






本文是《深度学习进阶:自然语言处理》、《神经网络与深度学习》和《动手学深度学习》的读书笔记。本文将介绍基于Numpy的循环神经网络的前向传播和反向传播实现,包括RNN和LSTM。
一、概述
1.1 循环神经网络(RNN)
循环神经网络(Recurrent Neural Networks, RNN) 是一类具有短期记忆能力的神经网络,其特点是在处理序列数据时,能够记录历史信息。RNN已广泛地用于序列相关的任务上,例如语言模型、自然语言生成、机器翻译、文本分类、序列标注、语音识别、时间序列分析等。
RNN可以被理解为一种迭代地利用当前时刻信息及历史信息来更新短期记忆的网络。通过数据的循环,RNN能一边记住历史的信息,一边更新到最新的信息(本文用RNN代指简单的循环神经网络)。
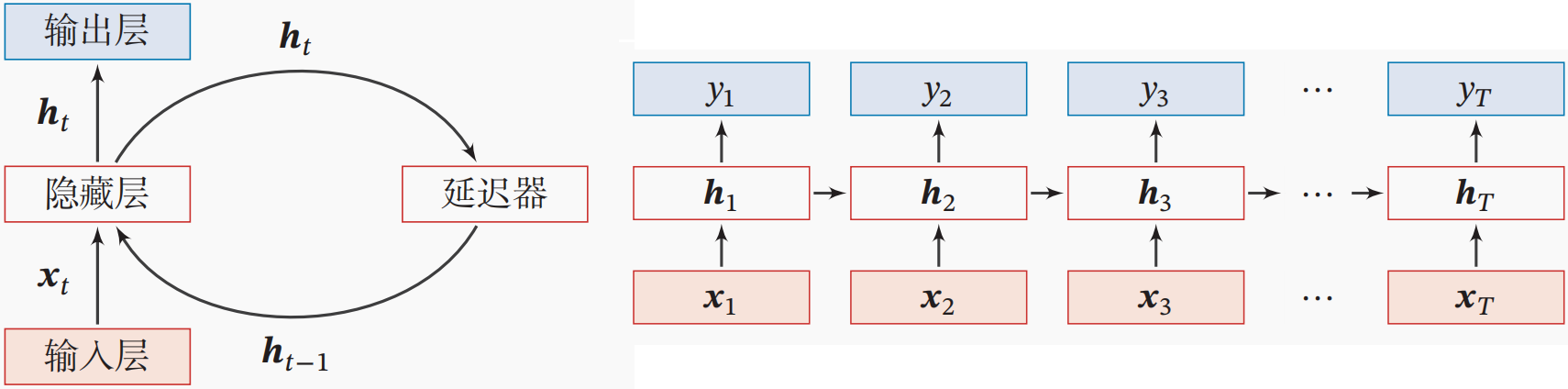 RNN通常按时间展开其计算图以便于理解其计算过程,具体如上图所示。具体地,RNN是一个非常简单的循环神经网络,它只有一个隐藏层。RNN在时刻\(t\)的更新公式如下所示:
RNN通常按时间展开其计算图以便于理解其计算过程,具体如上图所示。具体地,RNN是一个非常简单的循环神经网络,它只有一个隐藏层。RNN在时刻\(t\)的更新公式如下所示:
\[\mathbf{h}_t = \tanh \left( \mathbf{h}_{t-1}\mathbf{W}_{\text{h}} + \mathbf{x}_t \mathbf{W}_{\text{x}} + \mathbf{b} \right) \]
其中,向量\(\mathbf{h}_t \in \mathbb{R}^{1 \times d}\)为RNN的隐藏状态,而\(\mathbf{x}_t \in \mathbb{R}^{1 \times m}\)是网络在时刻\(t\)的输入,则\(\mathbf{h}_t\)不仅和当前时刻的输入\(\mathbf{x}_t\)相关,也和上一个时刻的隐藏状态\(\mathbf{h}_{t-1}\)相关。\(\mathbf{W}_{\text{h}} \in \mathbb{R}^{d \times d}\)和\(\mathbf{W}_{\text{x}} \in \mathbb{R}^{m \times d}\)分别表示状态-状态权重矩阵和状态-输入权重矩阵。RNN可被进一步表示为\(\mathbf{h}_t = \tanh \left( \mathbf{z}_{t} \right)\),其中\(\mathbf{z}_t\)为RNN在时刻\(t\)的净输入,有\(\mathbf{z}_t = \mathbf{h}_{t-1}\mathbf{W}_{\text{h}} + \mathbf{x}_t \mathbf{W}_{\text{x}} +\mathbf{b}\)。注意,本文为了便于编程实现,将向量均表示为行向量。
理论上,一个完全连接的RNN是任何非线性动力系统的近似器。RNN可以处理任意长的序列。但是在实际中,简单的RNN通常会面临梯度消失和梯度爆炸问题,使其不能建模好序列的长期依赖关系。
