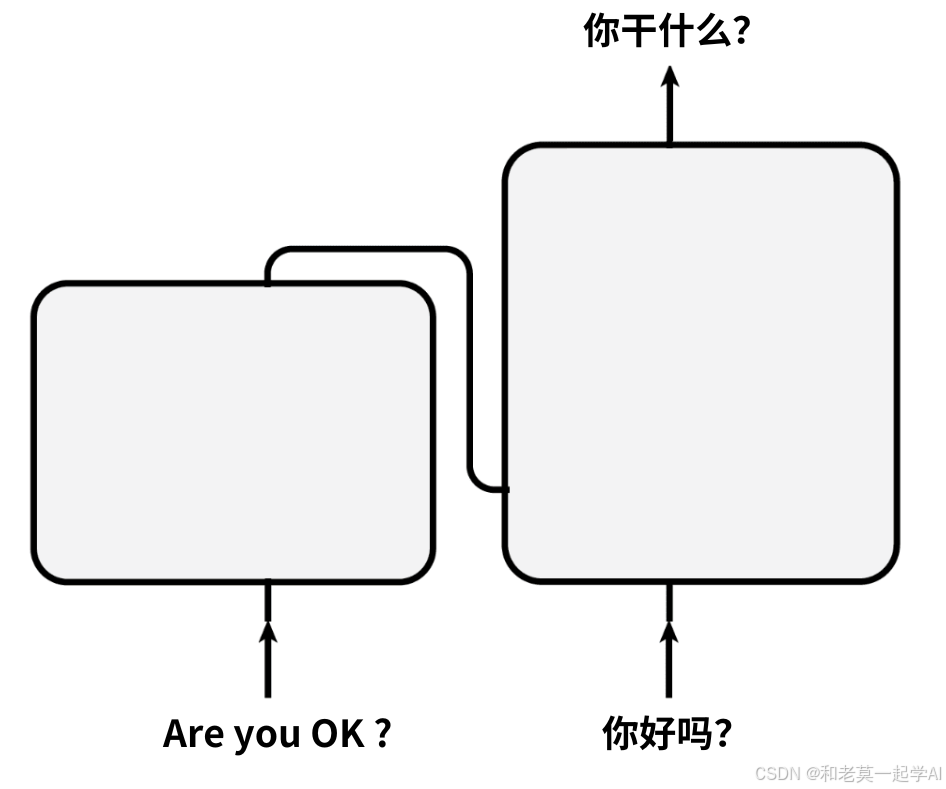
这两个位置进入模型。
因此下方的“Inputs”和“Outputs”,是模型的数据输入位置。
经过模型的推理计算,假设模型的翻译预测结果是“你干什么?”;
那么它会从模型的右上方Outputs位置输出。
这里我故意将模型的翻译输出写错;
从而更明确的表示上方的输出才是模型的预测结果。
特别说明:
严格来说“Are you OK?”、“你好吗?”、“你干什么?”;
这两组输入和一组输出是无法如上图中一样,同时出现的。
我此时只是用这个例子,帮助同学们快速认识Transformer。
总结来说,整个Transformer由两部分组成:
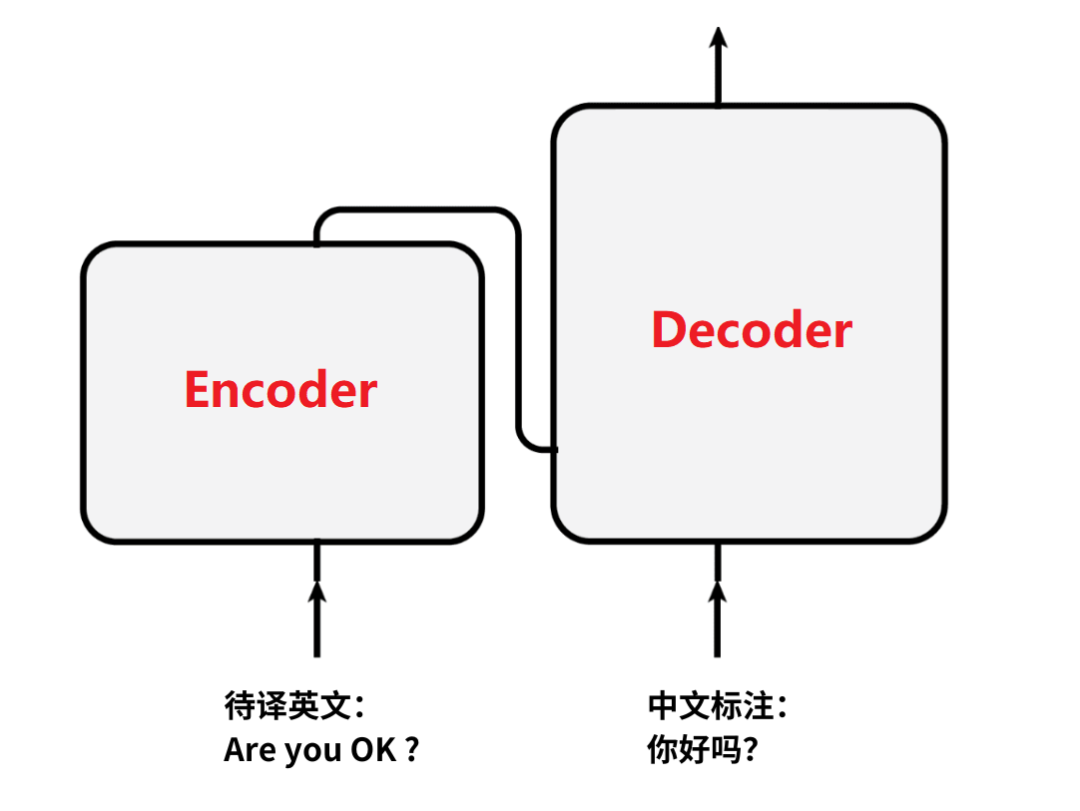
左侧的矩形结构,被称为“Encoder编码器”;
右侧的矩形结构,被称为“Decoder解码器”。
初学时,我们不必深究Encoder和Decoder内部到底是如何工作的;
