






1. Janus系列概述
DeepSeek推出的JanusPro和JanusFlow模型代表了一种新型的多模态模型架构。区别于传统的多模态模型(一般涉及图像/视频识别,或使用多个独立的模型进行协同工作),Janus系列通过单一模型整合了文本处理、图像识别与图像生成的功能。目前,这一系列模型尚处于早期阶段,更加侧重于学术研究而非实际应用。
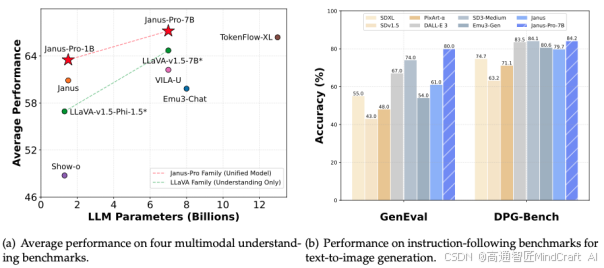
2. 参数优势与同类模型对比
从参数指标来看,Janus系列在多个维度上超越了同类模型。例如,在指令遵循能力方面,它的表现甚至对标OpenAI DALL·E 3。虽然此处的比较重点在指令遵循,而非图像质量,但仍然凸显了Janus系列的潜力。与多模态模型如Emu-3和Show-O相比,Janus系列显示出显著的优势。值得注意的是,这些新型多模态模型的开发主要由中国机构推动,例如Emu-3由北京智源人工智能研究院(BAAI)主导,而Show-O的团队则来自字节跳动和新加坡国立大学。


