






一直在想如何让AI 帮我写FPGA 的代码,分析代码,分析资料,不想一直重复造轮子。自从openAI 火爆之后,就一直在探索这条路,以至于求着给它送了不少银子。这是openAI 刚推出GPT Store功能的时候,我就做了一个AI 智能助手,上传自己的私有代码。但是效果一般。
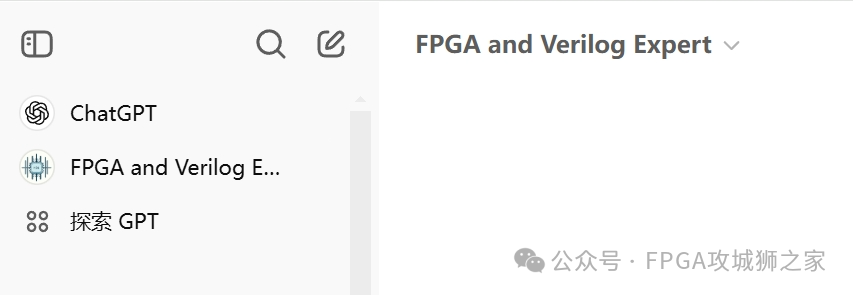
(我在GPT store 上的智能工具)
后来字节的 coze 出来了,我又用coze做了一个 FPGA 智能体。采用多个大模型进行需求重审,代码重审,最后总结输出。并且接入了自己的这个公众号后台,效果也是很一般。豆包,kimi,混元在FPGA 这个小众领域还是难以直接发挥其智能的特色。
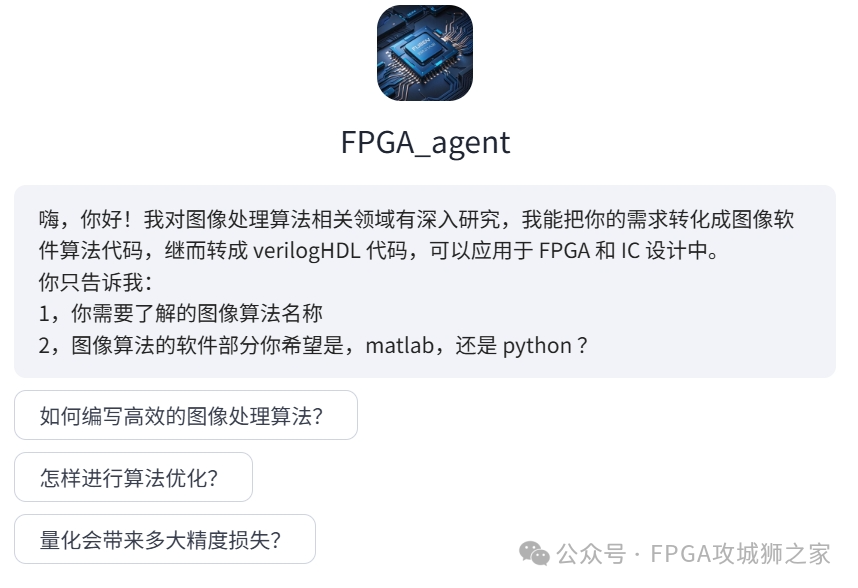
(我在coze上构建的多模型智能体)
坑我都已经踩过了,当然也不是说它们一定不行,只是现阶段用起来不顺手。还有一个主要的因素,就是它们都是闭源的,企业是不可能容忍自己的资料上传到网络的。