我们只需要知道,Encoder用来接收并处理“待译英文”数据;
Decoder用来接收并处理“中文标注”数据,就可以了。
下面,我们要重点研究Transformer的2种不同的工作模式:
自回归的推理模式和教师强制的训练模式。
2. 自回归的推理模式
理解“自回归的推理模式”是理解“教师强制的训练模式”的前提。
我们需要知道,在使用“自回归推理”时;
Transformer模型已经完成了训练。
我们要使用模型中的参数,对未知的数据进行推理计算。
例如,对于英译汉问题,就是根据未知的英文;
使用已训练的Transformer模型,将英文推理计算为中文翻译结果。
因此在“推理模式”时,我们并不知道英文的准确翻译结果。
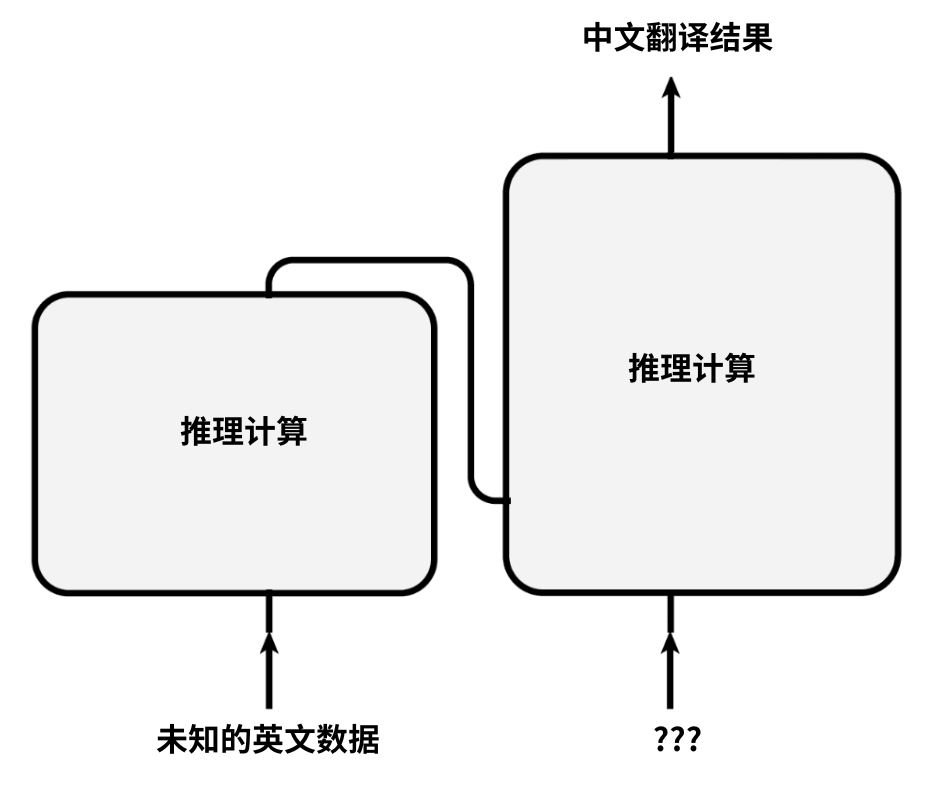
也就是模型的右下角,问号标记的位置;
一开始并没有可以输入的中文标注数据。
同学们此时可以想一想,这个**???**位置应该输入什么样的数据呢?