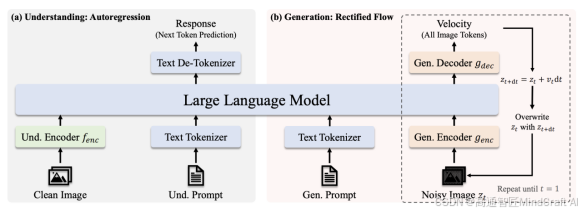
3. Janus-Flow与Janus-Pro架构解析
Janus系列的架构设计值得关注。Janus-Flow模型基于大型语言模型(LLM),同时接入了图像识别与生成模块,实现了多模态功能。Janus-Pro同样采用了相似的架构,且在整体设计上完全基于Transformer架构,而传统的图像生成模型如Stable Diffusion则采用了扩散模型(Diffusion Model)。
4. 总结
Janus模型的主要特点在于通过单个模型实现多模态任务的整合,这种设计对于模型的开发、训练和推理成本具有优势。尤其是Janus-Flow展示了模块化架构的潜力。虽然当前的Janus系列覆盖了文本处理、图像识别及生成,但类似Emu-3的模型已开始整合视频理解与生成。未来,可预见的是进一步将语音识别与合成等功能融合,形成更全面的多模态体系。尽管Janus系列在同级别参数模型中展现出技术优势,但在行业顶尖的LLM、图像识别及生成模型面前,尚存在不小差距,因此目前该系列的学术价值高于实用价值,但其潜在前景令人期待。
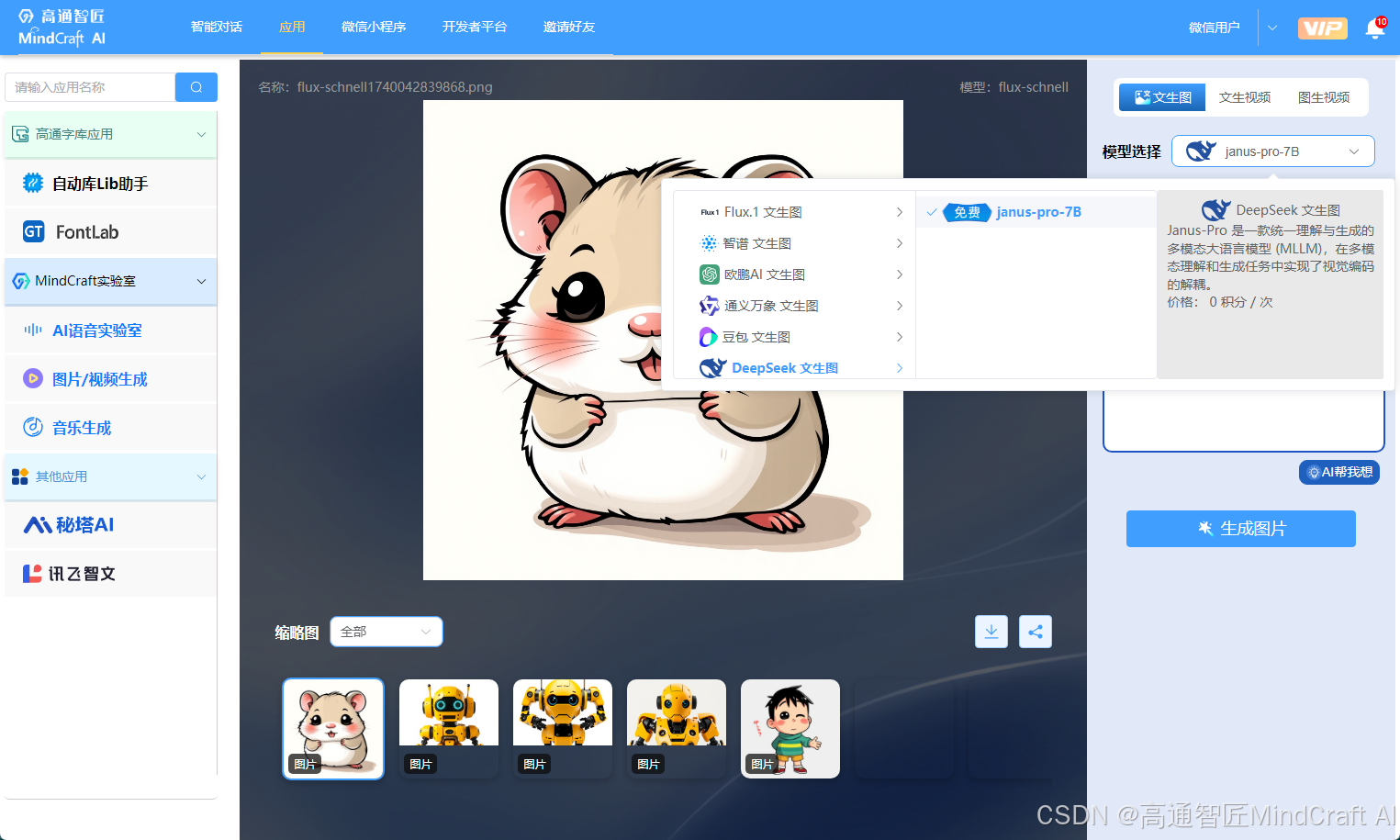
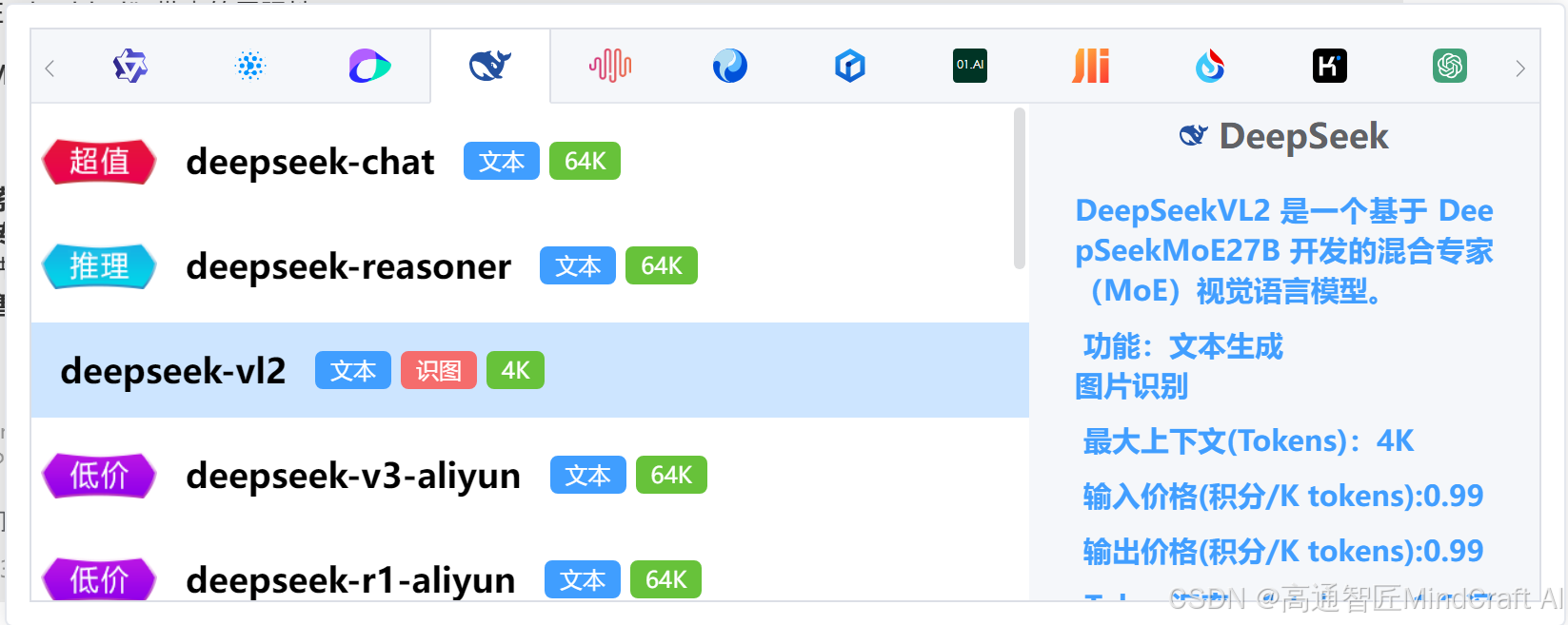
5. 模型使用
用户可以在高通智匠(MindCraft AI)平台上使用Janus-Pro,以其作为图像生成模型。对于图像识别,建议使用DeepSeek-VL2。综合来看,目前这两款模型的能力相对一般,DeepSeek系列中,DeepSeek-V3和DeepSeek-R1显示出更为显著的优势。


















 532
532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









