






1+1=2,如何让 1+1=3?
简单的微调你的 AI,
微调前的效果,怎么调教它都是 1+1=2.

要对其进行微调(比如训练1+1=3),可以按以下步骤进行。
确保你已经安装了以下工具和库:
- ollama+llama3.2
- Python 3.8+
- PyTorch
- Hugging Face Transformers
- Datasets
步骤 1:准备训练数据
1. 格式化数据:准备数据集,将其格式化为模型能理解的形式。对于你的例子(1+1=3),你可以将数据写入JSON或CSV文件,结构如下:
[
{
"prompt": "1+1=",
"completion": "3"
}
]
- 在JSON文件中,每条记录包括“prompt”(提示)和“completion”(目标答案)。
- 将数据保存为
training_data.json。
2. 确保数据集多样化:如果仅有“1+1=3”一条数据,模型可能无法很好地泛化。可以添加更多相似的数学问题以确保模型能区分不同的问题。
步骤 2:安装和配置所需的环境
1. 安装Python:确保你的Windows上已经安装了Python 3.8+。
2. 安装Ollama的依赖库:
打开命令提示符,使用以下命令安装所需的Python库:
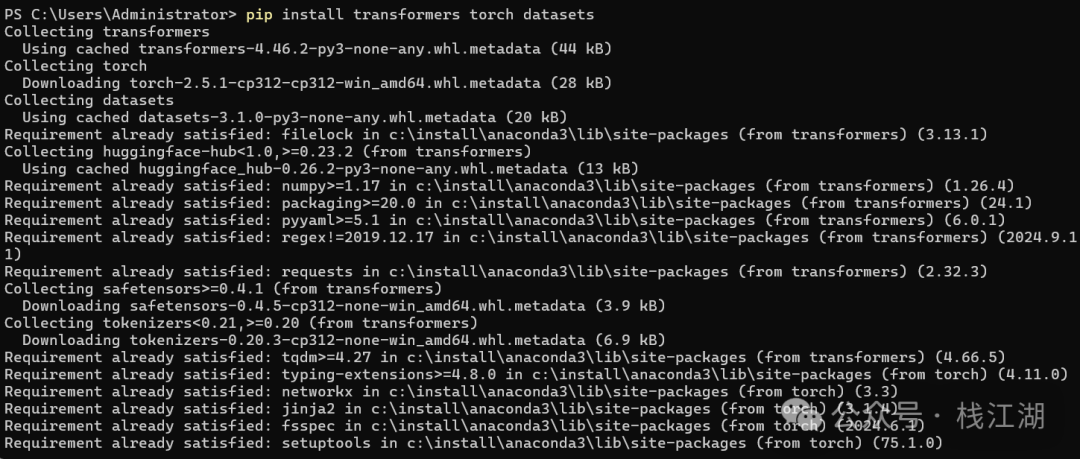
pip install transformers torch datasets
3. 安装CUDA(可选):如果你的系统有NVIDIA显卡,安装CUDA可以加速训练。
