






DeepSeek 最近太卡了,又非常想用怎么办?快来“白嫖”微软、英伟达和亚马逊等部署在自己服务器的全量 DeepSeek-R1 模型!真香!
最近 DeepSeek 可谓是“泼天的流量”,不仅全球的用户涌入,而且来自各地的攻击也让服务器不堪重负,甚至流传出了 DeepSeek3 天的流量约等于整个欧洲互联网三天的流量总和,引发我们的红客誓死捍卫 DeepSeek 的桥段。

甚至
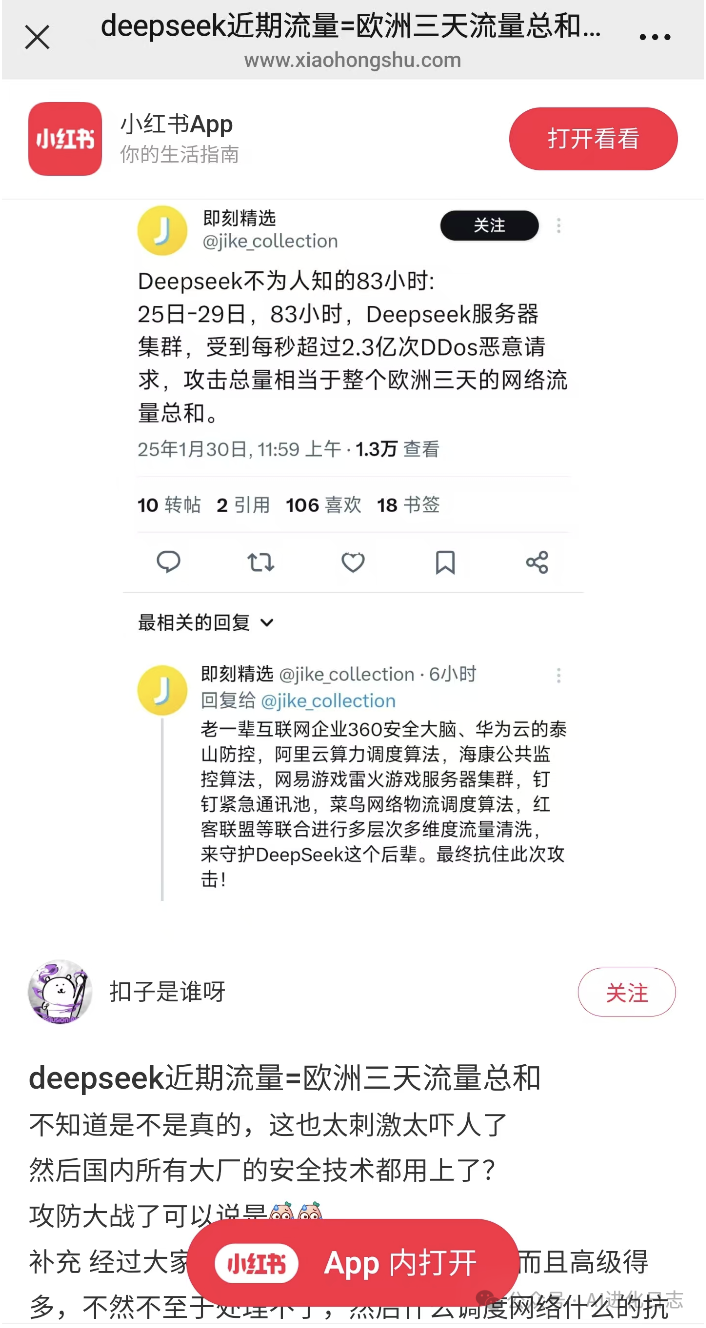
DeepSeek 官网服务太卡了怎么办?API 响应慢怎么办?
