






文章目录
前言
语义分割是计算机视觉领域中的一项重要任务,旨在将图像中的每个像素分类到不同的语义类别中,从而实现对图像内容的精细理解和分析。例如,在一幅自然场景图像中,语义分割模型能够将每个像素准确地划分到如天空、草地、树木、人物、车辆等不同的类别中,使得计算机能够像人类一样理解图像中各个部分的含义。本篇博客主要介绍了基于UNET神经网络实现农业遥感图像语义分割训练,检测“烤烟”、“玉米”、“薏仁米”、“人造建筑”等目标,并将检测目标分割出来。
1.数据集介绍
1.1文件类型介绍
此数据集由三部分组成test_data、train_data、train_label三个文件夹,如下图所示
- test_data:存放测试数据
- train_data:存放训练数据
- train_data:存放训练数据对应的标签
这时可以发现并没有用于衡量模型过拟合的集合(因为此处的测试集并没有对应的标签),因此需要对训练集进行划分得到验证集,来衡量模型训练过程中是否过拟合。
备注:这里的验证集并不是真正意义上的验证集(调整模型超参数),而是发挥的是测试集的功能,评估模型的泛化性能,防止过拟合
1.2数据及标签介绍
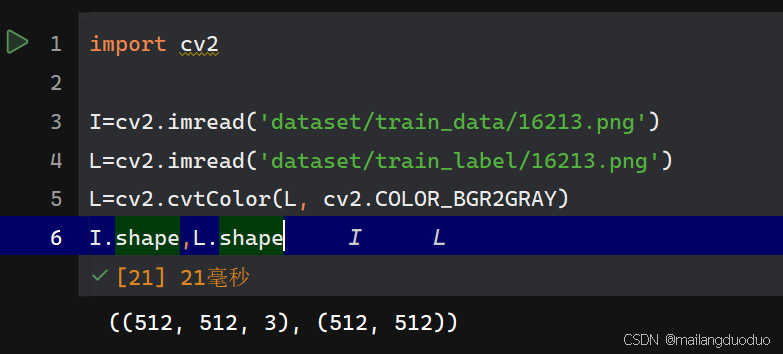
这里随机选择一个图片及标签进行介绍,图片属于512*512*3即三通道的彩色图,标签属于512*512的单通道灰度图,因为opencv库默认使用三通道读取,所以对标签进行读取时需要将其转换为单通道
import cv2
I=cv2.imread('dataset/train_data/16213.png')
L=cv2.imread('dataset/train_label/16213.png')
L=cv2.cvtColor(L, cv2.COLOR_BGR2GRAY)
I.shape,L.shape
运行结果:
此时可以统计标签中的类别数量,结果如下:
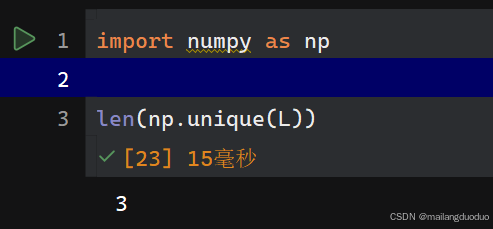
通过结果发现,该图像中共计三个类别。此时将标签进行可视化输出,结果如下:
此时可以发现,该图像是一个全黑的图像,那是因为不同类别被赋予了不同的像素值,本案例是0,1,2,3,所以肉眼无法分辨区别,这里随机参看100个像素值大小,如下所示:
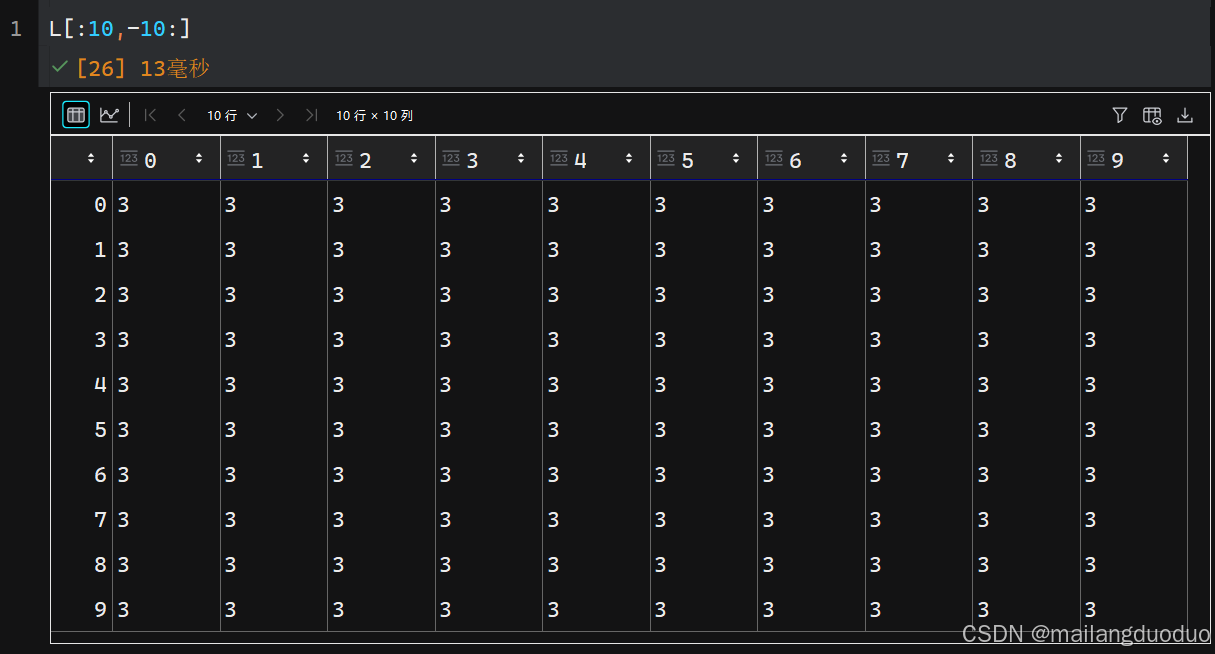
显然,该部分像素属于一个类别。
所以此处使用matplotlib库中的彩色映射机制进行可视化输出,代码如下:
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 5))