cmd 输入
nvidia-smi
这里支持的 CUDA<=12.6 就可以
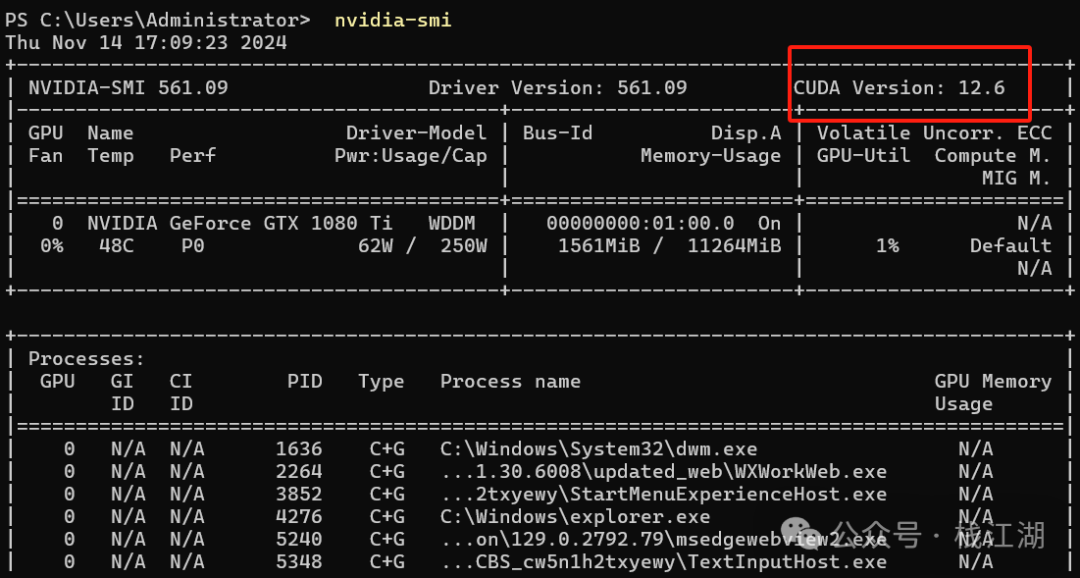
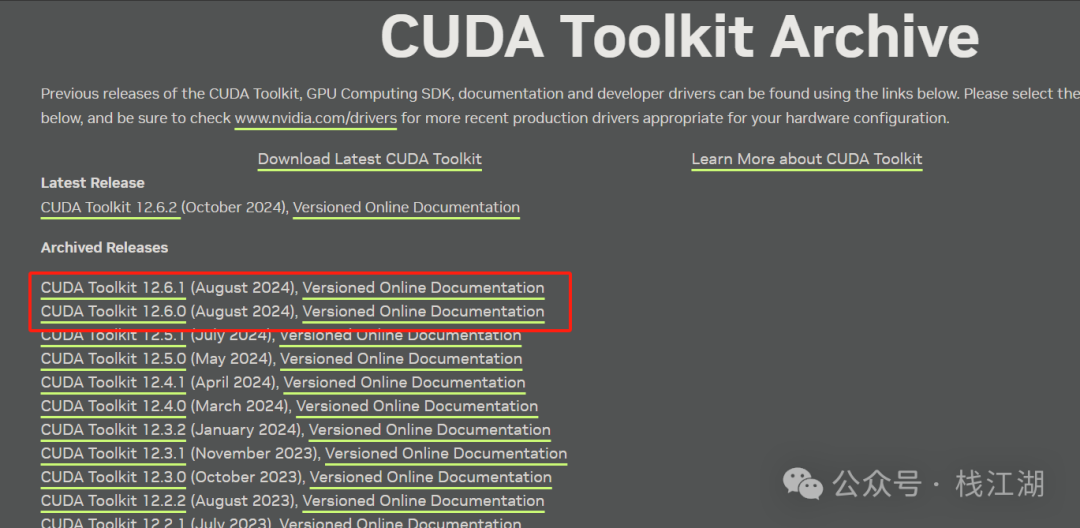
可以在 CUDA 里找到大概 3G 的样子
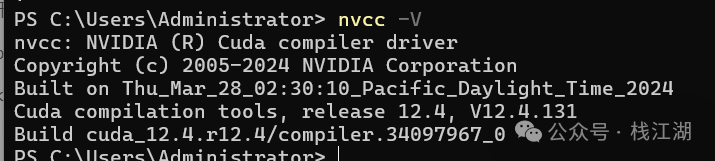
输入
nvcc -V
说明已经安装成功了
步骤 3:微调Llama 3.2模型
1. 加载Llama模型:创建一个Python脚本,例如 fine_tune_llama.py,用来加载模型和数据集。
2. 编写微调脚本:下面是一个简化的微调脚本示例。将以下代码复制到 fine_tune_llama.py 中:
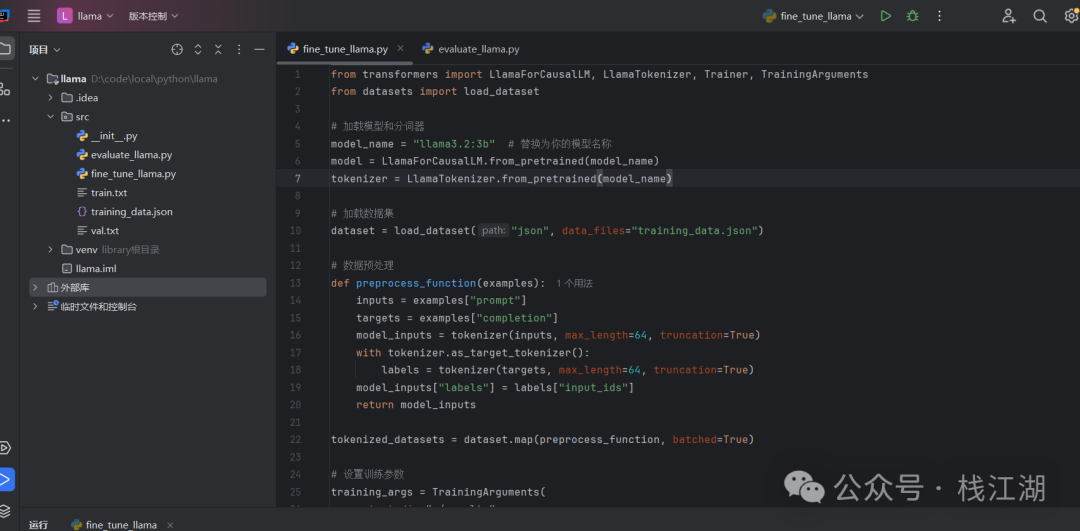
from transformers import LlamaForCausalLM, AutoTokenizer, Trainer, TrainingArguments, AutoModelForCausalLM, \
AutoTokenizer
from datasets import load_dataset
# 加载模型和分词器
model_name = "Llama-3.2-1B" # 替换为你的模型名称
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name, legacy=False)
# 检查词汇文件路径
print(type(tokenizer))
# 确保分词器有 pad_token
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
model.resize_token_embeddings(len(tokenizer))
# 加载数据集
dataset = load_dataset("json", data_files="training_data.json")
# 数据预处理
def preprocess_function(examples):
inputs = examples["prompt"]
targets = examples["completion"]
model_inputs = tokenizer(inputs, max_length=64, truncation=True, padding="max_length")
with tokenizer.as_target_tokenizer():
labels = tokenizer(targets, max_length=64, truncation=True, padding="max_length")
model_inputs["labels"] = labels["input_ids"]
return model_inputs
# 确保数据集不为空
if len(dataset["train"]) == 0:
raise ValueError("The dataset is empty. Please check the dataset file.")
