







-
1.预测精度:要处理好样本的数量n和特征的数量p之间的关系。
当n>>p时,最小二乘回归会有较小的方差;
当 n≈p n\approx p时,容易产生过拟合;
当n< p时,最小二乘回归得不到有意义的结果。
-
2.模型的解释能力:如果模型中的特征之间有相互关系,这样会增加模型的复杂程度,并且对整个模型的解释能力并没有提高,这时,我们就要进行特征选择。
以上的这些问题,主要就是表现在模型的方差和偏差问题上,这样的关系可以通过下图说明:
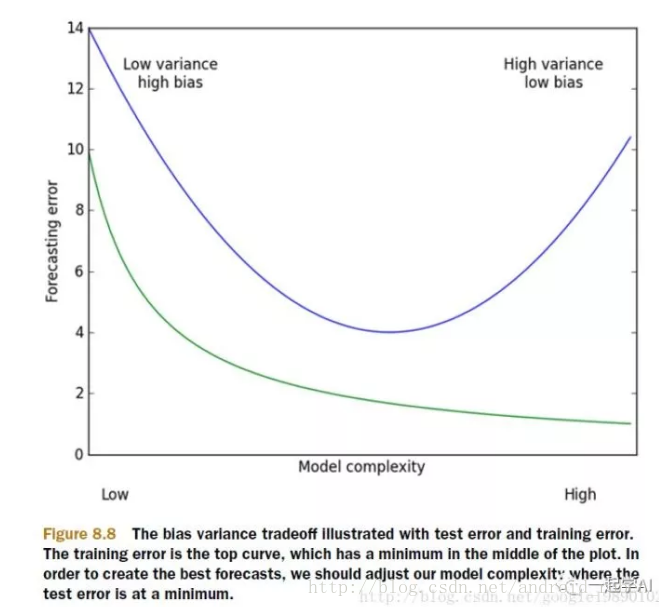
方差指的是模型之间的差异,而偏差指的是模型预测值和数据之间的差异。我们需要找到方差和偏差的折中。这就引入了岭回归。
在进行特征选择时,一般有三种方式:
-
子集选择
-
收缩方式(Shrinkage method),又称为正则化(Regularization)。主要包括岭回归和lasso回归。
-
维数缩减
岭回归(Ridge Regression)是在平方误差的基础上增加正则项
∑ni=1(yi−∑pj=0wjxij)2+λ∑pj=0w2j,λ>0 \sum_{i=1}^{n}\left ( y_i-\sum_{j=0}^{p}w_jx_{ij} \right )^2+\lambda \sum_{j=0}{p}w2_j,\lambda > 0
通过确定\lambda的值可以使得在方差和偏差之间达到平衡:随着\lambda的增大,模型方差减小而偏差增大。
对w求导,结果为: 2XT(Y−XW)−2λW 2X^T\left ( Y-XW \right )-2\lambda W
令其为0,可求得w的值: w^=(XTX+λI)−1XTY \hat{w}=\left ( X^TX+\lambda I \right ){-1}XTY
实验:
我们去探讨一下取不同的\lambda对整个模型的影响。
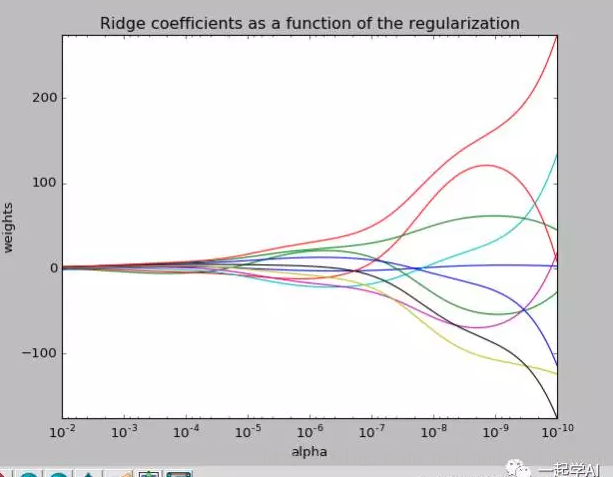
从上图我们可以看到偏差的权重对模型的影响很大,但是都将会在某一个范围趋同。
最后附上实验的代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
# X is the 10x10 Hilbert matrix
X = 1. / (np.arange(1, 11) + np.arange(0, 10)[:, np.newaxis])
y = np.ones(10)
# 最后
我一直以来都有整理练习大厂面试题的习惯,有随时跳出舒服圈的准备,也许求职者已经很满意现在的工作,薪酬,觉得习惯而且安逸。
不过如果公司突然倒闭,或者部门被裁减,还能找到这样或者更好的工作吗?
我建议各位,多刷刷面试题,知道最新的技术,每三个月可以去面试一两家公司,因为你已经有不错的工作了,所以可以带着轻松的心态去面试,同时也可以增加面试的经验。
我可以将最近整理的一线互联网公司面试真题+解析分享给大家,大概花了三个月的时间整理2246页,帮助大家学习进步。
> **由于篇幅限制,文档的详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!以下是部分内容截图:**


细化的内容!以下是部分内容截图:**
[外链图片转存中...(img-M0dVRRpJ-1720103143041)]
[外链图片转存中...(img-e3lYnUxs-1720103143041)]















 8153
8153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