去年12月底 deepseek V3发布,到后来的开源,终于不用偷偷摸摸的用AI 了。开源炸锅实在精彩,我顺着这个浪潮分享一下,如何用deepseek R1 搭建本地FPGA知识库。
第一:思考为什么要用RAG
RAG是 检索(Retrieval)+增强(Augmentation)+生成(Generation)的缩写,它是能将用户提问结合一个外挂知识库的资料,整合起来生成答案给到用户。 而随着技术的发展,平台越来越成熟,构建本地知识库,部署大模型,也将是随便一个高中生就能完成的事情。
1,解决模型幻觉问题。
AI 工具用的多的人都可以感觉的到,AI 工具有时候会胡编乱造,特别是针对我们这种FPGA小众领域,知识点更多的是掌握在企业自己的手里,而不是在公开的网络上,所以幻觉的概率就更大了。
2,为什么用RAG 不用微调
LangChain微调,人工成本和时间成本是最大的问题。这种研发投入,绝大部分公司是不愿意投入的。
但是RAG技术,只需要本地大模型部署(也可以不部署,就是要牺牲数据私有性) + 构建本地知识库。本地知识库可以在企业运营中慢慢磨合,不断精修数据库,让大模型和本企业契合度越来越高。再加上部署多个大模型,形成多模态agent智能体,让用户得到错误答案的概率进一步减小。这将是未来个人和企业的最优方案。
第二:本地部署全流程
概述:
2.1 安装 ollama,通过ollama 下载deepseek 到本地。
2.2 安装 Docker ,通过 Docker 给RAGflow一个运行环境
2.3 下载 RAGflow镜像。
2.4 配置RAGflow,建立个人知识库
2.1 安装 ollama 和下载 deepseek
进入官网 https://ollama.com/,下载对应win系统的安装包。exe文件,直接双击安装即可。如果不想安装到C盘,就需要用命令行模式安装。
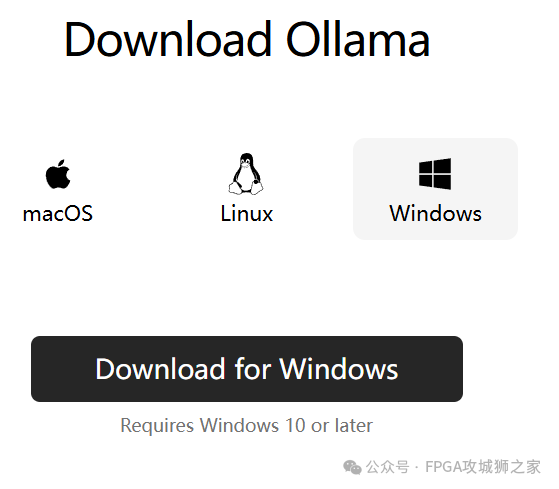
新建两个用户环境变量