“自回归的推理模式**”实际上是一个循环的过程。**
第1次循环:
首先,待译英文是“Are you OK ?”,它仍然会从模型下方的左侧位置输入。
不同于训练阶段,在推理时,模型的右下方,不会有完整的中文标注数据输入。
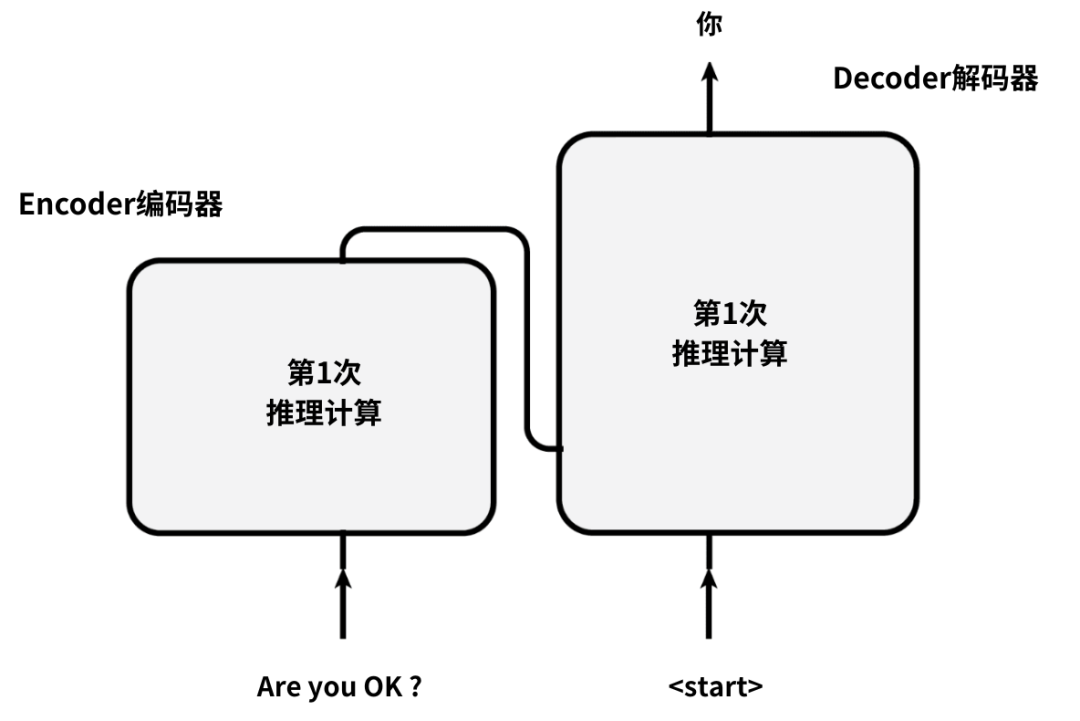
最开始只有一个特殊的起始符号;
例如,输入进来。它会提示模型此时已开始中文翻译工作。
Transformer模型的Encoder,会接收并处理左侧的英文输入;
Transformer模型的Decoder,会接收并处理右侧的起始符号。
然后经过Encoder和Decoder的共同努力;
Transformer就会完成了第一次推理计算。
如果此时模型算对了;
就会看到模型整体计算出了中文翻译结果中的第一个单词:“你”。
这里要特别说明:
因为待翻译的英文后面也不会发生变化;
所以对于左侧的英文的编码计算工作,只会进行一次计算。
第2次循环:
对于待翻译的英文“Are you OK ?”的计算,会直接使用刚刚的计算结果。
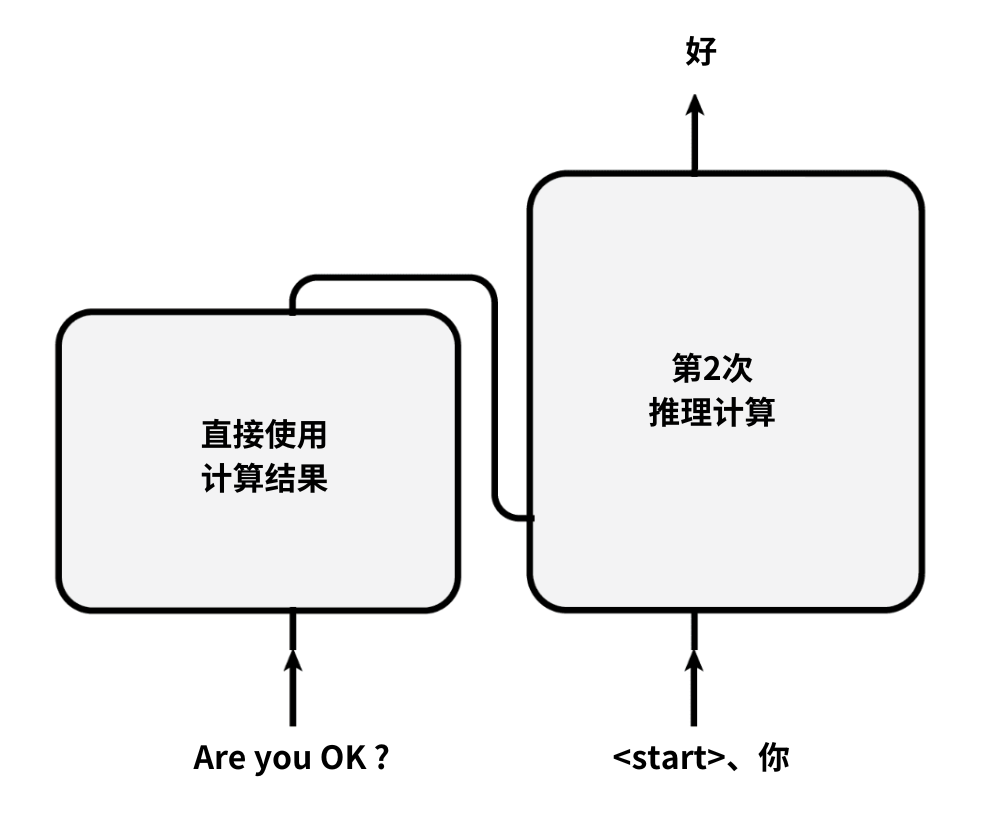
将起始符号和生成的“你”;
一起作为输入,输入至模型;
并生成第2次推理计算的结果“好”。
第3次循环:
实际上我们只需要考虑右侧的Decoder的循环工作过程;
因此我们可以将左侧的矩形框Encoder省略掉。
按照同样的方式,进行第3次推理计算:
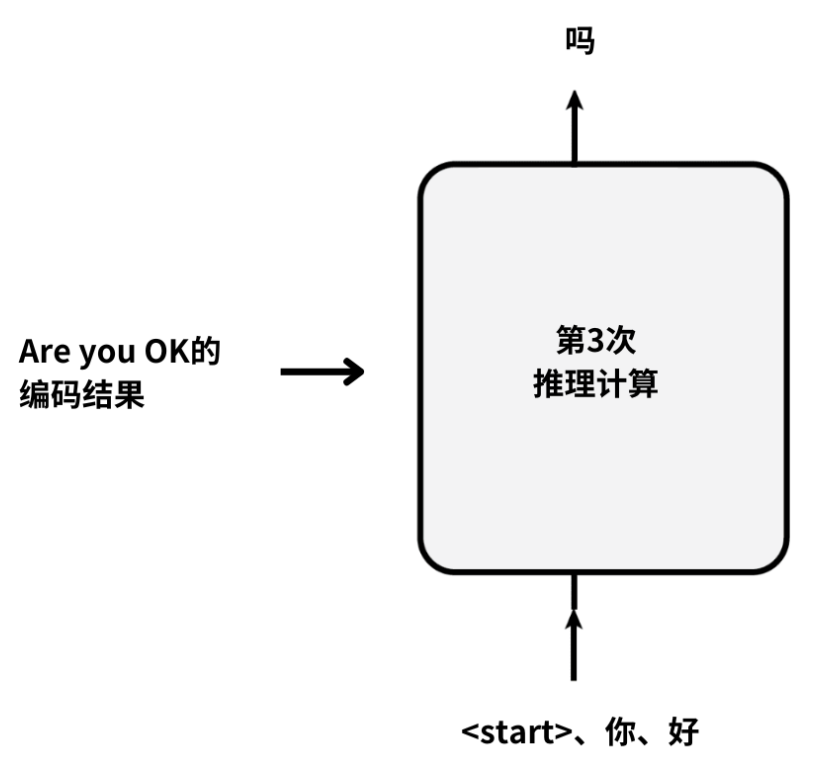
根据“”、“你”、“好”,计算出“吗”。
继续按照这样的计算流程,进行n轮推理计算。
当模型的右上方,生成了预先定义的特殊结束符号时:
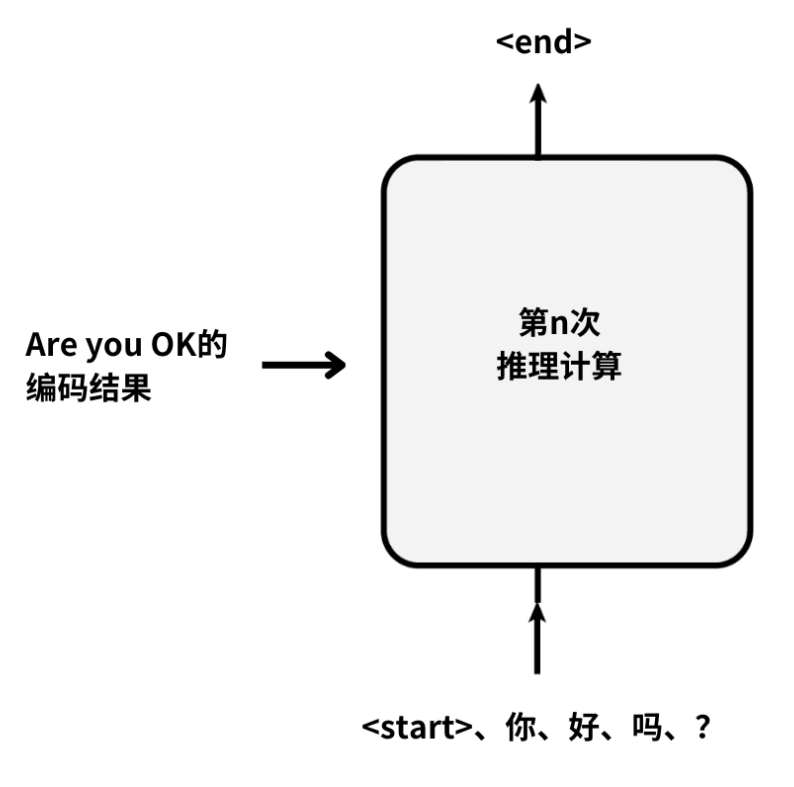
例如,就说明Transformer的推理计算完成了,不再需要下一次计算。
总结
“自回归的推理模式”就是基于之前的计算结果,推理后续的计算结果。
换句话说,在模型逐步生成输出序列的过程中;
其中的每一步产生的生成结果,都会依赖于之前已生成的结果。
如果疏略掉“自回归”中的循环进行输入输出的过程:

那么Tranformer就是基于“Are you OK ?”和“”;
生成了翻译结果,“你 好 吗 ?”。
3.Transformer 的基本训练流程
我们先不讨论Transformer的教师强制训练模式。
单纯将Transformer看作是一个普通的深度学习模型;
思考这个模型的基本训练逻辑。
训练一个深度学习模型;
就是要想办法,计算出“模型推理结果y^”和“人工标注数据y”之间的误差。