1.2 RNN的应用
RNN可以应用到很多不同类型的机器学习任务。根据这些任务的特点,其主要可被分为: 序列到类别模式、序列到序列模式。
1.2.1 序列到类别
序列到类别模式主要用于输入为序列、输出为类别的序列数据的分类问题,例如时间序列分类、文本分类。比如在文本分类中,输入数据为单词序列,输出为该文本的类别。
假设一个实例\(\mathbf{X} =[\mathbf{x}_{1} , \mathbf{x}_{2}, \ldots,\mathbf{x}_{T}] \in \mathbb{R}^{T \times m}\)为一个长度为\(T\)的序列,输出为一个类别\(\mathcal{Y} = \{1, \ldots, C\}\)。可将实例\(\mathbf{X}\)按不同时刻输入到RNN中,并得到不同时刻的隐藏状态\(\mathbf{h}_{1} , \mathbf{h}_{2}, \ldots,\mathbf{h}_{T}\)。
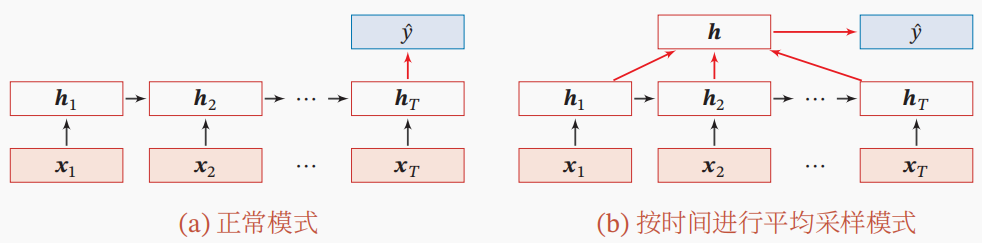
这时,可选择将最后时刻的状态\(\mathbf{h}_{T}\)作为整个序列的表示,也可对所有的隐藏状态进行汇聚,把这个汇聚后的状态\(\mathbf{s} \in \mathbb{R}^{1 \times d}\)作为整个序列的最终表示。其操作如上图所示。
具体地,有\(\mathbf{s} = \operatorname{Pooling} \big( \mathbf{h}_{1} , \mathbf{h}_{2}, \ldots,\mathbf{h}_{T}\big)\)。其中,汇聚操作可使用平均或注意力机制等操作。然后,可将序列的最终表示\(\mathbf{s}\)送入线性层或多层前馈神经网络FFN中用于分类。
当然,也可将其用于回归任务中,例如单步时间序列预测。此外,这一架构稍加改造,便可以用于语言模型或者序列化推荐中(通常是自回归的形式,即将历史的序列信息作为输入信息,来预测序列的下一时间步的状态或标签。)
1.2.2 序列到序列
序列到序列(Sequence-to-Sequence)可分为同步的序列到序列和异步的序列到序列。
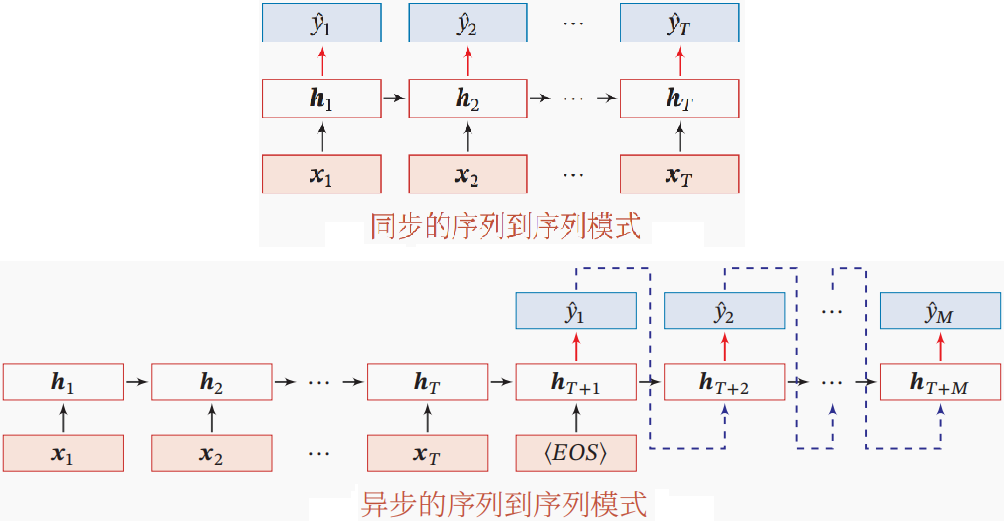
同步的序列到序列模式 主要用于序列标注(Sequence Labeling)任务,即每一时刻都有输入和输出,输入序列和输出序列的长度相同。其具体应用有,视频分类、词性标注等。比如,在词性标注(Part-of-Speech Tagging)中,每一个单词都需要标注其对应的词性标签。
异步的序列到序列模式也称为编码器-解码器(Encoder-Decoder)模型,即输入序列和输出序列不需要有严格的对应关系,也不需要保持相同的长度。其具体应用有,文本摘要、图像理解(Image Caption)、问答系统(Question Answering system)、多步时间序列预测、机器翻译等。比如在机器翻译中,输入为源语言的单词序列,输出为目标语言的单词序列。