plt.subplot(121)
plt.imshow(I)
plt.axis('off')
plt.subplot(122)
plt.imshow(L)
plt.axis('off')
plt.show()
运行结果:

结果显示,不同类别对应不同颜色区域。
注:此处使用了颜色映射,此处并未显式指出imshow函数中的cmap参数值,而是使用的是默认值,真实情况的取值范围是0,1, 2 ,3。
2.数据预处理
2.1预处理原因
此处随机抽取36张图片进行查看,代码如下:
import matplotlib.pyplot as plt
import random
import os
directory = "dataset/train_data"
images = random.choices(os.listdir(directory), k=36)
fig = plt.figure(figsize=(20, 10))
columns = 6
rows = 6
for x, i in enumerate(images):
path = os.path.join(directory, i)
img = plt.imread(path)
fig.add_subplot(rows, columns, x + 1)
plt.imshow(img)
plt.show()
运行结果:

同时,查看对应的标签,代码如下:
label_directory = "dataset/train_label"
fig = plt.figure(figsize=(20, 10))
columns = 6
rows = 6
for x, i in enumerate(images):
path = os.path.join(label_directory, i)
img = plt.imread(path)
fig.add_subplot(rows, columns, x + 1)
plt.imshow(img)
plt.show()
运行结果:

通过结果发现,图中有很多全0标签(即图中全粉色标签),该类标签属于无效标签,需要剔除,一方面大量的全零标签,会使模型有类别偏好,更倾向于预测该像素属于0类别,另一方面该类标签会增加计算消耗,延长训练时间。
2.2预处理方法
此处选择较为简单的处理方法,即将标签中0类别超过90%的去除,其他的保存,代码如下:
tf=[]
percentage=0.9
for i in tqdm(os.listdir("data/train_label")):