别着急,AI 界真相定律再次生效,“贼喊捉贼”的微软,率先将 DeepSeek部署在自家的 Azure 服务上,还有英伟达和亚马逊,都“羡慕”这波流量。
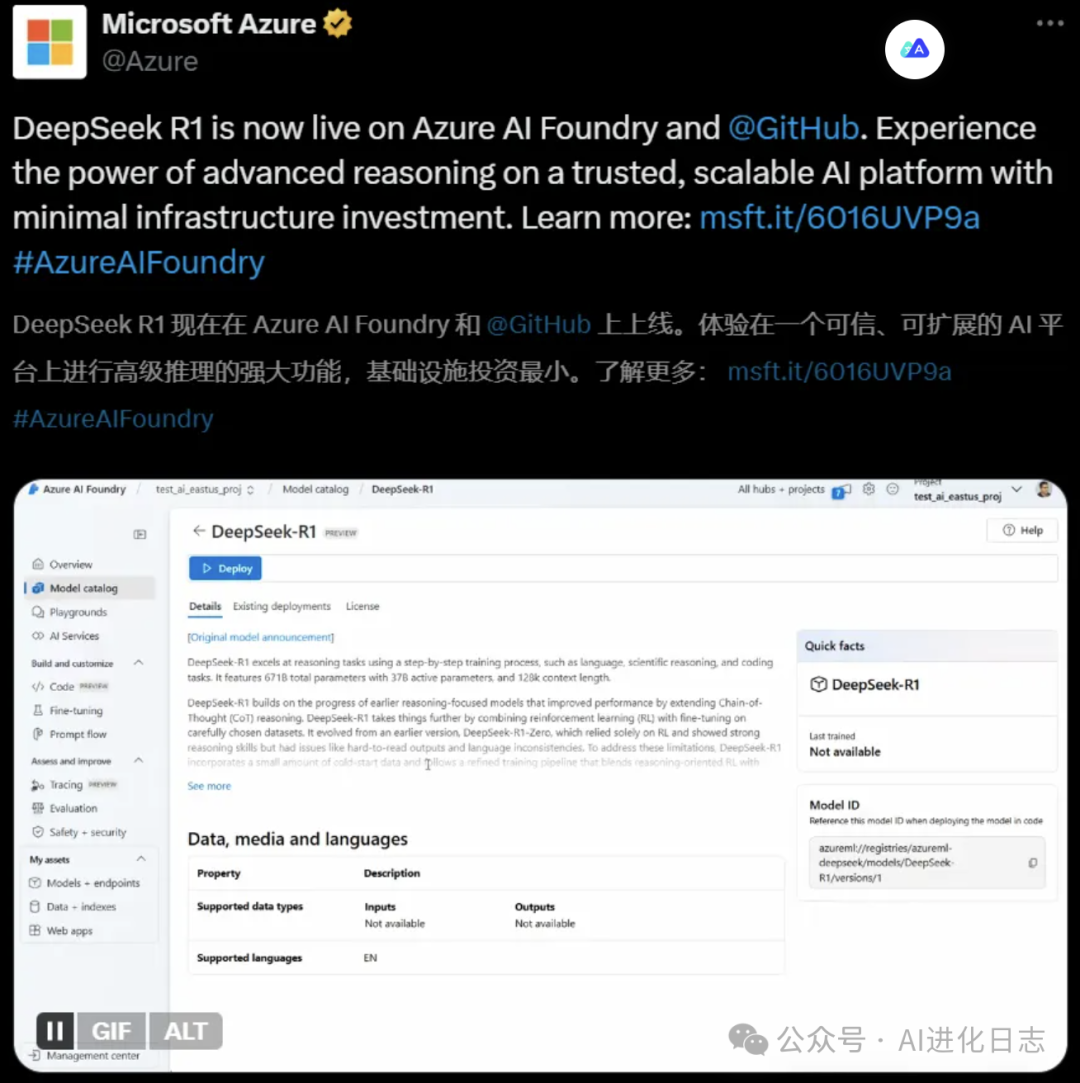
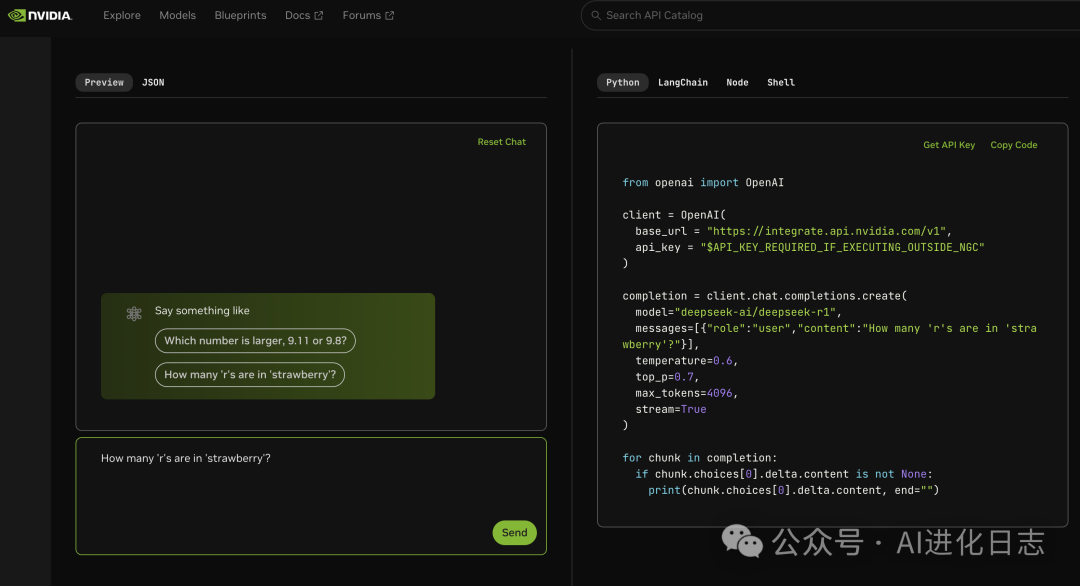
英伟达也在自己的 NIM 服务上部署了全量参数 671B 的 DeepSeek-R1 模型。
