






MiniMax发布了最新的旗舰款模型,MiniMax-Text-01。这是一个456B参数的MOE模型,支持最大4M上下文。今天我们来解读一下这个模型,最后会讲一下模型的使用方式和价格。
先来看整体指标,以下图表分为三块指标,分别是文本能力,多模态能力以及长文本能力。
- Core text benchmark performance(核心文本基准性能): 这部分展示了模型在多个自然语言处理任务中的表现,如:
- MMLU: 指多领域理解任务,通常包括多种自然语言推理、阅读理解等任务。
- MATH: 表示数学能力测试,评估模型在数学问题上的表现。
- C-SimpleQA, IFEval, GQPA 等:表示不同类型的问答任务性能。
- Core multimodal benchmark performance(核心多模态基准性能): 这部分展示了模型在多个多模态任务中的表现,涉及视觉、语言结合的任务:
- MMMU: 多模态理解任务。
- ChartQA, DocVQA: 图像或文档问答任务,要求模型从图像或文档中提取信息。
- AI2D, MathVista: 计算机视觉和其他形式的图像分析任务。
- Long-context RULER performance(长文本 RULER 性能): 该指标涉及对长上下文的理解和生成能力。RULER 是一个基于长上下文的基准,评估模型在处理较长文本时的能力,能够处理更多的信息输入(如超过8k字符)。
三项指标的评测结果:
- minimax-text-01模型整体性能与第一梯队模型相仿,数学能力仍弱于qwen2.5和deepseek-v3。
- 多模态能力,即视觉能力也处于第一梯队模型。
- 长文本处理的准确率远远领先于大部分模型,与minimax最相近的是gemini 1.5pro。
-
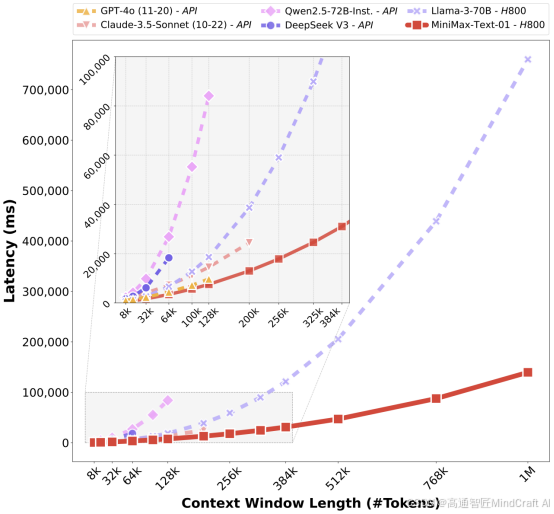
点评:长文本处理的响应速度远高于其他模型。
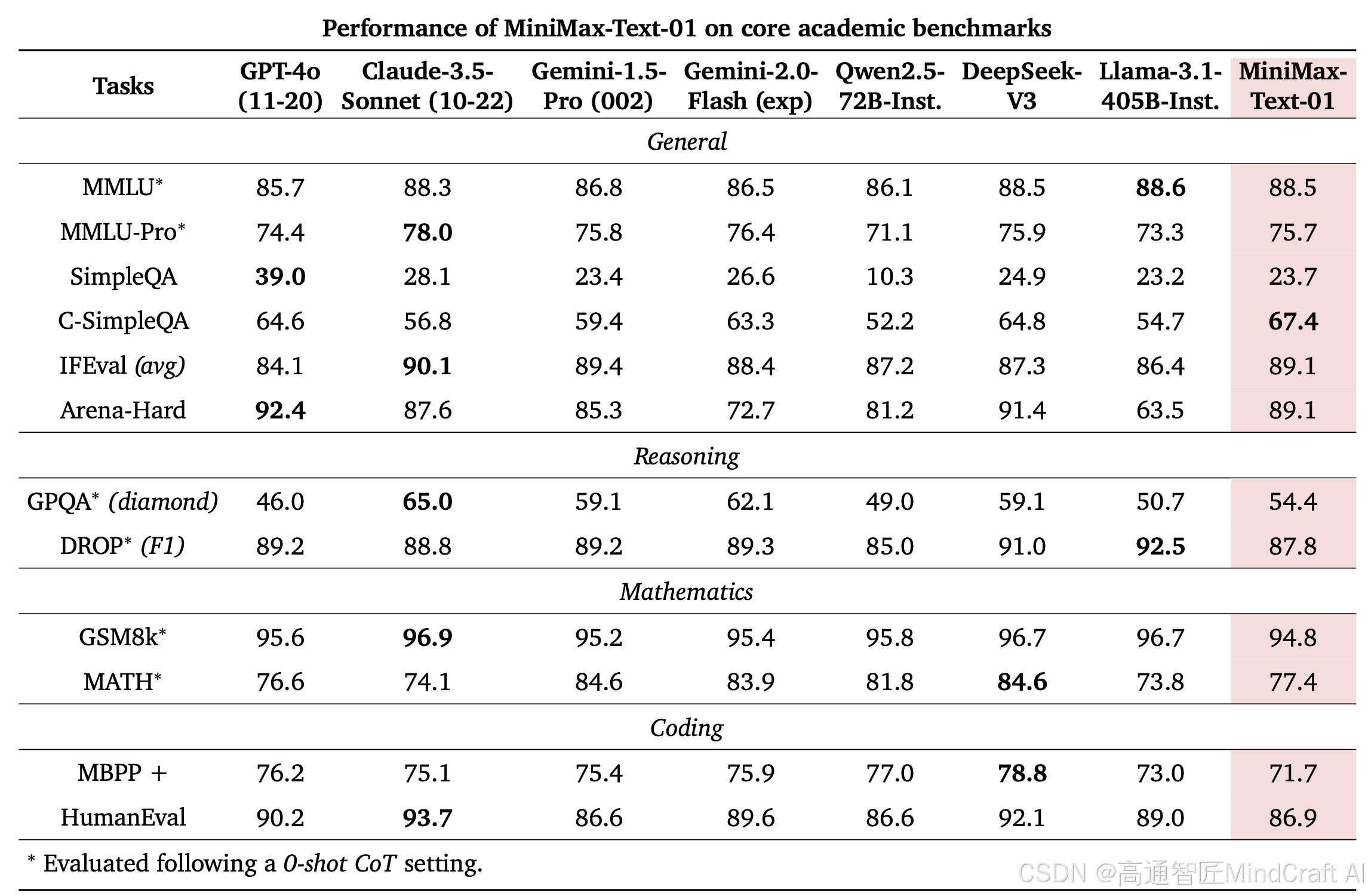
图表中的文本核心指标的具体明细。
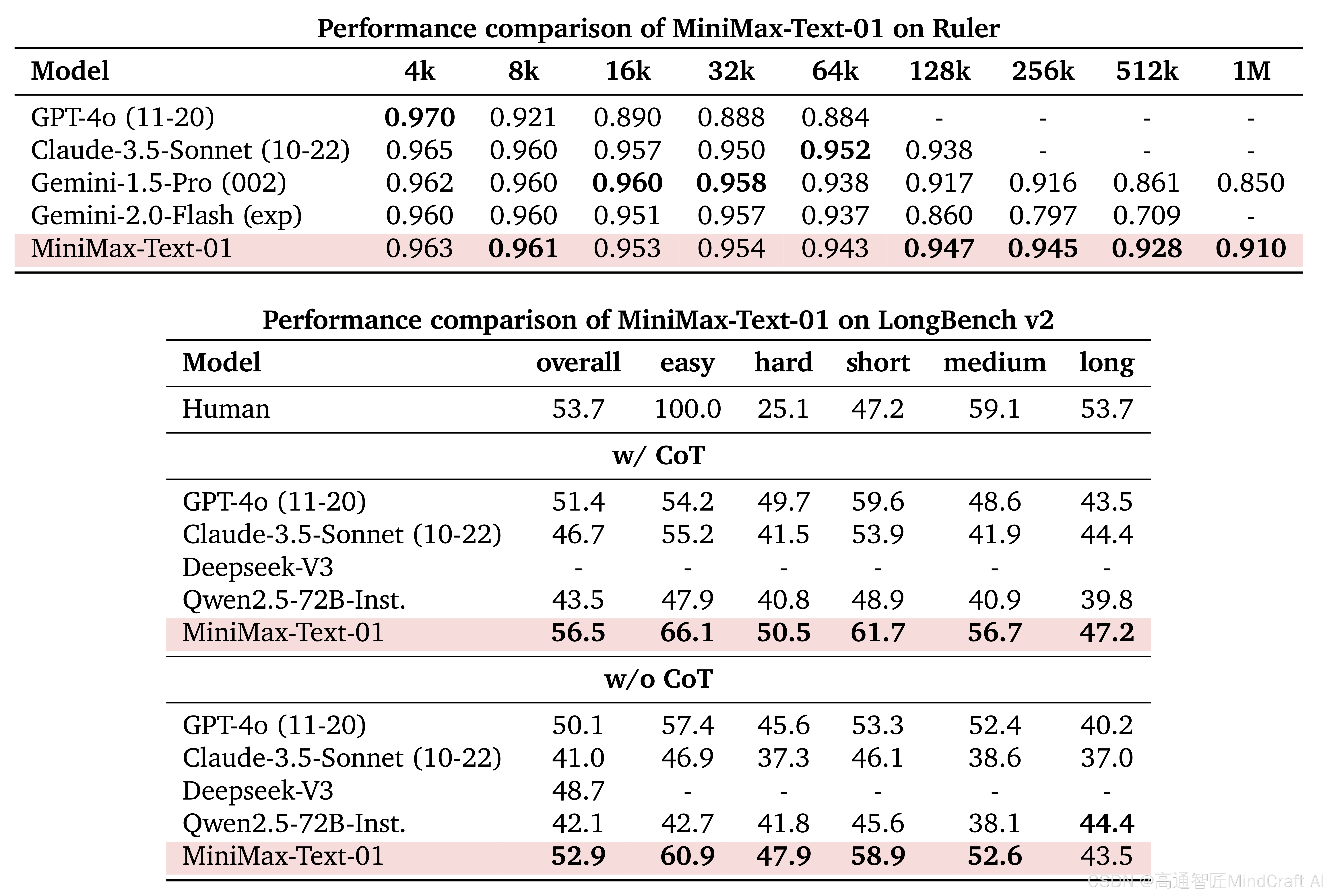
点评:长文本下指标的对比测试,再更长文本的情况下,有明显优势。用思维链CoT的方式解读长文本,效果优异。