1.3 模型学习
RNN的参数可以通过梯度下降方法,例如SGD,来进行学习。以同步的序列到序列模式为例,给定一个训练样本\((\mathbf{X}, \mathbf{y})\),其中\(\mathbf{y} \in \mathbb{R}^{1 \times T}\)是长度为\(T\)的标签序列。
RNN的参数关于某一时间步\(t\)的损失\(L_t\)(交叉熵损失),那么整个序列的损失函数为\(L=\sum_{i=1}^{T} L_t\) 。整个序列的损失函数\(L\)关于参数的梯度为:\(\frac{\partial L} {\partial \mathbf{W}_h}=\sum_{t=1}^{T} \frac{\partial L_t} {\partial \mathbf{W}_h}\)即每个时刻损失\(L_t\)对参数\(\mathbf{W}_h\)的偏导数之和。由于,RNN存在循环的计算过程,其计算梯度的方式和FFN不同。通常,需展开其计算图,然后按时间来进行梯度反向传播(Backpropagation Through Time,BPTT)。
1.3.1 按时间反向传播BPTT
BPTT算法将RNN看作一个展开的多层FFN,其中“每一层”对应RNN中的每个时间步,此时RNN可视为在水平方向上延伸的神经网络(相当于T层参数共享的FFN),它可按FFN中的反向传播算法计算参数的梯度。
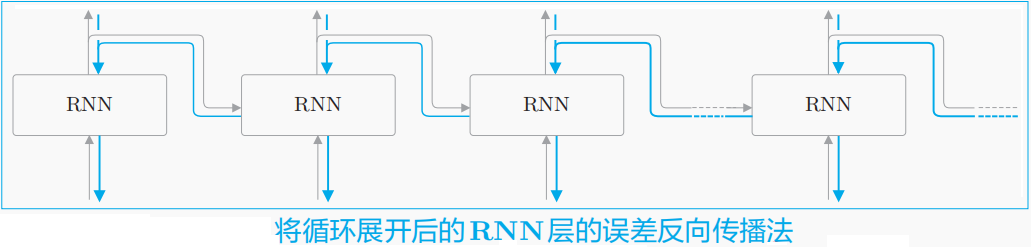
如上图所示,将循环展开后的RNN可使用反向传播。换句话说,可通过先进行正向传播,再进行反向传播的方式求目标梯度(直观地,只需要从损失开始,将其梯度不断反向传播回去,已求解各个参数的梯度)。
在“展开”的RNN中所有层的参数是共享的,因此参数的真实梯度是所有展开层(时间步)的参数的梯度之和。
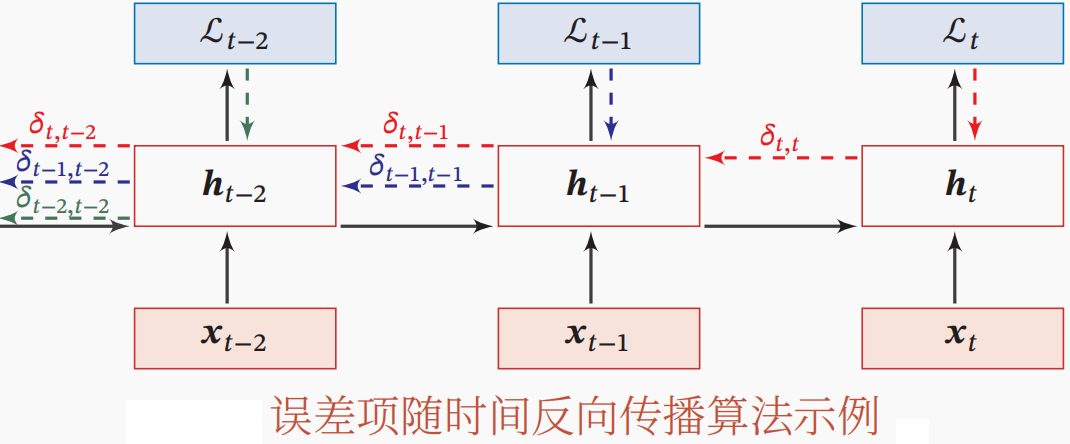
以时间步t时的损失为例,其参数的梯度是参数在所有的****时间步的梯度之和。
1.3.1 截断BPTT
尽管通过BPTT,RNN的学习似乎可以进行,但在这之前还有一个须解决的问题,那就是学习长时序数据的问题。因为随着时序数据的时间跨度的增大,BPTT 消耗的计算机资源也会成比例地增大。另外,反向传播的梯度也会变得不稳定。
二、RNN实现
2.1 简单RNN
这里以RNN用于语言模型为例(RNNLM),其试图建模马尔科夫链对应的条件概率分布。
基础模块
#!/usr/bin/env python
import numpy as np
class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W, = self.params
self.idx = idx
out = W[idx]
return out
def backward(self, dout):
dW, = self.grads
dW[...] = 0
if GPU:
np.scatter_add(dW, self.idx, dout)
else:
np.add.at(dW, self.idx, dout)
return None
class TimeEmbedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.layers = None
self.W = W
def forward(self, xs):
N, T = xs.shape
V, D = self.W.shape
out = np.empty((N, T, D), dtype='f')
self.layers = []
for t in range(T):
layer = Embedding(self.W)
out[:, t, :] = layer.forward(xs[:, t])
self.layers.append(layer)
return out
def backward(self, dout):
N, T, D = dout.shape
grad = 0
for t in range(T):
layer = self.layers[t]
layer.backward(dout[:, t, :])
grad += layer.grads[0]
self.grads[0][...] = grad
return None
class TimeAffine:
def __init__(self, W, b):
self.params = [W, b]
self.grads = [np.zeros_like(W), np.zeros_like(b)]
self.x = None
def forward(self, x):
N, T, D = x.shape
W, b = self.params
rx = x.reshape(N*T, -1)
out = np.dot(rx, W) + b
self.x = x
return out.reshape(N, T, -1)
def backward(self, dout):
x = self.x
N, T, D = x.shape
W, b = self.params
dout = dout.reshape(N*T, -1)
rx = x.reshape(N*T, -1)
db = np.sum(dout, axis=0)
dW = np.dot(rx.T, dout)
dx = np.dot(dout, W.T)
dx = dx.reshape(*x.shape)
self.grads[0][...] = dW
self.grads[1][...] = db
return dx
class TimeSoftmaxWithLoss:
def __init__(self):
self.params, self.grads = [], []
self.cache = None
self.ignore_label = -1
def forward(self, xs, ts):
N, T, V = xs.shape
if ts.ndim == 3: # 在监督标签为one-hot向量的情况下