OLLAMA_HOST 0.0.0.0:11434
OLLAMA_MODELS d:\agi\ollama (替换成你安装的位置)
然后在ollama官网左上角点击 models 找到 deepseek-R1
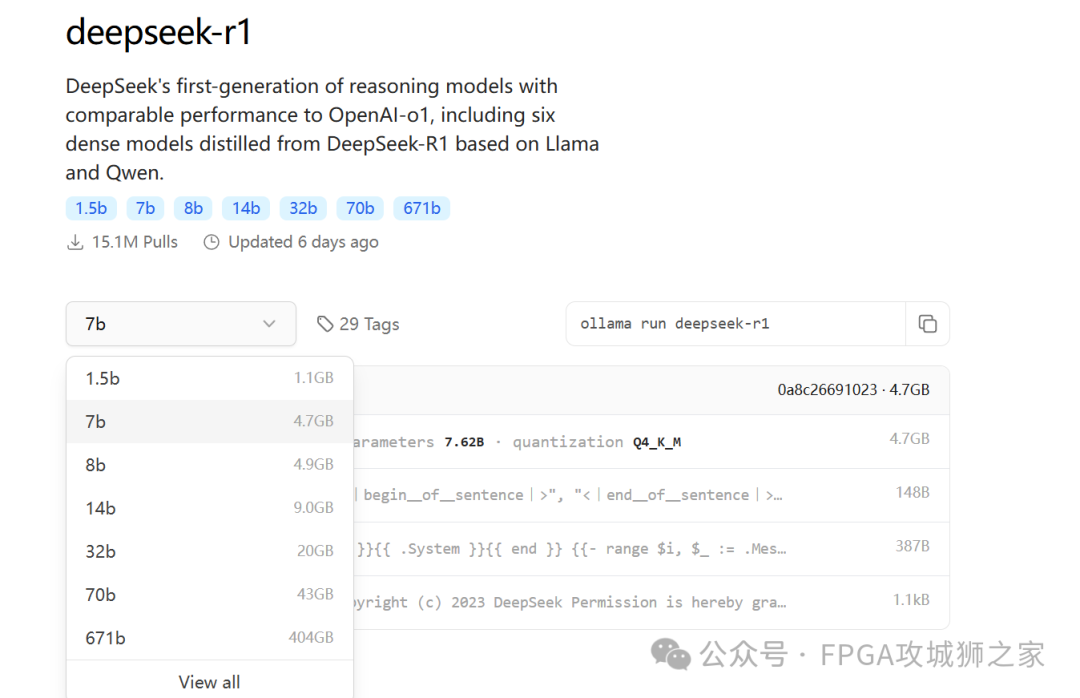
我下的是 7b模型,所以在 win的 cmd窗口中执行:
ollama run deepseek-r1:7b
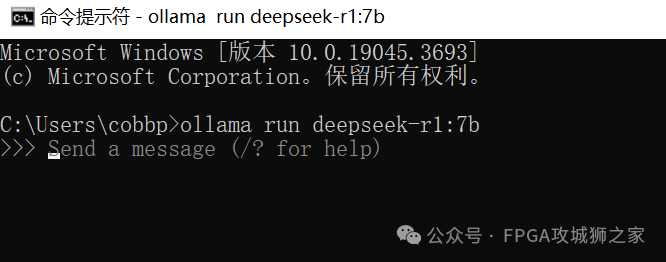
因为我已经安装了,所以展示就是这样子的。这时,deepseek R1 就已经被安装到电脑中了,可以在这个对话框里对话了。
2.2 安装 docker
docker是一个类似虚拟机的东西,它会给ragflow提供完整的各种依赖库,类似一个简易版本的虚拟机。进入docker的下载界面:
https://docs.docker.com/desktop/setup/install/windows-install/