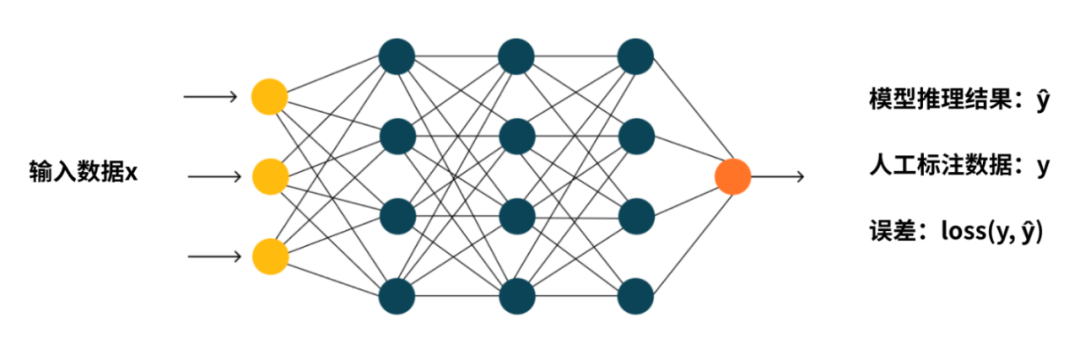
然后尽可能找出使“误差”最小的模型参数。
其中“误差”使用“损失函数loss”基于y和y-hat计算。
下面我们将Transformer前向传播的推理过程,看作是一个整体来考虑。
前向推理:
输入x对应了“Are you OK ?”;
预测结果是“你干什么?”,它对应了y^。
相比其他深度学习模型,Transformer最特殊的地方在于;
标记值Y“你好吗”也需要作为输入,输入到神经网络中。
相当于每次训练Transformer时;
Transformer会将“Are you OK ?”和“你好吗?”;
一起推理为“你干什么?”。
需要注意的是:
这个例子并不能体现真正的训练过程。
因为在教师强制的训练模式下;
是不可能出现“你干什么?”,这种预测结果的。
因为其中Y^和Y的长度,一定是一样的。
换句话说,在训练时,模型有可能预测出“你干嘛?”;
因为它的长度和“你好吗?”一样。
但模型一定预测不出“你干什么?”。
一会等我具体讲到“教师强制”后,同学们就理解我此时为什么这么说了。
计算损失:
然后我们要做的就是计算出中文标注“你好吗?”;
和模型预测“你干嘛?”之间的损失loss了。
