







目录
1.简介
目标站点:某江文学城书库
爬虫工具:BeautifulSoup,requests
数据分析:pandas,matplotlib
词云:wordcloud,re
PS. 鉴于江湖上一直流传着某江老板抠门得很,程序员只有3个服务器也只有几台办公还在小区里面,建议爬的时候通过sleep放慢爬取速度,减少给服务器的压力。
2.爬虫
2.1 url解析
在文库首页上随便勾选几个选项试试,观察url的变化(注意【】框出的部分):
-
性向:言情,按发表时间排序,只显示已完成,得到的url:
https://www.jjwxc.net/bookbase.php?fw0=0&fbsj0=0&ycx0=0&【xx1=1】&mainview0=0&sd0=0&lx0=0&fg0=0&bq=&removebq=&【sortType=3】&collectiontypes=ors&searchkeywords=&【page=0】&【isfinish=2】 -
性向:纯爱,按作品收藏排序,只显示无限制,跳转到第4页,得到的url:
https://www.jjwxc.net/bookbase.php?fw0=0&fbsj0=0&ycx0=0&【xx2=2】&mainview0=0&sd0=0&lx0=0&fg0=0&bq=&removebq=&【sortType=4】&【page=4】&【isfinish=0】&collectiontypes=ors&searchkeywords=
总结出来几个参数:
- 页数: page,从1开始(但0也是第一页)。上限为1000。
- 性向:言情是xx1=1、纯爱xx2=2、百合xx3=3,如果要同时选择多个性向就一起写上
- 排序方式:sortType,更新时间=1,作品收藏=4,发表时间=3,作品积分=2
- 是否完结:isfinish,无限制=0,连载中=1,已完结=2
2.2 页面元素解析
想要爬取的数据如下:
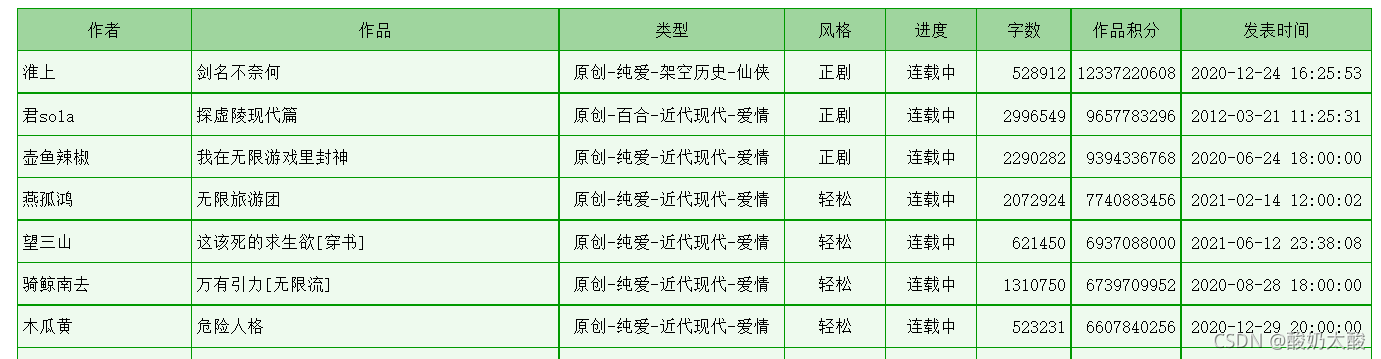
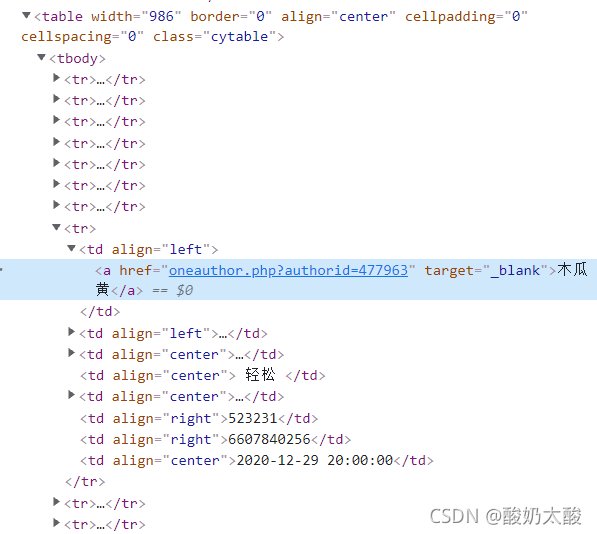
按F12打开开发者工具,查看页面元素,发现所有信息在一个table中(class=“cytable”),每行是一个tr,每个单元格是一个td。
2.3 登录
尝试跳转到超过10的页面时会出现要求登录的界面:

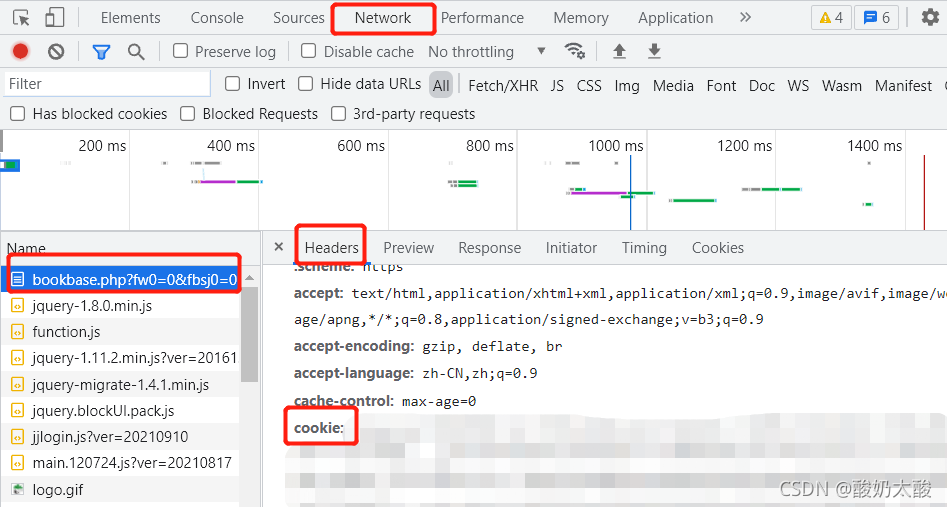
登录晋江账号后,按F12打开开发者工具,打开network选项卡,刷新页面,寻找到对应数据包,在headers中复制cookie,加到爬虫的请求头中。
2.4 完整代码
import pandas as pd
import requests
import BeautifulSoup
def main(save_path, sexual_orientation):
"""
save_path: 文件保存路径
sexual_orientation: 1:言情,2:纯爱,3:百合,4:女尊,5:无CP
"""
for page in range(1, 1001):
url = get_url(page, sexual_orientation)
headers = {
'cookie': 你的cookie,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'}
html = requests.get(url, headers=headers)
html.encoding = html.apparent_encoding
try:
data = parse(html.content)
except:
print("爬取失败:", page)
continue
if len(data) == 0:
break
df = pd.DataFrame(data)
df.to_csv(save_path, mode='a', header=False, index=False)
print(page)
time.sleep(3)
def get_url(page, sexual_orientation):
url = f"https://www.jjwxc.net/bookbase.php?fw0=0&fbsj0=0&ycx1=1&xx{
sexual_orientation}={
sexual_orientation}&mainview0=0&sd0=0&lx0=0&fg0=0&bq=-1&" \
f"sortType=3&isfinish=2&collectiontypes=ors&page={
page}"
return url
def parse(document):
soup = BeautifulSoup(document, "html.parser")
table = soup.find("table", attrs={
'class': 'cytable'})
rows = table. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1668
1668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