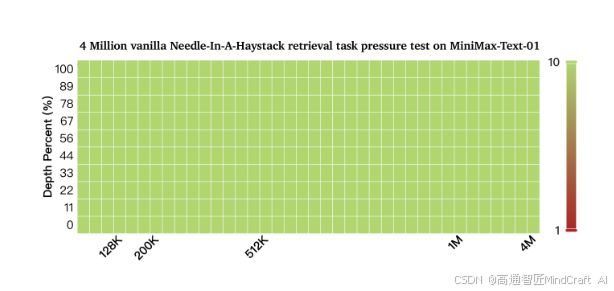
点评:在400万上下文的大海捞针测试中
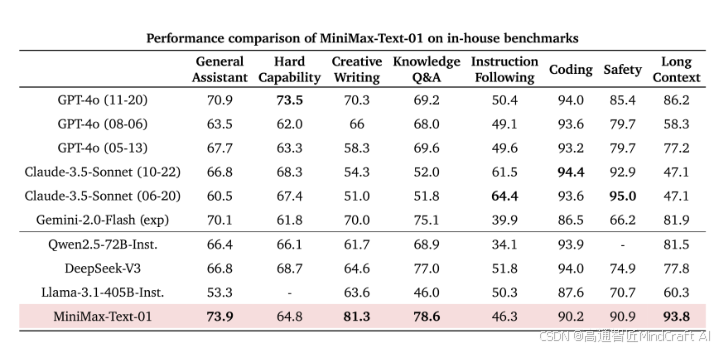
MiniMax自己的测试集指标对比
通用助理:MiniMax最高,其次是GPT4o和Gemini-2.0-Flash。
高难度问题:MiniMax得分并不高,这里GPT4o最强,仅比gemini2.0 flash强一点。
创意写作:MiniMax分数最高,远远领先于其他模型,其次是GPT4o和Gemini2.0 Flash。
知识问答:MiniMax分数最高,其次是gpt4o。
指令遵循:表现一般,仅高于qwen2.5,gemini 2.0 flash。最高的是claude3.5 sonnet。
代码能力:强于gemini 2.0 flash和llama3.1 405B。最高的是claude3.5 sonnet。
安全指数:仅次于claude3.5 sonnet。
长文本能力:远远领先于其他模型。第二档是gpt4o,gemini 2.0 flash,qwen2.5.