ts = ts.argmax(axis=2)
mask = (ts != self.ignore_label)
# 按批次大小和时序大小进行整理(reshape)
xs = xs.reshape(N * T, V)
ts = ts.reshape(N * T)
mask = mask.reshape(N * T)
ys = softmax(xs)
ls = np.log(ys[np.arange(N * T), ts])
ls *= mask # 与ignore_label相应的数据将损失设为0
loss = -np.sum(ls)
loss /= mask.sum()
self.cache = (ts, ys, mask, (N, T, V))
return loss
def backward(self, dout=1):
ts, ys, mask, (N, T, V) = self.cache
dx = ys
dx[np.arange(N * T), ts] -= 1
dx *= dout
dx /= mask.sum()
dx *= mask[:, np.newaxis] # 与ignore_label相应的数据将梯度设为0
dx = dx.reshape((N, T, V))
return dx
RNN
class RNN:
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev):
Wx, Wh, b = self.params
t = np.dot(h_prev, Wh) + np.dot(x, Wx) + b
h_next = np.tanh(t)
self.cache = (x, h_prev, h_next)
return h_next
def backward(self, dh_next):
Wx, Wh, b = self.params
x, h_prev, h_next = self.cache
dt = dh_next * (1 - h_next ** 2)
db = np.sum(dt, axis=0)
dWh = np.dot(h_prev.T, dt)
dh_prev = np.dot(dt, Wh.T)
dWx = np.dot(x.T, dt)
dx = np.dot(dt, Wx.T)
self.grads[0][...] = dWx
self.grads[1][...] = dWh
self.grads[2][...] = db
return dx, dh_prev
class TimeRNN:
def __init__(self, Wx, Wh, b, stateful=False):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None
self.h, self.dh = None, None
self.stateful = stateful
def forward(self, xs):
Wx, Wh, b = self.params
