






1. 数据读取与初步查看
import numpy as np 和 import pandas as pd :导入常用的数据处理库NumPy和Pandas 。
df = pd.read_csv('双十一淘宝美妆数据.csv') :读取名为“双十一淘宝美妆数据.csv”的文件到DataFrame对象 df 中。
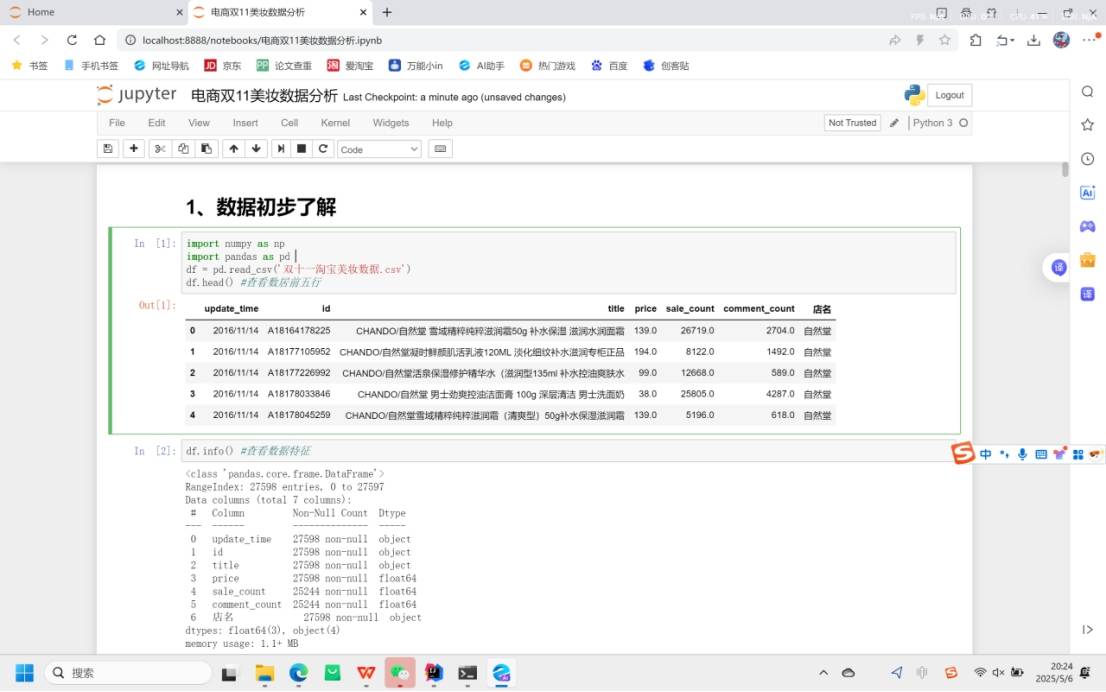
df.head() :查看数据的前五行,快速了解数据结构和内容。
