






随着计算生物学的进步,传统方法在解决蛋白质折叠、功能注释及新生物分子设计等问题时逐渐显露局限性,例如计算复杂度高或泛化能力不足。而大语言模型(LLMs)凭借其强大的语言理解与生成能力,为这些问题提供了新的解决方案。它们不仅能处理电子健康记录(EHR)或中医药问答等文本数据,还能分析蛋白质和RNA等生物序列,表现出比传统方法更高的准确性和适应性。
然而,如何系统性地评估LLMs在生物信息学任务中的表现,一直是一个难题。现有评估体系存在显著不足,包括测试数据与训练数据重叠、缺乏统一的答案提取工具以及任务覆盖范围有限等问题。这些缺陷限制了对LLMs在生物信息学中真实能力的全面衡量。因此,亟需一个标准化、覆盖广泛任务的评估框架。
为此,来自香港中文大学、香港大学及上海人工智能实验室的研究团队提出了Bio-benchmark——一个针对生物信息学NLP任务的全面评估框架。

Bio-benchmark框架
Bio-benchmark是一个基于提示(prompting)的评估框架,旨在通过零样本(zero-shot)和少样本(few-shot)设置,测试LLMs在生物信息学任务中的内在能力,而无需模型微调。该框架涵盖7大领域共30项任务,包括蛋白质设计、RNA结构预测、药物相互作用分析、电子病历推理及中医药智能问答等。
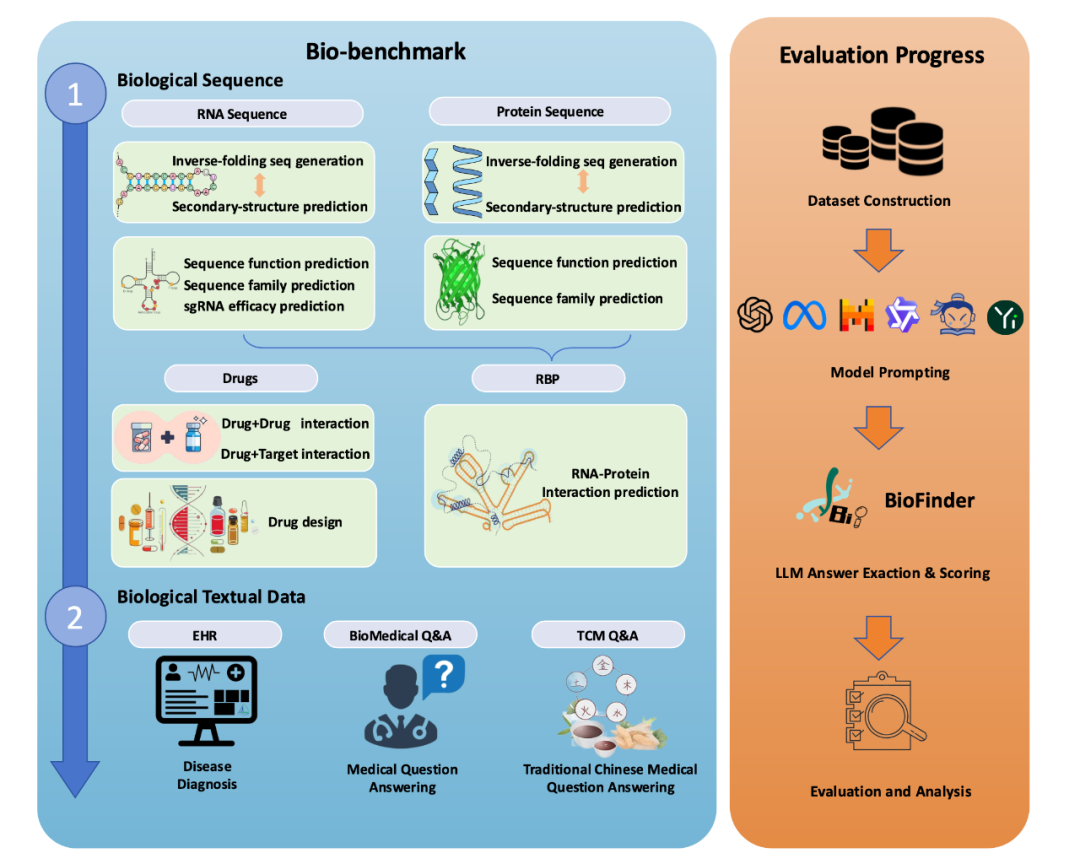
数据集设计
Bio-benchmark的数据集来源于多个权威数据库,覆盖以下子领域:
-
蛋白质:基于蛋白质数据库(PDB),包括二级结构预测、家族序列设计和逆折叠设计等任务。
-
RNA:数据来自bpRNA和RNA-Central,涵盖功能预测、二级结构预测及逆折叠设计。
-
药物:涉及抗生素设计、药物-药物相互作用预测及药物-靶标相互作用预测。
-
电子健康记录(EHR):基于MIMIC数据库,包含诊断预测和治疗计划制定。
-
医学问答:数据来源于HeadQA、MedMCQA等医学考试题库。
-
中医药问答:基于中医药经典文献和临床案例,测试模型对中医药知识的理解。