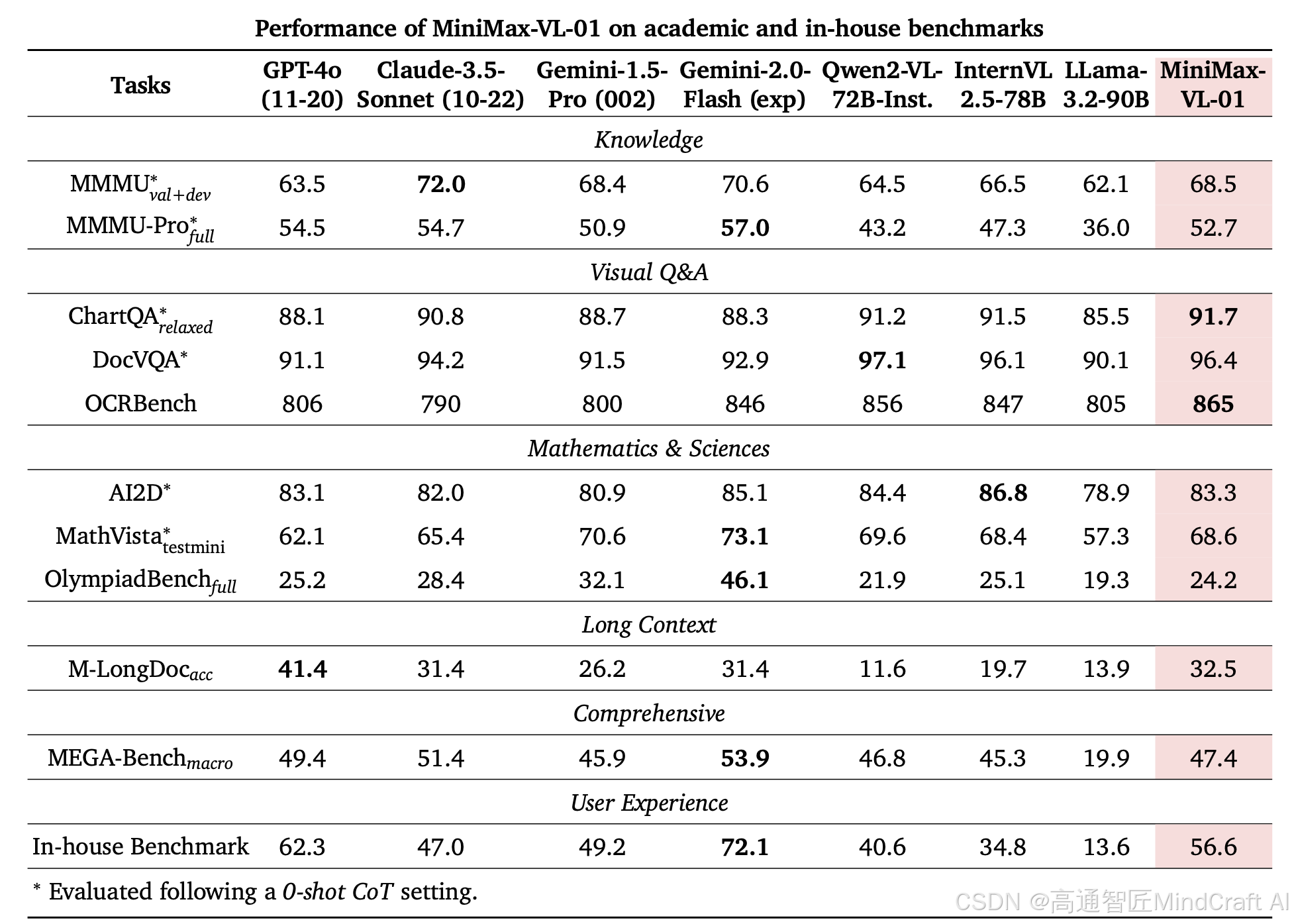
多模态能力的具体指标评测
通用综合能力:是GPT4o,claude3.5 sonnet, gemini的水准。
视觉问答:包括文档交互,图表交互,文字识别。指标是高于国外主流模型的。
数学与科学能力:整体来说与国外主流模型一个水准。Gemini2.0 FLASH似乎在这方面特别突出。作为国内视觉模型,在这方面可能仅次于QVQ 72B。
长下文的视觉能力:优于大部分模型,GPT4o特别出色。不知道这里指的什么长文本,难道是长下文+识图时的表现?
理解能力:略差于国外主流模型。
用户体验:Gemini 2.0 FLASH分数最高,MiniMax优于claude3.5 sonnet和gemini 1.5pro,但是比gpt4o低。
点评:视觉模型的结论。视觉能力处于世界第一梯队。意外的收获时,Gemini 2.0 FLASH作为视觉模型异常地强。
模型参数与费用:
- 上下文:开源版本能支持到4M上下文,国内API支持到1M。
- 价格:输入1元/百万tokens,输出8元/百万tokens。
最终结论:
- 长文本处理能力世界第一。
- 综合性能优异,包括视觉能力,整体达到世界一流水平。
- 数学、科学和代码能力仍然不如顶流模型。
- 性价比高,输入1元/百万tokens,输出8元/百万tokens。输入价格比deepseek v3涨价后价格便宜1倍。作为旗舰款还是OK的。


















 576
576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