N, T, D = xs.shape
D, H = Wx.shape
self.layers = []
hs = np.empty((N, T, H), dtype='f')
if not self.stateful or self.h is None:
self.h = np.zeros((N, H), dtype='f')
for t in range(T):
layer = RNN(*self.params)
self.h = layer.forward(xs[:, t, :], self.h)
hs[:, t, :] = self.h
self.layers.append(layer)
return hs
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D, H = Wx.shape
dxs = np.empty((N, T, D), dtype='f')
dh = 0
grads = [0, 0, 0]
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh = layer.backward(dhs[:, t, :] + dh)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
def set_state(self, h):
self.h = h
def reset_state(self):
self.h = None
基于RNN搭建语言模型
class SimpleRnnlm:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
# 初始化权重
embed_W = (rn(V, D) / 100).astype('f')
rnn_Wx = (rn(D, H) / np.sqrt(D)).astype('f')
rnn_Wh = (rn(H, H) / np.sqrt(H)).astype('f')
rnn_b = np.zeros(H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
# 生成层
self.layers = [
TimeEmbedding(embed_W),
TimeRNN(rnn_Wx, rnn_Wh, rnn_b, stateful=True),
TimeAffine(affine_W, affine_b)
]
self.loss_layer = TimeSoftmaxWithLoss()
self.rnn_layer = self.layers[1]
# 将所有的权重和梯度整理到列表中
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def forward(self, xs, ts):
for layer in self.layers:
xs = layer.forward(xs)
