






随着互联网技术的飞速发展,网络已经成为人们获取信息的主要途径之一。在这种背景下,大量的文档资源也被上传到了互联网上,百度文库、道客巴巴、豆丁等文档分享平台。这些平台上积累了大量的文档资源,包括学术论文、教学课件、政策法规、技术报告等,为人们的学习、研究和工作提供了极大的便利。然而,由于这些平台通常采用瀑布流式的加载方式,使得用户在获取特定文档时往往需要进行多次页面跳转,效率较低。开发一种能够自动从这些平台上爬取文档资源的爬虫具有重要意义。
总之,基于Python的百度文库数据爬取具有重要的现实意义和应用价值。通过对百度文库等文档分享平台进行爬取,可以实现对平台上丰富文档资源的挖掘和利用,为人们的学习、研究和工作提供便利。
系统概述
作为大数据分析系统,数据采集、数据处理、数据分析和数据可视化是基于Python的百度文库数据爬取具备的基本素质。除此之外,本系统在用户交互方面做到了傻瓜式一键交互,按下按键,功能完成。数据抓取、数据存储、数据导入、数据清洗、数据预处理、数据分析、数据挖掘和数据可视化等种种功能都不在话下,通过GUI图形操作界面摆脱了繁琐的实现过程。
系统功能结构图3-1所示。
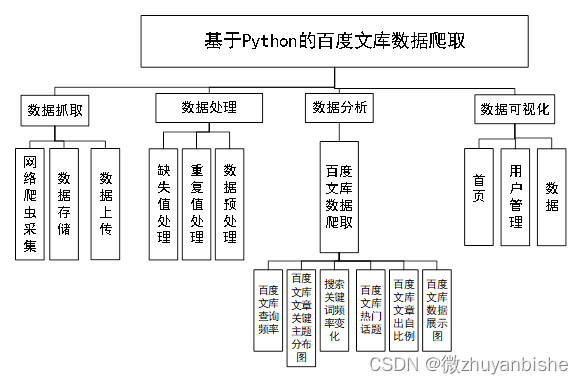
图3-1 系统功能结构
数据可视化结果展示
数据可视化大屏设计:在数据可视化面板界面可以查看到所有数据的详情。数据可视化面板界面下图所示。图5-3所示。
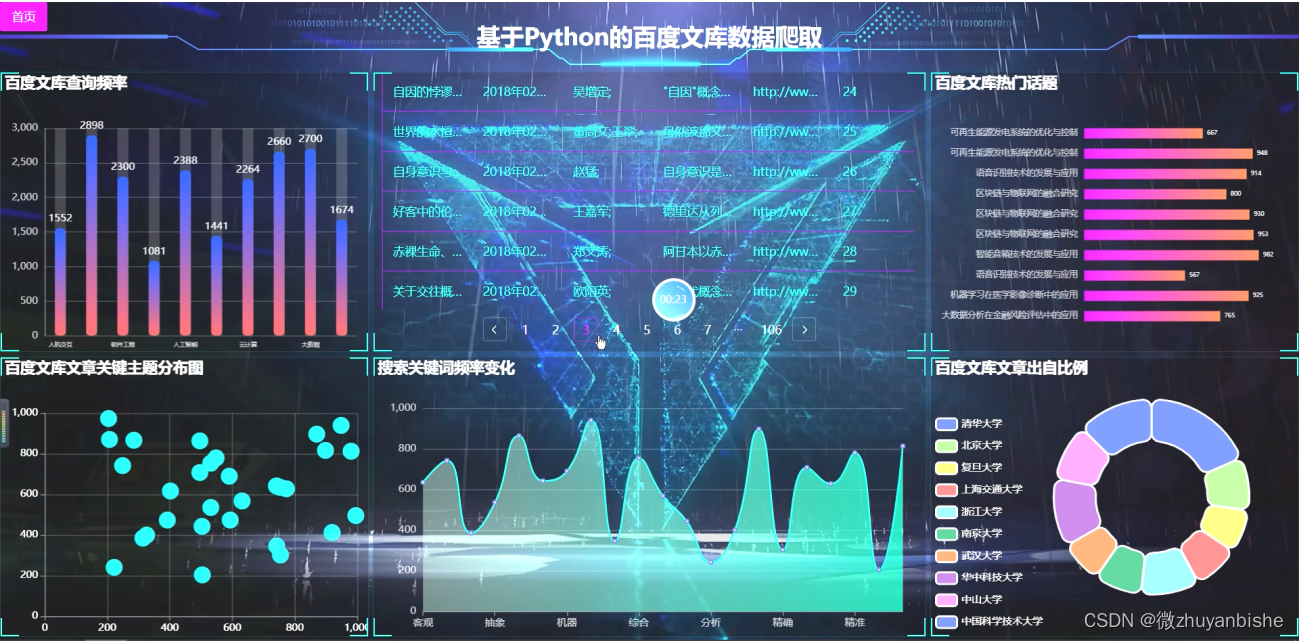
图5-3 数据可视化大屏设计















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