下面我们详细介绍如何使用5 种其他公司部署的 DeepSeek-R1 服务,得益于 DeepSeek 的开源政策,R1 的服务体验目前来说非常一致。
1、英伟达 NIM
登录:https://build.nvidia.com/explore/discover
直接点解 DeepSeek-R1 即可体验
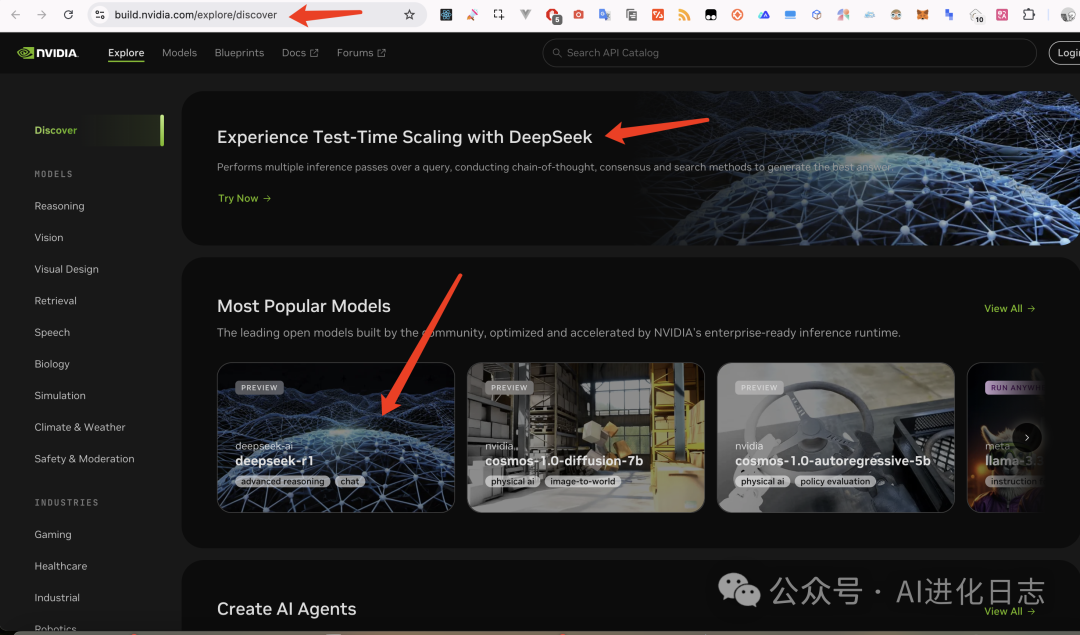