loss = self.loss_layer.forward(xs, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
self.rnn_layer.reset_state()
三、RNN存在的问题及其原因
RNN 的特点在于使用了上一时刻的隐藏状态,由此,RNN 可以继承过去的信息。
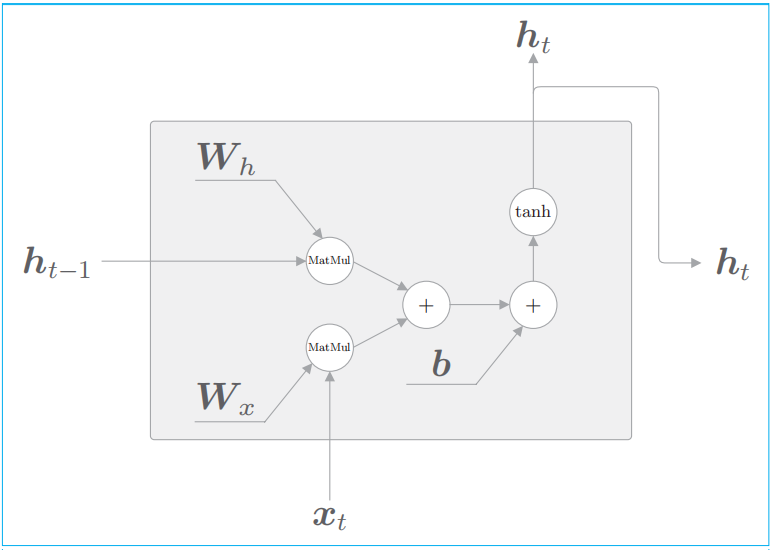
RNN单元的计算图如上所示。RNN 层的正向传播进行的计算由矩阵乘积、矩阵加法和基于激活函数tanh的变换构成。
3.1 梯度消失和梯度爆炸

语言模型的任务是根据已经出现的单词预测下一个将要出现的单词。借着探讨 RNNLM问题的机会,我们再来考虑一下图 6-3 所示的任务。
如前所述,填入“?”中的单词应该是 Tom。要正确回答这个问题,RNNLM 需要记住“Tom 在房间看电视,Mary 进了房间”这些信息。这些****信息必须被编码并保存在 RNN 层的隐藏状态中。
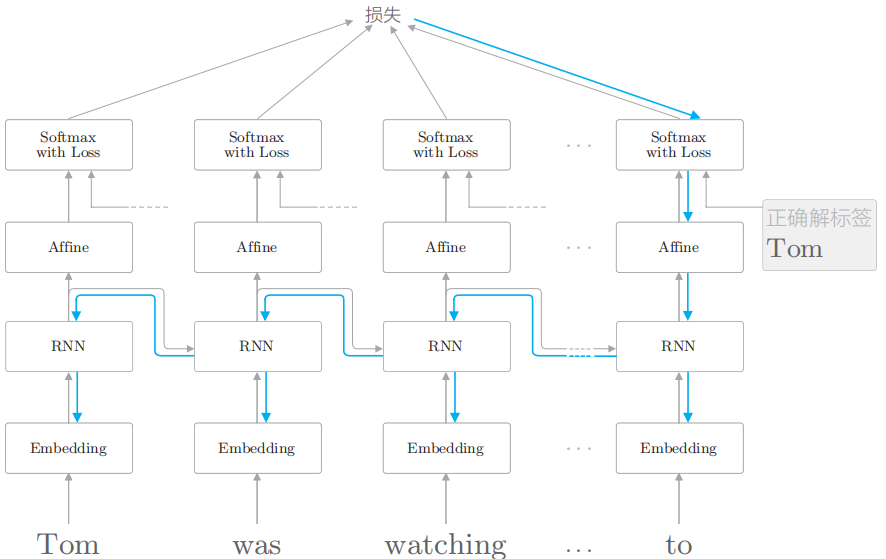
站在RNNLM进行学习的角度来考虑上述问题。在正确解标签为Tom时,RNNLM中的梯度是如何传播的呢?这里我们使用 BPTT进行学习,因此梯度将从正确解标签 Tom 出现的地方向过去的方向传播。
**RNN层通过向过去传递“有意义的梯度”,能够学习时间方向上的依赖关系。**此时梯度(理论上)包含了那些应该学到的有意义的信息。
通过将这些信息向过去传递,RNN 层学习长期的依赖关系。但是,如果这个梯度在中途变弱(甚至没有包含任何信息),则权重参数将不会被更新。也就是说,RNN 层无法学习长期的依赖关系(当前时刻参数的梯度只由局部时间步的回传的梯度决定,长范围的梯度信号很微弱)。
换句话说,随着梯度的回传,距离当前时间步损失越远的输入或隐状态对参数的梯度的贡献越小(梯度信号弱),它对模型学习的影响也微弱。
相反,如果梯度过大,也难以正常学习。
3.2 梯度消失和梯度爆炸的原因
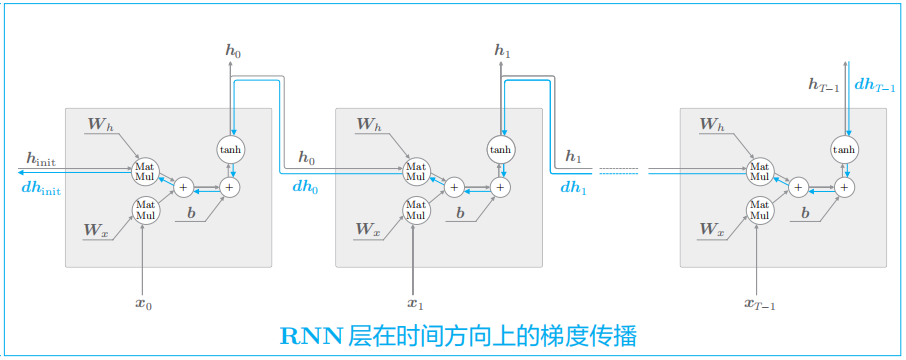
如上图所示, 这里考虑长度为 T T T的时序数据,关注从第 T T T个正确解标签传递出的梯度如何变化。就上面的问题来说,这相当于第 T T T个正确解标签是Tom的情形。
此时,关注时间方向上的梯度,可知反向传播的梯度流经 tanh、“+”和 MatMul(矩阵乘积)运算。“+”的反向传播将上游传来的梯度原样传给下游,因此梯度的值不变。
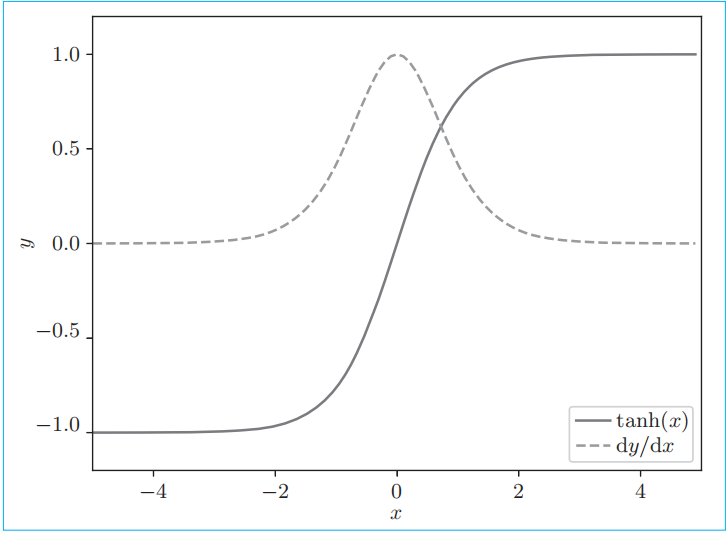
先来看一下tanh。此时,将y = tanh(x)的值(实线)及其导数的值(虚线)分别画在图上。从上图可以看出,它的值小于1.0,并且随着x远离0,它的值在变小。这意味着,当反向传播的梯度经过tanh节点时,它的值会越来越小。因此,如果经过tanh函数 T T T次,则梯度也会减小 T T T次。
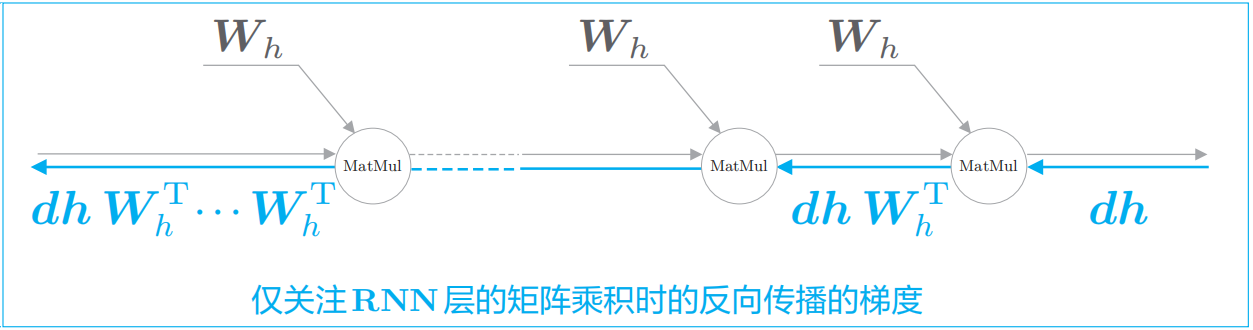