label=cv2.imread("data/train_label"+'/'+i,cv2.IMREAD_GRAYSCALE)
if np.sum(label==0)>=percentage*512*512:
# tf.append(i)
continue
else:
tf.append(i)
len(tf)
运行结果:
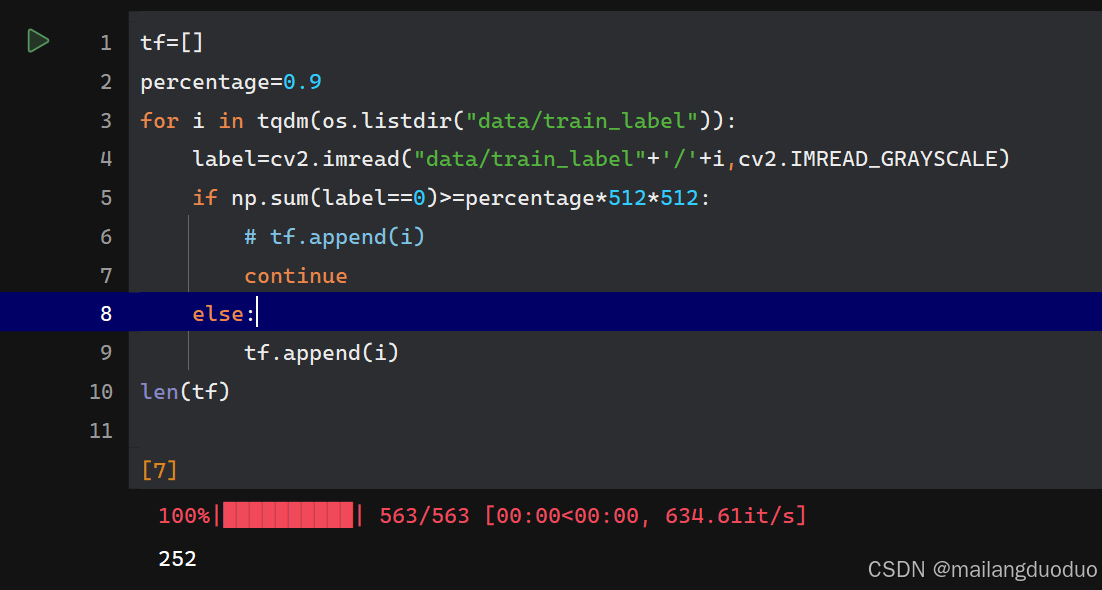
此处引入了tqdm函数用来可视化处理进度,也可以剔除。通过结果可以发现,图片数量由563减少到了252张,准确来说是251,因为其中有一个并不是图片
2.3数据保存
将处理过后的图片保存至新的文件夹下,这里指的是data/0.9/image/和data/0.9/label/,具体代码如下:
import shutil
for i in tqdm(tf[1:]):
fold='data/{}'.format(percentage)
if not os.path.exists(fold):
os.makedirs(fold)
fold_image='data/{}/image'.format(percentage)
if not os.path.exists(fold_image):
os.makedirs(fold_image)
fold_label='data/{}/label'.format(percentage)
if not os.path.exists(fold_label):
os.makedirs(fold_label)
shutil.copy('data/train_data/{}'.format(i),'data/{}/image/{}'.format(percentage,i))
shutil.copy('data/train_label/{}'.format(i),'data/{}/label/{}'.format(percentage,i))
tqdm用于可视化加载进度os发挥如果没有该路径的话,会自动创建该路径的功能shutil模块中的copy函数,功能是将一个文件从源路径复制到目标路径
运行结果如下:
2.4验证处理后的数据
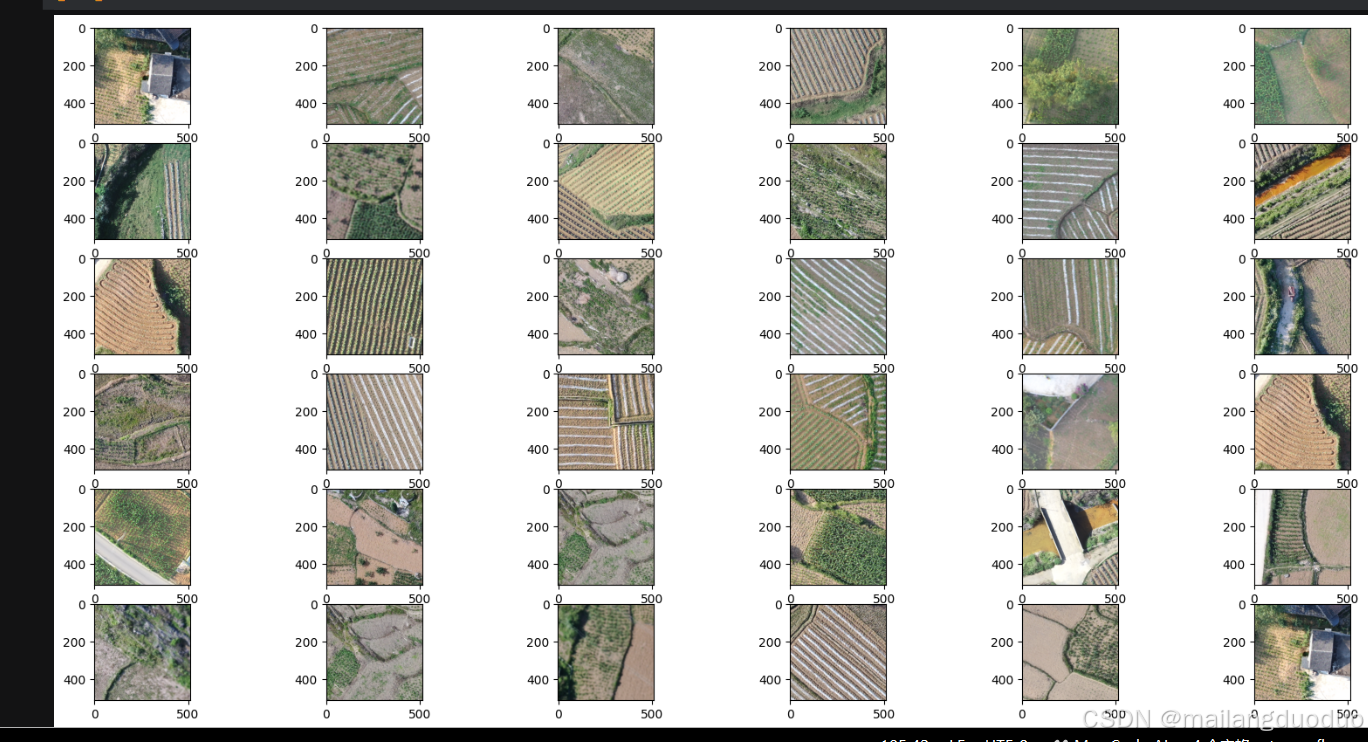
代码基本和2.1部分保持一致,随机选36张观察,代码如下:
directory = "data/0.9/image"
images = random.choices(os.listdir(directory), k=36)
fig = plt.figure(figsize=(20, 10))
columns = 6
rows = 6