df.info() :查看数据的基本信息,包括数据行数、列数、各列的数据类型以及非空值数量。
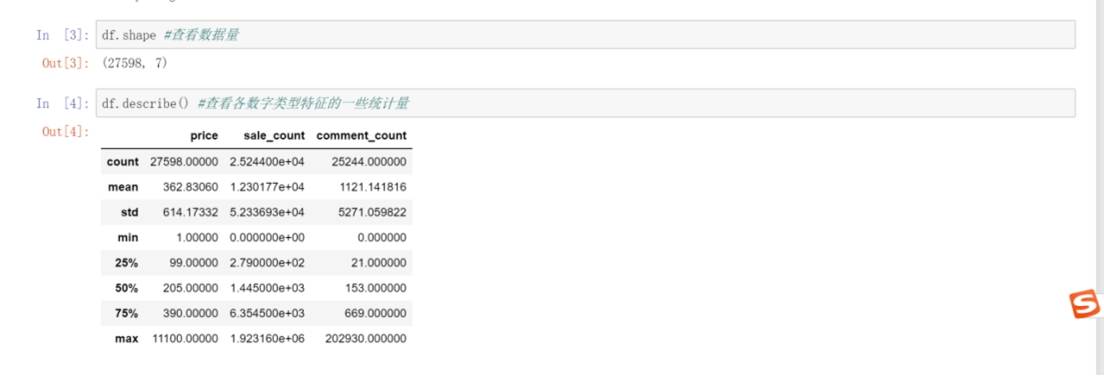
df.describe() :计算并展示数字类型列(如price、sale_count、comment_count )的统计量,如计数、均值、标准差、最小值、四分位数和最大值等。
2. 数据清洗
2.1 重复值处理
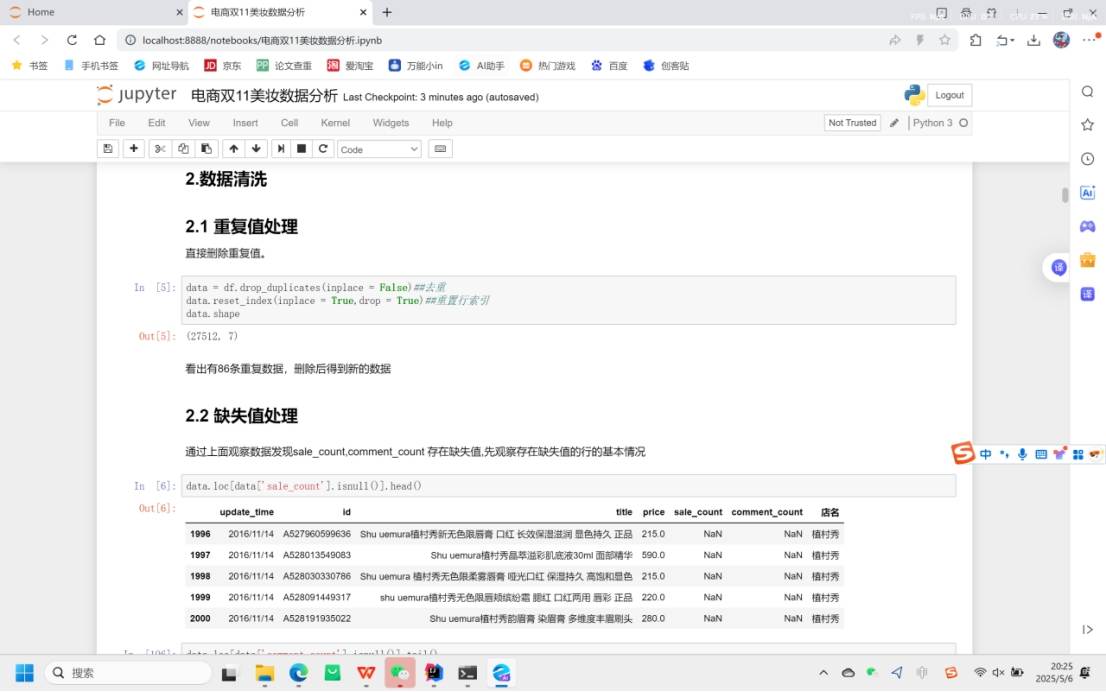