创建账户登录后,即可创建 API 体验 DeepSeek-R1 的服务。(不过在我测试的时候,突然变得很卡,真是’富贵的流量啊”)
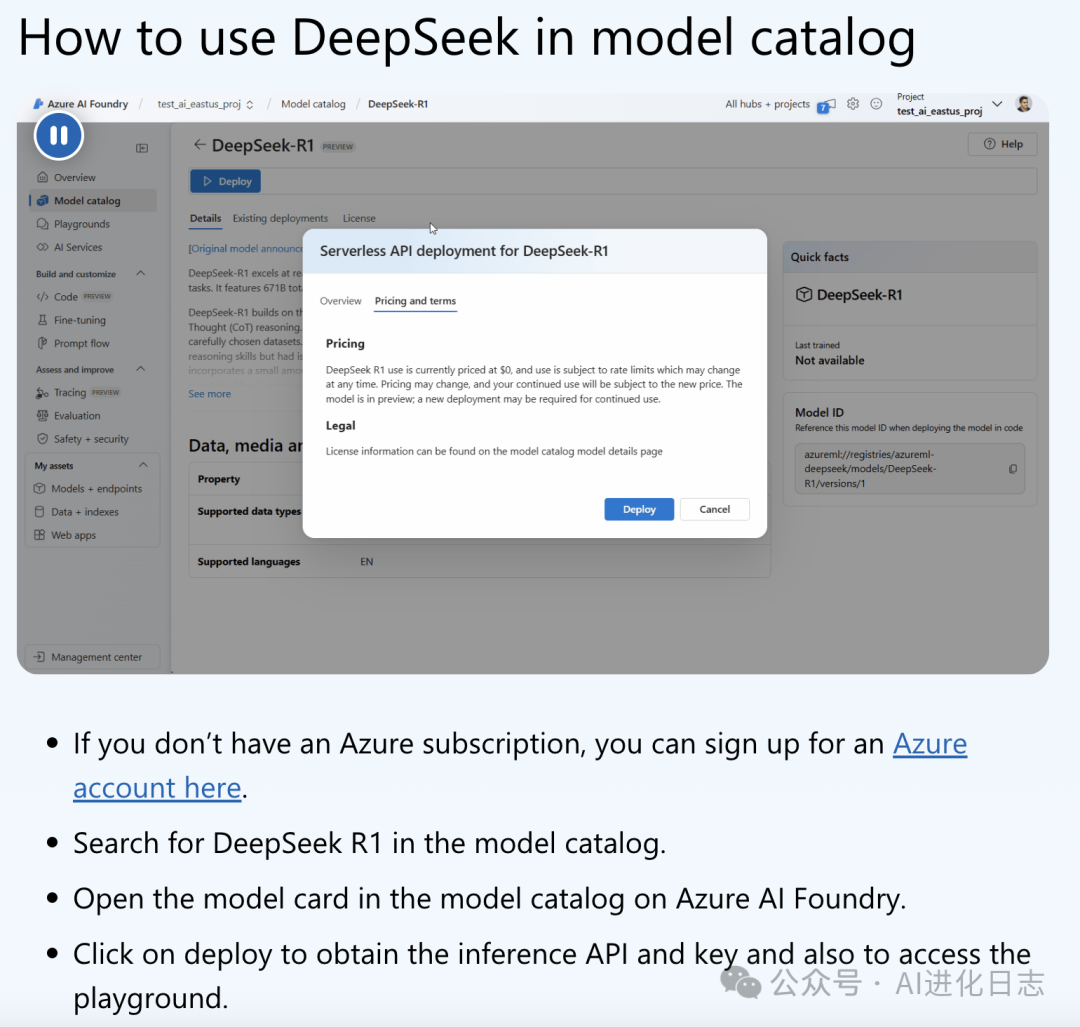
2、微软 Azure
登录:
https://azure.microsoft.com/en-us/pricing/purchase-options/azure-account?icid=payg