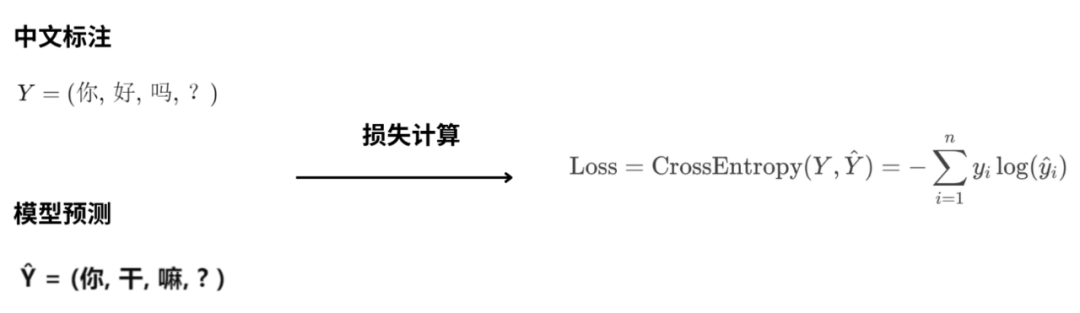
loss描述了中文标注Y“你好吗?”;
和预测值Y^“你干嘛?”之间的差异;
这个差异会使用交叉熵误差CrossEntropy进行计算。
梯度下降:
当计算出loss后,要继续计算loss关于Transformer模型中参数θ的梯度:
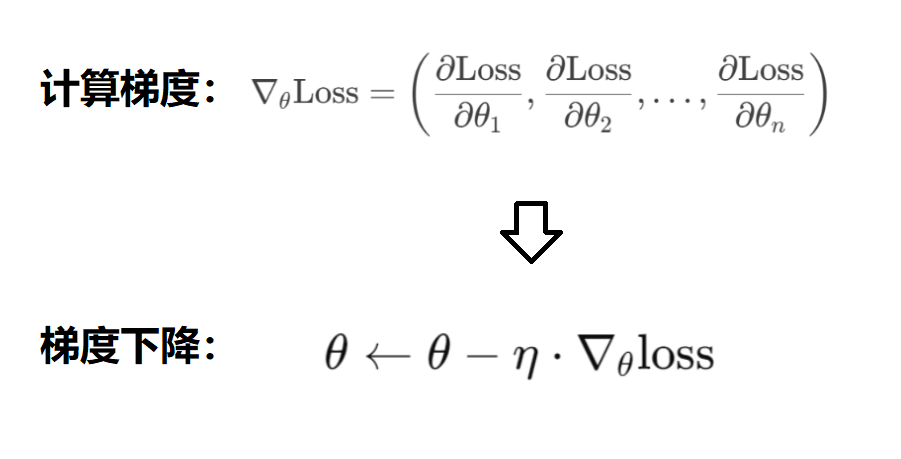
然后使用梯度下降算法,更新这些参数θ。
当完成前向推理、损失计算和梯度下降三个步骤后;
就完成了1次深度学习模型的迭代。
4. 教师强制,Teacher Forcing模式
“教师强制的前向推理”与“自回归的前向推理”,它们的底层逻辑是一样的。
不同的地方在于,“自回归”的前向推理是一个循环过程。
而“教师强制的前向推理”,是基于不同长度的真实标签,“分别”进行推理。
具体举个例子。
设一组标注,待译英文是“Are you OK ?”,中文标注是“你好吗?”。
在计算前,我们需要会先将标注“你好吗?”添加和,对应起始和结束标记。
接着构造出表格中的5组训练数据:
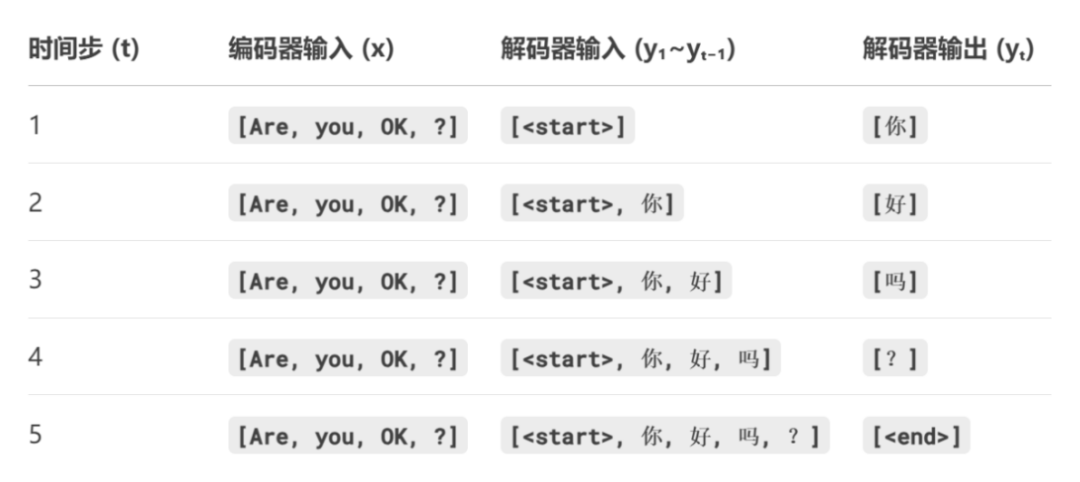
这5组训练数据,也被称为“5个时间步”的训练数据。