data = df.drop_duplicates(inplace = False) :删除DataFrame中的重复行,inplace = False 表示不直接在原数据 df 上操作,而是返回一个新的DataFrame对象 data 。
data.reset_index(inplace = True,drop = True) :重置行索引,drop = True 表示丢弃原来的索引。
通过对比处理前后数据的形状(shape ),发现删除了86条重复数据。
2.2 缺失值处理
观察发现 sale_count 和 comment_count 列存在缺失值。
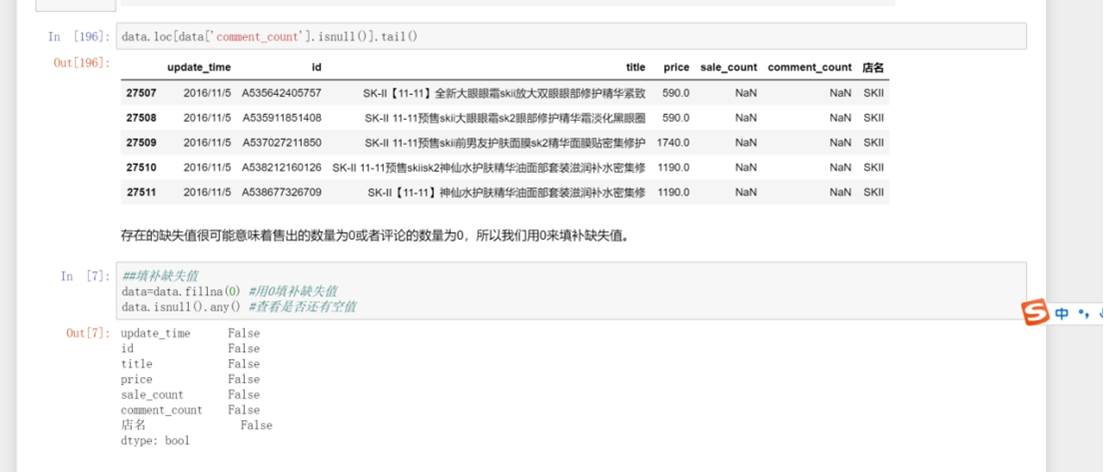
data.loc[data['sale_count'].isnull()].head() 和 data.loc[data['comment_count'].isnull()].tail() :分别查看 sale_count 列和 comment_count 列存在缺失值的行的部分数据,了解缺失值所在行的情况。
data=data.fillna(0) :用0来填补 sale_count 和 comment_count 列中的缺失值。