注册登录 Azure 后,可以在 Model Catalog 中选择 DeepSeek-R1 来体验。
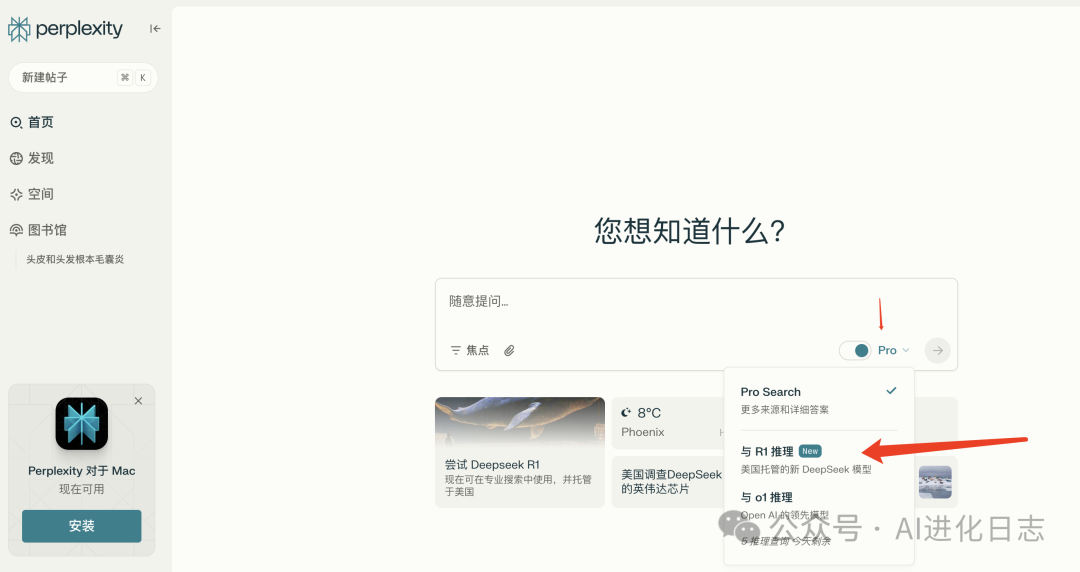
3、Perplexity 上直接使用
打开 Perplexity 直接使用。
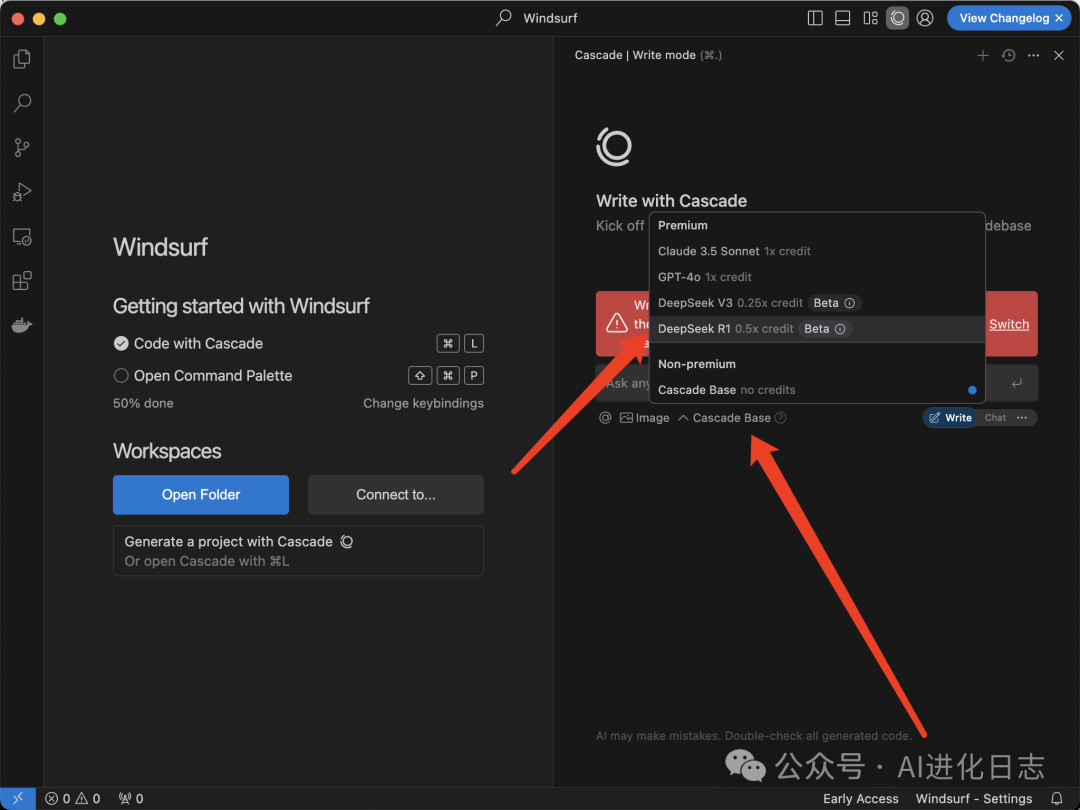
4、Windsurf 直接白嫖
Windsurf 是一个编程 IDE,但是现在他们动作快,已经可以用上 DeepSeek-R1 了