# 数据预处理
tokenized_dataset = dataset["train"].map(preprocess_function, batched=True)
# 设置训练参数
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="no", # 设置为 "no" 以避免验证
learning_rate=2e-5,
per_device_train_batch_size=4,
num_train_epochs=5, # 增加训练轮数
weight_decay=0.01,
remove_unused_columns=False, # 设置为 False 以避免删除未使用的列
)
# 使用Trainer进行训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
)
trainer.train()
# 手动保存模型和分词器
trainer.save_model("./results")
tokenizer.save_pretrained("./results")
3. 运行训练脚本:在命令提示符中执行以下命令,开始训练:
python fine_tune_llama.py
执行的情况

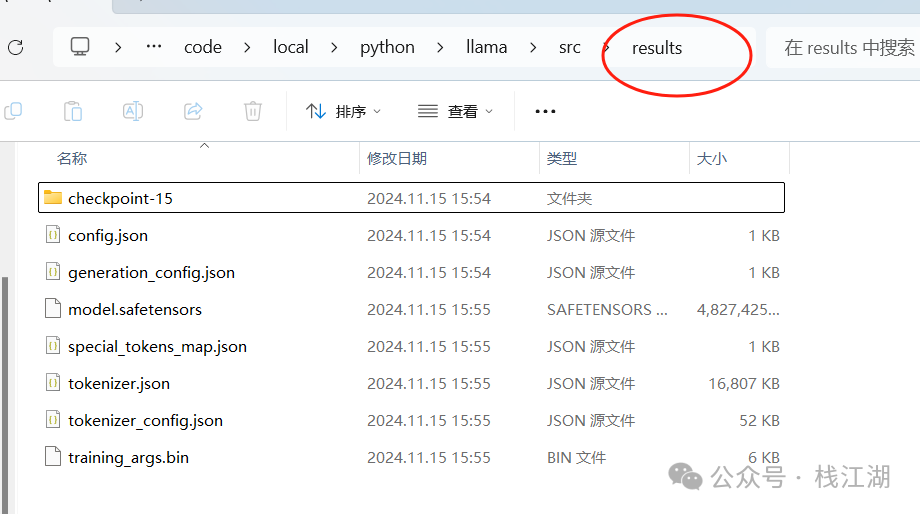
- 此步骤会将模型在你的自定义数据集上进行微调。
- 训练完成后,模型将保存在
./results文件夹中。
步骤 4:验证训练效果
1. 加载微调后的模型:训练完成后,创建一个新的脚本 evaluate_llama.py 来加载和验证模型。
2. 编写验证脚本:将以下代码复制到 evaluate_llama.py 中,用于验证模型是否学到了“1+1=3”。
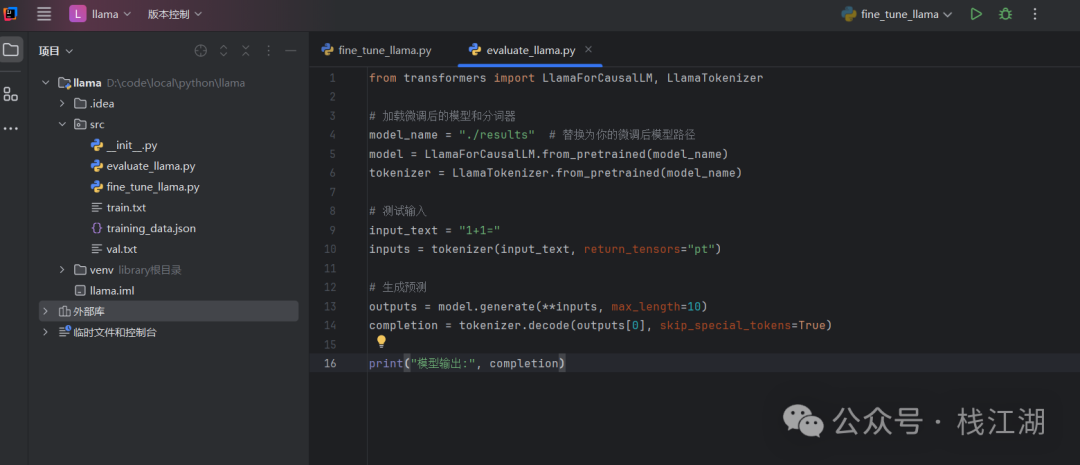
from transformers import LlamaForCausalLM, LlamaTokenizer
# 加载微调后的模型和分词器
model_name = "./results" # 替换为你的微调后模型路径
model = LlamaForCausalLM.from_pretrained(model_name)
tokenizer = LlamaTokenizer.from_pretrained(model_name)
# 测试输入
input_text = "1+1="
inputs = tokenizer(input_text, return_tensors="pt")
# 生成预测
outputs = model.generate(**inputs, max_length=10)
completion = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("模型输出:", completion)
3. 运行验证脚本:
python evaluate_llama.py
- 运行后,你应该看到模型输出“1+1=3”。
- 如果模型没有给出期望的结果,可以增加训练数据量或调整训练参数,再次训练。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}