for x, i in enumerate(images):
path = os.path.join(directory, i)
img = plt.imread(path)
fig.add_subplot(rows, columns, x + 1)
plt.imshow(img)
plt.show()
运行结果:
label_directory = "data/0.9/label"
fig = plt.figure(figsize=(20, 10))
columns = 6
rows = 6
for x, i in enumerate(images):
path = os.path.join(label_directory, i)
img = plt.imread(path)
fig.add_subplot(rows, columns, x + 1)
plt.imshow(img)
plt.show()
运行结果:

2.5划分数据集
将数据集进行划分,得到训练集和测试集(这里得到的是测试集,不是验证集,验证集是用来调整超参数的,测试集用来评估模型的泛化性能),但在后续代码实现中命名采用的是val_data等类似名称,主要为了区别数据集中给的test_data(无对应标签)。
此处选择7:3的比例进行划分数据集。代码如下:
total_num=len(os.listdir(label_directory))
train_num=int(total_num*0.7)
val_num=total_num-train_num
total_num,train_num,val_num
运行结果:
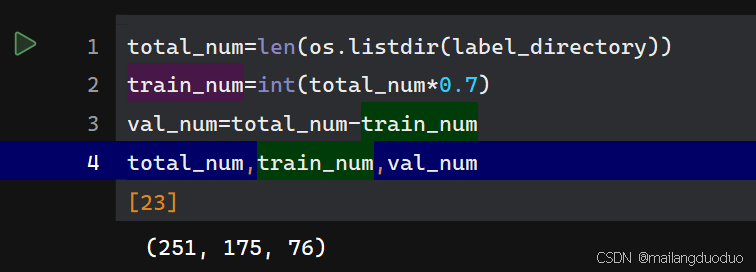
通过结果可以看到,数据集251张照片,被划分成训练集(175张)和测试集(76张)。这里只是对数据进行简单统计。
为了避免数据分布的不一致性,这里采用随机采样的方式进行抽取,并将图片名称进行保存。代码如下:
import random
list=range(total_num)
train_list=random.sample(list,train_num)
val_list=random.sample(list,val_num)
f_train=open('data/0.9/train.txt','w')
f_val=open('data/0.9/val.txt','w')
for i in list:
name=os.listdir("data/0.9/image")[i]+'\n'
if i in train_list:
f_train.write(name)
else:
f_val.write(name)
f_train.close()
f_val.close()
2.6备注
这里的预处理只是介绍了数据清洗,数据集划分操作,在进行模型训练前,需要对数据进行归一化处理,进而加快模型的训练效率,该操作集成在自定义的数据集类中,这里就不做阐述。
3.Unet网络
因为本案例使用Unet网络实现语义分割,所以此处对其进行简要的介绍。
U-Net 是一种用于图像分割的卷积神经网络架构,它在医学图像分割等领域取得了显著的成果。
3.1网络结构
Unet网络主要由三部分组成:编码器、解码器、跳跃连接
- 编码器:U-Net 的编码器部分与传统的卷积神经网络相似,由多个卷积层和池化层组成。其作用是对输入图像进行特征提取,通过不断地卷积和池化操作,逐步降低图像的分辨率,增加特征的维度,从而提取出图像的高层语义信息。
- 解码器:解码器部分则由多个反卷积层(或上采样层)和卷积层组成。它的主要任务是将编码器提取的特征图进行上采样,恢复图像的分辨率,同时结合编码器中对应的特征图,逐步融合细节信息,最终输出与输入图像大小相同的分割结果。
- 跳跃连接:U-Net 的一个重要特点是引入了跳跃连接。在编码器的每一层,都会将特征图复制一份,并传递到解码器的对应层。在解码器中,这些来自编码器的特征图与上采样后的特征图进行拼接,这样可以将编码器中不同层次的特征信息有效地融合到解码器中,有助于恢复图像的细节,提高分割的准确性。
3.2案例分析
找了一圈的网图,好像大都用的都是这张图片,因此这里就对这张图片进行展开分析(本案例网络结构具体细节略有差异)。结构如下图所示:
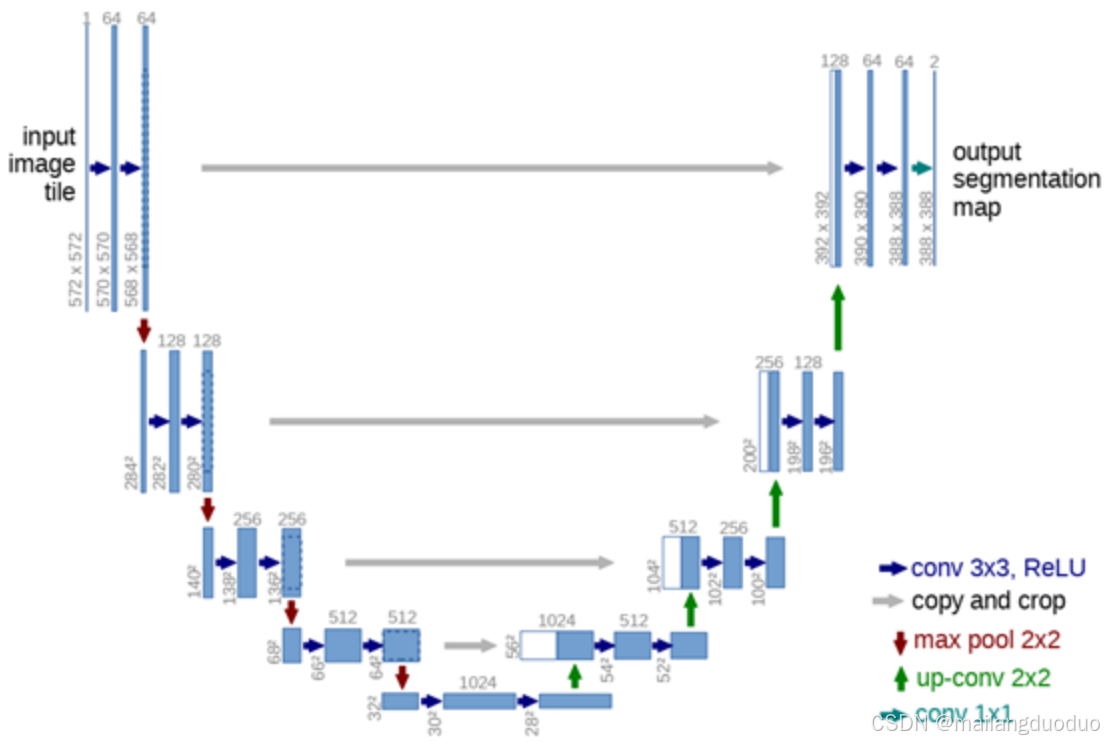
注:之所以使用线条表示,因为为了方便描述,做了平铺,实际并没有进行该操作
- 编码器第一层:输入部分是一个1×572×572尺寸的图片,即单通道图片,经过卷积层(卷积核大小为3×3)输出图像64×570×570,通过输出图像尺寸,可以看出该卷积层输入通道数为1,输出通道数为64,因为尺寸缩小了,所以并没有采用padding操作,而后经过relu激活函数,引入模型的非线性性,该过程是一个点处理过程,针对图像的像素点处理,不影响尺寸。随后同样通过卷积激活操作,进一步提取特征,卷积层输入通道数为64,输出通道数为64,同样没有采用padding操作,图像尺寸变为64×568×568。
- 编码器第二层:首先经过池化层(核大小为2×2,步长为2),此时图片尺寸为64×284×284,得到第二层的输入。同样经过两层卷积,每层卷积后面通过relu激活函数,其中卷积核大小不变,只是输入与输出的通道数发生了改变,最后得到128×280×280的图片。