这个默认安装就行,只是安装起来容易,但是用起来多少会出现一些依赖库不足的问题,到时候就需要根据不同的电脑环境,根据不同的错误进行依赖库添加。安装win版docker,是所有步骤中最麻烦的,其他的都是常规操作。不过如果出错,下面这个网址的内容,基本上能解决大部分问题:
《win10系统 Docker 提示Docker Engine stopped解决全过程记录》
https://blog.csdn.net/cplvfx/article/details/138033592
2.3 下载ragflow 源代码和镜像
进入 ragflow的官方git网址,直接下载zip压缩包。
https://github.com/infiniflow/ragflow
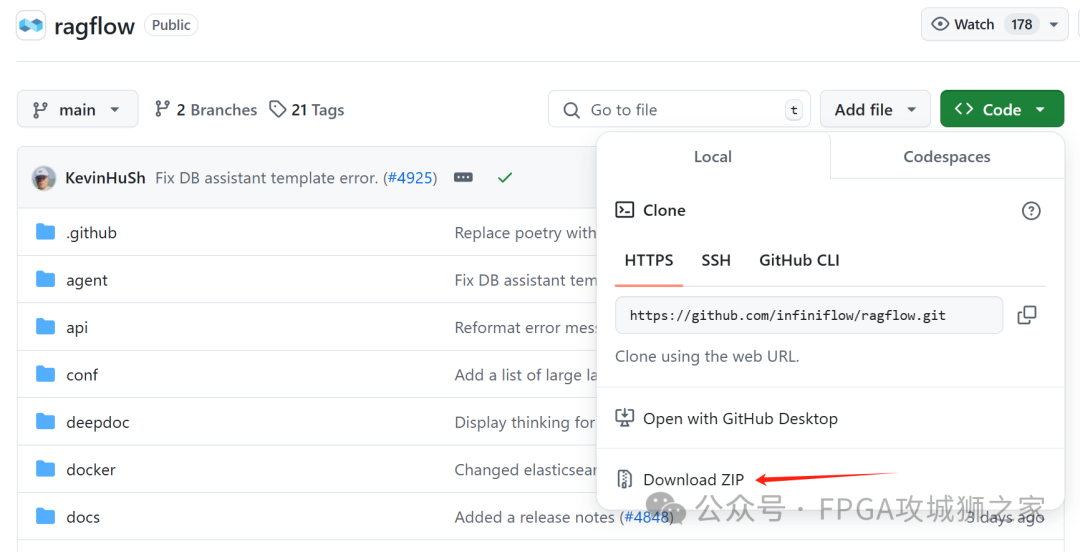
解压缩后,按照git上的提示,还需要在解压缩的文件夹中执行 cmd 命令:
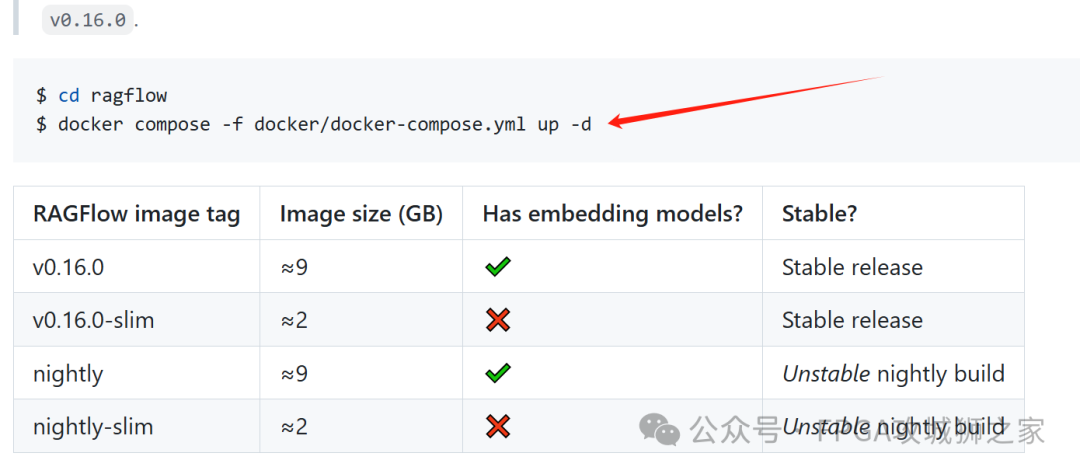