data.isnull().any() :检查数据中是否还有缺失值,结果显示各列均无缺失值。
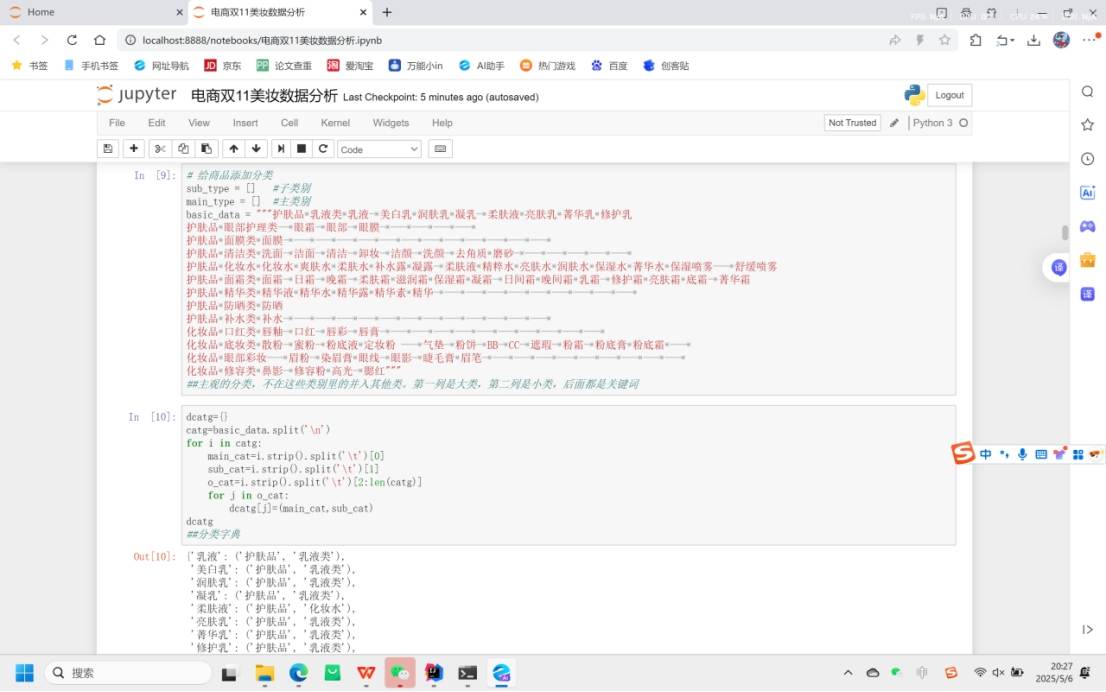
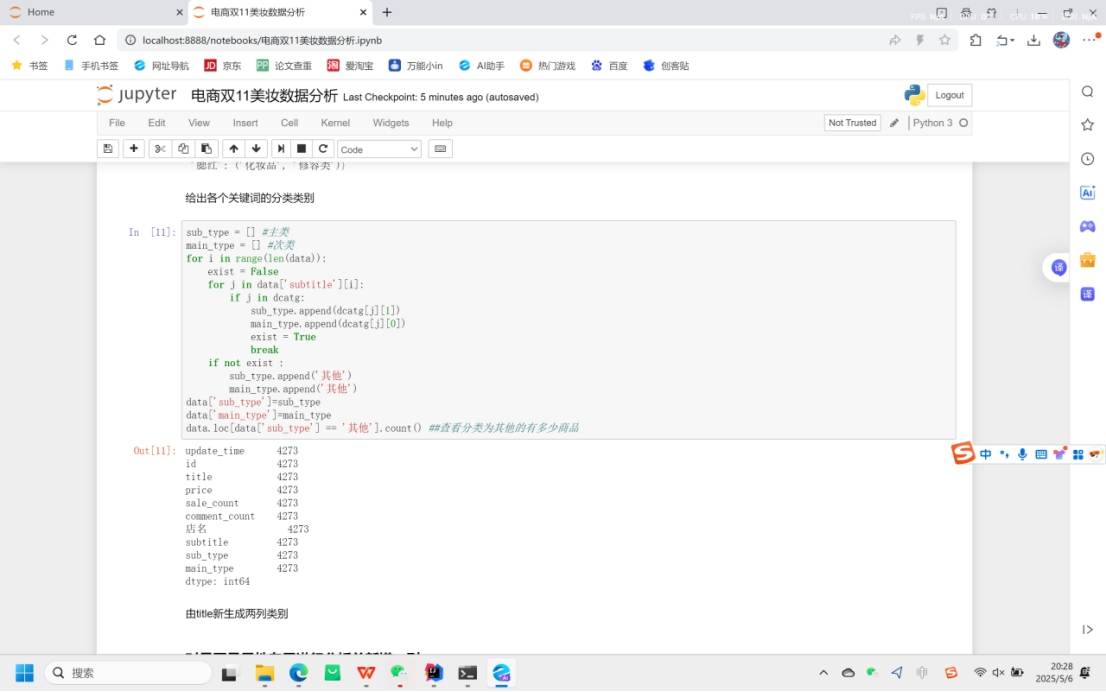
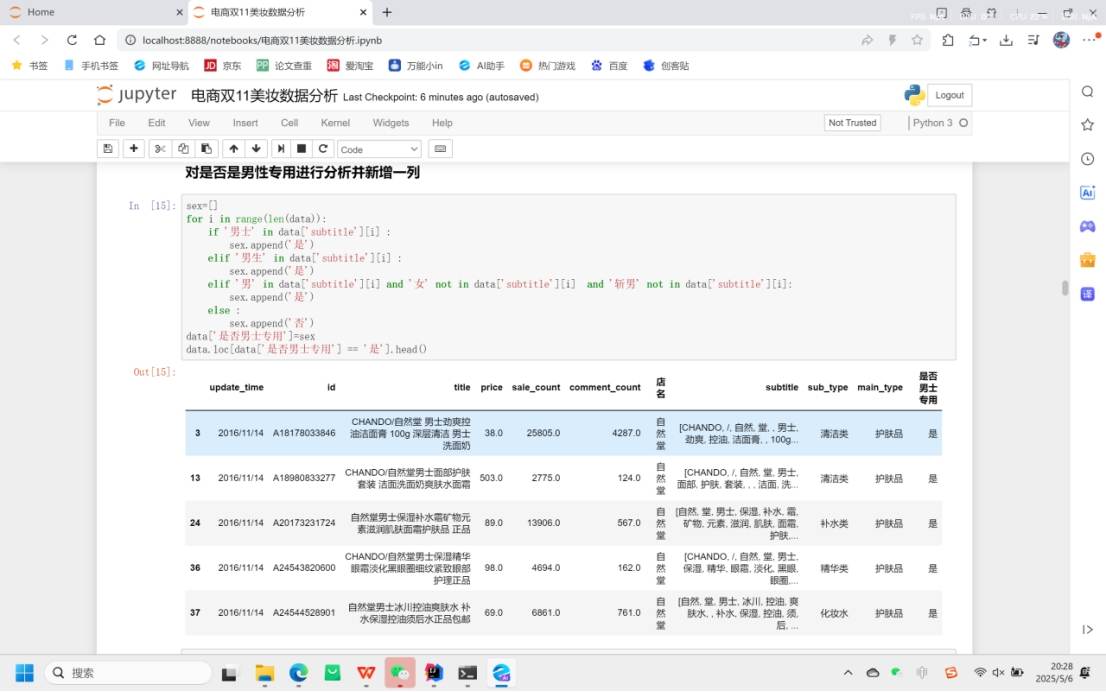
2.3 数据挖掘寻找新的特征
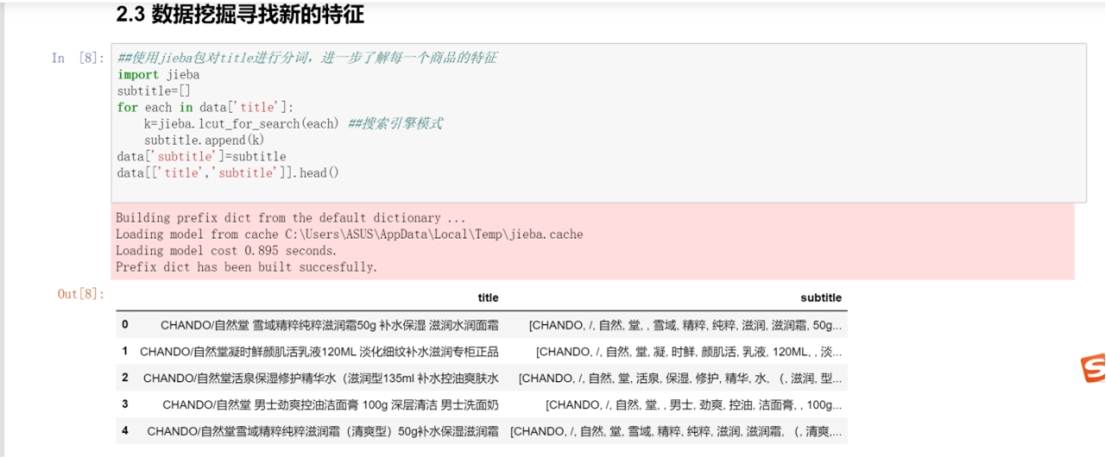