这一多样化的数据集设计确保了评估的全面性与代表性。
评估方法与BioFinder工具
为准确评估LLMs的表现,研究团队开发了BioFinder,一种专门用于从模型自由格式输出中提取答案的工具。传统方法(如正则表达式)在处理复杂输出时的准确率仅为72%,而BioFinder通过结合正则表达式与自然语言推理(NLI)技术,显著提升了性能。其主要优势包括:
-
生物序列提取:准确率达93.5%,较传统方法提升约30%。
-
医学NLI任务:准确率89.8%,超越GPT-4约30%。
-
长文本评估:支持无参考答案的质量评估。
以下是BioFinder与传统方法的性能对比:
| 方法 | 多选题 | 文本匹配 | 数值提取 | 生物序列 |
|---|---|---|---|---|
| 正则表达式 | 77.5% | 74.8% | 68.1% | 68.0% |
| GPT-4 | 65.8% | 80.5% | 67.0% | 38.5% |
| BioFinder | 95.5% | 94.3% | 95.5% | 93.5% |
评估分为两类:客观评估(如选择题,使用BioFinder提取答案并与标准答案比对)和主观评估(如长文本生成,通过相似性、专业知识及逻辑一致性判断质量)。
实验结果与分析
研究团队对六种主流LLMs(GPT-4o, Qwen 2.5-72b, Llama-3.1-70b, Mistral-large-2, Yi1.5-34b, InternLM-2.5-20b)进行了zero-shot和few-shot测试,结果如下:
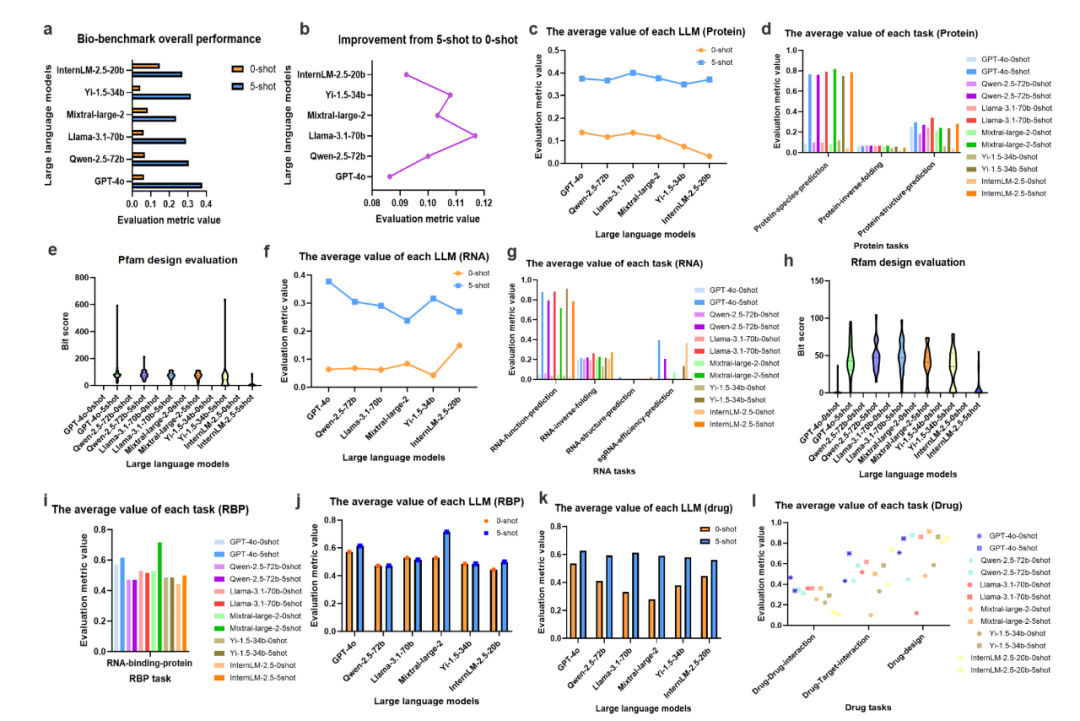
蛋白质任务
-
物种预测:Mistral-large-2在few-shot设置下以82%准确率领先;少样本提示显著提升表现,如Yi-1.5-34b准确率提升6倍,InternLM-2.5-20b提升近20倍。
-
结构预测:Llama-3.1在few-shot下恢复率达34%,表现最佳。
RNA任务
-
功能预测:Llama-3.1在few-shot下准确率达89%,少样本效果显著。