不过在执行之前,你需要修改一下 解压缩文件,docker文件夹下的 .env文件。屏蔽掉84行,打开87行,让上述命令下载一个完整版的RAGflow。因为你需要embedding模型来解析文件。
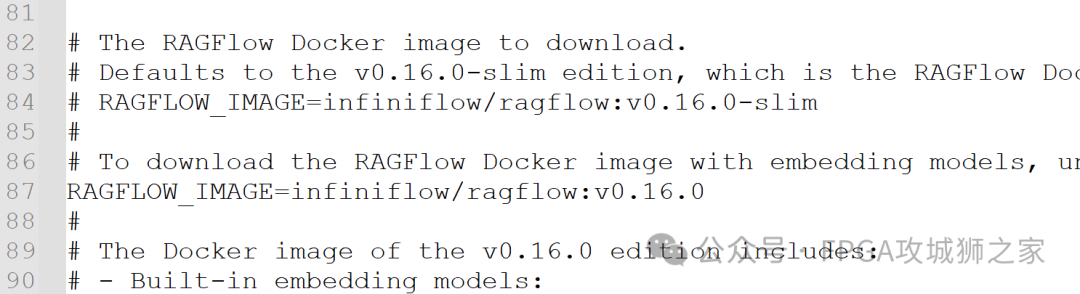
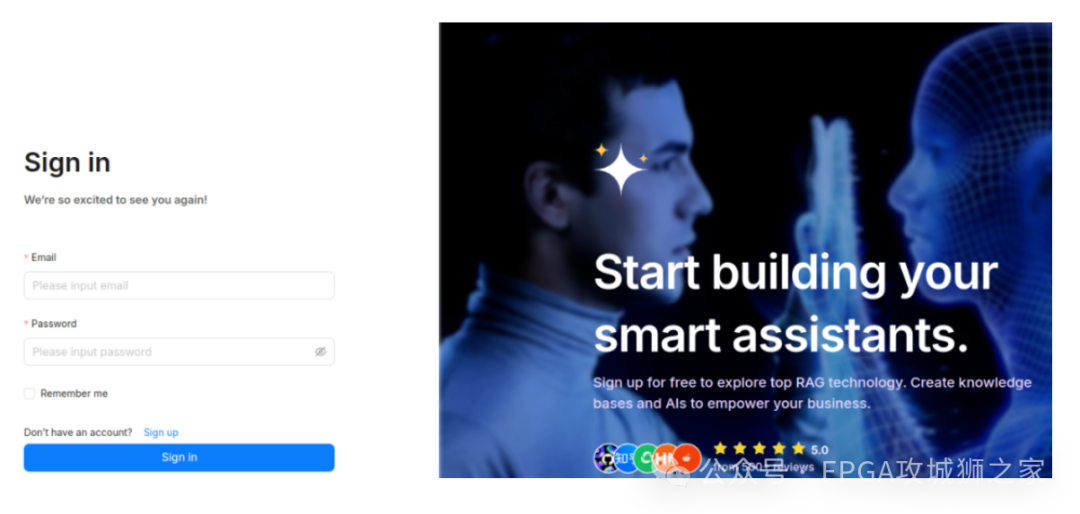
RAGflow的执行时间会非常久,需要耐心等待,不过提醒一下这里可能要科学一下。执行完毕之后,在网页上输入localhost:80

如果你出现的是注册登录界面,那恭喜你。完成了 。你只需要邮箱注册一下,就可以使用了。
2.4 配置RAGflow,建立个人知识库.
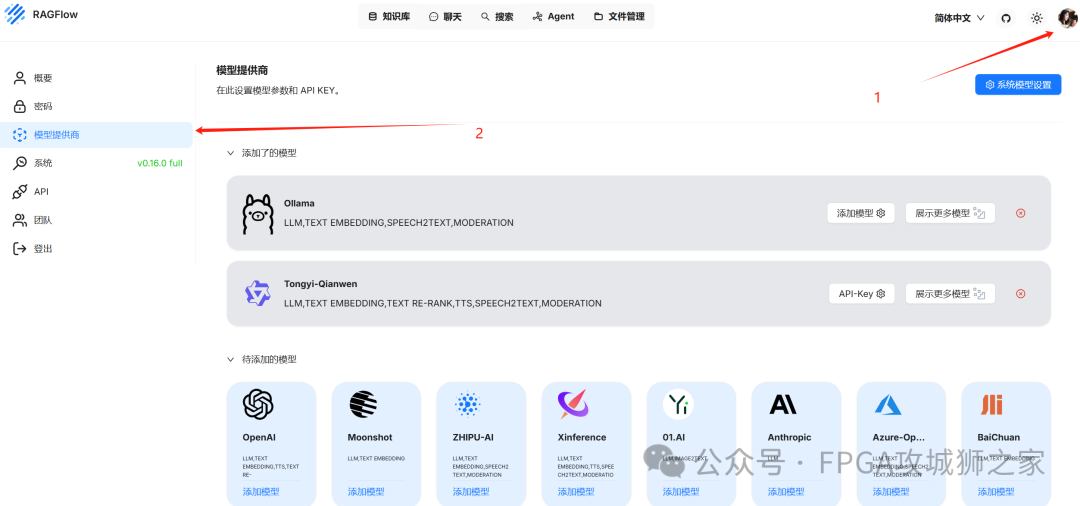
2.4.1 大模型设定。
点击个人图像,进入用户设置,然后点击 模型供应商。找到 ollama,选择添加模型。