仔细观察表格:
第1列,时间步t:
它和第3列,解码器输入序列y的长度相同。
第2列,编码器的输入x:
每个x都一样,为are you ok?。
第3列,解码器的输入序列:
y的下标是1~t-1,表示预测第t个时间步的单词yt,需要1到t-1时间步的历史信息。
第4列是解码器输出:
也就是第t个时间步的预测标签。
以第2个时间步举例说明:
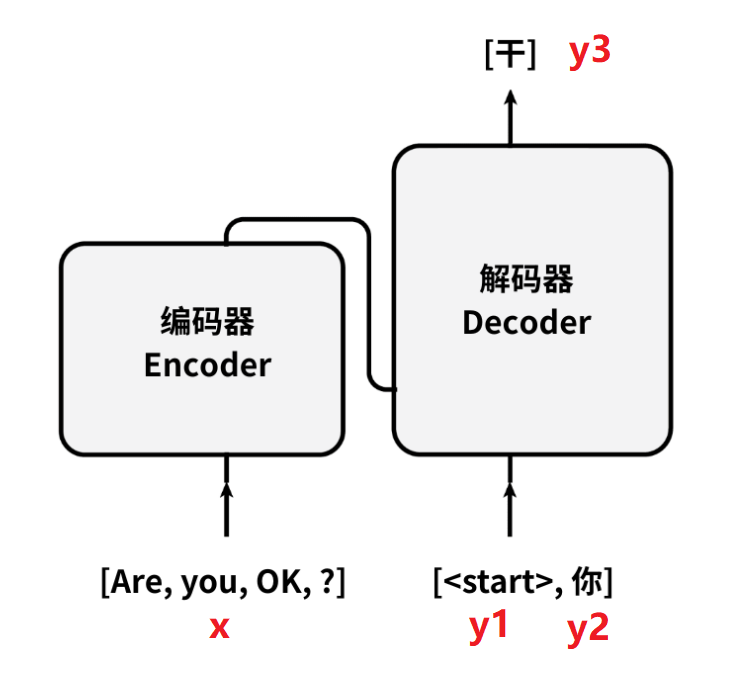
x“Are you OK ?”从左下方输入;
解码器输入长度是2,也就是y1、y2;
对应了“”和“你”,它们从右下方输入;
解码器输出为y3,对应“好”字。
如果此时模型预测出“干”字。
这说明模型预测错了,我们要优化预测值“干”和标注“好”之间的损失。
接着基于这个例子继续说明“教师强制”:

我们会看到解码器的每一步输入,也就是y1到y(t-1)这一列,实际上都是标注数据中的词语。
比如输出了“干”;
但对于第3个时间步;
在训练时仍然会使用“Are you OK ?”和“ 你 好”作为输入,去预测“吗”。
所以第2个时间步的错误输出“干”;
只是第2个时间步的输出。
它不会影响第3个时间步的训练时的输入。
因此解码器强制使用了正确的数据作为输入,就被称为“教师强制”。