-
二级结构预测:所有模型表现较差,准确率普遍较低,显示任务复杂性。
-
sgRNA效率预测:InternLM在zero-shot下表现意外优于few-shot。
药物任务
-
抗生素设计:Mistral-large-2在few-shot下准确率达91%,表现突出。
-
药物-靶标预测:InternLM在few-shot下达73%。
-
药物-药物相互作用:最佳准确率仅47%,表明仍有改进空间。
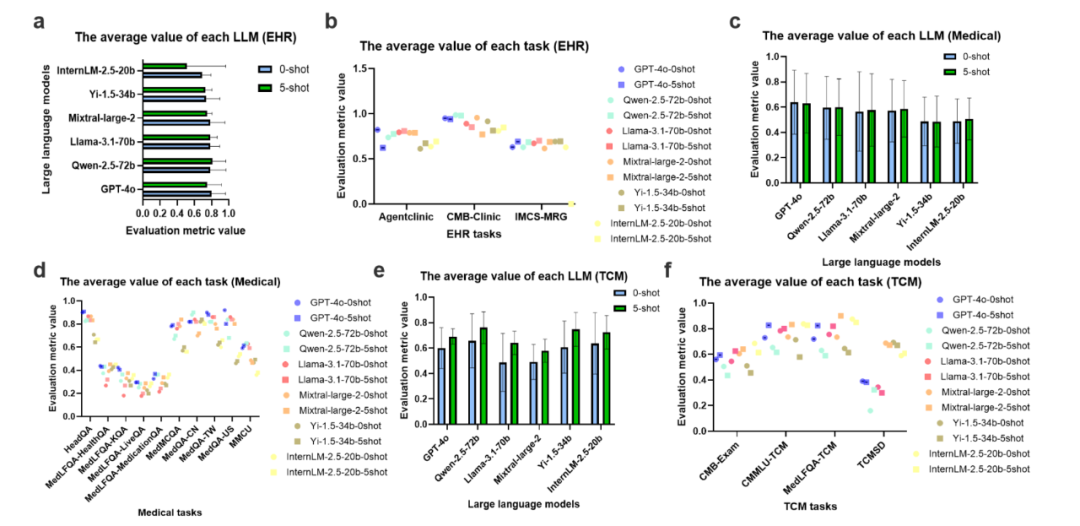
电子健康记录(EHR)任务
-
诊断预测:GPT-4o在AgentClinic任务中准确率达82.24%,表现优异。
医学问答任务
-
多选题:在HeadQA、MedMCQA等数据集上,平均准确率超70%,但少样本提示提升有限,甚至偶有下降。
中医药问答任务
-
表现提升:少样本提示显著改善结果,如TCMSD任务中准确率从31.7%升至65.3%。
提示工程的最佳实践
基于百万级测试数据,研究总结出三条提示工程经验:
-
分字符输入:将连续生物序列改为换行分隔,准确率提升3倍。
-
动态few-shot:示例数与任务复杂度正相关,3-10个为最佳范围。
-
领域知识注入:在提示中加入专业术语解释,错误率降低41%。
结论与展望
Bio-benchmark表明,LLMs在蛋白质设计、药物开发及中医药问答等任务中表现出色,尤其在少样本设置下潜力显著。然而,RNA二级结构预测及药物-药物相互作用等复杂任务仍具挑战性。BioFinder的引入为答案提取提供了高效工具,未来可进一步优化提示策略或探索微调方案。
局限性
尽管Bio-benchmark覆盖广泛,但其评估限于zero-shot和few-shot场景,未涉及微调潜力。此外,任务虽多样,仍可能无法全面代表生物信息学所有挑战。BioFinder的性能也受输入数据质量影响,在复杂输出中可能面临限制。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