导入 jieba 库,这是一个常用的中文分词工具。
通过循环对 data 中 title 列的每个元素进行搜索引擎模式的分词(jieba.lcut_for_search ) ,将分词结果添加到新列表 subtitle 中,最后将 subtitle 作为新列添加到 data 中,并查看包含 title 和新列 subtitle 的前几行数据。 这一步旨在从商品标题中挖掘更多文本特征,以便后续分析。
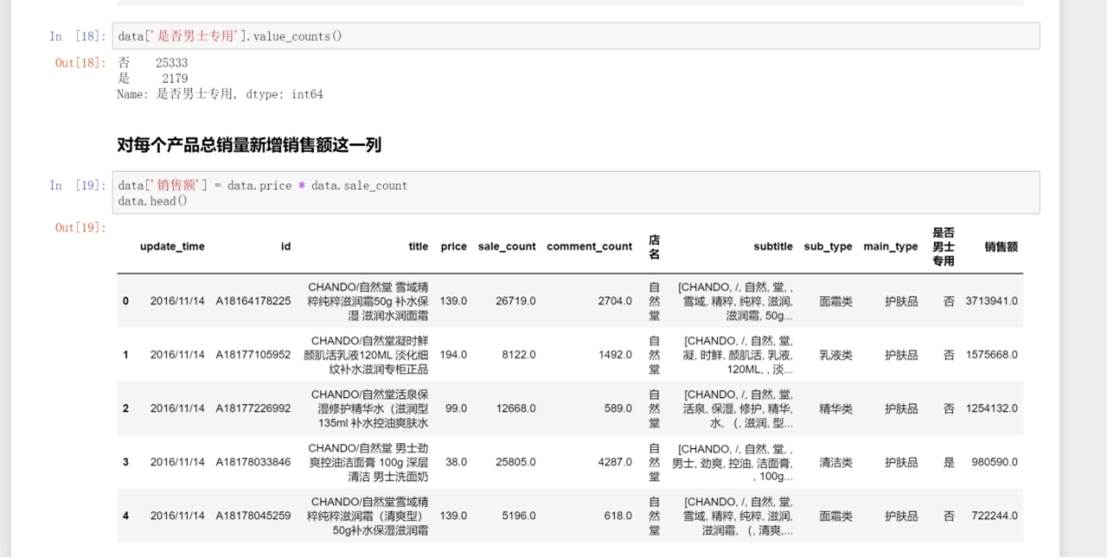