在使用“教师强制”时,可以不用担心某一个时间步出错,影响到后面的计算。
换句话说,如果没有“教师强制”,就很可能越错越离谱。
整体来说:
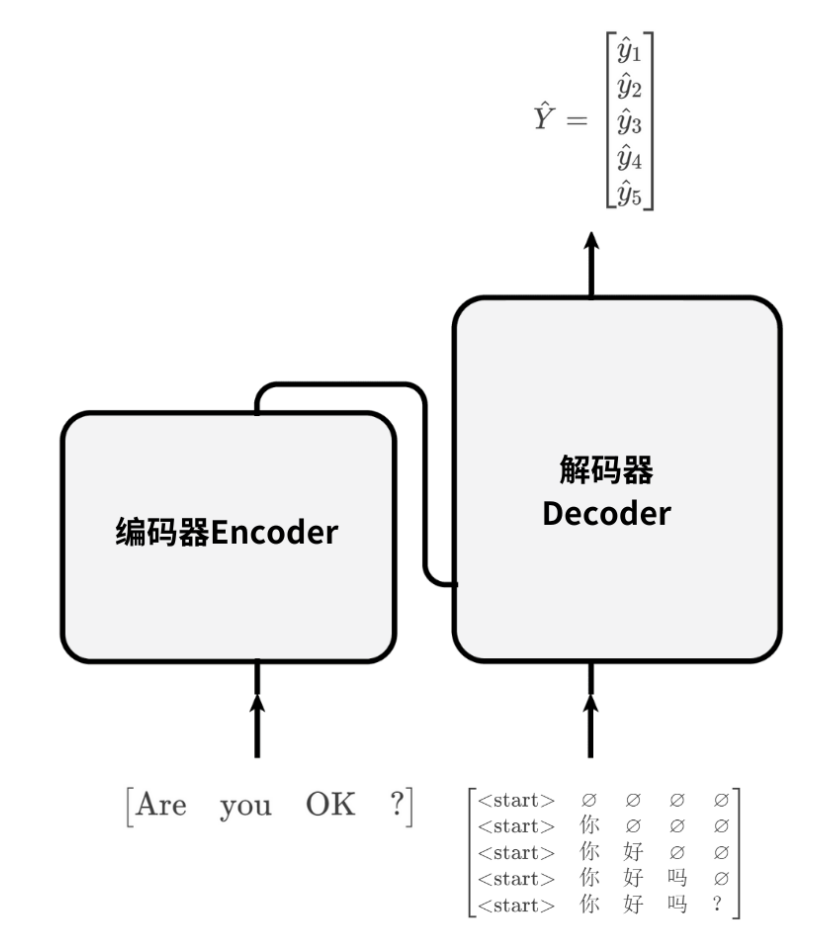
Are you OK会被输入至编码器;
输入给解码器的数据可以看做是下三角矩阵;
模型的预测结果是一个列向量y-hat。
标签值是列向量Y,其中保存了“你、好、吗、?、”。
最终我们要计算所有时间步的:

Y与y-hat之间的损失loss。
这里需要说明的是:
输入至解码器的下三角矩阵形式的数据;
并非是真实意义的下三角矩阵数据。
它的本质仍然是一行数据:
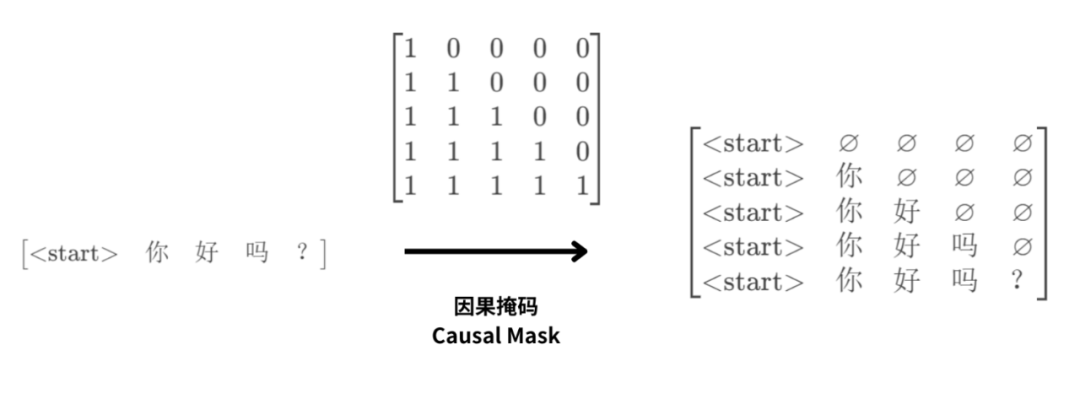
只不过会通过因果掩码矩阵,在计算注意力的时候体现处理。
说到这,本期视频也就结束了。
大家是不是已经学懂了Transformer呢?
对了,别忘了还有个问题2。
在解码器上方的多头自注意力机制中:
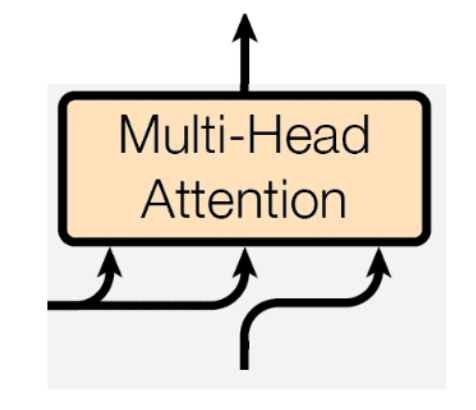
对于三个输入分叉,到底谁是Q、谁是K、谁是V?
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