然后按照下面进行配置,url部分写入自己的 ip v4地址(在cmd窗口用ip config 命令就可以得到)后面跟上端口号 11434 ,最大token可以随意,反正本地的又不要钱。
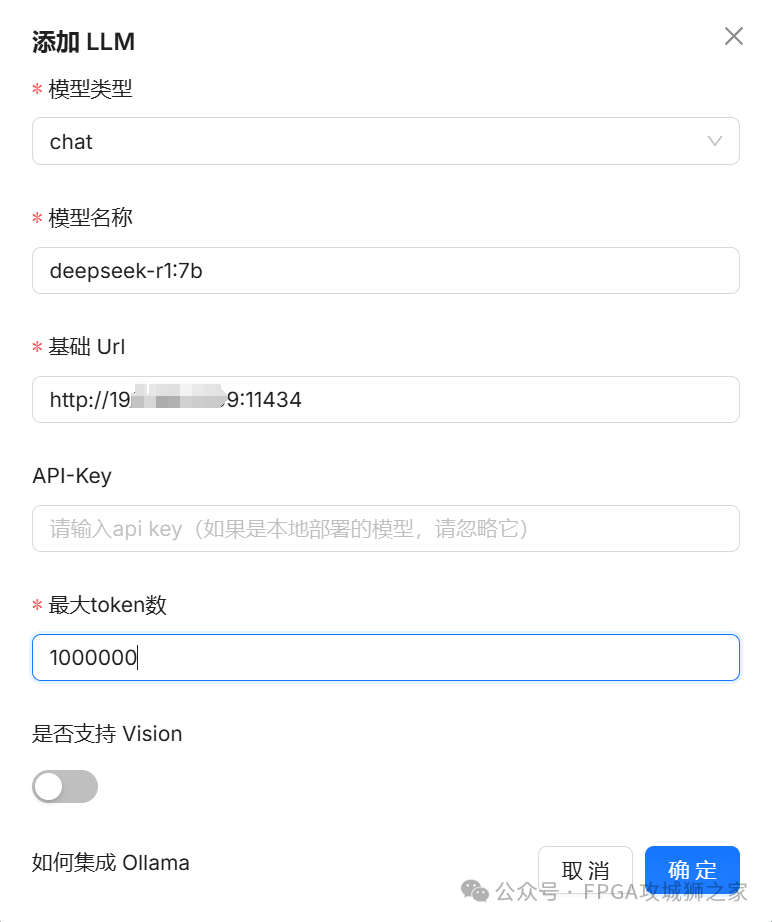
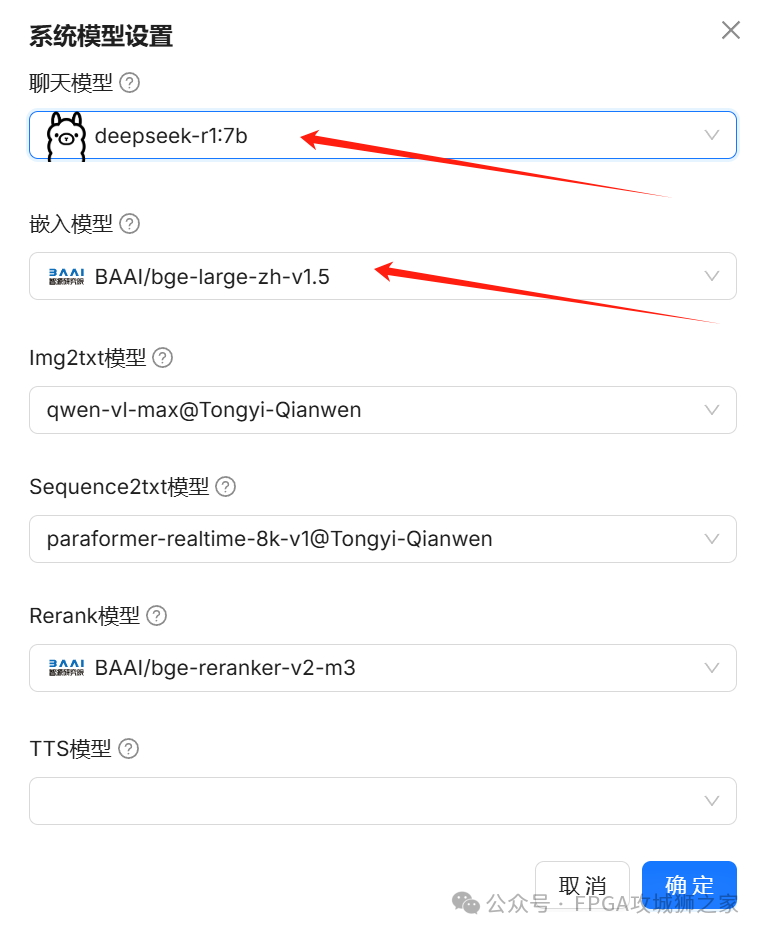
上面是聊天模型的设定,还有一个系统模型的设定,还是这个界面,点击右上角的,系统模型设置,按照下面设置这两个模型即可。其他默认。大模型设置完毕。
2.4.2 构建知识库 。
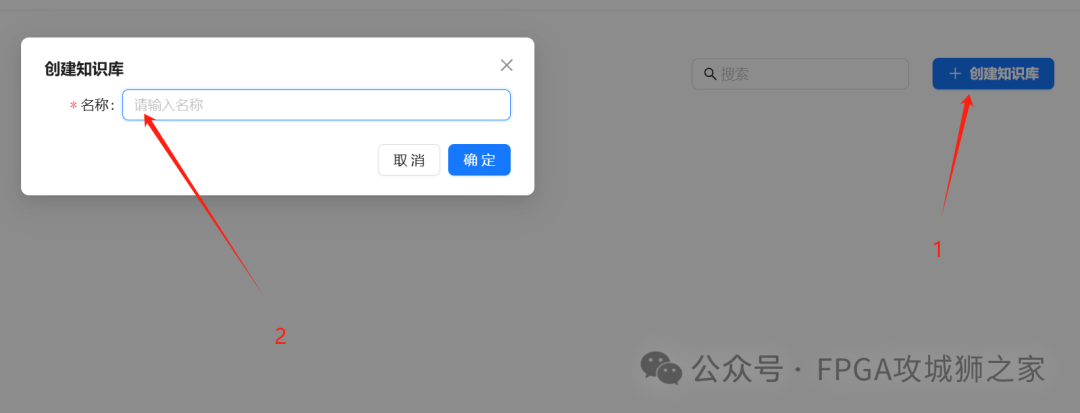
点击创建知识库,取名。然后点击数据库,新增文件,上传之后点击 解析的绿色小图标。待解析完成,就可以在聊天窗口中获取文本知识。
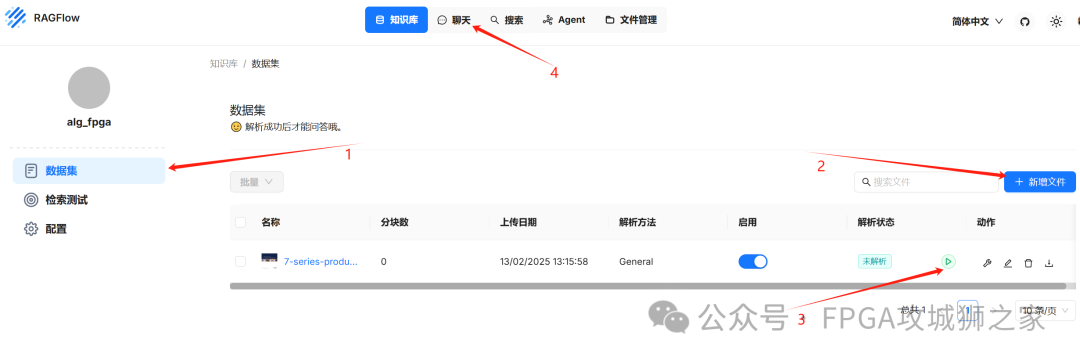
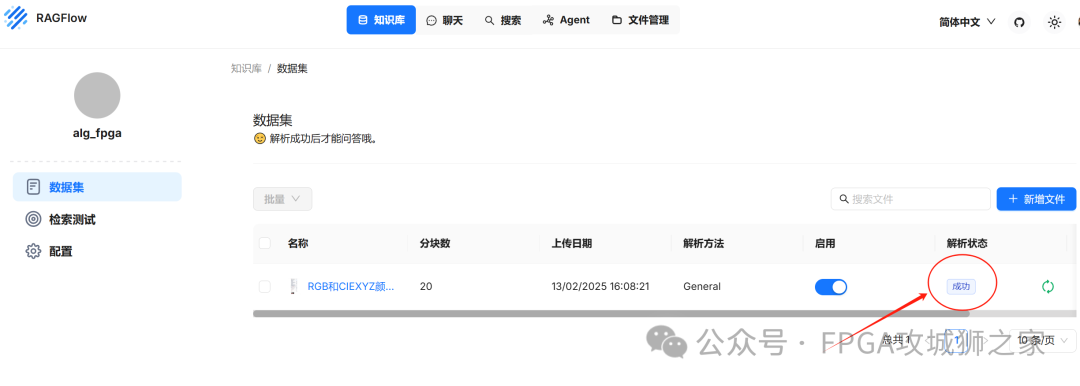