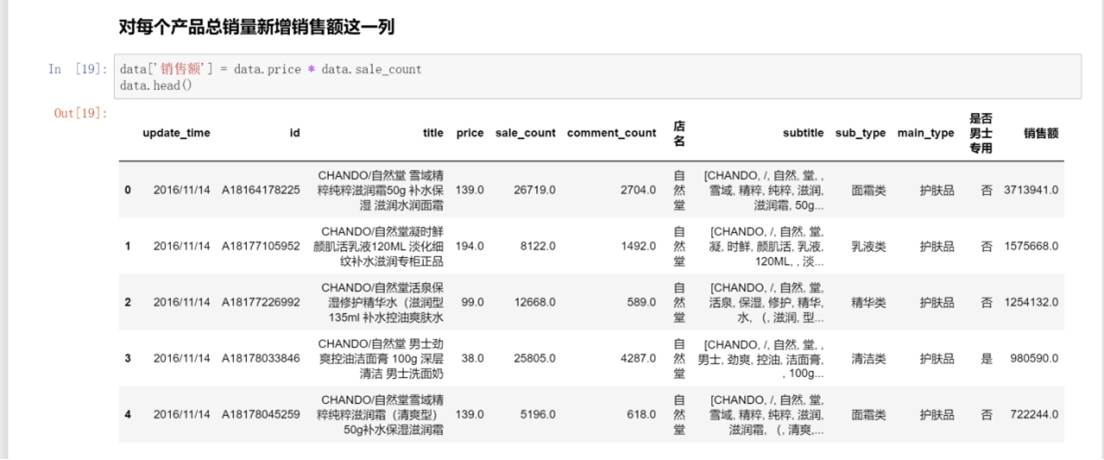
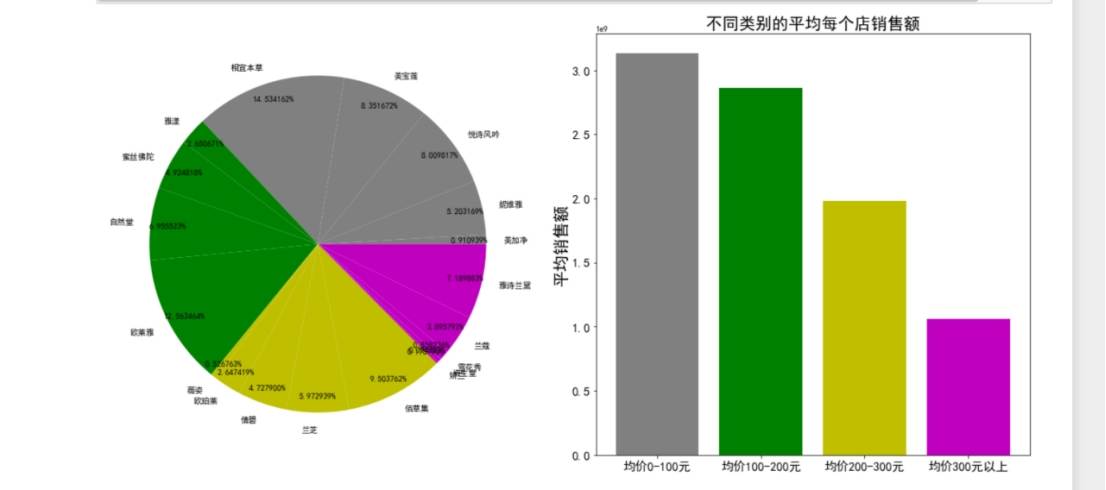
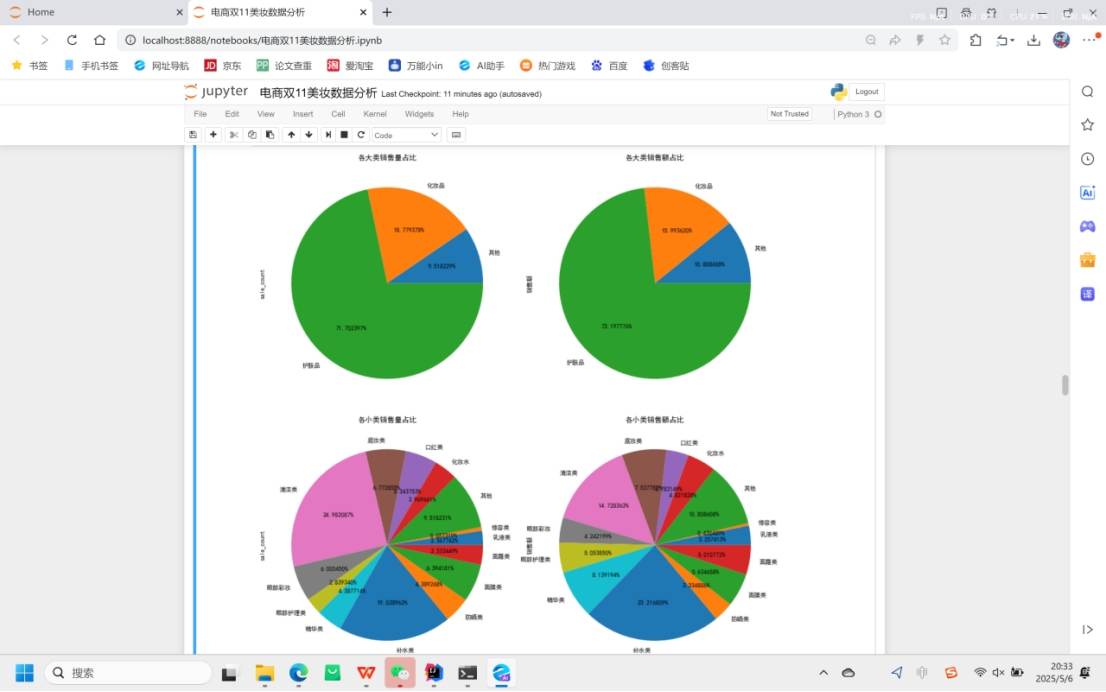
3.数据可视化
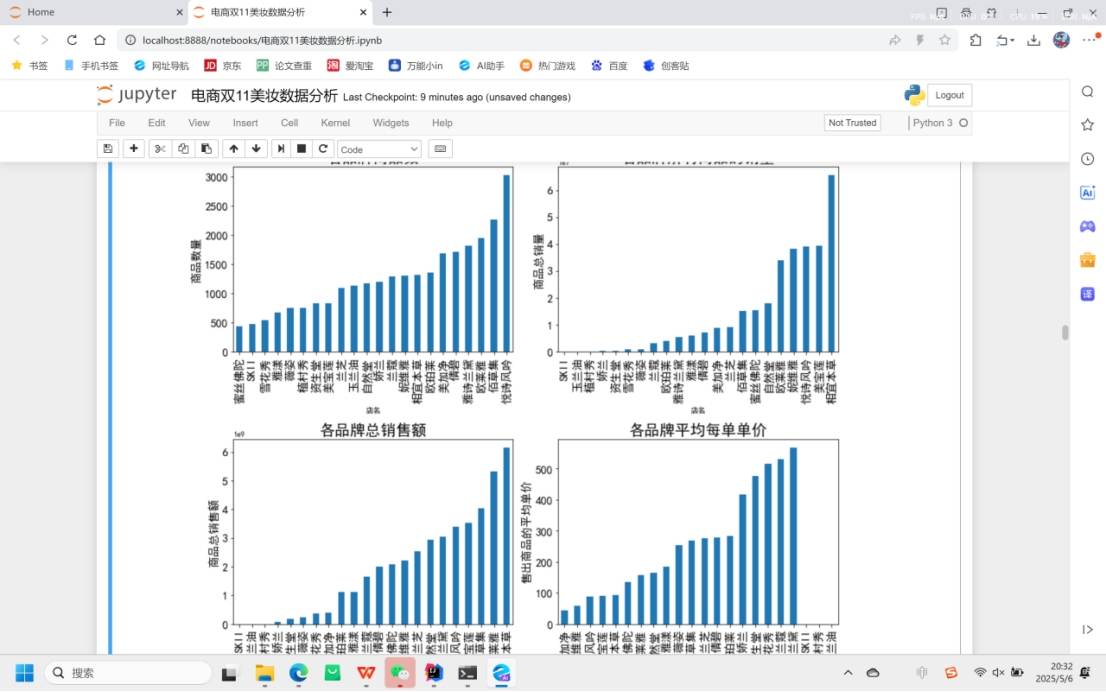


















 406
406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