接下来,关注图中的 MatMul(矩阵乘积)节点。简单起见,这里省略tanh节点。如此一来,RNN层的反向传播的梯度就仅取决于MatMul运算。在上图中,假定从上游传来梯度 d h dh dh,此时 MatMul 节点的反向传播通过矩阵乘积 d h m a t h b f W _ h T dh \\mathbf{W}\_h^{T} dhmathbfW_hT计算梯度。之后,根据时序数据的时间步长,将这个计算重复相应次数。
需注意的是,每一次矩阵乘积计算都使用相同的权重 m a t h b f W _ h \\mathbf{W}\_h mathbfW_h。那么,反向传播时梯度的值通过MatMul节点时会呈指数级增加,或者呈指数级减小。因为矩阵 m a t h b f W _ h \\mathbf{W}\_h mathbfW_h被反复乘了 T T T次。
如果\(\mathbf{W}_h\)是标量,则问题将很简单:当\(\mathbf{W}_h\)大于1时,梯度呈指数级增加;当\(\mathbf{W}_h\)小于1时,梯度呈指数级减小。那么,如果\(\mathbf{W}_h\)不是标量,而是矩阵呢?此时,矩阵的谱半径将成为指标。简单而言,矩阵的谱半径(最大的特征值,表明矩阵是否收敛)表示数据的离散程度。根据这个谱半径是否大于1,可以预测梯度大小的变化(这是必要条件,并非充分条件)。
四、LSTM
==========
在面临梯度消失或梯度爆炸时(梯度爆炸可以通过梯度裁剪,主要还是梯度消失问题),RNN难以学习序列的长期依赖关系。为此,长短期记忆网络LSTM引入了门控机制来缓解梯度消失问题。

LSTM提出了用门控网络来控制信息的流动,以缓解RNN在处理长序列时会面临梯度消失。LSTM引入了基于门控机制的输入门、输出门和遗忘门,且相比RNN多了一个外部记忆单元Cell Memory。其中记忆单元的计算采用了哈达玛 (Hadamard)积。
可通过观察记忆单元Cell Memory的反向传播来了解LSTM缓解梯度消失的原因。
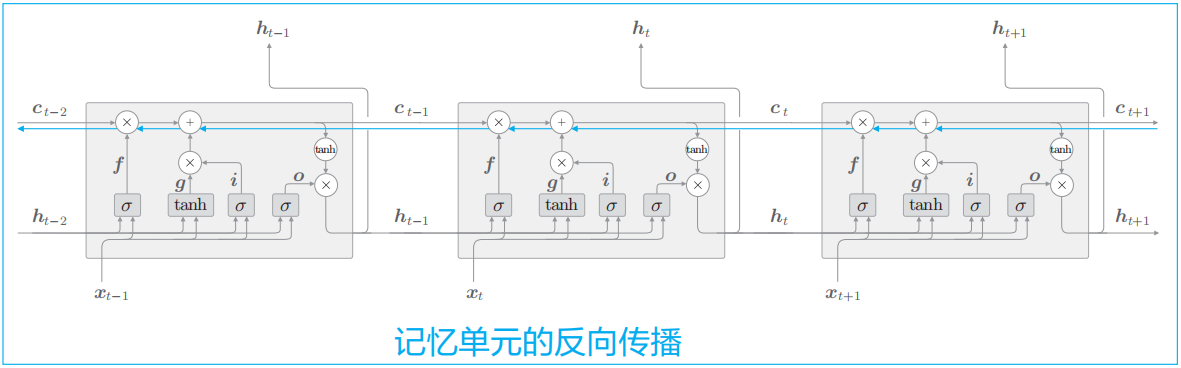
哈达玛积 \(\otimes\)使LSTM的反向传播计算过程中的不仅是矩阵乘积计算,而跟多涉及对应元素乘积(Element-wise Product)(偏导数为恒等矩阵),而且每次都会基于不同的门值进行对应元素的乘积计算。这就是它不会发生梯度消失(或梯度爆炸)的原因。
节点的计算由遗忘门控制(每次输出不同的门控值):
- 遗忘门认为应该忘记的记忆单元的元素,其梯度会变小;
- 遗忘门认为不能忘记的元素,其梯度在向过去的方向流动时不会退化;
因此,可以期待记忆单元的梯度(应该长期记住的信息)能在不发生梯度消失的情况下传播。
总结,LTSM通过基于哈达玛积的门控机制的记忆单元,构建了一条更有效的梯度回传通道,从而能缓解梯度消失。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 1198
1198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









