






0、前言
AI是下一代颠覆性的机会,已经是很多人的共识。尤其是在媒体的大力宣传下,大模型显得格外火热,但为什么已经到2025年了,在企业落地应用上颇有“雷声大,雨点小”的态势呢?
落地遇到的挑战是什么?希望尝试从3个不同的角度来讨论:
1)大模型技术本身的挑战(本文)
2)企业认知和自身工作流成熟度的挑战
3)负责企业落地的算法产研团队挑战
最容易想到和有共识的,是大模型本身技术还不成熟的问题,因此本篇先聊聊此方面的挑战,和当下的解决方案。
1、大模型和之前的AI有什么区别?
首先我们从企业落地的角度来看看,大模型和之前的AI有什么区别,能让大家看到“未来的希望”。
相对之前AI 1.0时代,大模型最大的变化是:之前不论做什么,都需要花人力先整“特定场景”的数据,再训个“定制模型”。而大模型写写prompt,就能出结果,有些场景甚至也还不错。
先不论这个结果能不能满足所有企业级要求,但它一下子就越过了之前的前置流程,要知道之前很多场景,都是被卡在前置数据和训模型的环节上了。这也是大模型一度颇有“百花齐放”的原因,毕竟尝鲜的门槛降低了,很多场景从“原本想都不敢想”到“都能低成本、短周期 试试”。
2、LLM的问题
然而大模型也不是万能的,以大语音模型LLM为例,通用的大语言模型技术直接落地企业实际业务需求,有以下问题:
-
幻觉问题 : 大模型的原理是“文字接龙”,也就是基于数学概率预测后面要输出的文字,这导致了大模型输出结果存在幻觉的问题。
-
知识过期 : 大模型本身训练的数据是静态的,当前主流的大模型(比如 ChatGPT、通义千问、文心一言…)的训练集基本都是抓取网络公开数据,所以大模型所掌握的知识存在截止日期,也不具备实时性的、非公开的知识。
-
安全性 : 企业都不愿意泄露自己的私域数据,因此很难同意传给别人训练。
-
对话长度限制 : 如果给大模型的内容过多,超过或接近限制,就会失败或容易“漏指令”。
-
可解释性:大模型输入输出充满了不确定性,缺乏可解释性、黑盒问题。(以前AI 1.0时代好歹是有一个目标清晰的限定场景,自己知道自己用的什么数据,什么方式训得,或者训练数据量和模型参数量都小。但大模型动不动就是百亿千亿为单位的训练量和参数量,而且企业通常都是调用的第三方大模型厂商的API,甚至是闭源的大模型)
-
灵活性 : 大模型一旦训练完成,再调整的周期和成本就是很高的。
3、有哪些方案?
之前的文章已经提到了企业落地时几种主流方案,这里罗列比较全的4种方案:
1)prompt:仅靠提示词对通用LLM下达指令
2)RAG : 通用LLM结合RAG
3)微调 : 基于开源LLM,用SFT等方法
4)从头训练 : 用海量企业私有数据,从头训练一个适配企业行业或场景的大模型
这里给出一个不严谨的结论,仅为了能从整体上有个大概的感知:
效果:从头训练>微调>RAG>prompt
成本:从头训练>微调>=RAG>prompt
训练/搭建周期:从头训练>RAG >=微调>prompt
推理响应耗时:RAG >从头训练>微调>=prompt
(要提醒的是:由于过于简化,细化到具体的场景,可能有不一样的结论,尤其是RAG可以由简单拓展成复杂的架构,以及几种方案往往是逐渐叠加使用,不是孤立的)
4、Prompt、RAG、微调的区别
由于从头训练一个大模型不是一般企业能吃得消的(钱、卡、人才、数据都是挑战),所以企业落地方案一般讨论的是:prompt、RAG和微调。