如下图所示,文件需要解析成功,才能获取到文件中的知识。如此,你的个人知识库构建完毕。
小试一把:
先传个文档,聊聊天试试。
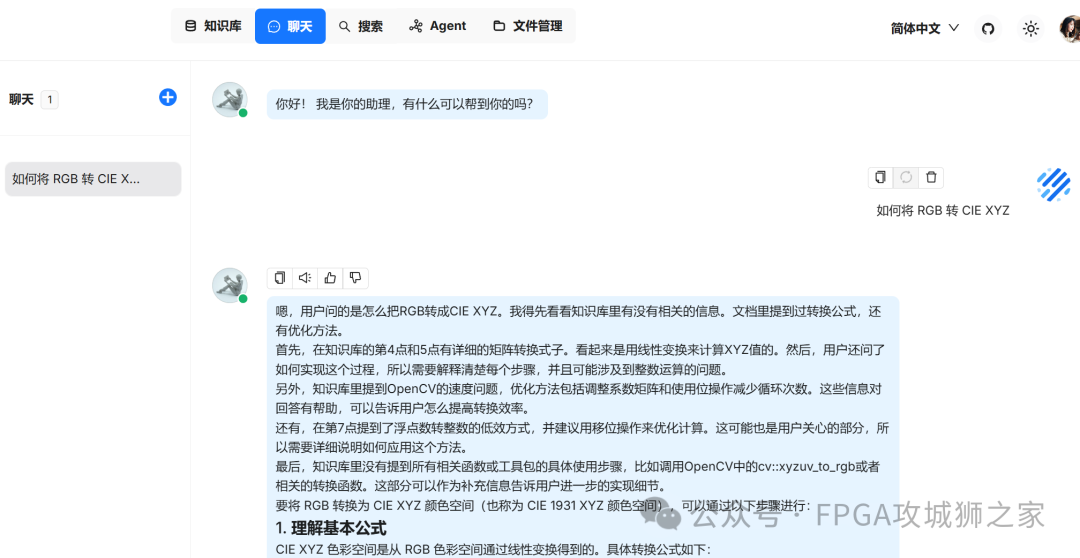
再上传一个代码,代码量比较大,分块都到了100个,再聊天试试。发现是可以关联到文档中的内容并且做了参考,可能是因为只上传了一个文件,代码质量还是很一般,不过有了好的参考,应该会有所提升。


总结:
1,RAGflow虽然现在支持中文,但是中文的支持还不是太丝滑。这个后续肯定会有所改进。但是它对资料的解析,知识库关联度目前还算不错的。这个才是尤为重要的。
2,本地部署与知识库的对于企业的意义最大,对于个人而言,也是一个能力放大器,也可以将个人能力无限放大。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1750
1750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