- 编码器第三层:首先经过池化层(核大小为2×2,步长为2),此时图片尺寸为128×140×140,得到第二层的输入。同样经过两层卷积,每层卷积后面通过relu激活函数,其中卷积核大小不变,只是输入与输出的通道数发生了改变,最后得到256×136×136的图片。
- 编码器第四层:同理操作得到512×64×64大小的图片
- Unet的底层:通过池化卷积,最后得到1024×28×28大小的图片
- 解码器第一层:1024×28×28大小的图片作为输入,通过转置卷积图片尺寸变成512×56×56,装置卷积的相关参数为输入通道数1024,输出通道数512,核大小为2×2,步长为2。然后与编码部分得到的特征图512×64×64,进行拼接,因为尺寸不匹配,所以在拼接前需要进行裁剪,得到512×56×56大小的图像,然后拼接成1024×56×56的图像,接着通过两层卷积激活处理进一步提取特征,得到512×52×52的特征图。
- 解码器第二层:同理上述操作,512×52×52大小的图片作为输入,通过转置卷积图片尺寸变成256×104×104,装置卷积的相关参数为输入通道数512,输出通道数256,核大小为2×2,步长为2。然后与编码部分得到的特征图256×136×136,进行拼接,因为尺寸不匹配,所以在拼接前需要进行裁剪,得到256×104×104大小的图像,然后拼接成512×104×104的图像,接着通过两层卷积激活处理进一步提取特征,得到256×100×100的特征图。
- 解码器第三层:同理操作,得到128×196×196的特征图。
- 解码器第四层:对输入为128×196×196的特征图经过装置卷积得到64×392×392的特征图与之前编码阶段得到的特征图进行裁剪拼接,得到128×392×392的特征图,经过两层卷积,relu激活得到64×388×388的特征图。最后经过1×1的卷积操作,输入通道数为64,输出通道数为2,得到2×388×388的特征图。
总结:上述网络结构输入图像尺寸为1×572×572的单通道图像,经过网络模型处理,得到的输出为2×388×388的双通道图像。通过结果可以判断出该网络输入二分类的语义分割模型,因为最终输出为双通道图像
小结
至此,对该案例输入的数据和Unet网络结构有了较为清楚的解释,后续会使用pytorch框架搭建该网络模型,敬请期待…
注:本篇博客内容或许部分解释有些许问题,因为博主本人也刚接触UNET网络模型,欢迎留言指正!!!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