区别比对表:
Prompt | RAG | 微调 Fine-tuning | |
类比 | 在模型的考卷上,框定/提炼得分要点。 | 为模型额外提供教科书,允许它开卷考,随时翻书 | 正式开考前,让模型上专项冲刺班,提供和正式考卷差不多题型的模拟试卷和标准答案,消化巩固和提高。 |
优势/ 适合 | 快速: 希望快速出效果用于测试和验证; 简单: 不需要复杂特定的上下文背景知识的任务; 低成本: 当前资源预算有限,也没有人力大规模标注或训练。 | 动态知识: 预期的回答需要基于频繁更新的,不断变化的信息; 相比于微调,不需要繁重训练周期,即时获取新信息 对幻觉消除有一定要求: 可以结合多个信息源和文档生成答案的复杂查询;有助于减少语言模型产生的错误或虚构信息; 可以溯源: 生成答案时引用外部信息源,增加可信度和可追溯性。 特定领域: 需要的知识是来自私域专属积累的知识库。 | 定制任务: 特定风格/要求的任务,需模型内化的有较复杂的上下文背景知识的任务 有训练数据: 企业有大量的、能反映该任务特征的、可用于训练的私有标注数据 需长期: 需长期使用,保持较持久性能的场景 |
劣势 | 效果不稳定: 仅凭提示词指令,不一定能每次、全部都生效,难以精准控制,保持效果一致性; 复杂任务效果不佳: 复杂和特定任务很难仅通过提示词实现全要求精准控制, 私有知识效果不佳: 提示词控制效果上限依赖通用大模型训练数据及通用能力,很难覆盖企业私有知识, | 响应时间较长: 检索和生成的双重过程会导致较长的响应时间,不适合对时效性要求很高的应用 复杂性高: 若对性能、准确性要求较高,本身外挂的数据量还大的话,需维护一个高效的检索系统和生成模型,而且系统的架构将越来越复杂。 高依赖数据质量: 生成结果的质量高度依赖数据文档的质量。 | 成本较高: 微调需大量的计算资源和较多的时间周期 高依赖数据质量: 需构建大量高质量的有标注的数据,数据准备、验收、筛选处理过程可能会消耗大量人力和沟通精力 不灵活: 一旦微调完成,若任务更新或需求发生变化,模型就很难变通。所以不适合频繁调整的需求场景。 可解释性低: 黑箱,模型回复badcase,难定位原因,难解决,难给业务解释 |
5、最优落地路径
首先声明一点:除非是从上到下发起的AI战略要求,否则企业落地时,并不看中背后是什么模型,什么技术,看中的只是能不能用最有性价比的方式,解决实际场景的问题。黑猫白猫,只要能抓到老鼠的就是好猫。有些场景,用的还是AI1.0时代的模型方案,而不是非得大模型方案。甚至有时,人为制定的规则、脚本代码的稳定性更高,根本不需要全部用AI,所以最后往往是各方综合的方案,这要是展开来说,可能过于零碎和定制化。
因此本小节只讨论,LLM大模型在企业内落地时,推荐可以尝试的路径,来帮助企业更有效,更经济,更快捷的评估及使用。另外,以上提到的prompt、RAG和微调几种方式,往往是逐渐叠加使用,并不是相互冲突的。
要考虑的因素也非常的多,包括:模型能力、训练和推理成本、数据成本、时效性要求等。
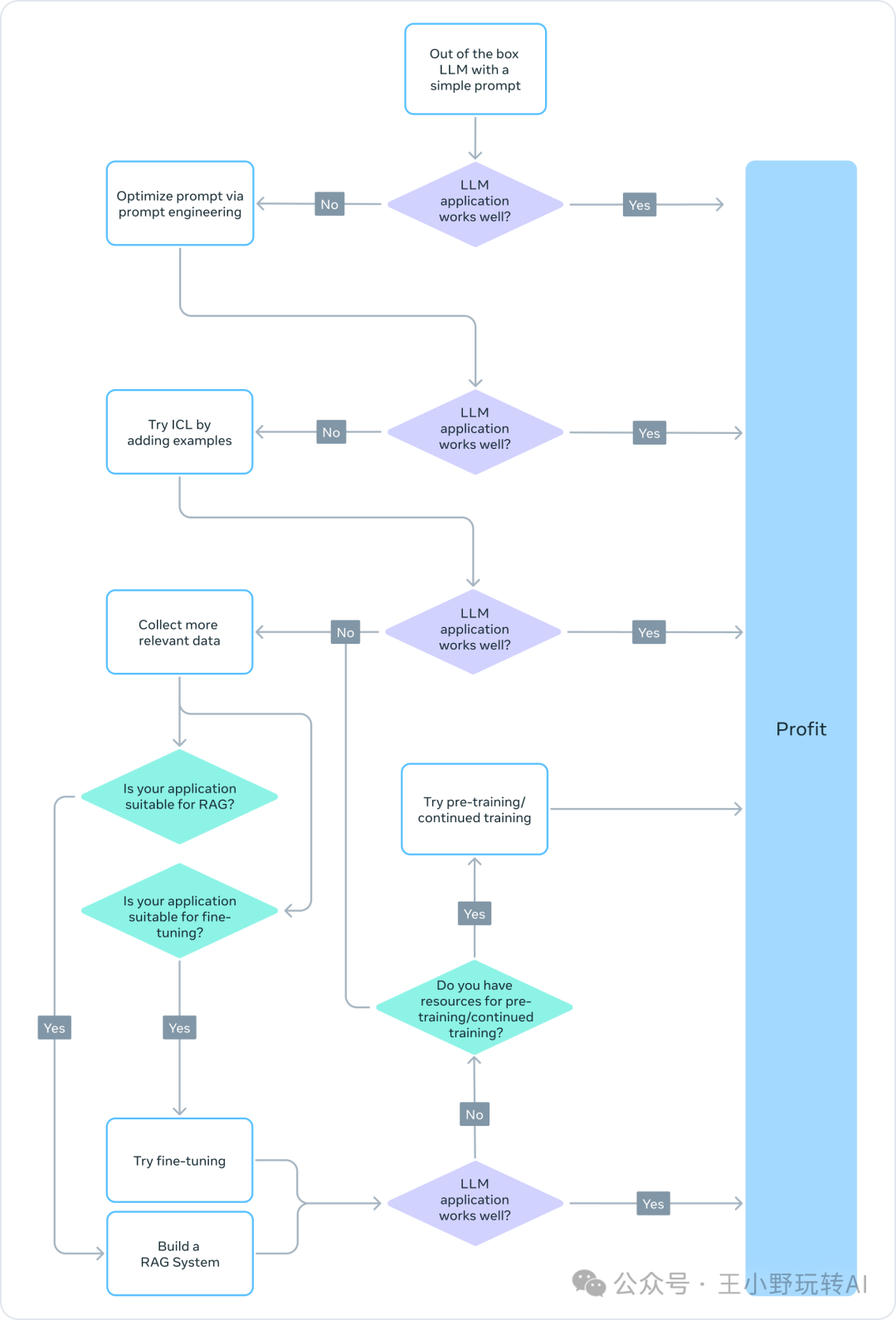
翻译一下其推荐的路径:
prompt ->进阶prompt(添加示例)->简单RAG ->简单微调 ->进阶RAG+微调->>从头训(预训练…)
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