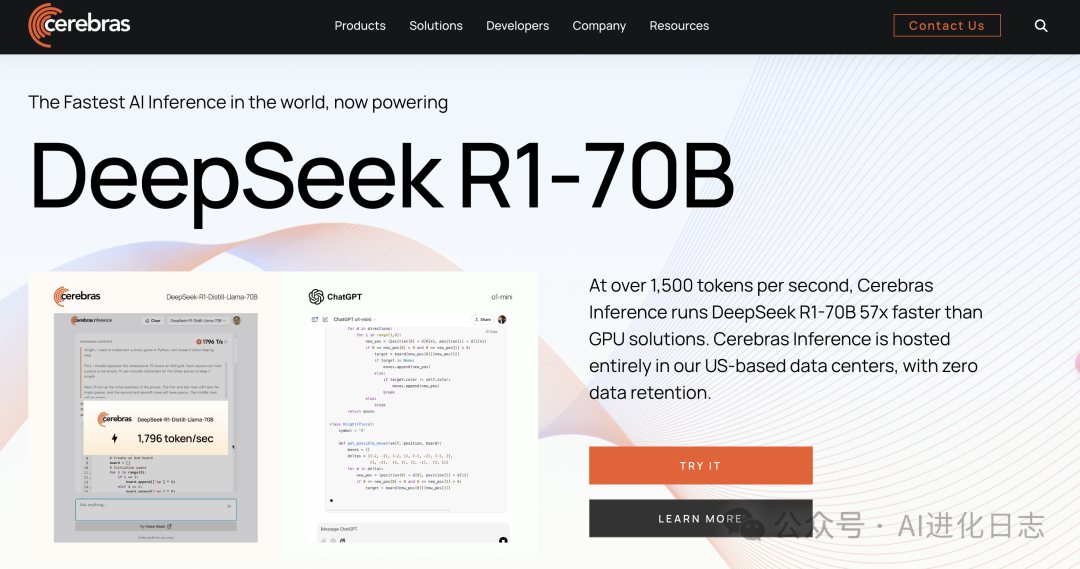
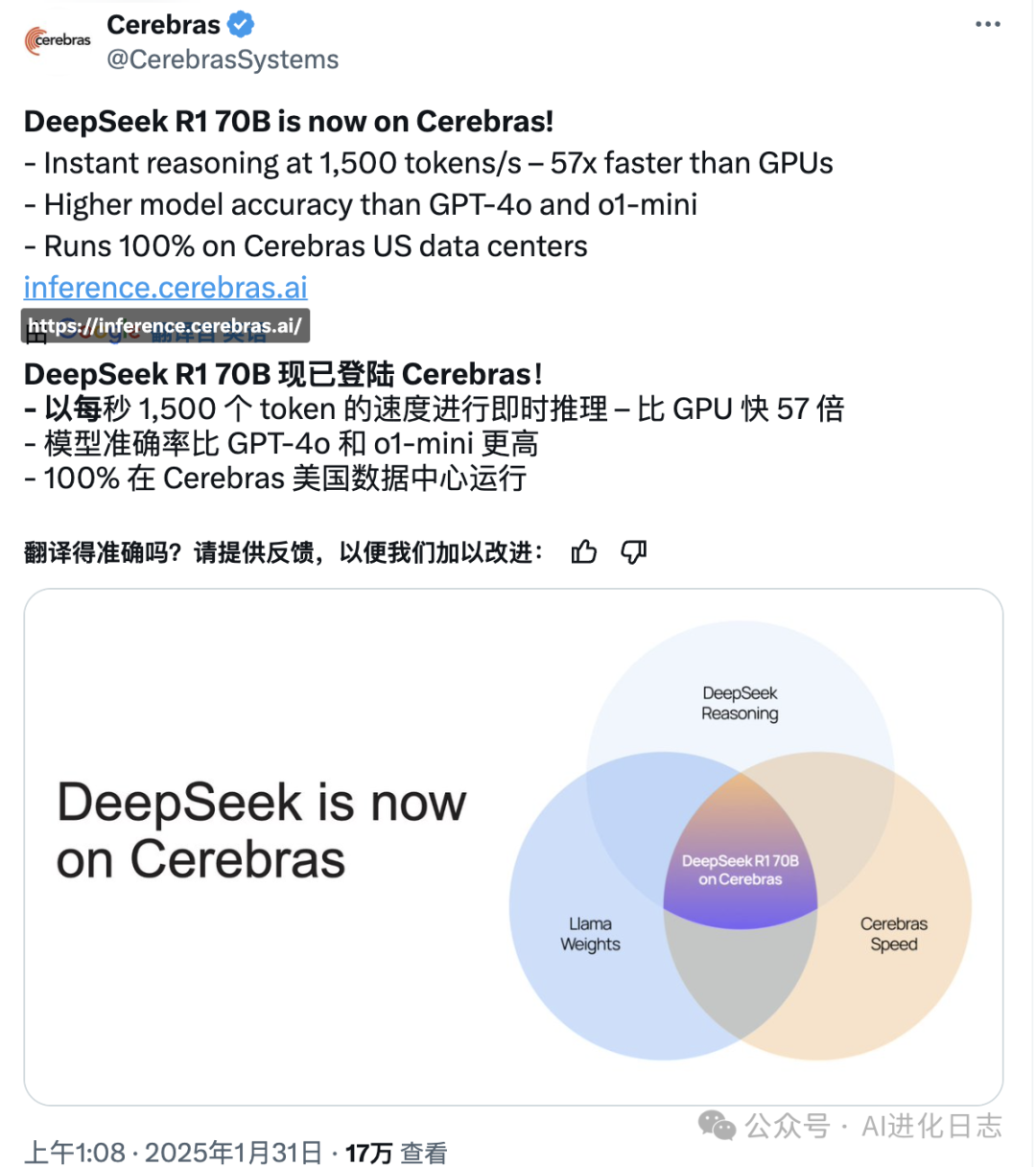
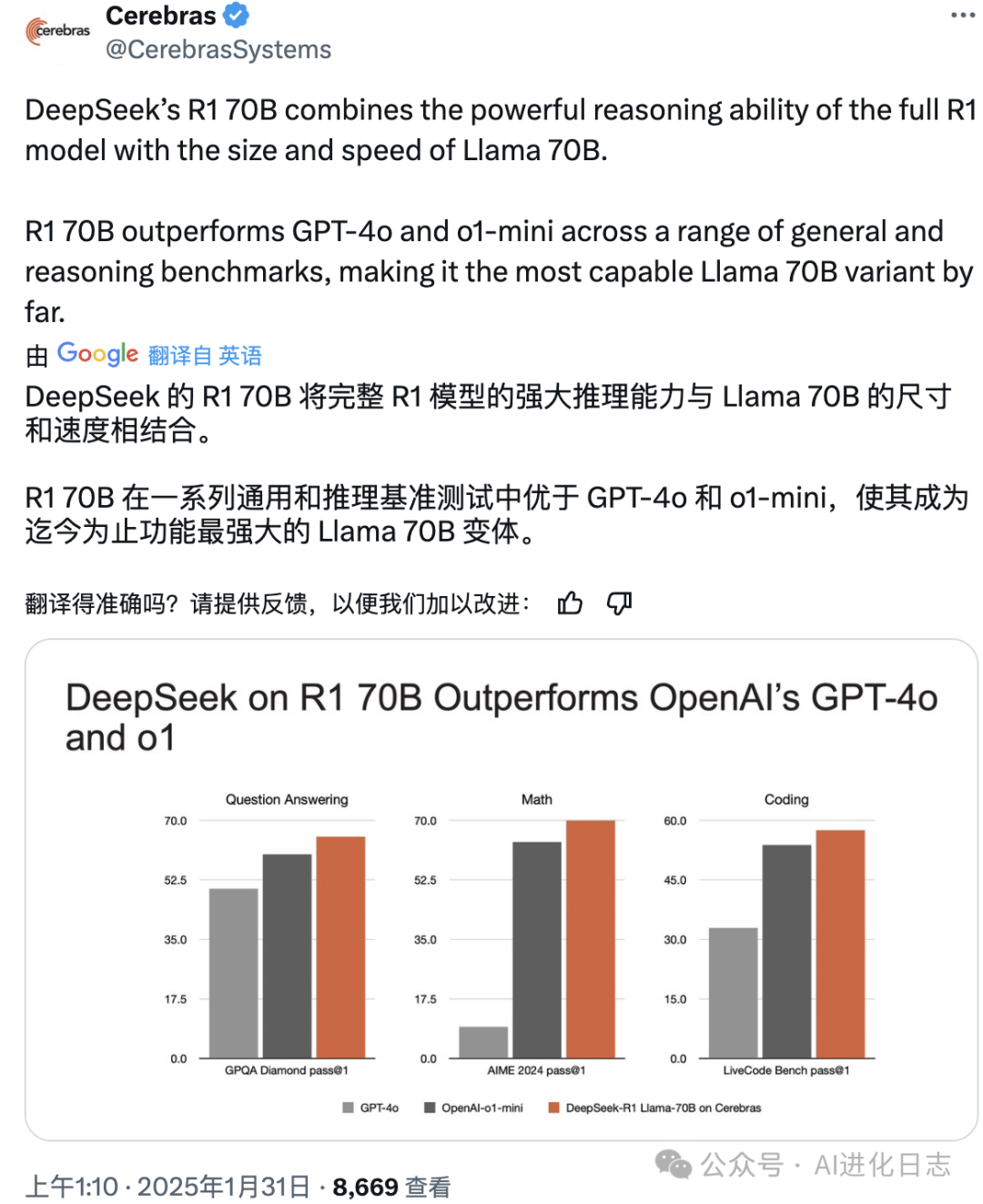
5、Cerebras
Cerebras虽然模型部署的 70B 但是号称比 GPU 的部署快了 57 倍。
而且比 o1-mini 还要聪明,这是真的香!
5、亚马逊 AWS
登录:
https://aws.amazon.com/cn/blogs/machine-learning/deploy-deepseek-r1-distilled-llama-models-with-amazon-bedrock-custom-model-import/
可以看到,DeepSeek-R1 现在各家真的是又怕又爱。
但是这泼天的流量又不想错过,真的就是真香定律了。

目前DeepSeek-API 平台服务依然是 503 状态。
想要体验 DeepSeek 的朋友们,可以临时用以上5 种方式救急。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1792
1792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









